生產環境里的Kafka天天丟消息,老大逼著我通宵排查解決
一、背景引入
這篇文章,給大家聊一下寫入Kafka的數據該如何保證其不丟失?
我們暫且不考慮寫磁盤的具體過程,先大致看看下面的圖,這代表了Kafka的核心架構原理。
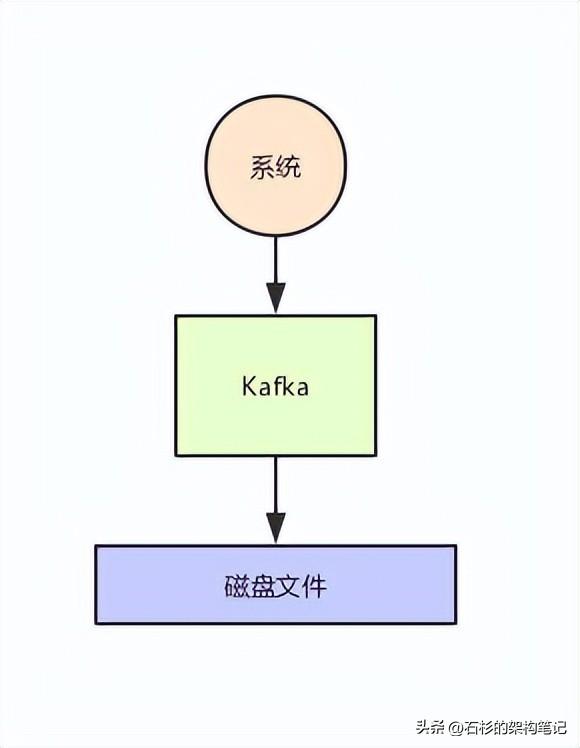
二、Kafka分布式存儲架構
那么現在問題來了,如果每天產生幾十TB的數據,難道都寫一臺機器的磁盤上嗎?這明顯是不靠譜的啊!
所以說,這里就得考慮數據的分布式存儲了,其實關于消息中間件的分布式存儲以及高可用架構,之前的一篇文章《想去BAT、美團、京東和字節面試?那你必須懂他們的面試套路!》也分析過了,但是這里,我們結合Kafka的具體情況來說說。
在Kafka里面,有一個核心的概念叫做“Topic”,這個topic你就姑且認為是一個數據集合吧。
舉個例子,如果你現在有一份網站的用戶行為數據要寫入Kafka,你可以搞一個topic叫做“user_access_log_topic”,這里寫入的都是用戶行為數據。
