一個開發者自述:我是如何設計針對冷熱讀寫場景的 RocketMQ 存儲系統
作者 | Ninety Percent
一、悸動
32 歲,碼農的倒數第二個本命年,平淡無奇的生活總覺得缺少了點什么。
想要去創業,卻害怕家庭承受不住再次失敗的挫折,想要生二胎,帶娃的壓力讓我想著還不如去創業;所以我只好在生活中尋找一些小感動,去看一些老掉牙的電影,然后把自己感動得稀里嘩啦,去翻一些泛黃的書籍,在回憶里尋找一絲絲曾經的深情滿滿;去學習一些冷門的知識,最后把自己搞得暈頭轉向,去參加一些有意思的比賽,撿起那 10 年走來,早已被刻在基因里的悸動。
那是去年夏末的一個傍晚,我和同事正閑聊著西湖的美好,他們說看到了阿里云發布云原生編程挑戰賽,問我要不要試試。我說我只有九成的把握,另外一成得找我媳婦兒要;那一天,我們繞著西湖走了好久,最后終于達成一致,Ninety
Percent 戰隊應運而生,云原生 MQ 的賽道上,又多了一個艱難卻堅強的選手。
人到中年,仍然會做出一些沖動的決定,那種屁股決定腦袋的做法,像極了領導們的睿智和 18 歲時我朝三暮四的日子;夏季的 ADB 比賽,已經讓我和女兒有些疏遠,讓老婆對我有些成見;此次參賽,必然是要暗度陳倉,臥薪嘗膽,不到關鍵時刻,不能讓家里人知道我又在賣肝。
二、開工
你還別說,或許是人類的本性使然,這種背著老婆偷偷干壞事情的感覺還真不錯,從上路到上分,一路順風順水,極速狂奔;斷斷續續花了大概兩天的時間,成功地在 A 榜拿下了 first blood;再一次把第一名和最后一名同時納入囊中;快男總是不會讓大家失望了,800 秒的成績,成為了比賽的 base line。
第一個版本并沒有做什么設計,基本上就是拍腦門的方案,目的就是把流程跑通,盡快出分,然后在保證正確性的前提下,逐步去優化方案,避免一開始就過度設計,導致遲遲不能出分,影響士氣。
三、整體設計
先回顧下賽題:Apache RocketMQ 作為一款分布式的消息中間件,歷年雙十一承載了萬億級的消息流轉,其中,實時讀取寫入數據和讀取歷史數據都是業務常見的存儲訪問場景,針對這個混合讀寫場景進行優化,可以極大的提升存儲系統的穩定性。

基本思路是:當 append 方法被調用時,會將傳入的相關參數包裝成一個 Request 對象,put 到請求隊列中,然后當前線程進入等待狀態。
聚合線程會循環從請求隊列里面消費 Request 對象,放入一個列表中,當列表長度到達一定數量時,就將該列表放入到聚合隊列中。這樣在后續的刷盤線程中,列表中的多個請求,就能進行一次性刷盤了,增大刷盤的數據塊的大小,提升刷盤速度;當刷盤線程處理完一個請求列表的持久化邏輯之后,會依次對列表中個各個請求進行喚醒操作,使等待的測評線程進行返回。

1.內存級別的元數據結構設計

首先用一個二維數組來存儲各個 topicId+queueId 對應的 DataMeta 對象,DataMeta 對象里面有一個 MetaItem 的列表,每一個 MetaItem 代表的一條消息,里面包含了消息所在的文件下標、文件位置、數據長度、以及緩存位置。
2.SSD 上數據的存儲結構

