













GPT-4“自我反思”后能力大增,測(cè)試表現(xiàn)提升 30%

4 月 4 日消息,OpenAI 最新的語(yǔ)言模型 GPT-4 不僅能夠像人類一樣生成各種文本,還能夠設(shè)計(jì)和執(zhí)行測(cè)試來(lái)評(píng)估和改進(jìn)自己的表現(xiàn)。這種“反思”技術(shù)讓 GPT-4 在多項(xiàng)難度較高的測(cè)試中,都取得了顯著的進(jìn)步,測(cè)試表現(xiàn)提升 30%。
GPT-4 是繼 GPT、GPT-2 和 GPT-3 之后,OpenAI 推出的最先進(jìn)的系統(tǒng),也是目前最大的多模態(tài)模型(可以接受圖像和文本輸入,輸出文本)。其利用深度學(xué)習(xí)技術(shù),使用人工神經(jīng)網(wǎng)絡(luò)來(lái)模仿人類的寫作。
研究人員諾亞?辛恩(Noah Shinn)和阿什溫?戈平納特(Ashwin Gopinath)在論文中寫道:“我們開(kāi)發(fā)了一種新穎的技術(shù),讓 AI 代理能夠模擬人類的自我反思,并評(píng)估自己的表現(xiàn)。GPT-4 在完成各種測(cè)試的時(shí)候,會(huì)增加一些額外的步驟,讓它能夠自己設(shè)計(jì)測(cè)試來(lái)檢查自己的答案,找出錯(cuò)誤和不足之處,然后根據(jù)發(fā)現(xiàn)來(lái)修改自己的解決方案。”
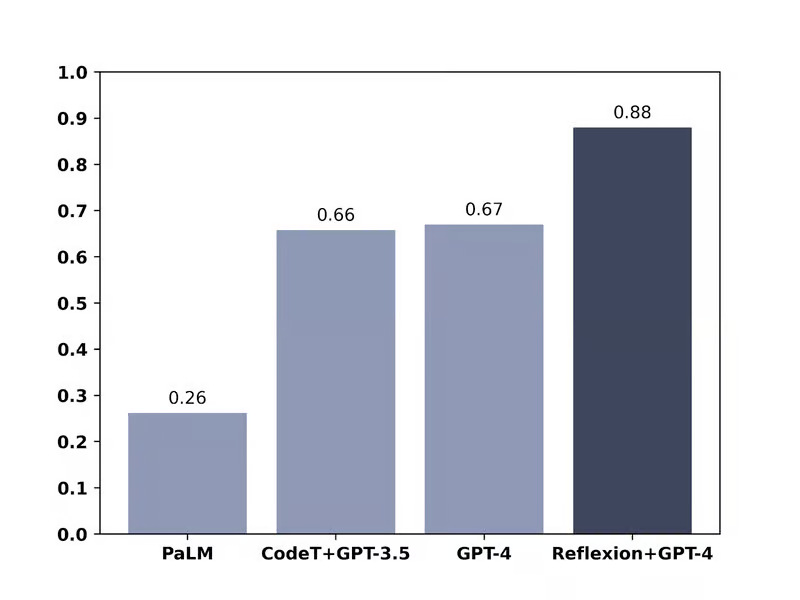
在 HumanEval 編碼測(cè)試中,GPT-4 使用自我反思環(huán)路,準(zhǔn)確率從 67% 上升到 88%
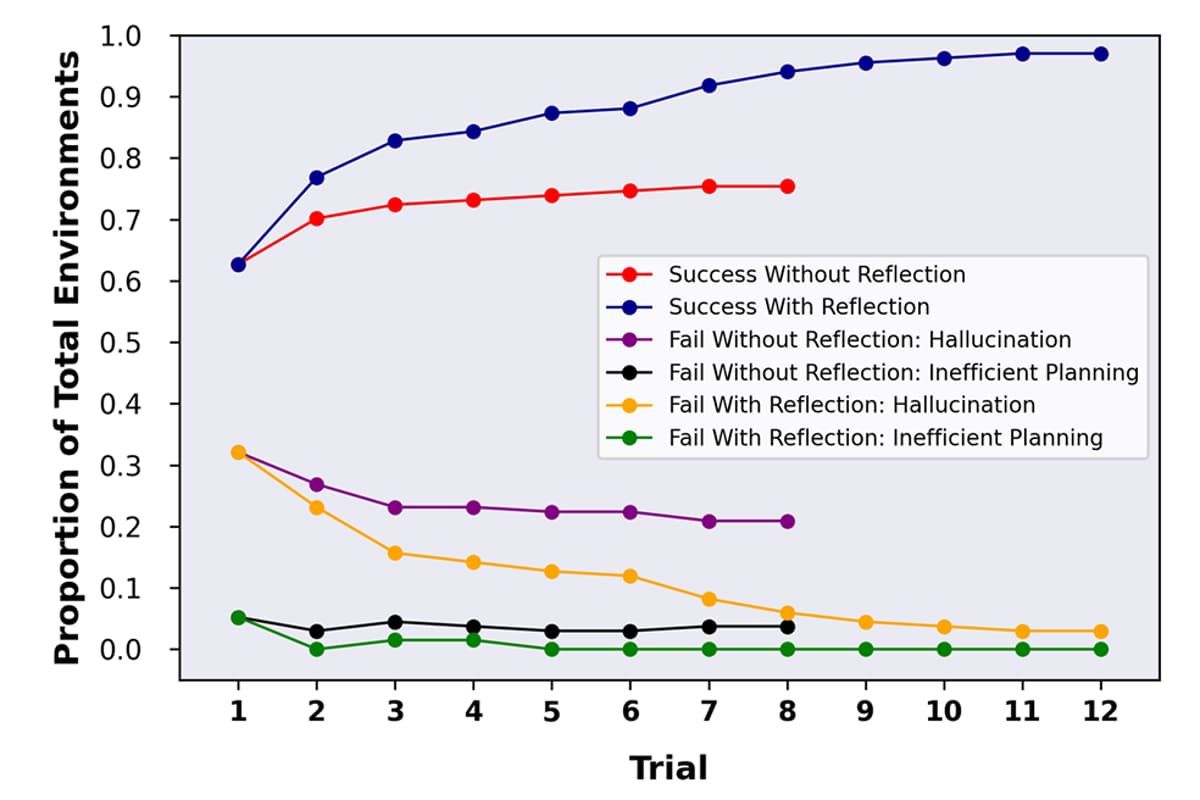
