













擊穿黑盒模型!MIT華人博士發布ExSum,模型解釋新神器
?人工智能近些年的快速發展主要歸功于神經網絡模型,但隨著模型越做越大、越來越復雜,研究人員漸漸也無法完全理解模型究竟是如何做出預測的,「黑匣子」也就變得越來越黑。
能否理解黑盒模型的運行機制對于模型部署來說至關重要,關乎模型的可靠性和易用性,所以也有研究人員正在開發模型的可解釋方法。

為了嘗試理解模型,之前大多采用測試樣例的方法來描述和解釋模型的決策過程,比如在情感分析任務中,對電影評論數據高亮顯示模型認為正向還是負向的關鍵詞,也叫「局部解釋」。
但對于復雜一些的任務,人類可能就沒辦法輕易理解了,甚至可能會產生誤解,那這種解釋方法就毫無用處。
最近,麻省理工學院的研究人員提出了一個全新的數學框架ExSum,可以形式化地量化和評估機器學習模型的可解釋性的可理解度,論文已被NAACL 2022接收。


論文鏈接:https://arxiv.org/pdf/2205.00130.pdf
說得通俗點,就是看你「解釋模型的規則」適不適用于更多的數據。
局部解釋的一大弊端就是沒法判斷規則是不是可以擴展到其他測試樣例上,比如高亮了「精彩」作為電影評論的正向詞,那是不是意味著「不」之類的否定詞就對測試沒影響了?
使用ExSum,用戶可以用三個指標來查看規則是否成立:覆蓋率、有效性和清晰度。
覆蓋率衡量規則在整個數據集中的適用范圍;有效性則顯示有多少樣例使得規則成立;清晰度描述了規則的精確程度:一個有效的規則可能也很通用,但對于理解模型來說則沒有用處。
文章的第一作者Yilun Zhou是麻省理工學院電子工程和計算機科學系(EECS)的五年級博士生,導師為Julie Shah教授。目前的研究方向是幫助人類更好地理解那些在世界上做出重要決策的模型,主要問題包括如何確保一個黑盒模型的正確工作?如何對預期的和更重要的非預期的模型行為有一個全面的理解?人類對這種復雜推理過程的理解有什么局限性?
為了回答這些問題,他開發了可解釋機器學習的模型、算法和評估,并將其應用于不同的領域,包括計算機視覺(CV)、自然語言處理(NLP)和機器人學。

