













提升生成式零樣本學習能力,視覺增強動態語義原型方法入選CVPR 2024
雖然我從來沒見過你,但是我有可能「認識」你 —— 這是人們希望人工智能在「一眼初見」下達到的狀態。
為了達到這個目的,在傳統的圖像識別任務中,人們在帶有不同類別標簽的大量圖像樣本上訓練算法模型,讓模型獲得對這些圖像的識別能力。而在零樣本學習(ZSL)任務中,人們希望模型能夠舉一反三,識別在訓練階段沒有見過圖像樣本的類別。
生成式零樣本學習(GZSL)是實現零樣本學習的一種有效方法。在生成式零樣本學習中,首先需要訓練一個生成器來合成未見類的視覺特征,這個生成過程是以前面提到的屬性標簽等語義描述為條件驅動的。有了生成的視覺特征作為樣本,就可以像訓練傳統的分類器一樣,訓練出可以識別未見類的分類模型。
生成器的訓練是生成式零樣本學習算法的關鍵,理想狀態下,生成器根據語義描述生成的某個未見類的視覺特征樣本,應與此類別真實樣本的視覺特征具有相同的分布。
在現有的生成式零樣本學習方法中,生成器在被訓練和使用時,都是以高斯噪聲和類別整體的語義描述為條件的,這限制了生成器只能針對整個類別進行優化,而不是描述每個樣本實例,所以難以準確反映真實樣本視覺特征的分布,導致模型的泛化性能較差。另外,已見類與未見類所共享的數據集視覺信息,即域知識,也沒有在生成器的訓練過程中被充分利用,限制了知識從已見類到未見類的遷移。
為了解決這些問題,華中科技大學研究生與阿里巴巴旗下銀泰商業集團的技術專家提出了視覺增強的動態語義原型方法(稱為 VADS),將已見類的視覺特征更充分地引入到語義條件中,推動生成器學習準確的語義 - 視覺映射,研究論文《Visual-Augmented Dynamic Semantic Prototype for Generative Zero-Shot Learning》已被計算機視覺頂級國際學術會議 CVPR 2024 接收。
具體而言,上述研究呈現了三個創新點:
