如何實現(xiàn)秒級百萬TPS?微博WAIC實時流計算平臺架構演進
原創(chuàng)圖片來自包圖網(wǎng)
【51CTO.com原創(chuàng)稿件】WAIC 實時流計算平臺為新浪微博提供可靠的毫秒級和秒級實時數(shù)據(jù)處理服務,通過提供統(tǒng)一的數(shù)據(jù)源和配置化接入方式,幫助提高新浪微博實時作業(yè)的開發(fā)效率,降低部門開發(fā)與運營的成本。
2018 年 5 月 18-19 日,由 51CTO 主辦的全球軟件與運維技術峰會在北京召開。
在“高并發(fā)與實時處理”分會場,新浪微博實時流技術平臺負責人廖博帶來了《WAIC 實時流計算平臺的成長和繁衍》的主題演講。
本文將按照如下四個階段分享微博實時流計算平臺的搭建歷程,以及在創(chuàng)建過程中的一些問題和解決方案:
- 初入實時流計算
- 實時流計算平臺初建
- 實時流計算平臺發(fā)展
- 總結 DQRA 設計模式
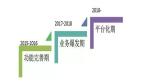
初入實時流計算
首先介紹一下我們實時流計算平臺開發(fā)歷程:
- 2015 年,我進入新浪微博。當年,我們利用實時流計算做出了物料池系統(tǒng)。
- 2016 年,我們進行了用戶實時興趣反饋系統(tǒng)的開發(fā)。
- 2017 年,我們接入了一些與多媒體相關的,如人臉識別系統(tǒng)的建設。同年,我們也開始進行實時流計算平臺的初建。
- 2018 年,我們開啟了 WAIC 實時流計算平臺。

上圖是實時流計算的技術背景,常用的計算引擎有:Spark、Streaming、Flink、Storm、Flume 和 Kafka 等一些中間件。

我們 WAIC 實時流計算平臺中,主要用到的計算引擎是:Storm、Kafka、Flume 和 Flink。
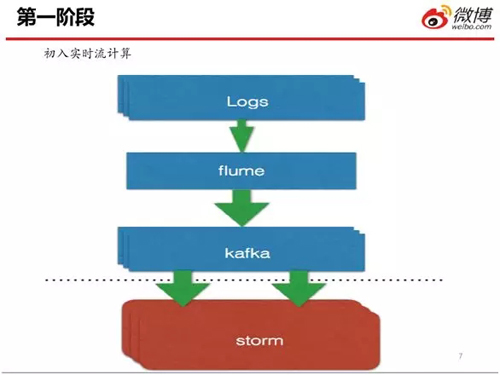
上圖是實時流計算的第一階段。這是一個經(jīng)典的架構,它通過利用 Flume,將業(yè)務系統(tǒng)里的實時流日志數(shù)據(jù)寫入 Kafka。
然后再利用 Storm 去讀取 Kafka 里的數(shù)據(jù),最后將數(shù)據(jù)進行相應的業(yè)務邏輯處理。
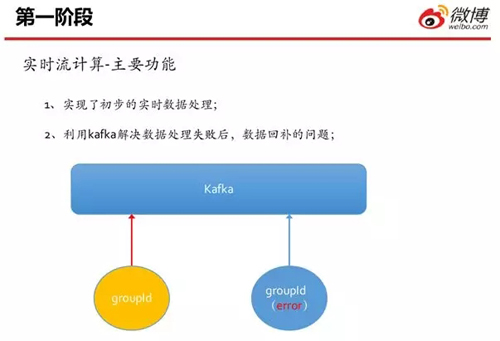
在該階段,我們主要完成了如下兩項工作:
- 讓微博“接入”實時流計算功能。
- 當數(shù)據(jù)處理出現(xiàn)失敗時,使用 Kafka 來執(zhí)行必要的數(shù)據(jù)回滾,從而解決問題。

上圖是第一階段相應的數(shù)據(jù)成果。彼時的數(shù)據(jù)量和集群個數(shù)都比較少,因此主要存在的問題包括:
- 人工工作量比較多,即:面對需求時,全靠人編碼。
- 代碼重復率比較高,異常排查的方式較為簡陋,全靠登錄到服務器上,去 Grep 日志。
- 監(jiān)控的方式則全靠腳本。

上圖是第一階段所遺留的一些問題。
實時流計算平臺初建
那么隨著實時流計算的頻繁使用、業(yè)務場景的增多、以及監(jiān)控需求的提升,我們意識到需要搭建一個實時流的計算平臺。