總共使用了 15 個 byte 來存儲消息的元數據,消息的實際數據和元數據放在一起,這種混合存儲的方式雖然看起來不太優雅,但比起獨立存儲,可以減少一半的 force 操作。
3.數據恢復
依次遍歷讀取各個數據文件,按照上述的數據存儲協議生成內存級別的元數據信息,供后續查詢時使用。
4.數據消費
數據消費時,通過 topic+queueId 從二維數組中定位到對應的 DataMeta 對象,然后根據 offset 和 fetchNum,從 MetaItem 列表中找到對應的 MetaItem 對象,通過 MetaItem 中所記錄的文件存儲信息,進行文件加載。
總的來說,第一個版本在大方向上沒有太大的問題,使用 queue 進行異步聚合和刷盤,讓整個程序更加靈活,為后續的一些功能擴展打下了很好的基礎。
四、緩存
60 個 G的 AEP,我垂涎已久,國慶七天,沒有出遠門的計劃,一定要好好卷一卷 llpl。下載了 llpl 的源碼,一頓看,發現比我想象的要簡單得多,本質上和用 unsafe 訪問普通內存是一模一樣的。卷完 llpl,緩存設計方案呼之欲出。
1.緩存分級
緩存的寫入用了隊列進行異步化,避免對主線程造成阻塞(到比賽后期才發現云 SSD 的奧秘,就算同步寫也不會影響整體的速度,后面我會講原因);程序可以用作緩存的存儲介質有 AEP 和 Dram,兩者在訪問速度上有一定的差異,賽題所描述的場景中,會有大量的熱讀,因此我對緩存進行了分級,分為了 AEP 緩存和 Dram 緩存,Dram 緩存又分為了堆內緩存、堆外緩存、MMAP 緩存(后期加入),在申請緩存時,優先使用 Dram 緩存,提升高性能緩存的使用頻度。
Dram 緩存最后申請了 7G,AEP 申請了 61G,Dram 的容量占比為 10%;本次比賽總共會讀取(61+7)/2+50=84G 的數據,根據日志統計,整個測評過程中,有 30G 的數據使用了 Dram 緩存,占比 35%;因為前 75G 的數據不會有讀取操作,沒有緩存釋放與復用動作,所以嚴格意義上來講,在寫入與查詢混合操作階段,總共使用了 50G 的緩存,其中滾動使用了 30-7/2=26.5G 的 Dram 緩存,占比 53%。10%的容量占比,卻滾動提供了 53%的緩存服務,說明熱讀現象非常嚴重,說明緩存分級非常有必要。
但是,現實總是殘酷的,這些看似無懈可擊的優化點在測評中作用并不大,畢竟這種優化只能提升查詢速度,在讀寫混合階段,讀緩存總耗時是 10 秒或者是 20 秒,對最后的成績其實沒有任何影響!很神奇吧,后面我會講原因。
2.緩存結構

當獲取到一個緩存請求后,會根據 topic+queueId 從二維數組中獲取到對應的緩存上下文對象;該對象中維護了一個緩存塊列表、以及最后一個緩存塊的寫入指針位置;如果最后一個緩存塊的余量足夠放下當前的數據,則直接將數據寫入緩存塊;如果放不下,則申請一個新的緩存塊,放在緩存塊列表的最后,同時將寫不下的數據放到新緩存塊中;若申請不到新的緩存塊,則直接按緩存寫入失敗進行處理。
在寫完緩存后,需要將緩存的位置信息回寫到內存中的Meta中;比如本條數據是從第三個緩存塊中的 123B 開始寫入的,則回寫的緩存位置為:(3-1)*每個緩存塊的大小+123。在讀取緩存數據時,按照 meta 數據中的緩存位置新,定位到對應的緩存塊、以及塊內位置,進行數據讀取(需要考慮跨塊的邏輯)。
由于緩存的寫入是單線程完成的,對于一個 queueId,前面的緩存塊的消息一定早于后面的緩存塊,所以當讀取完緩存數據后,就可以將當前緩存塊之前的所有緩存都釋放掉(放入緩存資源池),這樣 75G 中被跳過的那 37.5G 的數據也能快速地被釋放掉。
緩存功能加上去后,成績來到了 520 秒左右,程序的主體結構也基本完成了,接下來就是精裝了。
五、優化
1.緩存準入策略
一個 32k 的緩存塊,是放 2 個 16k 的數據合適,還是放 16 個 2k 的數據合適?毫無疑問是后者,將小數據塊盡量都放到緩存中,可以使得最后只有較大的塊才會查 ssd,減少查詢時 ssd 的 io 次數。
那么閾值為多少時,可以保證小于該閾值的數據塊放入緩存,能夠使得緩存剛好被填滿呢?(若不填滿,緩存利用率就低了,若放不下,就會有小塊的數據無法放緩存,讀取時必須走 ssd,io 次數就上去了)。
一般來說,通過多次參數調整和測評嘗試,就能找到這個閾值,但是這種方式不具備通用性,如果總的可用的緩存大小出現變化,就又需要進行嘗試了,不具備生產價值。
這個時候,中學時代的數學知識就派上用途了,如下圖:

由于消息的大小實際是以 100B 開始的,為了簡化,直接按照從 0B 進行了計算,這樣會導致算出來的閾值偏大,也就是最后會出現緩存存不下從而小塊走 ssd 查詢的情況,所以我在算出來的閾值上減去了 100B*0.75(由于影響不大,基本是憑直覺拍腦門的)。如果要嚴格計算真正準確的閾值,需要將上圖中的三角形面積問題,轉換成梯形面積問題,但是感覺意義不大,因為 100B 本來就只有 17K 的 1/170,比例非常小,所以影響也非常的小。
梯形面積和三角形面積的比為:(17K+100)(17K-100)/(17k17K)=0.999965,完全在數據波動的范圍之內。
在程序運行時,根據動態計算出來的閾值,大于該閾值的就直接跳過緩存的寫入邏輯,最后不管緩存配置為多大,都能保證小于該閾值的數據塊全部寫入了緩存,且緩存最后的利用率達到 99.5%以上。
2.共享緩存
在剛開始的時候,按照算出來的閾值進行緩存規劃,仍然會出現緩存容量不足的情況,實際用到的緩存的大小總是比總緩存塊的大小小一些,通過各種排查,才恍然大悟,每個 queueId 所擁有的最后一個緩存塊大概率是不會被寫滿的,宏觀上來說,平均只會被寫一半。一個緩存塊是32k,queueId 的數量大概是 20w,那么就會有 20w*32k/2=3G 的緩存沒有被用到;3G/2=1.5G(前 75G 之后隨機讀一半,所以要除以 2),就算是順序讀大塊,1.5G 也會帶來 5 秒左右的耗時,更別說隨機讀了,所以不管有多復雜,這部分緩存一定要用起來。
既然自己用不完,那就共享出來吧,整體方案如下:

在緩存塊用盡時,對所有的 queueId 的最后一個緩存塊進行自增編號,然后放入到一個一維數組中,緩存塊的編號,即為該塊在以為數字中的下標;然后根據緩存塊的余量大小,放到對應的余量集合中,余量大于等于
2k 小于 3k 的緩存塊,放到 2k 的集合中,以此類推,余量大于最大消息體大小(賽題中為 17K)的塊,統一放在 maxLen 的集合中。
當某一次緩存請求獲取不到私有的緩存塊時,將根據當前消息體的大小,從共享緩存集合中獲取共享緩存進行寫入。比如當前消息體大小為 3.5K,將會從 4K 的集合中獲取緩存塊,若獲取不到,則繼續從 5k 的集合中獲取,依次類推,直到獲取到共享緩存塊,或者沒有滿足任何滿足條件的緩存塊為止。
往共享緩存塊寫入緩存數據后,該緩存塊的余量將發生變化,需要將該緩存塊從之前的集合中移除,然后放入新的余量集合中(若余量級別未發生變化,則不需要執行該動作)。
訪問共享緩存時,會根據Meta中記錄的共享緩存編號,從索引數組中獲取到對應的共享塊,進行數據的讀取。
在緩存的釋放邏輯里,會直接忽略共享緩存塊(理論上可以通過一個計數器來控制何時該釋放一個共享緩存塊,但實現起來比較復雜,因為要考慮到有些消息不會被消費的情況,且收益也不會太大(因為二階段緩存是完全夠用的,所以就沒做嘗試)。
3.MMAP 緩存
測評程序的 jvm 參數不允許選手自己控制,這是攔在選手面前的一道障礙,由于老年代和年輕代之間的比例為 2 比 1,那意味著如果我使用 3G 來作為堆內緩存,加上內存中的 Meta 等對象,老年代基本要用 4G 左右,那就會有 2G 的新生代,這完全是浪費,因為該賽題對新生代要求并不高。
所以為了避免浪費,一定要減少老年代的大小,那也就意味著不能使用太多的堆內緩存;由于堆外內存也被限定在了 2G,如果減小堆內的使用量,那空余的緩存就只能給系統做 pageCache,但賽題的背景下,pageCache 的命中率并不高,所以這條路也是走不通的。
有沒有什么內存既不是堆內,申請時又不受堆外參數的限制?自然而然想到了 unsafe,當然也想到官方導師說的那句:用 unsafe 申請內存直接取消成績。。。這條路只好作罷。
花了一個下午的時間,通讀了 nio 相關的代碼,意外發現 MappedByteBuffer 是不受堆外參數的限制的,這就意味著可以使用 MappedByteBuffer 來替代堆內緩存;由于緩存都會頻繁地被進行寫與讀,如果使用 Write_read 模式,會導致刷盤動作,就得不償失了,自然而然就想到了 PRIVATE 模式(copy on write),在該模式下,會在某個 4k 區首次寫入數據時,和 pageCache 解耦,生成一個獨享的內存副本;所以只要在程序初始化的時候,將 mmap 寫一遍,就能得到一塊獨享的,和磁盤無關的內存了。
所以我將堆內緩存的大小配置成了 32M(因為該功能已經開發好了,所以還是要意思一下,用起來),堆外申請了 1700M(算上測評代碼的 300M,差不多 2G)、mmap 申請了 5G;總共有 7G 的 Dram 作為了緩存(不使用 mmap 的話,大概只能用到 5G),內存中的Meta大概有700M左右,所以堆內的內存差不多在 1G 左右,2G+5G+1G=8G,操作系統給 200M 左右基本就夠了,所以還剩 800M 沒用,這800M其實是可以用來作為 mmap 緩存的,主要是考慮到大家都只能用 8G,超過 8G 容易被挑戰,所以最后最優成績里面總的內存的使用量并沒有超過 8G。
4.基于末尾填補的 4K 對齊
由于 ssd 的寫入是以 4K 為最小單位的,但每次聚合的消息的總大小又不是 4k 的整數倍,所以這會導致每次寫入都會有額外的開銷。
比較常規的方案是進行 4k 填補,當某一批數據不是 4k 對齊時,在末尾進行填充,保證寫入的數據的總大小是 4k 的整數倍。聽起來有些不可思議,額外寫入一些數據會導致整體效益更高?
是的,推導邏輯是這樣的:“如果不填補,下次寫入的時候,一定會寫這未滿的4k區,如果填補了,下次寫入的時候,只有 50%的概率會往后多寫一個 4k 區(因為前面填補,導致本次數據后移,尾部多垮了一個 4k 區)”,所以整體來說,填補后會賺 50%。或者換一個角度,填補對于當前的這次寫入是沒有副作用的(也就多 copy<4k 的數據),對于下一次寫入也是沒有副作用的,但是如果下一次寫入是這種情況,就會因為填補而少寫一個 4k。

