譯者 | 朱先忠?
審校 | 孫淑娟?
深度學習神經網絡最近受到了大量關注,原因在于它是當今語音識別、人臉檢測、語音控制、自動駕駛汽車、腦腫瘤檢測技術背后的技術,而這些在20年前并不屬于我們生活的內容。盡管這些神經網絡看起來很復雜,但它們也像人類一樣地學習——通過各種案例來進行。只不過,神經網絡是使用大量數據集進行訓練,并通過多個網絡層和多次迭代進行優化,以便獲得最佳的運算結果而已。?
在過去20年中,計算能力和數據量的指數級增長為深度學習神經網絡創造了完美的發展條件。盡管我們在機器學習和人工智能等華而不實的術語上磕磕絆絆;但其實,這些技術只不過是線性代數和微積分與計算的結合結果罷了。?
Keras、PyTorch和TensorFlow等框架有助于定制深度神經網絡的艱難構建、訓練、驗證和部署過程。在現實生活中,創建深度學習應用程序時,這幾款框架顯然成為首選。?
盡管如此,有時后退一步繼續前進是至關重要的,我的意思是真正理解框架幕后發生的事情。在本文中,我們將通過僅使用NumPy這個基礎框架來創建一個深度神經網絡并將其應用于圖像分類問題來實現這一點。在計算過程中,你可能會迷失在某個地方,特別是在與微積分相關的反向傳播環節,但不要擔心。在框架處理過程中,對過程的直覺比計算更重要。?
在本文中,我們將構建一個圖像分類(貓或無貓)神經網絡,該網絡將使用兩組共1652張圖像進行訓練。其中,852張圖像來自??狗和貓圖像數據集??的貓圖像,另外800張來自Unsplash隨機圖像集的??隨機圖像??。開始時,首先需要將圖像轉換為數組,我們將通過將原始尺寸減小到128x128像素來加快計算速度,因為如果我們保持原始形狀,則需要很長時間來訓練模型。所有這些128x128圖像都有三個顏色層(紅色、綠色和藍色);當混合時,這些顏色會達到圖像的原始顏色。每幅圖像上的128x128像素中的每一個像素都具有從0到255的紅色、綠色和藍色值范圍,這些值是我們圖像矢量中的值。因此,在我們的計算中,我們將處理1652幅圖像的共計128x128x3個矢量。
要在網絡中運行上述矢量,需要通過將三層顏色堆疊成單個數組來重構它,如下圖所示。然后,我們將獲得一個(49152,1652)大小的向量,該向量將通過使用1323個圖像向量來訓練模型,并通過使用訓練后的模型預測圖像分類(貓或無貓)來對其進行測試。在將這些預測與圖像的真實分類標簽進行比較之后,將有可能估計模型的準確性。?
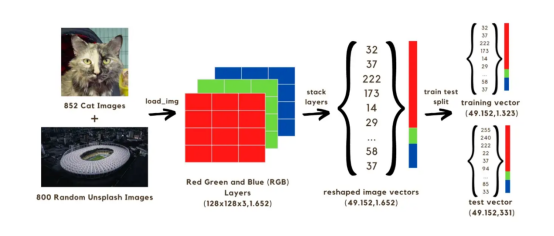
圖像1:將圖像轉換為矢量的過程?
隨著訓練向量的解釋,現在是討論網絡架構的時候了,如圖2所示。由于訓練向量中使用了49152個值,模型的輸入層必須具有相同數量的節點(或神經元)。然后,在輸出層之前有三個隱藏層,這將是該圖片中貓的概率。在現實生活中的模型中,通常有3個以上的隱藏層,因為網絡需要更深入才能在大數據環境中表現良好。?
在本文中,我們僅使用了三個隱藏層,這是因為它們對于簡單的分類模型來說已經足夠好。盡管該架構只有4層(輸出層不計算在內),但該代碼可以通過使用層的維度作為訓練函數的參數來創建更深層的神經網絡。?
