













用一行代碼大幅提升零樣本學習方法效果,南京理工&牛津提出即插即用分類器模塊
零樣本學習(Zero-Shot Learning)聚焦于對訓練過程中沒有出現過的類別進行分類,基于語義描述的零樣本學習通過預先定義的每個類別的高階語義信息來實現從可見類(seen class)到未見類(unseen class)的知識遷移。傳統零樣本學習在測試階段僅需要對未見類進行識別,而廣義零樣本學習(GZSL)需要同時識別可見類和未見類,其評測指標是可見類類平均準確率與未見類類平均準確率的調和平均。
一種通用的零樣本學習策略是使用可見類樣本和語義訓練從語義空間到視覺樣本空間的條件生成模型,再借助未見類語義生成未見類的偽樣本,最后使用可見類樣本和未見類偽樣本訓練分類網絡。然而,要學習兩個模態(語義模態與視覺模態)間的良好映射關系通常需要大量樣本(參照 CLIP),這在傳統零樣本學習環境下無法實現。因此,使用未見類語義生成的視覺樣本分布通常和真實樣本分布存在偏差(bias),這意味著以下兩點:1. 這種方法獲得的未見類準確率有限。2. 在未見類平均每類生成偽樣本數量與可見類平均每類樣本數量相當的情況下,未見類準確率與可見類準確率存在較大差值,如下表 1 所示。

我們發現就算只學習語義到類別中心點的映射,并將未見類語義映射為的單一樣本點復制多次再參加分類器訓練也能得到接近使用生成模型的效果。這意味著生成模型生成的未見類偽樣本特征對分類器來說是較為同質(homogeneity)的。
先前的方法通常通過生成大量未見類偽樣本來迎合 GZSL 評測指標(盡管大的采樣數量對未見類類間判別沒有幫助)。然而這種重采樣(re-sampling)的策略在長尾學習(Long-tail Learning)領域被證明會導致分類器在部分特征上過擬合,在這里即是與真實樣本偏移的偽未見類特征。這種情況不利于可見類和未見類真實樣本的識別。那么,能否舍棄這種重采樣策略,轉而將生成未見類偽樣本的偏移性和同質性(或者可見類與未見類的類別不平衡)作為歸納偏置(inductive bias)植入分類器學習呢?
基于此,我們提出了一個即插即用的分類器模塊,只需修改一行代碼就能提升生成型零樣本學習方法的效果。每個不可見類只需生成 10 個偽樣本,就能達到 SOTA 水平。與其他生成型零樣本方法相比,新方法在計算復雜度上具有巨大優勢。研究成員來自南京理工大學和牛津大學。

- 論文: https://arxiv.org/abs/2204.11822
- 代碼: https://github.com/cdb342/IJCAI-2022-ZLA
本文以一致化訓練與測試目標為指引,推導出廣義零樣本學習評測指標的變分下界。以此建模的分類器能夠避免使用重采用策略,防止分類器在生成的偽樣本上過擬合對真實樣本的識別造成不利影響。所提方法能夠使基于嵌入的分類器在生成型方法框架上有效,減少了分類器對于生成偽樣本質量的依賴。
方法
1. 引入參數化先驗
我們決定從分類器的損失函數上著手。假設類別空間已經被生成的未見類偽樣本所完善,先前的分類器以最大化全局準確率為優化目標:
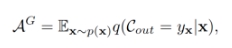

其中 為全局準確率,
為全局準確率, 表示分類器輸出,
表示分類器輸出, 表示樣本分布,
表示樣本分布, 為樣本 X 對應標簽。而 GZSL 的評測指標為:
為樣本 X 對應標簽。而 GZSL 的評測指標為:
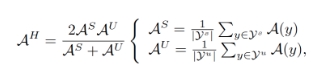

其中 和
和 分別代表可見類和未見類集合。訓練目標和測試目標的不一致意味著先前的分類器訓練策略沒有考慮可見類和未見類的差異。自然而然地,我們試圖通過對
分別代表可見類和未見類集合。訓練目標和測試目標的不一致意味著先前的分類器訓練策略沒有考慮可見類和未見類的差異。自然而然地,我們試圖通過對 進行推導來實現訓練與測試目標一致的結果。經過推導,我們得到了其下界:
進行推導來實現訓練與測試目標一致的結果。經過推導,我們得到了其下界:

其中 代表可見類 - 未見類先驗,其與數據無關,在實驗中作為超參數進行調整,
代表可見類 - 未見類先驗,其與數據無關,在實驗中作為超參數進行調整, 代表可見類或未見類內部先驗,在實現過程中用可見類樣本頻率或均勻分布代替。通過最大化
代表可見類或未見類內部先驗,在實現過程中用可見類樣本頻率或均勻分布代替。通過最大化 的下界,我們得到了最終的優化目標:
的下界,我們得到了最終的優化目標:

由此,我們的分類建模目標相較先前發生了以下改變:

通過使用交叉熵(cross-entropy)擬合后驗概率 ,我們得到分類器損失為:
,我們得到分類器損失為:

這與長尾學習中的邏輯調整(Logit Adjustment)類似,因此我們稱之為零樣本邏輯調整(ZLA)。至此,我們實現了通過引入參數化先驗將可見類與未見類的類別不平衡作為歸納偏置植入到分類器訓練中,并且在代碼實現中只需對原始 logits 加上額外偏置項就能達到以上效果。

2. 引入語義先驗
到目前為止,零樣本遷移的核心,即語義先驗(semantic prior)僅在訓練生成器與生成偽樣本階段發揮作用,對未見類的識別完全取決于生成的未見類偽樣本的質量。顯然,如果能夠在分類器訓練階段引入語義先驗,將會有助于未見類的識別。在零樣本學習領域有一類基于嵌入(embedding-based)的方法能夠實現這一功能。然而,這一類方法與生成模型學習到的知識是相似的,即語義與視覺間的聯系(semantic-visual link),這導致在先前的生成型框架中(參照論文 f-CLSWGAN)直接引入基于嵌入的分類器無法取得比原先更好的效果(除非這種分類器本身就有更好的零樣本性能)。通過本文提出的 ZLA 策略,我們能夠改變生成的未見類偽樣本在分類器訓練中扮演的角色。從原先的提供不可見類信息到現在的調整不可見類與可見類間的決策界限(decision boundary),我們得以在分類器訓練階段引入語義先驗。具體地,我們采用了原型學習的方法將每個類別的語義映射為視覺原型(即分類器權值),再將調整的后驗概率(adjusted posterior)建模為樣本與視覺原型間的余弦相似度(cosine similarity),即

其中 為溫度系數。在測試階段,樣本被預測為與其余弦相似度最大的視覺原型對應類別。
為溫度系數。在測試階段,樣本被預測為與其余弦相似度最大的視覺原型對應類別。

實驗
我們將所提出的分類器與基礎 WGAN 結合,在每個未見類生成 10 個樣本的情況下達到了媲美 SoTAs 的效果。另外我們將其插入到更加先進的 CE-GZSL 方法中,在不改變其他參數(包括生成樣本數量)的情況下提升了初始效果。

在消融實驗中,我們將基于生成的原型學習器(prototype learner)與純原型學習器進行了比較。我們發現,最后一個 ReLU 層對于純原型學習器的成功至關重要,因為將負數置零可以增大類別原型與未見類特征的相似度(未見類特征同樣經過 ReLU 激活)。然而將部分數值置零也限制了原型的表達,不利于更進一步的識別性能。借助偽未見類樣本來彌補未見類信息不僅能在使用 RuLU 時達到更高性能,更能在沒有 ReLU 層的情況下實現進一步的性能超越。

在另一項消融研究中,我們將原型學習器與初始分類器進行比較。結果顯示當生成大量未見類樣本時,原型學習器與初始分類器相比沒有優勢。而在使用本文提出的 ZLA 技術時,原型學習器顯示出其優越性。正如前文所說,這是因為原型學習器和生成模型都在學習語義 - 視覺聯系,所以語義信息很難被充分利用。ZLA 使生成的未見類樣本能夠調整決策邊界,而不是僅僅提供未見類信息,從而對原型學習器起到激活作用。



