5.基于末尾剪切的 4k 對齊
填補的方案確實能帶來不錯的提升,但是最后落盤的文件大概有 128G 左右,比實際的數據量多了 3 個 G,如果能把這 3 個 G 用起來,又是一個不小的提升。
自然而然就想到了末尾剪切的方案,將尾部未 4k 對齊的數據剪切下來,放到下一批數據里面,剪切下來的數據對應的請求,也在下一批數據刷盤的時候進行喚醒。
方案如下:

6.填補與剪切共
剪切的方案固然優秀,但在一些極端的情況下,會存在一些消極的影響;比如聚合的一批數據整體大小沒有操作 4k,那就需要扣留整批的請求了,在這一刻,這將變向導致刷盤線程大幅降低、請求線程大幅降低;對于這種情況,剪切對齊帶來的優勢,無法彌補扣留請求帶來的劣勢(基于直觀感受),因此需要直接使用填補的方式來保證 4k 對齊。
嚴格意義上來講,應該有一個扣留線程數代價、和填補代價的量化公式,以決定何種時候需要進行填補,何種時候需要進行剪切;但是其本質太過復雜,涉及到非同質因子的整合(要在磁盤吞吐、磁盤 io、測評線程耗時三個概念之間做轉換);做了一些嘗試,效果都不是很理想,沒能跑出最高分。
當然中間還有一些邊界處理,比如當 poll 上游數據超時的時候,需要將扣留的數據進行填充落盤,避免收尾階段,最后一批扣留的數據得不到處理。
7.SSD 的預寫
得此優化點者,得前 10,該優化點能大幅提升寫入速度(280m/s 到 320m/s),這個優化點很多同學在一些技術貼上看到過,或者自己意外發現過,但是大部分人應該對本質的原因不甚了解;接下來我便循序漸進,按照自己的理解進行 yy 了。
假設某塊磁盤上被寫滿了 1,然后文件都被刪除了,這個時候磁盤上的物理狀態肯定都還是 1(因為刪除文件并不會對文件區域進行格式化)。然后你又新建了一個空白文件,將文件大小設置成了 1G(比如通過 RandomAccessFile.position(1G));這個時候這 1G 的區域對應的磁盤空間上仍然還是 1,因為在生產空白文件的時候也并不會對對應的區域進行格式化。
但是,當我們此時對這個文件進行訪問的時候,讀取到的會全是 0;這說明文件系統里面記載了,對于一個文件,哪些地方是被寫過的,哪些地方是沒有被寫過的(以 4k 為單位),沒被寫過的地方會直接返回 0;這些信息被記載在一個叫做 inode 的東西上,inode 當然也是需要落盤進行持久化的。
所以如果我們不預寫文件,inode 會在文件的某個 4k 區首次被寫入時發生性變更,這將造成額外的邏輯開銷以及磁盤開銷。因此,在構造方法里面一頓 for 循環,按照預估的總文件大小,先寫一遍數據,后續寫入時就能起飛了。
8.大消息體的優化策略
由于磁盤的讀寫都是以 4k 為單位,這就意味著讀取一個 16k+2B 的數據,極端情況下會產生 16k+2*4k=24k 的磁盤 io,會多加載將近 8k 的數據。
顯然如果能夠在讀取的時候都按 4k 對齊進行讀取,且加載出來的數據都是有意義的(后續能夠被用到),就能解決而上述的問題;我依次做了以下優化(有些優化點在后面被廢棄掉了,因為它和一些其他更好的優化點沖突了)。