然后如果你要把電商網站的訂單數據的增刪改變更記錄寫Kafka,那可以搞一個topic叫做“order_tb_topic”,這里寫入的都是訂單表的變更記錄。
然后假如說咱們舉個例子,就說這個用戶行為topic吧,里面如果每天寫入幾十TB的數據,你覺得都放一臺機器上靠譜嗎?
明顯不太靠譜,所以Kafka有一個概念叫做Partition,就是把一個topic數據集合拆分為多個數據分區,你可以認為是多個數據分片,每個Partition可以在不同的機器上,儲存部分數據。
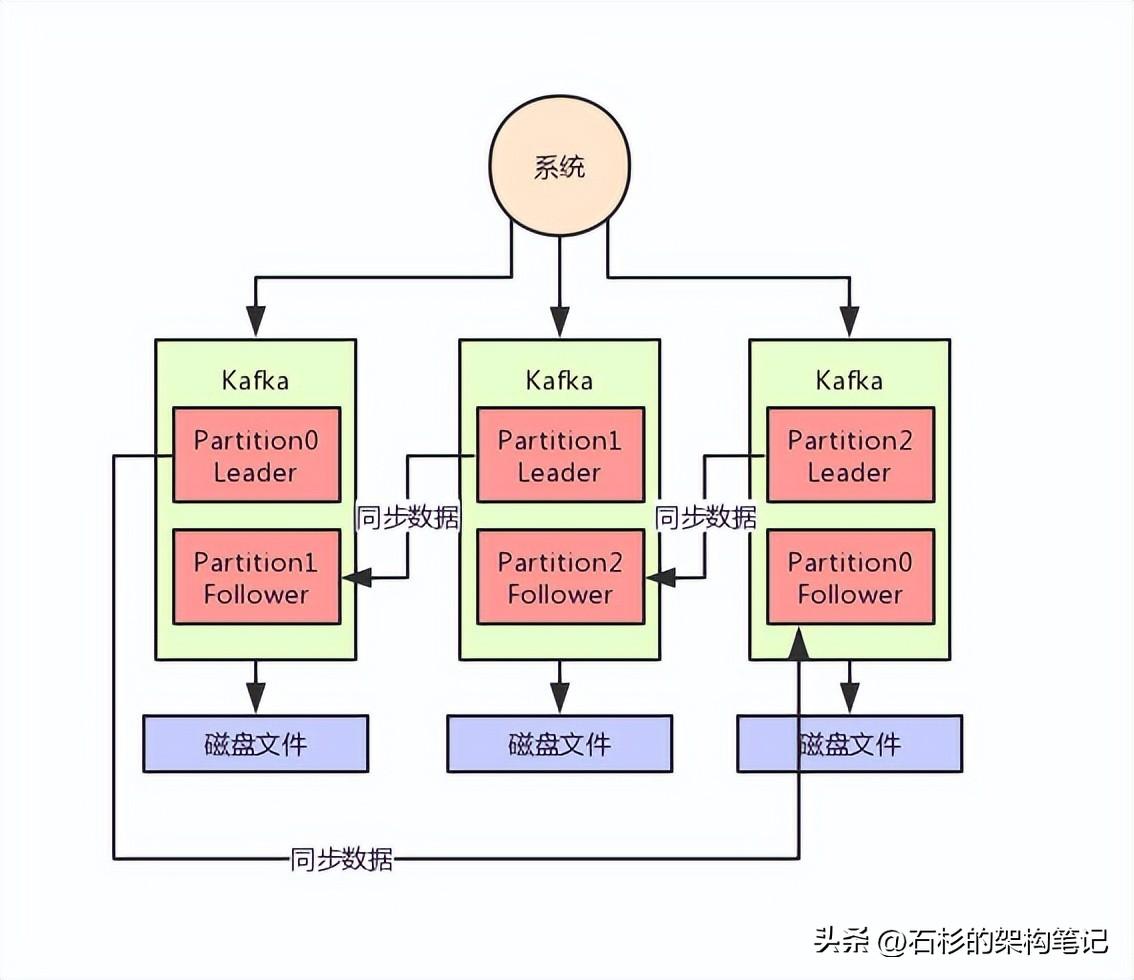
這樣,不就可以把一個超大的數據集合分布式存儲在多臺機器上了嗎?大家看下圖,一起來體會一下。
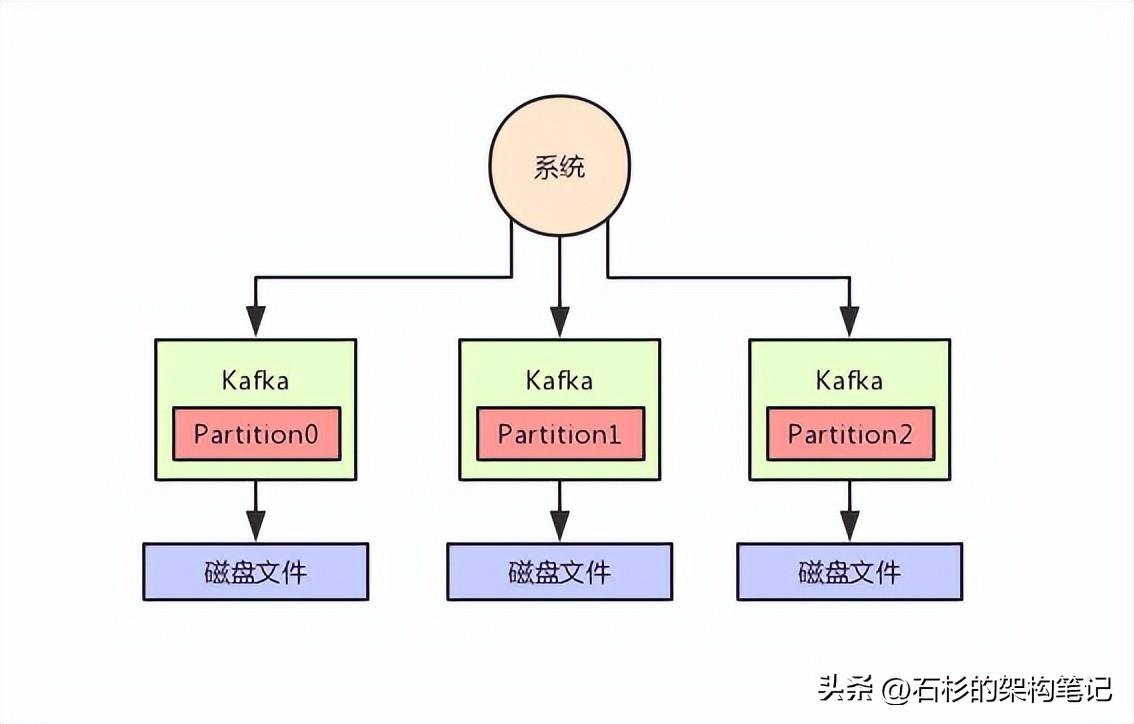
三、Kafka高可用架構
但是這個時候,我們又會遇到一個問題,就是萬一某臺機器宕機了,這臺機器上的那個partition管理的數據不就丟失了嗎?