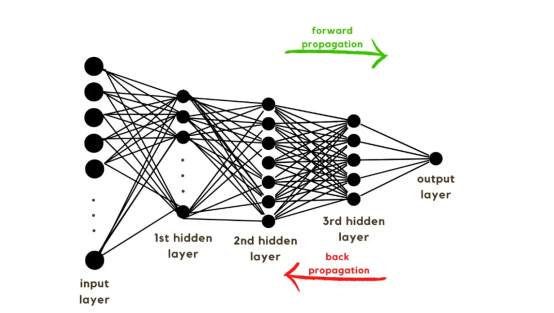
圖2:網絡架構?
到現在為止,我們已經解釋了圖像向量和所采用的網絡架構;接下來,我們將使用優化算法在圖3所示的梯度下降算法中進行描述。同樣,如果您不能立即完成所有步驟,請不要擔心,因為本文稍后將在編碼部分詳細介紹其圖中所示的每個步驟。?
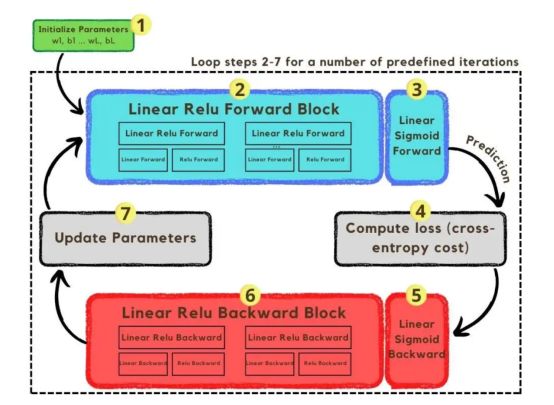
圖3:訓練過程?
首先,我們啟動網絡的參數。這些參數是圖像2中顯示的節點的每個連接的權重(w)和偏差(b)。在代碼中,更容易理解每個權重和偏差參數的工作方式以及它們的初始化方式。稍后,當這些參數初始化后,是時候運行正向傳播塊并在最后一次激活中應用sigmoid函數以獲得概率預測。?
在我們的例子中,這是一只貓出現在照片中的概率。隨后,我們通過交叉熵成本(一種廣泛用于優化分類模型的損失函數)將我們的預測與圖像的真實標簽(貓或非貓)進行比較。最后,在計算出成本的情況下,我們通過反向傳播模塊將其返回,以計算其相對于參數w和b的梯度。隨著損失函數相對于w和b所具有的梯度已經為我們所掌握,可以通過對各個梯度求和來更新參數,因為它們指向使損失函數最小化的w和b值的方向。?
由于目標是使損失函數最小化,所以該循環應該經過預定義的迭代次數,朝著損失函數的最小值邁出一小步。在某一點上,參數將停止改變,因為當最小值接近時,梯度會趨于零。?
1. 加載數據?
首先,需要加載庫。除了使用keras.preprrocessing.image將圖像轉換為向量之外,只需要導入Numpy、Pandas和OS三個庫模塊,而另一方面我們使用sklearn.model_selection將圖像向量拆分為訓練向量和測試向量兩部分。
數據必須從兩個文件夾下加載:cats和random_images。這可以通過獲取所有文件名并構建每個文件的路徑來完成。然后,只需合并數據幀中的所有文件路徑,并創建一個條件列“is_cat”。如果該路徑位于cats文件夾中,則值為1;否則值為0。?
有了路徑數據集,是時候通過分割圖像來構建我們的訓練和測試向量了;其中80%用于訓練,20%用于測試。Y表示特征的真實標簽,而X表示圖像的RGB值,因此X被定義為數據幀中具有圖像文件路徑的列,然后使用load_img函數加載它們,target_size設置為128x128像素,以便實現更快的計算。最后,使用img_to_array函數將圖像轉換為數組。這些是X_train和X_test向量的形狀:?
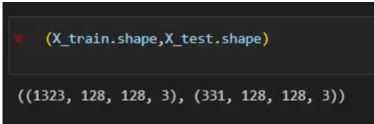
圖4:X_train和X_test向量的形狀?