(1)大塊置頂
由于每一批聚合的消息都是 4k 對齊的落盤的(剪切扣留方案之前),所以我將每批數據中最大的那條消息放在了頭部(基于緩存規劃策略,大消息大概率是不會進緩存的,消費時會從 ssd 讀取),這樣這條消息至少有一端是 4k 對齊的,讀取的時候能緩解 50%的對齊問題,該種方式在剪切扣留方案之前確實帶來了 3 秒左右的提升。
(2)消息順序重組
通過算法,讓大塊數據盡量少地出現兩端不對齊的情況,減少讀取時額外的數據加載量;比如針對下面的例子:

在整理之前,加載三個大塊總共會涉及到 8 個 4k 區,整理之后,就變成了 6 個。
由于自己在算法這一塊兒實在太弱了,加上這是一個 NP 問題,折騰了幾個小時,效果總是差強人意,最后只好放棄。
(3)基于內存的 pageCache
在數據讀取階段,每次加載數據時,若加載的數據兩端不是 4k 對齊的,就主動向前后延伸打到 4k 對齊的地方;然后將首尾兩個 4k 區放到內存里面,這樣當后續要訪問這些4k區的時候,就可以直接從內存里面獲取了。
該方案最后的效果和預估的一樣差,一點驚喜都沒有。因為只會有少量的數據會走 ssd,首尾兩個 4k 里面大概率都是那些不需要走ssd的消息,所以被復用的概率極小。
(4)部分緩存
既然自己沒能力對消息的存儲順序進行調整優化,那就把那些兩端不對齊的數據剪下來放到緩存里面吧:

某條消息在落盤的時候,若某一端(也有可能是兩端)沒有 4k 對齊,且在未對齊的 4k 區的數據量很少,就將其剪切下來存放到緩存里,這樣查詢的時候,就不會因為這少量的數據,去讀取一個額外的 4k 區了。
剪切的閾值設置成了 1k,由于數據大小是隨機的,所以從宏觀上來看,剪切下來的數據片的平均大小為 0.5k,這意味著只需要使用 0.5k 的緩存,就能減少 4k 的 io,是常規緩存效益的 8 倍,加上緩存部分的余量分級策略,會導致有很多碎片化的小內存用不到,該方案剛好可以把這些碎片內存利用起來。
9.測評線程的聚合策略
每次聚合多少條消息進行刷盤合適?是按消息條數進行聚合,還是按照消息的大小進行聚合?
剛開始的時候并沒有想那么多,通過日志得知總共有 40 個線程,所以就寫死了一次聚合 10 條,然后四個線程進行刷盤;但這會帶來兩個問題,一個是若線程數發生變化,性能會大幅下降;第二是在收尾階段,會有一些跑得慢的線程還有不少數據未寫入的情況,導致收尾時間較長,特別是加入了尾部剪切與扣留邏輯后,該現象尤為嚴重。
為了解決收尾耗時長的問題,我嘗試了同步聚合的方案,在第一次寫入之后的 500ms,對寫入線程數進行統計,然后分組,后續就按組進行聚合;這種方式可以完美解決收尾的問題,因為同一個組里面的所有線程都是同時完成寫入任務的,大概是因為每個線程的寫入次數是固定的吧;但是使用這種方式,尾部剪切+扣留的邏輯就非常難融合進來了;加上在程序一開始就固定線程數,看起來也有那么一些不優雅;所以我就引入了“線程控制器”的概念。