所以說,我們還得做多副本冗余,每個Partition都可以搞一個副本放在別的機器上,這樣某臺機器宕機,只不過是Partition其中一個副本丟失。
如果某個Partition有多副本的話,Kafka會選舉其中一個Parititon副本作為Leader,然后其他的Partition副本是Follower。
只有Leader Partition是對外提供讀寫操作的,Follower Partition就是從Leader Partition同步數據。
一旦Leader Partition宕機了,就會選舉其他的Follower Partition作為新的Leader Partition對外提供讀寫服務,這不就實現了高可用架構了?
大家看下面的圖,看看這個過程。
四、Kafka寫入數據丟失問題
現在我們來看看,什么情況下Kafka中寫入數據會丟失呢?
其實也很簡單,大家都知道寫入數據都是往某個Partition的Leader寫入的,然后那個Partition的Follower會從Leader同步數據。
但是萬一1條數據剛寫入Leader Partition,還沒來得及同步給Follower,此時Leader Partiton所在機器突然就宕機了呢?
大家看下圖:
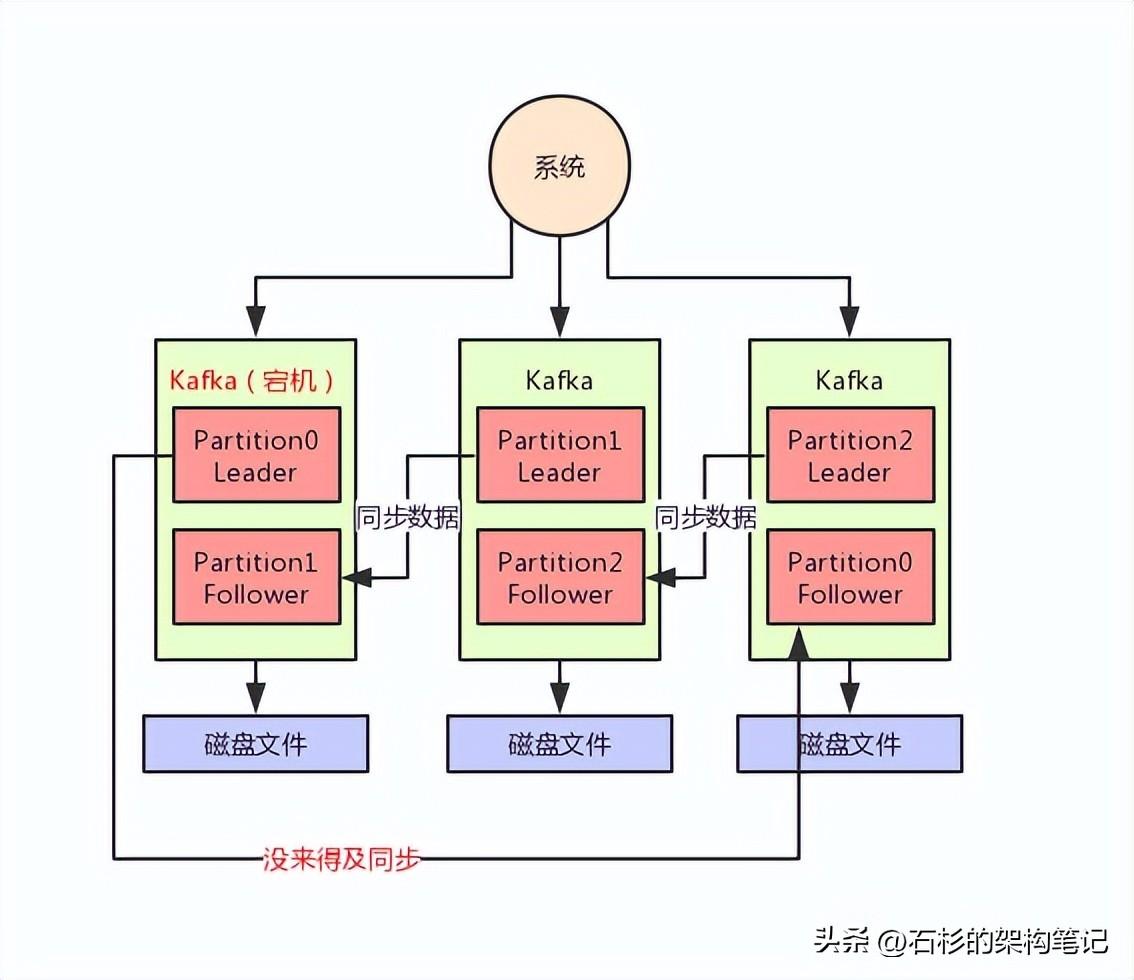
如上圖,這個時候有一條數據是沒同步到Partition0的Follower上去的,然后Partition0的Leader所在機器宕機了。