2. 初始化參數?
由于線性函數是z=w*x+b并且網絡具有4個層,所以要初始化的參數向量是w1、w2、w3、w4、b1、b2、b3和b4。在代碼中,這是通過在層維度列表的長度上循環來完成的——稍后將定義;但是在這里它是一個硬編碼列表,其中包含網絡中每個層中的神經元數量。?
參數w和b必須使用不同的初始化方式:w必須初始化為隨機小數字矩陣,b必須初始化為零矩陣。這是因為如果我們將權重初始化為零,則權重wrt(相對于)損失函數的導數將全部相同,因此后續迭代中的值將始終相同,隱藏層將全部對稱,導致神經元只學習相同的幾個特征。因此,我們把權重初始化為隨機數,以打破這種對稱性,從而允許神經元學習不同的特征。需要注意的是,偏置可以初始化為零,因為對稱性已經被權重打破,并且神經元中的值都將不同。?
最后,為了理解參數向量初始化時定義的形狀,必須知道權重參與矩陣乘法,而偏差參與矩陣和運算(還記得z1=w1*x+b1嗎?)。得益于Python廣播技術,可以使用不同大小的數組進行矩陣加法運算。另一方面,矩陣乘法只有在形狀兼容時才可能進行運算,如(m,n)x(n,k)=(m,k)。這意味著,第一個陣列上的列數需要與第二個陣列上行數匹配,最終矩陣將具有陣列1的行數和陣列2的列數。圖5顯示了神經網絡上使用的所有參數向量的形狀。?
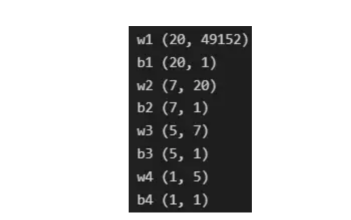
圖5:參數向量的形狀?
在第一層中,當我們將w1參數向量乘以原始49152個輸入值時,我們需要w1形狀為(20,49152)*(49152,1323)=(20,1323),這是第一個隱藏層激活的形狀。b1參數與矩陣乘法的結果相加(記住z1=w1*x+b1),因此我們可以將(20,1)數組添加到乘法的(20,1323)結果中,因為廣播會自動考慮不匹配的形狀。這一邏輯繼續到下一層,因此我們可以假設w(l)形狀的公式是(節點數量層l+1,節點數量層l),而b(l)的公式為(節點數量,層l+1)。?
最后,我們對權重向量初始化進行重要分析。我們應該將隨機初始化值除以正在初始化w參數向量的各個層上節點數量的平方根。例如,輸入層有49152個節點,因此我們將隨機初始化的參數除以√49152,即222,而第一個隱藏層有20個節點;所以,我們將隨機初始的w2參數除以√20,即結果值為45。初始化必須保持較小,因為這是隨機梯度下降的要求。?
3. 正向傳播?
現在,參數向量已經被初始化,現在我們可以進行正向傳播了。該正向傳播將線性操作z=w*x+b與ReLU激活相結合,直到最后一層,當sigmoid激活函數替代ReLU激活函數時,我們得到最后一次激活的概率。線性運算的輸出通常用字母“z”表示,稱為預激活參數。因此,預激活參數z將是ReLU和sigmoid激活的輸入。?
在輸入層之后,給定層L上的線性操作將是z[L]=w[L]*a[L-1]+b[L],使用前一層的激活值而不是數據輸入x。線性操作和激活函數的參數都將存儲在緩存列表中,用作稍后在反向傳播塊上計算梯度的輸入。?
因此,首先定義線性正向函數:?
接下來,我們來定義Sigmoid和ReLU兩個激活函數。圖6顯示了這兩個函數的圖形示意。其中,Sigmoid激活函數通常用于二類分類問題,以預測二元變量的概率。這是因為S形曲線使大多數值接近0或1。因此,我們將僅在網絡的最后一層使用Sigmoid激活函數來預測貓出現在圖片中的概率。?