10.聚合策略迭代-針對剪切扣的留方案的定向優化
假設當前動態計算出來的聚合數量是 10,對于聚合出來的 10 條消息,如果本批次被扣留了 2 條,下次聚合時應該聚合多少條?
在之前的策略里面,還是會聚合 10 條,這就意味著一旦出現了消息扣留,聚合邏輯就會產生抖動,會出現某個線程聚合不到指定的消息數據量的情況(這種情況會有 poll 超時方式進行兜底,但是整體速度就慢了)。
所以聚合參數不能是一個單純的、統一化的值,得針對不同的刷盤線程的扣留數,進行調整,假設聚合數為 n,某個刷盤線程的上批次扣留數量為 m,那針對這個刷盤線程的下批次的聚合數量就應該是 n-m。
那么問題就來了,聚合線程(生產者)只有一個,刷盤線程(消費者)有好幾個,都是搶占式地進行消費,沒辦法將聚合到的特定數量的消息,給到指定的刷盤線程;所以聚合消息隊列需要拆分,拆分成以刷盤線程為維度。
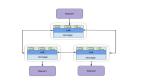
由于改動比較大,為了保留以前的邏輯,就引入了聚合數量的“嚴格模式”的概念,通過參數進行控制,如果是“嚴格模式”,就使用上述的邏輯,若不是,則使用之前的邏輯;設計圖如下:

將聚合隊列換成了聚合隊列數組,在非嚴格模式下,數組里面的原始指向的是同一個隊列對象,這樣很多代碼邏輯就能統一。
聚合線程需要先從扣留信息隊列里面獲取一個對象,然后根據扣留數和最新的聚合參數,決定要聚合多少條消息,聚合好消息后,放到扣留信息所描述的隊列中。
六、完美的收尾策略,一行代碼帶來 5s 的提升
引入了線程控制器后,收尾時間被降低到了 2 秒多,兩次收尾,也就是 5 秒左右(這些信息來源于最后一個晚上對 A 榜時的日志的分析),在賽點位置上,這 5 秒的重要性不言而喻。
比賽結束前的最后一晚,分數徘徊在了 423 秒左右,前面的大佬在很多天前就從 430 一次性優化到了 420,然后分數就沒有太大變化了;我當時抱著僥幸的態度,斷定應該是 hack 了,直到那天晚上在釘釘群里和他聊了幾句,直覺告訴我,420
的成績是有效的。當時是有些慌的,畢竟比賽第二天早上 10 點就結束了。
我開始陷入深深的反思,我都卷到極致了,從 432 到 423 花費了大量的精力,為何大神能夠一擊致命?不對,一定是我忽略了什么。
我開始回看歷史提交記錄,然后對照分析每次提交后的測評得分(由于歷史成績都有一定的抖動,所以這個工作非常的上頭);花費了大概兩個小時,總算發現了一個異常點,在 432 秒附近的時候,我從同步聚合切換成了異步聚合,然后融合了剪切扣留+4k 填補的方案,按理說這個優化能減少 3G 多的落盤數據量,成績應該是可以提升 10 秒左右的,但是當時成績只提升了 5 秒多,由于當時還有不少沒有落地的優化點,所以就沒有太在意。
扣留策略會會將尾部的請求扣留下來,尾部的請求本來就是慢一拍(對應的測評線程慢)的請求(隊列是順序消費),這一扣留,進度就更慢了!!!
聚合到一批消息后,按照消息對應的線程被扣留的次數,從大到小排個序,讓那些慢的、扣留多的線程,盡可能不被扣留,讓那些快的、扣留少的請求,盡可能被扣留;最后所有的線程幾乎都是同時完成(基于假想)。
趕緊提交代碼、開始測評,抖了兩把就破 420 了,最好成績到達了 418,比優化前高出 5 秒左右,非常符合預期.
1.查詢優化
- 多線程讀 ssd
由于只有少量的數據會讀 ssd,這使得在讀寫混合階段,sdd 查詢的并發量并不大,所以在加載數據時進行了判斷,如果需要從 ssd 加載的數量大于一定量時,則進行多線程加載,充分利用 ssd 并發隨機讀的能力。
為什么要大于一定的量才多線程加載,如果只需要加載兩條數據,用兩個線程來加載會有提升嗎?當存儲介質夠快、加載的數據量夠小時,多線程加載數據帶來的 io 時間的提升,還不足以彌補多線程執行本身帶來的程序開銷。
2.緩存的批量 copy
若某次查詢時需要加載的數據,在緩存上是連續的,則不需要一條一條從緩存進行復制,可以以緩存塊的大小為最小粒度,進行復制,提升緩存讀取的效益。 ?
?