此時就會選舉Partition0的Follower作為新的Leader對外提供服務,然后用戶是不是就讀不到剛才寫入的那條數據了?
因為Partition0的Follower上是沒有同步到最新的一條數據的。
這個時候就會造成數據丟失的問題。
五、Kafka的ISR機制是什么?
現在我們先留著這個問題不說具體怎么解決,先回過頭來看一個Kafka的核心機制,就是ISR機制。
這個機制簡單來說,就是會自動給每個Partition維護一個ISR列表,這個列表里一定會有Leader,然后還會包含跟Leader保持同步的Follower。
也就是說,只要Leader的某個Follower一直跟他保持數據同步,那么就會存在于ISR列表里。
但是如果Follower因為自身發生一些問題,導致不能及時的從Leader同步數據過去,那么這個Follower就會被認為是“out-of-sync”,從ISR列表里踢出去。
所以大家先得明白這個ISR是什么,說白了,就是Kafka自動維護和監控哪些Follower及時的跟上了Leader的數據同步。
六、數據如何保證不丟失?
所以如果要讓寫入Kafka的數據不丟失,你需要要求幾點:
每個Partition都至少得有1個Follower在ISR列表里,跟上了Leader的數據同步
每次寫入數據的時候,都要求至少寫入Partition Leader成功,同時還有至少一個ISR里的Follower也寫入成功,才算這個寫入是成功了
如果不滿足上述兩個條件,那就一直寫入失敗,讓生產系統不停的嘗試重試,直到滿足上述兩個條件,然后才能認為寫入成功