第一,研究使用視覺特征對生成器進行增強,來為零樣本學習中的未見類生成可靠的視覺特征,在零樣本學習領域中是具有創新性的方法。
第二,研究提出了 VDKL 和 VOSU 兩個組件,有效地獲取數據集的視覺先驗并用圖像的視覺特征動態更新預定義好的類別語義描述,從而有效地實現了對視覺特征的利用。
第三,從試驗結果上看,本研究使用視覺特征對生成器進行增強的效果顯著,而且作為一個即插即用的方法,具有較強的通用性。
研究細節
VADS 由兩個模塊組成:(1)視覺感知域知識學習模塊(VDKL)學習視覺特征的局部偏差和全局先驗,即域視覺知識,這些知識取代了純高斯噪聲,提供了更豐富的先驗噪聲信息;(2)面向視覺的語義更新模塊(VOSU)學習如何根據樣本的視覺表示更新其語義原型,更新的后語義原型中也包含了域視覺知識。
最終,研究團隊將兩個模塊的輸出連接為一個動態語義原型向量,作為生成器的條件。大量實驗表明,VADS 方法在常用的零樣本學習數據集上實現了顯著超出已有方法的性能,并可以與其他生成式零樣本學習方法結合,獲得精度的普遍提升。
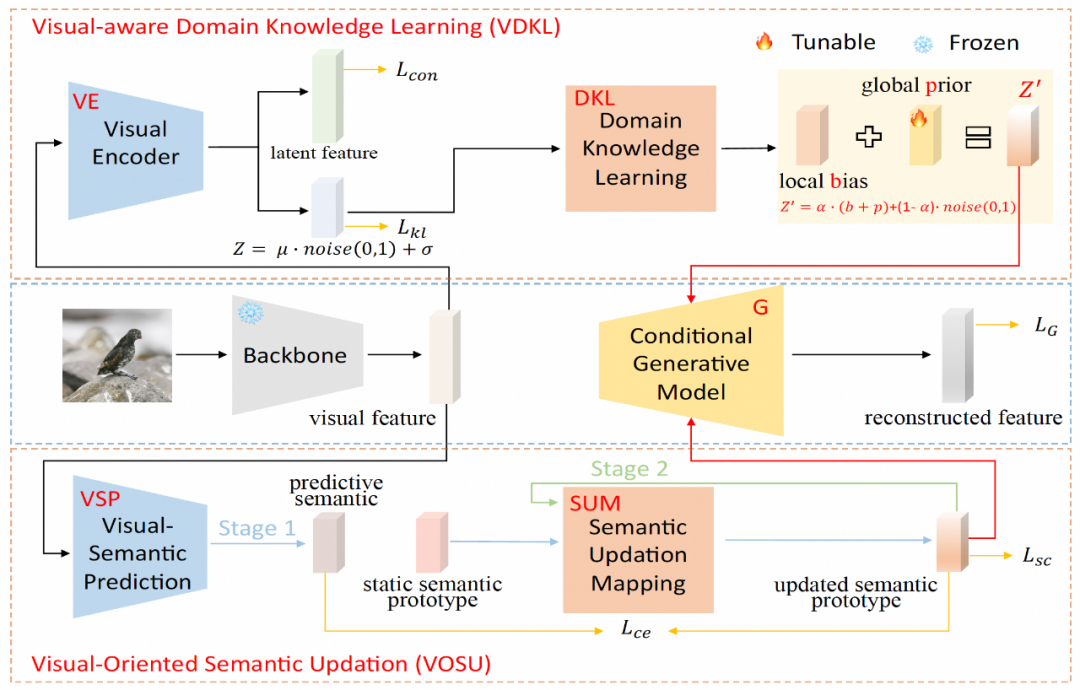
在視覺感知域知識學習模塊(VDKL)中,研究團隊設計了一個視覺編碼器(VE)和一個域知識學習網絡(DKL)。其中,VE 將視覺特征編碼為隱特征和隱編碼。通過使用對比損失在生成器訓練階段利用已見類圖像樣本訓練 VE,VE 可以增強視覺特征的類別可分性。
在訓練 ZSL 分類器時,生成器生成的未見類視覺特征也被輸入 VE,得到的隱特征與生成的視覺特征連接,作為最終的視覺特征樣本。VE 的另一個輸出,即隱編碼,經過 DKL 變換后形成局部偏差 b,與可學習的全局先驗 p,以及隨機高斯噪聲一起,組合成域相關的視覺先驗噪聲,代替其他生成式零樣本學習中常用的純高斯噪聲,作為生成器生成條件的一部分。