上面的例子中,使用批量 copy 的方式,可以將 copy 的次數從 5 次降到 2 次。
這樣做的前提是:用于返回的各條消息對應的 byteBuffer,在內存上需要是連續的(通過反射實現,給每個 byteBuffer 都注入同一個 bytes 對象);批量復制完畢后,根據各條消息的大小,動態設置各自 byteBuffer 的 position 和 limit,以保證 retain 區域剛好指向自己所對應的內存區間。
該功能一直有偶現的 bug,本地又復現不了,A 榜的時候沒太在意,B 榜的時候又不能看日志,一直沒得到解決;怕因為代碼質量影響最后的代碼分,所以后來就注釋掉了。
3遺失的美好
在比賽開始的時候,看了金融通的賽題解析,里面提到了一個對數據進行遷移的點;10 月中旬的時候進行了嘗試,在開始讀取數據時,陸續把那些緩存中沒有的數據讀取到緩存中(因為一旦開始讀取,就會有大量的緩存被釋放出來,緩存容量完全夠用),總共進行了兩個方案的嘗試:
(1)基于順序讀的異步遷移方案
在第一階段,當緩存用盡時,記錄當前存儲文件的位置,然后遷移的時候,從該位置開始進行順序讀取,將后續的所有數據都讀取到緩存中;這樣做的好處是大幅降低查詢階段的隨機讀次數;但是也有不足,因為前 75G 數據中有一般的數據是不會被消費的,這意味著遷移到緩存中的數據,有 50%都是沒有意義的,當時測下來該方案基本沒有提升(由于成績有一定的抖動,具體是有一部分提升、沒提升、還是負優化,也不得而知);后來引入了緩存準入策略后,該方案就徹底被廢棄了,因為需要從 ssd 中讀取的數據會完全散列在存儲文件中。
(2)基于懶加載的異步遷移方案
上面有講到,由于一階段的數據中有一半都不會被消費到,想要不做無用功,就必須要在保證遷移的數據都是會被消費的數據。
所以加了一個邏輯,當某個 queueId 第一次被消費的時候,就異步將該 queueId 中不存在緩存中的消息,從 ssd 中加載到緩存中;由于當時覺得就算是異步遷移,也是要隨機讀的,讀的次數并不會減少,一段時間內磁盤的壓力也并不會減少;所以對該方案就沒怎么重視,完全是抱著寫著玩的態度;并且在遷移的準入邏輯上加了一個判斷:“當本次查詢的消息中包含有從磁盤中加載的數據時,才異步對該 queueId 中剩下的 ssd 中的數據進行遷移”;至今我都沒相透當時自己為什么要加上這個一個判斷。也就是因為這個判斷,導致遷移效果仍然不理想(會導致遷移不夠集中、并且很多 queueId 在某次查詢的時候讀了 ssd,后續就沒有需要從 ssd 上讀取的數據了),對成績沒有明顯的提升;在一次版本回退中,徹底將遷移的方案給抹掉了(相信打比賽的小伙伴對版本回退深有感觸,特別是對于這種有較大成績抖動的比賽)。
比賽結束后我在想,如果當時在遷移邏輯上沒有加上那個神奇的邏輯判斷,我的成績能到多少?或許能到 410,或許突破不了 420;正式因為錯過了那個大的優化點,才讓我在其他點上做到了極致;那些錯過的美好,會讓大家在未來的日子里更加努力地奔跑。
接下來我們講一下為什么異步遷移會快。
ssd 的多線程隨機讀是很快的,但是我上面有講到,如果查詢的數據量比較小,多線程分批查詢效果并不一定就好,因為每一批的數據量實在太小了;所以想要在查詢階段開很多的線程來提升整體的查詢速度并不能取的很好的效果。異步遷移能夠完美地解決這個問題,并且在 io 次數一定的情況下,集中進行 ssd 的隨機讀,比散列進行隨機讀,pageCache 命中率更高,且對寫入速度造成的整體影響更小(這個觀點純屬個人感悟,只保證 Ninety Percent 的正確率)。
4.SSD 云盤的奧秘
我也是個小白,以下內容很多都是猜測,大家看一看就可以了。
(1)云 ssd 的運作機制
SSD 云盤和傳統的 ssd 盤擁有著相同的特性,但是卻是不同的東西;可以理解成 SSD 云盤,是傳統 ssd 盤的一個放大版。