另一方面,如果輸入為正,ReLU函數將直接輸出;否則,將輸出零。這是一個非常簡單的操作,因為它沒有任何指數運算,有助于加快內層的計算速度。此外,與tanh和sigmoid函數不同,使用ReLU作為激活函數降低了消失梯度問題的可能性。?
值得注意的是,ReLU激活函數不會同時激活所有節點,因為激活后所有負值將變為零。在整個網絡中設置一些0值很重要,因為它增加了神經網絡的一個理想特性——稀疏性;這意味著網絡具有更好的預測能力和更少的過度擬合。畢竟,神經元正在處理有意義的信息部分。像我們的例子中一樣,可能存在一個特定的神經元可以識別貓耳朵;但是,如果圖像是人或風景的話,顯然應該將其設置為0。?
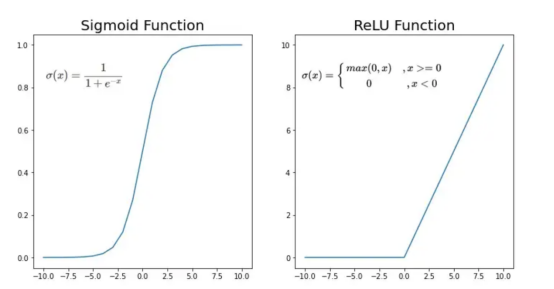
圖6:Sigmoid和ReLU激活函數圖形示意?
現在可以實現全部的激活函數了。?
最后,是時候根據前面預先計劃的網絡架構在一個完整的函數中整合上面的激活函數了。首先,創建緩存列表,將第一次激活函數設置為數據輸入(訓練向量)。由于網絡中存在兩個參數(w和b),因此可以將層的數量定義為參數字典長度的一半。然后,該函數在除最后一層外的所有層上循環;在最后一層應用線性前向函數,隨后應用的是ReLU激活函數。?
4. 交叉熵損失函數?
損失函數通過將預測的概率(最后一次激活的結果)與圖像的真實標簽進行比較來量化模型對給定數據的性能。如果網絡使用數據進行學習,則每次迭代后成本(損失函數的結果)必須降低。在分類問題中,交叉熵損失函數通常用于優化目的,其公式如下圖7所示:?
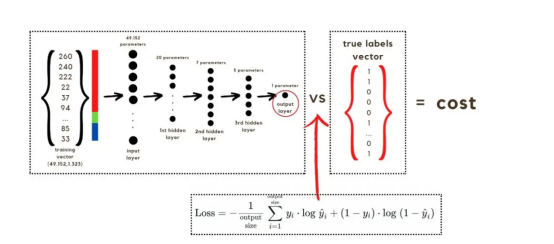
圖7:神經網絡的成本(損失函數的輸出結果)示意圖?
在本例中,我們使用NumPy定義交叉熵成本函數:?
5. 反向傳播?
在反向傳播模塊中,我們應該在網絡上從右向左移動,計算與損失函數相關的參數梯度,以便稍后更新。就像在前向傳播模塊中一樣的順序,接下來,我們首先介紹一下線性反向傳播,然后是sigmoid和relu,最后通過一個函數整合網絡架構上的所有功能。?
對于給定的層L,線性部分為z[L]=w[L]*a[L-1]+b[L]。假設我們已經計算了導數dZ[L],即線性輸出的成本導數,對應的公式稍后很快就會給出。但首先讓我們看看下圖8中dW[L]、dA[L-1]和db[L]的導數公式,以便首先實現線性后向函數。?
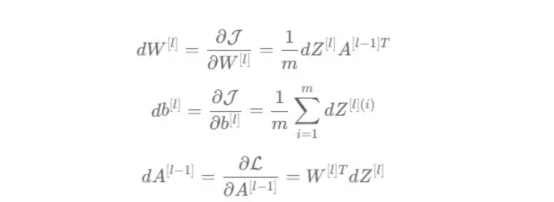
圖8:成本相關權重、偏差和先前激活函數的導數?