按照上述思路去配置相應的參數,才能保證寫入Kafka的數據不會丟失
好!現在咱們來分析一下上面幾點要求。
第一條,必須要求至少一個Follower在ISR列表里。
那必須的啊,要是Leader沒有Follower了,或者是Follower都沒法及時同步Leader數據,那么這個事兒肯定就沒法弄下去了。
第二條,每次寫入數據的時候,要求leader寫入成功以外,至少一個ISR里的Follower也寫成功。
大家看下面的圖,這個要求就是保證說,每次寫數據,必須是leader和follower都寫成功了,才能算是寫成功,保證一條數據必須有兩個以上的副本。
這個時候萬一leader宕機,就可以切換到那個follower上去,那么Follower上是有剛寫入的數據的,此時數據就不會丟失了。
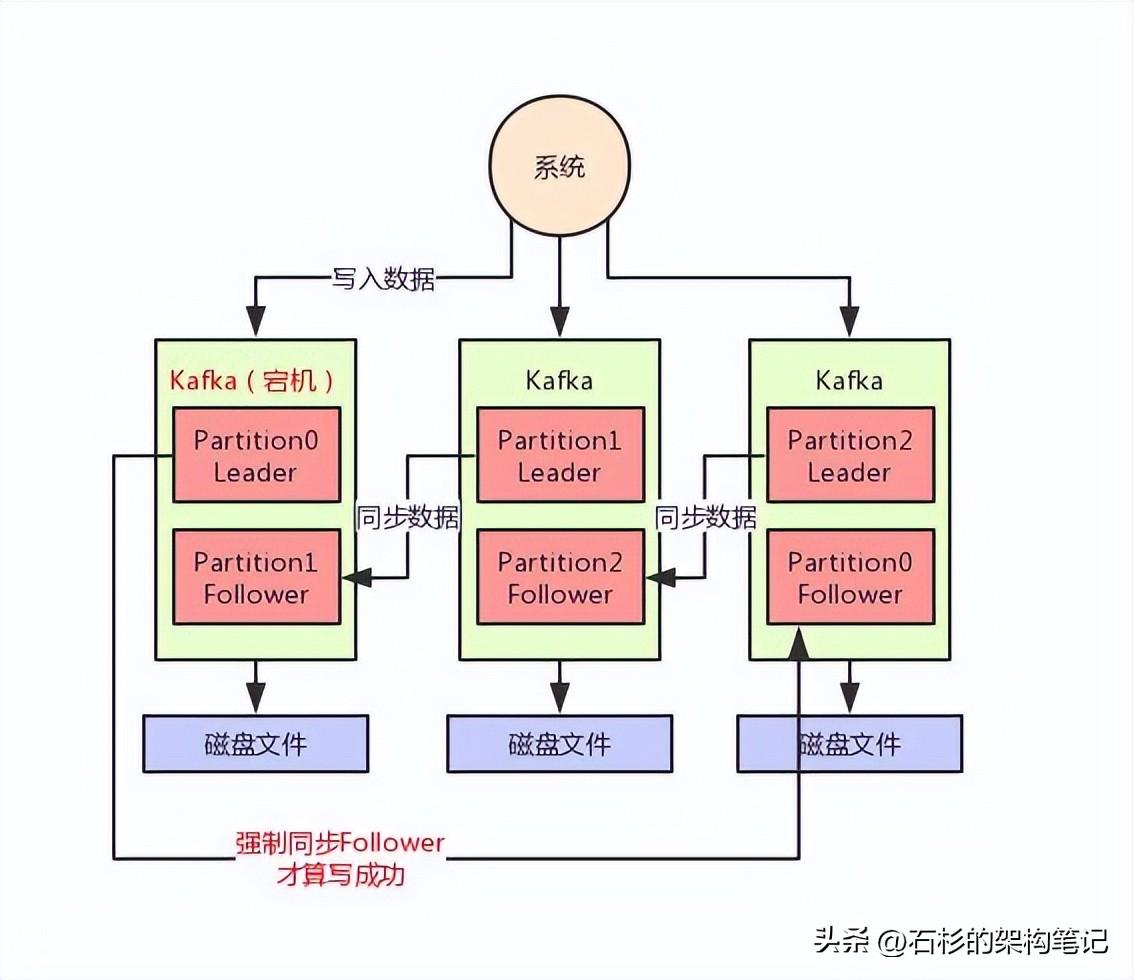
如上圖所示,假如現在leader沒有follower了,或者是剛寫入leader,leader立馬就宕機,還沒來得及同步給follower。
在這種情況下,寫入就會失敗,然后你就讓生產者不停的重試,直到kafka恢復正常滿足上述條件,才能繼續寫入。
這樣就可以讓寫入kafka的數據不丟失。
七、總結
最后總結一下,其實kafka的數據丟失問題,涉及到方方面面。
譬如生產端的緩存問題,包括消費端的問題,同時kafka自己內部的底層算法和機制也可能導致數據丟失。
但是平時寫入數據遇到比較大的一個問題,就是leader切換時可能導致數據丟失。所以本文僅僅是針對這個問題說了一下生產環境解決這個問題的方案。?