SSD 云盤的底層存儲介質是多個普通的物理硬盤,這些物理硬盤就類似于傳統 ssd 中的存儲顆粒,在進行寫入或讀取的時候,會將任務分配到多個物理設備上并行進行處理。同時,在云 ssd 中,對數據的更新采用了 append 的方式,即在進行更新時,是順序追加寫一塊數據,然后將位置的引用從原有的數據塊指向新的數據塊(我們訪問的文件的position和硬盤的物理地址之間有一層映射,所以就算硬盤上有很多的碎片,我們也仍然能獲取到一個“連續”的大文件)。
阿里云官網上有云 ssd 的 iops 和吞吐的計算公式:
iops = min{1800+50 容量, 50000}; 吞吐= min{120+0.5 容量, 350}。
我們看到無論是 iops 和吞吐,都和容量呈正相關的關系,并且都有一個上限。這是因為,容量越大,底層的物理設備就會越多,并發處理的能力就越強,所以速度就越快;但是當物理設備多到一定的數量時,文件系統的“總控“就會成為瓶頸;這個總控肯定也是需要存儲能力的(比如存儲位置映射、歷史數據的 compact 等等),所以當給總控配置不同性能的存儲介質時,就得到了 PL0、PL1 等不同性能的云盤(當然,除此之外,網絡帶寬、運算能力也是云 ssd 速度的影響因子)。
(2)云 ssd 的 buffer 現象
在過程中發現了一個有趣的現象,就算是 force 落盤,在剛開始寫入時,速度也是遠大于 320m/s 的(能達到 400+),幾秒之后,會降下來,穩定在 320 左右(像極了不 force 時,pageCache 帶來的 buffer 現象)。
針對這種奇怪的現象,我進行了進一步的探索,每寫 2 秒的數據,就 sleep 2 秒,結果是:在寫入的這兩秒時間里,速度能達到 400+,整體平均速度也遠超過了 160m/s;后來我又做了很多實驗,包括在每次寫完數據之后直接進行短暫的 sleep,但是這根本不會影響到 320m/s 的整體速度。測試代碼中,雖然是 4 線程寫入,但是總會有那么一些時刻,大部分甚至所有線程都處于 sleep 狀態,這必然會使得在這個時間點上,應用程序到硬盤的寫入速度是極低的;但是時間拉長了看,這個速度又是能恒定在 320m/s 的。這說明云 ssd 上有一層 buffer,類似操作系統的 pageCache,只是這個“pageCache”是可靠存儲的,應用程序到這個 buffer 之間的速度是可以超過 320 的,320 的閾值,是下游所導致的(比如 buffer 到硬盤陣列)。
對于這個“pageCache”有幾種猜測:
- 物理設備本身就有 buffer 效應,因為物理設備的存儲狀態本質上是通過電刺激,改變存儲介質的化學狀態或者物理狀態的實現的,驅動這種變化的工業本質,產生了這種 buffer 現象‘;
- 云 ssd 里面有一塊較小的高性能存介質作為緩沖區,以提供更好的突擊寫的性能;
- 邏輯限速,哈哈,這個純屬開玩笑了。
由于有了這個 buffer 效應,程序層面就可以為所欲為了,比如寫緩存的動作,整體會花費幾十秒,但是就算是在只有 4 個寫入線程的情況下,不管是異步寫還是同步寫,都不會影響整體的落盤速度,因為在同步寫緩存的時候,云 ssd 能夠進行短暫的停歇,在接下來的寫入時,速度會短暫地超過 320m/s;查詢的時候也類似,非 io 以外的時間開銷,無論長短,都不會影響整體的速度,這也就是我之前提到的,批量復制緩存,理論上有不小提升,但是實際上卻沒多大提升的原因。
當然,這個 buffer 現象其實是可以利用起來的,我們可以在寫數據的時候多花一些時間來做一些其他的事情,反正這樣的時間開銷并不會影響整體的速度;比如我之前提到的 NP 問題,可以 for 循環暴力破解。