這些公式是交叉熵成本函數相對于權重、偏差和先前激活(a[L-1])的導數。本文不打算進行導數計算,但它們已經在我的另一篇文章??《走向數據科學》??一文中進行了介紹。
定義線性向后函數需要使用dZ作為輸入,因為在反向傳播中線性部分位于sigmoid或relu向后激活函數之后。在下一段代碼中,將計算dZ,但為了在正向傳播上遵循相同的函數實現邏輯,首先應用線性反向函數。?
在執行梯度計算之前,必須從前一層加載參數權重、偏置和激活,所有這些都在線性傳播期間存儲在緩存中。參數m最初來自交叉熵成本公式,是先前激活函數的向量大小,可以通過previous_activation.shape[1]獲得。然后,可以使用NumPy實現梯度公式的矢量化計算。在偏置梯度中,keepdims=True和axis=1參數是必要的,因為求和需要在向量的行中進行,并且必須保持向量的原始維度,這意味著dB將具有與dZ相同的維度。?
成本wrt對線性輸出(dZ)公式的導數如圖9所示,其中g’(Z[L])代表激活函數的導數。?
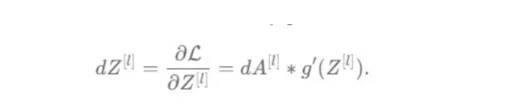
圖9——線性輸出成本的導數。?
因此,必須首先計算Sigmoid函數和ReLU函數的導數。在ReLU中,如果該值為正,則導數為1;否則,未定義。但是,為了計算ReLU后向激活函數中的dZ,有可能只復制去激活向量(因為dactivation * 1 = dactivation),并在z為負時將dZ設置為0。對于Sigmoid函數s,其導數為s*(1-s),將該導數乘以去激活,矢量dZ在Sigmoid向后函數中實現。?
現在可以實現linear_activation_backward函數。?
首先,必須從緩存列表中檢索線性緩存和激活緩存。然后,對于每一次激活,首先運行activation_backward函數,獲得dZ,然后將其作為輸入,與線性緩存結合,用于linear_backward函數。最后,函數返回dW、dB和dprevious_activation梯度。請記住,這是正向傳播的逆序,因為我們在網絡上從右向左傳播。?
現在,我們可以為整個網絡實現后向傳播函數了。該函數將從最后一層L開始向后迭代所有隱藏層。因此,代碼需要計算dAL;dAL是上次激活時成本函數的導數,以便將其用作sigmoid激活函數的linear_activation_backward函數的輸入。dAL的公式如下圖10所示:?
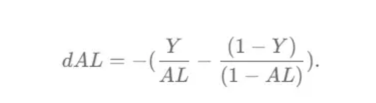
圖10:最后激活函數的成本導數?
現在,實現后向傳播函數的一切都設置到位。?
首先,創建梯度字典。網絡的層數是通過獲取緩存字典的長度來定義的,因為每個層在前向傳播塊期間都存儲了其線性緩存和激活緩存,因此緩存列表長度與層數相同。稍后,該函數將遍歷這些層的緩存,以檢索線性激活反向函數的輸入值。此外,真正的標簽向量(Y_train)被重構為與上一次激活的形狀相匹配的維度,因為這是dAL計算中一個除以另一個的要求,即代碼的下一行。?
創建current_cache對象并將其設置為檢索最后一層的線性緩存和激活緩存(請記住,python索引從0開始,因此最后一層是n_layers-1)。然后,到最后一層,在linear_activation_backward函數上,激活緩存將用于sigmoid_backward函數,而線性緩存將作為linear_backward的輸入。最后,該函數收集函數的返回值并將它們分配給梯度字典。在dA的情況下,因為計算的梯度公式來自于先前的激活,所以有必要在索引上使用n_layer-1來分配它。在該代碼塊之后,計算網絡的最后一層的梯度。?
按照網絡的反向順序,下一步是在線性層向relu層上反向循環并計算其梯度。但是,在反向循環期間,linear_activation_backward函數必須使用“relu”參數而不是“sigmoid”,因為需要為其余層調用relu_backward函數。最后,該函數返回計算的所有層的dA、dW和dB梯度,并完成反向傳播。?
