場景化、重實操,分享一個實時數倉實踐案例
?大部分數據團隊在進行實時業務建設的初期,都會出現煙囪式開發、一個任務搞定全部數據加工環節等問題,缺乏實時數據的管理和實時數倉分層建設的規范意識。隨著實時場景的進一步豐富,出現了實時數據復用、業務方自助進行實時取數等需求,因此要求數據團隊要像管理離線數據一樣對實時數據進行有規范的實時數倉管理。
本文將從一個實際業務場景和一個模擬數倉構建的案例來說明如何利用 EasyData 實時開發平臺來建設實時數倉。
1、實際業務場景
1.1 背景介紹
業務方是某移動 APP 的運營團隊,需求是要實時監控各類運營活動的 ABtest 的實驗效果,以便業務方根據實驗效果隨時調整運營投放策略、投放目標用戶和投放比例。
1.2 業務數據分層
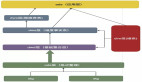
通常業務方的實時數據流轉鏈路包含實時數據采集、實時數據加工處理、實時數據落庫查詢等步驟,在此用戶的ABtest 場景中,數據加工鏈路如下圖所示:

第一步:用戶的日志數據經過實時采集寫入 ODS 層的 Kafka 中。ODS 層數據為原始未加工的業務數據,保存在 Kafka,7 天后自動清理。
第二步:ODS 層數據經過 Flink 任務處理寫入 DWD 層 Kafka 中。DWD 層數據為經過清洗的數據。
第三步:DWD 層數據經過 Flink 任務處理寫入 DWS 層 KUDU 數據庫中落庫。DWS 層數據為經過聚合、過濾等加工步驟,可以向業務方提供的數據。
第四步:業務方在需要時通過 Impala 查詢 KUDU 數據庫中的數據生成報表。
通過以上實時數據加工鏈路,業務方可實現實時報表展示,時效性較離線加工鏈路大大提高,可以滿足業務方要求數據實時更新的需求。
1.3 業務痛點
在這個業務場景中 ODS 層、DWD 層的 Kafka 數據在其他加工鏈路中也需要被復用,但在其他鏈路加工過程中,同樣的 Topic 需要不斷重復在不同任務中進行 Flink Table 的定義,每次定義用戶均需要使用 DDL 語句定義字段、表配置等,重復工作很多,同時在任務中進行表定義時,數據管理者無法感知哪些數據已被使用,也無法判斷是否有可以優化的數據流轉鏈路。
1.4 產品方案
EasyData 實時開發模塊中為用戶提供了實時流表登記和管理的功能,輔助用戶進行實時數倉的建設。實時流表是 EasyData 實時開發模塊中的特有概念。流表的內容為 Kafka,Rocketmq 等沒有明確 schema 的消息中間件的元數據。在平臺通過登記流表并在任務中直接引用流表的方式即可將這部分元數據進行復用。
同時在流表管理模塊中,用戶可以查看流表的定義。此外,按照業務方的數倉規范中的表命名規范登記流表后,可以根據流表的表名判斷流表的分層歸屬。在接下來的規劃中,數倉流表模塊將支持數據血緣查看、數據預覽、使用數據模型建表等功能,基于流表元數據進行更完整更易用的實時數倉管理。
在下方模擬案例介紹中,將為大家講解如何定義和使用流表,以及如何通過登記流表進行數倉建設。
2、案例場景介紹
業務目標:統計某 APP 實時訪問的 DAU,需要統計的值包括總 DAU,各設備類型 DAU(iPhone、華為、OPPO、其他)。
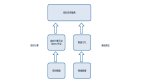
業務數據鏈路:

第一步:通過 CDC 任務采集用戶訪問數據數據實時變更至 Kafka(對應案例步驟第一步)
第二步:將 ODS 層 Kafka 數據通過 Flink 任務進行清洗和聚合,寫入 MySQL 落庫(對應案例步驟第二、三步)
第三步:將 MySQL 數據通過 BI 報表展示(對應案例最終結果)
3、案例操作步驟
3.1 準備階段:準備模擬數據
3.1.1 數據源準備
需準備用于實踐的 MySQL 數據源和 Kafka 數據源。
3.1.2 數據表準備
(1)準備 DS 層源端表:DAU_DS
此表用于記錄用戶訪問數據。表結構與樣例數據如下:

(2)準備 DWD 層結果表:DAU_FINAL
此表用于統計最終結果。表結構如下:

注意:由于模擬案例最終希望直接展示不同用戶的計算結果,故需要向同一張已提前制作好對應 BI 報表的表內寫數據,每人更新一行數據。正常業務場景下根據業務需求決定結果表結構和數量。
3.2 第一步:創建 CDC 任務
3.2.1 創建 CDC 任務
任務名稱可自行命名,任務保存位置可選擇根目錄或創建以自己名字命名的目錄。任務環境和任務類別為任務標簽信息,選擇測試和默認標簽即可,不影響任務實際運行。

3.2.2 編輯 CDC 任務
源端配置:
表:DAU_DS
傳輸起始位點:
若只想消費新增數據,請選擇最新數據,最終結果報表中將僅有體驗當日的數據。
若想先消費歷史存量數據,之后再消費最新數據,請選擇全量初始化,最終結果報表中將有歷史數據。

目標端配置:
類型:kafka
數據源:poc_kafka
Topic:自行命名,可通過目標 Topic 生成規則生成,也可在目標 Topic 中手動修改,建議修改目標 Topic 名稱為自己的名稱,方便下一步新建流表時使用。此處選擇不存在的 Topic,在任務運行后對應 Topic 將被自動創建。
序列化方式:canal-json

3.2.3 保存并一鍵發布任務
點擊頁面上方的 保存 和 一鍵發布 按鈕,填寫任意提交描述,將任務發布至實時運維列表。

成功發布后可點擊 運維 按鈕前往任務運維頁面。
3.2.4 啟動任務
在運維頁面找到對應任務后點擊 啟動 按鈕啟動任務。

任務成功啟動,任務狀態變為運行中時,創建 CDC 任務步驟操作完成。
3.3 第二步:創建 ODS 層流表
點擊實時開發頁面左側目錄第四項流表,打開流表管理頁面。點擊頁面右上角創建表按鈕,開始創建流表。

表名:自行命名
topic:填寫上一步 CDC 任務的目標 Topic 名稱
序列化方式:canal-json

填寫完以上信息后可開始進行字段自動解析。
字段信息獲取方式選擇自動解析,之后點擊獲取數據,獲取到數據樣例后點擊解析,即可解析出流表的字段信息。
Tip:若 CDC 任務正常運行但此處未獲取到樣例數據,可能是因為數據暫未寫入,稍等一分鐘后重新嘗試。

字段信息確認無誤后即可保存流表。
保存流表成功,即為此步驟操作完成。
3.4 第三步:創建 SQL 任務
3.4.1 創建 SQL 任務
引擎請選擇 FLINK-1.14。其他類似創建 CDC 任務步驟。
3.4.2 編輯 SQL 代碼
代碼邏輯為:將同一天的用戶方式數據按日期聚合,并統計當天的DAU總數以及各設備類型的DAU。
在代碼中引用流表時,直接使用 [庫].[表] 二元組的寫法即可使用對應的流表。
注意以下內容在拷貝代碼后需自行更改:
Kafka消費者組id配置,需要更改配置中的流表名稱為自己的流表名稱
Kafka流表名稱,需要更改為上一步中自己登記的流表名稱
插入結果表的submitter字段值,需要更改為自己的名字
具體要修改的內容請見代碼中的標注。
3.4.3 發布 SQL 任務并啟動任務
保存并發布 SQL 任務,并啟動任務。操作方法與 CDC 任務的發布和啟動相同。
SQL 任務成功啟動且狀態變為運行中,則此步驟操作完成。
3.4.4 創建 BI 報表并展示數據結果
在有數 BI 中創建對應報表,查看最終的統計結果即可。刷新報表數據即可看到報表數據實時更新后的結果。預期效果如下:
(1)折線圖:

(2)報表