在面向視覺的語義更新模塊(VOSU)中,研究團隊設計了一個視覺語義預測器 VSP 和一個語義更新映射網絡 SUM。在 VOSU 的訓練階段,VSP 以圖像視覺特征為輸入,生成一個能夠捕獲目標圖像視覺模式的預測語義向量,同時,SUM 以類別語義原型為輸入,對其進行更新,得到更新后的語義原型,然后通過最小化預測語義向量與更新后語義原型之間的交叉熵損失對 VSP 和 SUM 進行訓練。VOSU 模塊可以基于視覺特征對語義原型進行動態調整,使得生成器在合成新類別特征時能夠依據更精確的實例級語義信息。
在試驗部分,上述研究使用了學術界常用的三個 ZSL 數據集:Animals with Attributes 2(AWA2),SUN Attribute(SUN)和 Caltech-USCD Birds-200-2011(CUB),對傳統零樣本學習和廣義零樣本學習的主要指標,與近期有代表性的其他方法進行了全面對比。
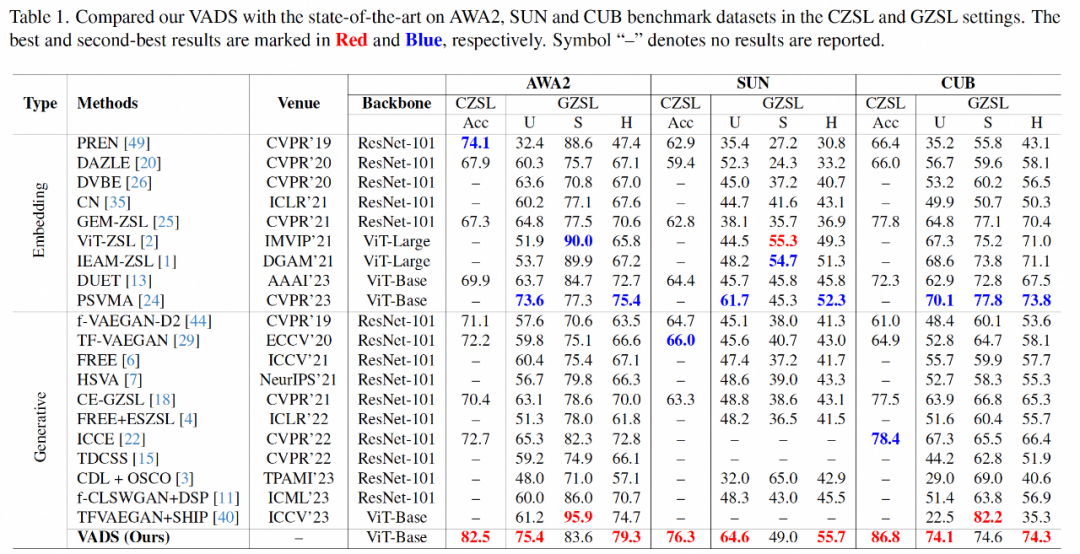
在傳統零樣本學習的 Acc 指標方面,該研究的方法與已有方法相比,取得了明顯的精度提升,在三個數據集上分別領先 8.4%,10.3% 和 8.4%。在廣義零樣本學習場景,上述研究方法在未見類和已見類精度的調和平均值指標 H 上也處于領先地位。
VADS 方法還可以與其他生成式零樣本學習方法結合。例如,與 CLSWGAN,TF-VAEGAN 和 FREE 這三種方法結合后,在三個數據集上的 Acc 和 H 指標均有明顯提升,三個數據集的平均提升幅度為 7.4%/5.9%, 5.6%/6.4% 和 3.3%/4.2%。

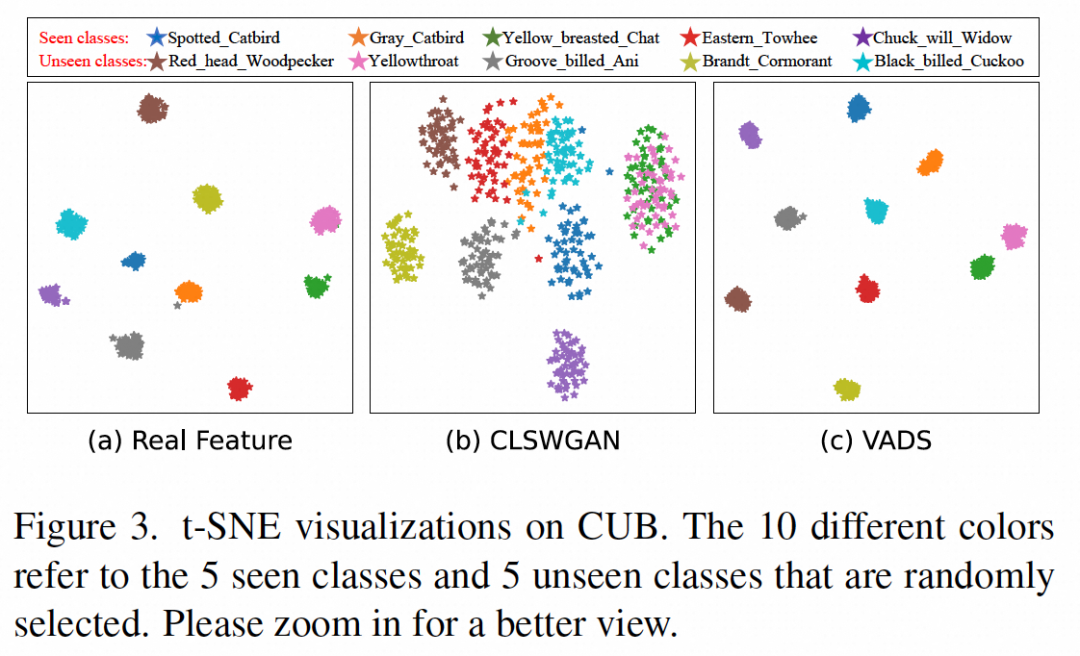
通過對生成器生成的視覺特征進行可視化可以看出,原本混淆在一起的部分類別的特征,例如下圖 (b) 中顯示的已見類「Yellow breasted Chat」和未見類「Yellowthroat」兩類特征,在使用 VADS 方法后,在圖(c)中能夠被明顯地分離為兩個類簇,從而避免了分類器訓練時的混淆。
可延展到智能安防和大模型領域
機器之心了解到,上述研究研究團隊關注的零樣本學習旨在使模型能夠識別在訓練階段沒有圖像樣本的新類別,在智能安防領域具有潛在的價值。
