作為一個程序員你懂降級嗎?小心系統被高并發請求給擊垮
這篇文章,我們繼續給大家聊聊另外一個線上系統在生產環境遇到的問題。
一、背景介紹
背景情況是這樣:線上一個系統,在某次高峰期間MQ中間件故障的情況下,觸發了降級機制,結果降級機制觸發之后運行了一小會兒,突然系統就完全卡死,無法響應任何請求。
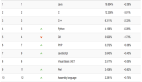
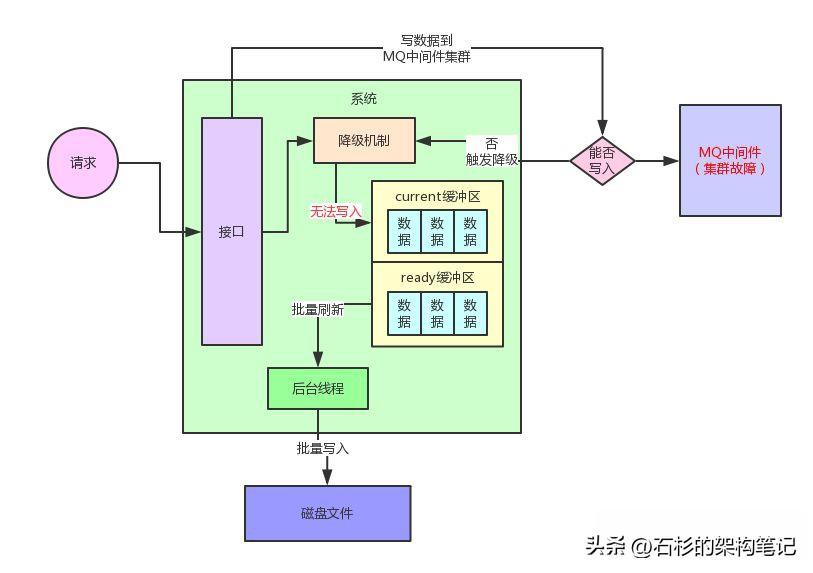
給大家簡單介紹一下這個系統的整體架構,這個系統簡單來說就是有一個非常核心的行為,就是往MQ里寫入數據,但是這個往MQ里寫入的數據是非常核心及關鍵的,絕對不容許有丟失。
所以最初就設計了一個降級機制,如果一旦MQ中間件故障,那么這個系統立馬就會把核心數據寫入本地磁盤文件。
但是如果說在高峰期并發量比較高的情況下,接收到一條數據立馬同步寫本地磁盤文件,這個性能絕對是極其差的,會導致系統自身的吞吐量瞬間大幅度下降,這個降級機制是絕對無法在生產環境運行的,因為自己就會被高并發請求壓垮。
因此當時設計的時候,對降級機制進行了一番精心的設計。
我們的核心思路是一旦MQ中間件故障,觸發降級機制之后,系統接收到一條請求不是立馬寫本地磁盤,而是采用內存雙緩沖 + 批量刷磁盤的機制。
簡單來說,系統接收到一條消息就會立馬寫內存緩沖,然后開啟一個后臺線程把內存緩沖的數據刷新到磁盤上去。