GPT-4 可以通過(guò)設(shè)計(jì)和執(zhí)行測(cè)試來(lái)批判其自身的性能,如 AlfWorld 測(cè)試結(jié)果所示,可以大大改善其性能
研究團(tuán)隊(duì)使用這種技術(shù)對(duì) GPT-4 進(jìn)行了幾種不同的性能測(cè)試。在 HumanEval 測(cè)試中,GPT-4 需要解決 164 個(gè)從未見(jiàn)過(guò)的 Python 編程問(wèn)題,原本準(zhǔn)確率為 67%,使用反思技術(shù)后,準(zhǔn)確率提升到了 88%。在 Alfworld 測(cè)試中,AI 需要在各種不同的交互環(huán)境中,通過(guò)執(zhí)行一些允許的操作,來(lái)做出決策和解決多步任務(wù)。使用反思技術(shù)后,GPT-4 的準(zhǔn)確率從 73% 提高到了 97%,只有 4 個(gè)任務(wù)失敗。在 HotPotQA 測(cè)試中,GPT-4 可以訪問(wèn)維基百科,并回答 100 個(gè)需要從多個(gè)支持文檔中解析內(nèi)容和推理的問(wèn)題,原本準(zhǔn)確率為 34%,使用反思技術(shù)后,準(zhǔn)確率提高到了 54%。
這項(xiàng)研究表明,AI 問(wèn)題的解決方案有時(shí)候是依賴 AI 本身。IT之家發(fā)現(xiàn),這有點(diǎn)像生成對(duì)抗網(wǎng)絡(luò),這是一種讓兩個(gè) AI 互相提高技能的方法,比如一個(gè) AI 試圖生成一些看起來(lái)像真實(shí)圖片的圖片,另一個(gè) AI 試圖分辨哪些是假的,哪些是真的。但在這種情況下,GPT 既是寫作者又是編輯,通過(guò)自我反思來(lái)改進(jìn)自己的輸出質(zhì)量。






