用數學描述經驗
在訓練文本分類模型時,對模型進行解釋通常會怎么做?
先給模型輸入一個句子,然后模型給文本預測一個標簽。如果預測正確,就分析一下句子中每個詞在預測中的重要度。
比如下圖中的例句,在情感分類任務中的標簽為正向,使用SHAP解釋方法可以對文本中的每個詞測量貢獻度,比如「memorable」和「great」的評分更高,在情感分類時預測重要度更高;而停用詞「for」得分只有-0.02,基本就是忽略掉了,對預測結果沒有影響。
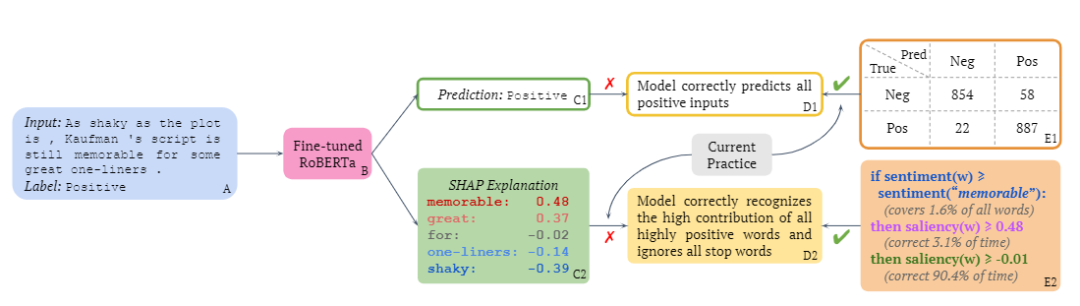
這么一驗證,再加上模型的分類性能特別好,你可能會得出結論:模型能夠正確地識別所有正向詞、忽視停用詞。
但事實果真如此嗎?
孤證不立,模型在其他數據上是否能滿足這個結論,還是個未知數;并且用人來觀察這種方式也不夠自動化。
ExSum框架的做法就是將這條規則「數學化」,在進行模型解釋時,每個單詞的每個特征都稱之為一個基本的解釋單元(fundamental explanation unit, FEU),在這個例子里,用到的特征就是SHAP評分。
然后生成一條規則,比如句子的情感評分(0.638)比「memorable」的評分更高,然后以0.479的評分作為正向詞的基準,判斷在其他句子上該條規則的正確率(3.1%)。
這種方法可以自動地測量規則的覆蓋度、有效性和清晰度,能夠幫助開發者更深入地理解模型的行為。
上手指南
隨文章一同發布的還有ExSum框架程序,只需要通過pip install exsum即可開始「模型解釋」之旅。
ExSum主要用于檢查和修改針對文本二分類模型的ExSum規則,包含Exsum規則和規則集合的類定義,基于Flask的服務器,還可以對規則和規則集合進行交互式可視化展示。
代碼鏈接:https://github.com/YilunZhou/ExSum
教程鏈接:https://yilunzhou.github.io/exsum/documentation.html
運行ExSum GUI后可以看到程序主要分為5個面板。
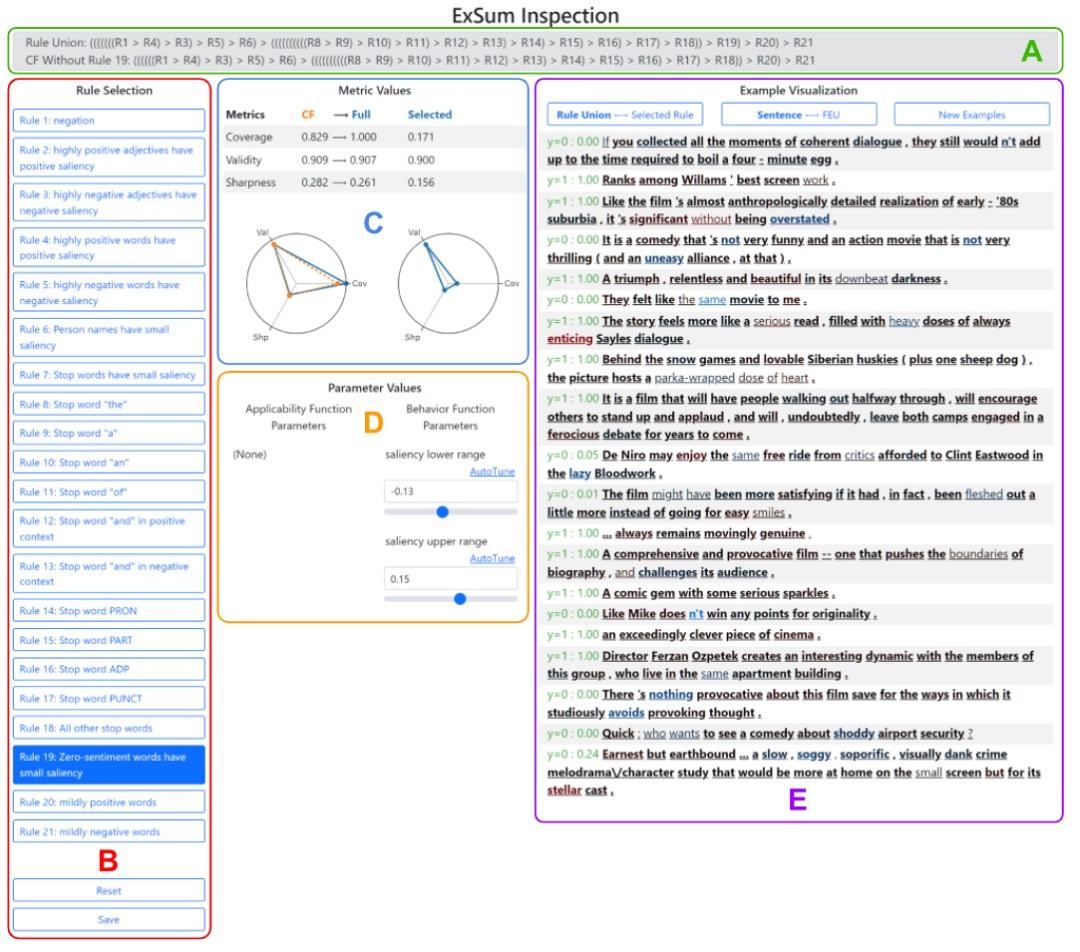
面板A顯示規則的組成結構,并非所有的規則都被選中,比如A表示不使用規則2和7,但每個規則最多只能使用一次。

當選擇一條規則時,將自動計算一個沒有該規則的反事實(counterfactual, CF)規則聯合,以便用戶直觀地了解其邊際貢獻,第二行則顯示了CF規則集合的結構。
面板B將所有規則轉為按鈕,用戶可以通過單擊規則來更詳細地檢查規則,底部是重置和保存按鈕。重置按鈕用來放棄對規則(面板D)中的參數值所做的所有更改,保存按鈕則將當前規則集合的副本保存到某個指定目錄中。
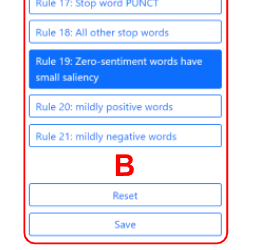
面板C以數字和圖形形式顯示為完整規則集合、CF規則集合和選定規則計算的度量值。對規則所做的任何更改都會自動觸發對這些值的重新計算和更新。
面板D列出所選規則的參數,可以通過輸入或使用滑塊手動更改。

此外,還可以使用AutoTune工具箱自動調整參數。
面板E顯示特定數據實例上的規則和規則集合,包括三個控制按鈕,分別用來在切換顯示整個規則集合和僅顯示選定規則、切換顯示整個句子或僅顯示句子中的一個FEU、重隨機數據并顯示新的一批實例。

當預測正確時(使用0.5作為閾值),文本為綠色,否則為紅色。
單詞的下劃線表示它被所選規則或規則集合覆蓋,對于覆蓋詞,粗體表示根據行為函數是有效的。
將鼠標懸停在每個單詞上會顯示一個工具提示,顯示數字屬性值和覆蓋該單詞的規則(如果有)。下圖顯示了一個例子(在這種情況下,規則19對「嚴重」一詞無效,因為該詞不是粗體字)。


