整個過程,大家看看下面的圖,就知道了。
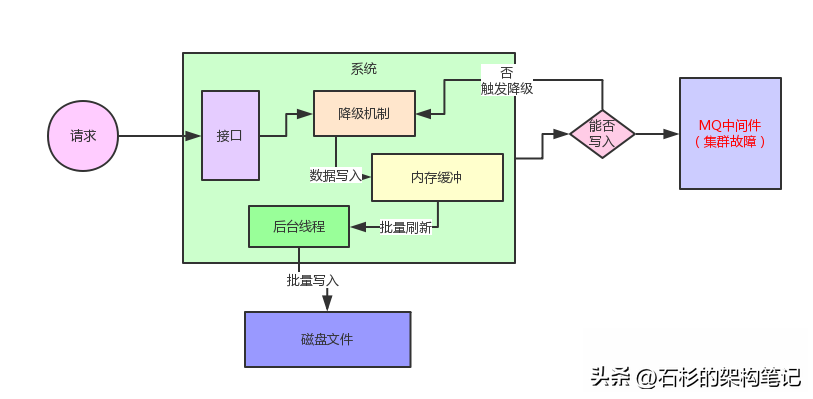
這個內存緩沖實際在設計的時候,分為了兩個區域。
一個是current區域,用來供系統寫入數據,另外一個是ready區域,用來供后臺線程刷新數據到磁盤里去。
每一塊內存區域設置的緩沖大小是512kb,系統接收到請求就寫current緩沖區,但是current緩沖區總共就512kb的內存空間,因此一定會寫滿。
同樣,大家結合下面的圖,一起來看看。
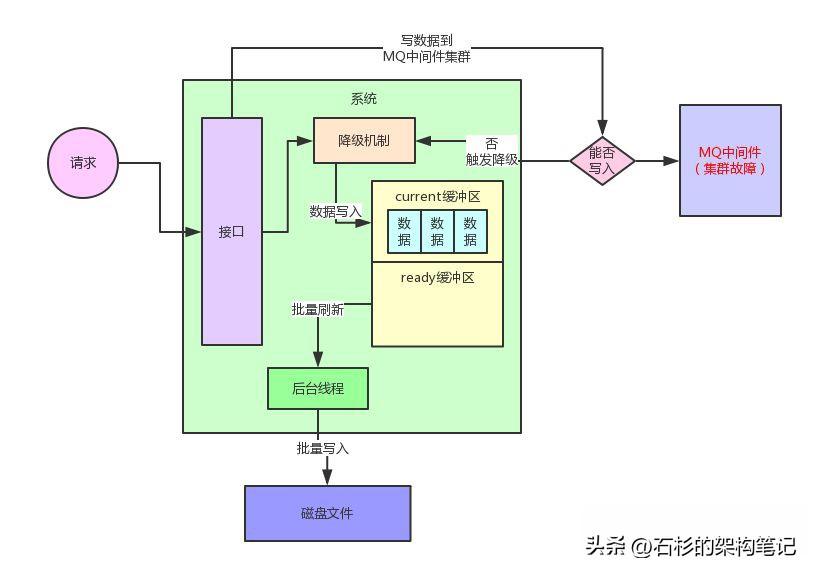
current緩沖區寫滿之后,就會交換current緩沖區和ready緩沖區。交換過后,ready緩沖區承載了之前寫滿的512kb的數據。
然后current緩沖區此時是空的,可以繼續接著系統繼續將新來的數據寫入交換后的新的current緩沖區。
整個過程如下圖所示:
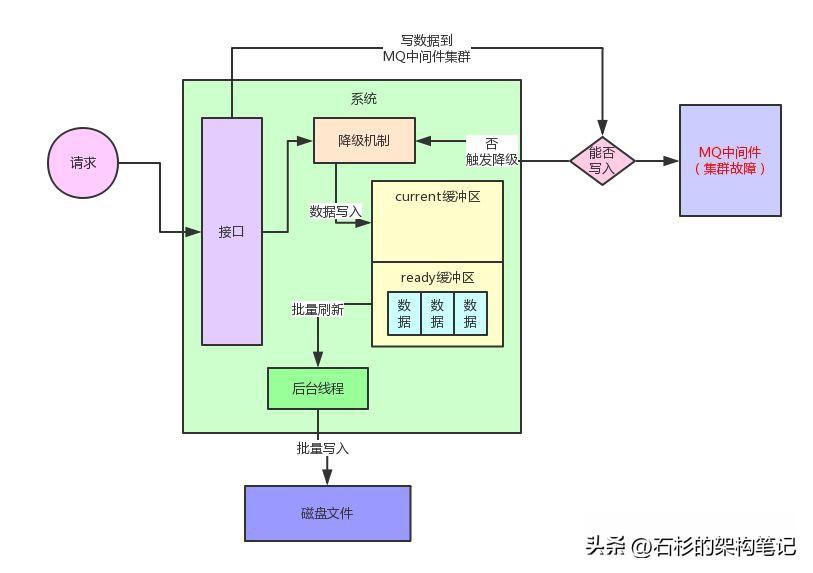
此時,后臺線程就可以將ready緩沖區中的數據通過Java NIO的API,直接高性能append方式的寫入到本地磁盤文件里。
當然,這里后臺線程會有一整套完善的機制,比如說一個磁盤文件有固定大小,如果達到了一定大小,自動開啟一個新的磁盤文件來寫入數據。
二、埋下隱患
好!通過上面一套機制,即使是高峰期,也能順利的抗住高并發的請求,一切看起來都很美好!