第一,處理安防場景中新出現的風險,由于安防場景下,會不斷出現新的威脅類型或不尋常的行為模式,它們可能在之前的訓練數據中未曾出現。零樣本學習使安防系統能快速識別和響應新風險類型,從而提高安全性。
第二,減少對樣本數據的依賴:獲取足夠的標注數據來訓練有效的安防系統是昂貴和耗時的,零樣本學習減少了系統對大量圖像樣本的依賴,從而節約了研發成本。
第三,提升動態環境下的穩定性:零樣本學習使用語義描述實現對未見類模式的識別,與完全依賴圖像特征的傳統方法相比,對于視覺環境的變化天然具有更強的穩定性。
該技術作為解決圖像分類問題的底層技術,還可以在依賴視覺分類技術的場景落地,例如人、貨、車、物的屬性識別,行為識別等。尤其在需要快速增加新的待識別類別,來不及收集訓練樣本,或者難以收集大量樣本的場景(如風險識別),零樣本學習技術相對于傳統方法具有較大優勢。
該研究技術對于當前大模型的發展有無借鑒之處?
研究者認為,生成式零樣本學習的核心思想是對齊語義空間和視覺特征空間,這與當前多模態大模型中的視覺語言模型(如 CLIP)的研究目標是一致的。
它們最大的不同點是,生成式零樣本學習是在預先定義好的有限類別的數據集上訓練和使用,而視覺語言大模型則是通過對大數據的學習獲得具有通用性的語義和視覺表征能力,不局限在有限的類別,作為基礎模型,具有更寬廣的應用范圍。
如果技術的應用場景是特定領域,可以選擇將大模型針對此領域進行適配微調,在此過程中,與本文相同或相似研究方向的工作,理論上可以帶來一些有益的啟發。
作者介紹
侯文金,華中科技大學碩士研究生,感興趣的研究方向包括計算機視覺,生成建模,少樣本學習等,他在阿里巴巴 - 銀泰商業實習期間完成了本論文工作。
王炎,阿里巴巴 - 銀泰商業技術總監,深象智能團隊算法負責人。
馮雪濤,阿里巴巴 - 銀泰商業資深算法專家,主要關注視覺和多模態算法在線下零售等行業的應用落地。



