6. 參數更新?
隨著梯度的計算,我們將通過用梯度更新原始參數以向成本函數的最小值移動來結束梯度下降。?
該函數通過在層上循環并將w和b參數的原始值減去學習率輸入乘以相應的梯度來實現。乘以學習率是控制每次更新模型權重時響應于估計誤差改變網絡參數w和b的程度的方法。?
7. 預處理矢量?
最后,我們實現了計算梯度下降優化所需的所有函數,從而可以對訓練和測試向量進行預處理,為訓練做好準備。?
初始化函數的layers_dimensions輸入必須進行硬編碼,這是通過創建一個包含每個層中神經元數量的列表來實現的。隨后,必須將X_train和X_test向量展平,以作為網絡的輸入,如圖11所示。這可以通過使用NumPy函數重構來完成。此外,有必要將X_train和X_test值除以255,因為它們是以像素為單位的(范圍從0到255),并且將值標準化為0到1是一個很好的做法。這樣,數字會更小,計算速度更快。最后,Y_train和Y_test被轉換為數組,并被展平。?
這些是訓練和測試向量的最終形狀打印結果:?
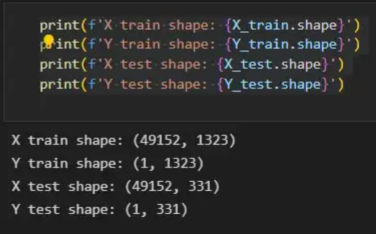
圖11:訓練和測試向量的形狀大小?
8. 訓練?
有了所有的函數,只需要將它們組織成一個循環來創建訓練迭代即可。?
但首先,創建一個空列表來存儲cross_entropy_cost函數的成本輸出,并初始化參數,因為這必須在迭代之前完成一次,因為這些參數將由梯度更新。?
現在,在輸入的迭代次數上創建循環,以正確的順序調用實現的函數:l_layer_model_forward、cross_entropy_cost、l_layer_mmodel_backward和update_parameters。最后,是一個每50次迭代或最后一次迭代打印一次成本的條件語句。?
調用函數2500次迭代的形式如下:?
調用訓練函數的代碼?
下面輸出展示了成本從第一次迭代的0.69下降到最后一次迭代的0.09。?
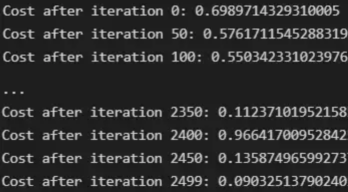
圖12:成本輸出值越來越小?
這意味著,在NumPy中開發的梯度下降函數優化了訓練過程中的參數,這必將導致更好的預測結果,從而降低了成本。?
訓練結束以后,接下來我們可以檢查訓練后的模型是如何預測測試圖像標簽的。?
9. 預測?
通過使用訓練的參數,該函數運行X_test向量的正向傳播以獲得預測,然后將其與真標簽向量Y_test進行比較以返回精度。?
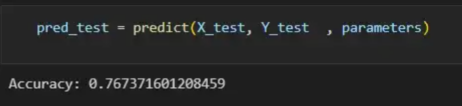
圖13:調用預測函數?
該模型在測試圖像上檢測貓的準確率達到了77%。考慮到僅使用NumPy構建網絡,這已經是一個相當不錯的準確性了。將新圖像添加到訓練數據集、增加網絡的復雜性或使用數據增強技術將現有訓練圖像轉換為新圖像都是提高準確性的可能方案。?
最后,值得再次強調的是,當我們深入數學基礎時,準確性并不是重點。這正是本文所強調的。努力學習神經網絡的基礎知識將為以后深入學習神經網絡應用的迷人世界奠定扎實的基礎。真誠希望您繼續深入下去!?
譯者介紹?
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。?
原文標題:??Behind the Scenes of a Deep Learning Neural Network for Image Classification??,作者:Bruno Caraffa?