但是,當時這個降級機制在開發時,我們采取的思路,為后面埋下了隱患!
當時采取的思路是:如果current緩沖區寫滿了之后,所有的線程全部陷入一個while循環無限等待。
等到什么時候呢?一直需要等到ready緩沖區的數據被刷到磁盤文件之后,清空掉ready緩沖區,然后跟current緩沖區進行交換。
這樣current緩沖區要再次變為空的緩沖區,才可以讓工作線程繼續寫入數據。
但是大家有沒有考慮過一個異常的情況有可能會發生?
就是后臺線程刷新ready緩沖區的數據到磁盤文件,實際上也是需要一點時間的。
萬一在他刷新數據到磁盤文件的過程中,current緩沖區突然也被寫滿了呢?
此時就會導致系統的所有工作線程無法寫入current緩沖區,線程全部卡死。
給大家上一張圖,看看這個問題!
這個就是系統的降級機制的雙緩沖機制最根本的問題了,在開發好這套降級機制之后,采用正常的請求壓力測試過,發現兩塊緩沖區在設置為512kb的情況下,運作良好,沒有什么問題。
三、高峰請求,問題爆發
但是問題就出在高峰期上了。某一次高峰期,系統請求壓力達到了平時的10倍以上。
當然正常流程下,高峰期的時候,寫請求其實也是直接全部寫到MQ中間件集群去的,所以哪怕你高峰期流量增加10倍也無所謂,MQ集群是可以天然抗高并發的。
但是當時不幸的是,在高峰期的時候,MQ中間件集群突然臨時故障,這也是一年遇不到幾次的。
這就導致這個系統突然觸發了降級機制,然后就開始寫入數據到內存雙緩沖里面去。
要知道,此時是高峰期啊,請求量是平時正常的10倍!因此10倍的請求壓力瞬間導致了一個問題的發生。
這個問題就是瞬時涌入的高并發請求一下將current緩沖區寫滿,然后兩個緩沖區交換,后臺線程開始刷新ready緩沖區的數據到磁盤文件里去。
結果因為高峰期請求涌入過快,導致ready緩沖區的數據還沒來得及刷新到磁盤文件,此時current緩沖區又突然寫滿了。。。
這就尷尬了,線上系統瞬間開始出現異常。。。
典型的表現就是,所有機器上部署的實例全部線程都卡死,處于wait的狀態。
四、定位問題,對癥下藥
于是,這套系統開始在高峰期無法響應任何請求。后來經過線上故障緊急排查、定位和搶修,才解決了這個問題。
其實說來解決方法也很簡單,我們通過jvm dump出來快照進行分析,查看系統的線程具體是卡在哪個環節,然后發現大量線程卡死在等待current緩沖區的地方。
這就很明顯知道原因了,解決方法就是對線上系統擴容雙段緩沖的大小,從512kb擴容到一個緩沖區10mb。
這樣在線上高峰期的情況下,也可以穩穩的讓降級機制的雙緩沖機制流暢的運行,不會說瞬間高峰涌入的請求打滿兩塊緩沖區。
因為緩沖區越大,就可以讓ready緩沖區被flush到磁盤文件的過程中,current緩沖區沒那么快被打滿。
但是這個線上故障反饋出來的一個教訓,就是對系統設計和開發的任何較為復雜的機制,都必須要參照線上高峰期的最大流量來壓力測試。只有這樣,才能確保任何在系統上線的復雜機制可以經得起線上高峰期的流量的考驗。