我們當時所提出的平臺目標主要包括:
- 研發(fā)一個工作量可以沉淀,并且可配置的開發(fā)框架。
- 統(tǒng)一所有的監(jiān)控,打造一個統(tǒng)一的監(jiān)控平臺。
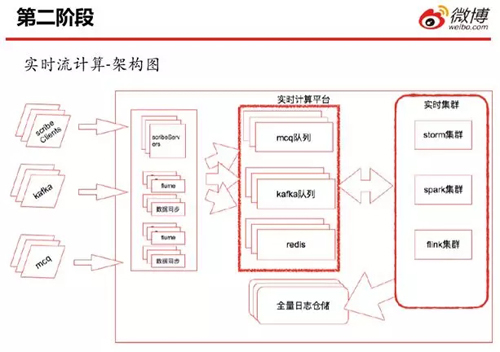
這是第二階段實時流的初步架構圖。在此,我們的接入日志方式豐富了許多。如圖,我們既通過 Scribe 進行收集、又從 Kafka 以及 Mcq 里面讀取數(shù)據(jù)。
然后通過 Scribe、或者其他的數(shù)據(jù)同步服務,將它們接入到實時隊列之中,最后在不同的業(yè)務場景下,利用不同的實時集群進行處理。
自研 WeiPig 框架
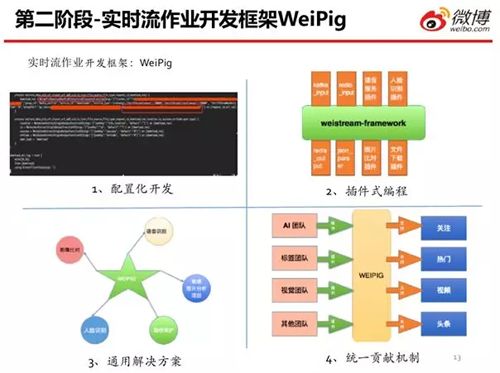
為了降低開發(fā)人員上手實時任務開發(fā)的門檻,我們自行研發(fā)了一個 WeiPig 框架。
它具有如下四個主要特點:
- 配置化開發(fā)。對于一些簡單的開發(fā)需求,我們只需編寫 WeiPig 開發(fā)文件,便可實現(xiàn)。
- 插件式編程。它提供一個插件式編程的編碼規(guī)范。對于初期的一些功能需求,我們按照相應的規(guī)范進行編碼,即我們通過編寫 WeiPig 文件,來滿足各種需求。
- 通用解決方案。因為 WeiPig 是一個針對實時流而開發(fā)的應用框架,所以它需要滿足供應鏈上所有不同類型的實時流需求。
- 統(tǒng)一貢獻機制。使不同的業(yè)務團隊,能夠按照同一套規(guī)范來進行相應的插件開發(fā),并提供相應的插件功能。同時,他們也可以按照同樣的規(guī)范和機制,來使用其他團隊所提供的功能插件。
同時,我們需要通過該 WeiPig 框架,讓所有開發(fā)人員的工作模式“沉淀”下去,實現(xiàn)公司內(nèi)各個部門的共享與協(xié)作。
統(tǒng)一監(jiān)控平臺
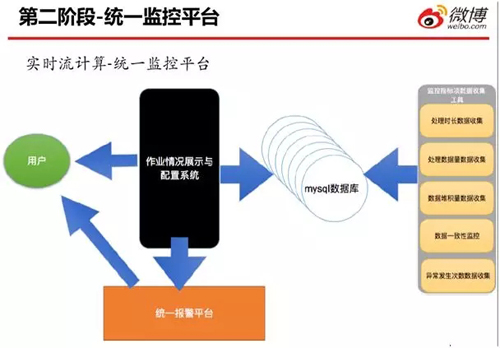
如前所述,在第一階段,我們的監(jiān)控實現(xiàn)方式基本上是:靠那些運行在不同服務器上的腳本,進行日志數(shù)據(jù)的采集,然后再發(fā)送報警郵件。
而進入第二階段之后,我們利用如上圖所示的實時流統(tǒng)一計算與監(jiān)控平臺,對作業(yè)情況予以了展示與配置。
即:該系統(tǒng)既可以展示相應的數(shù)據(jù)監(jiān)控指標,又可以對數(shù)據(jù)監(jiān)控指標進行相應的報警配置。
而這些監(jiān)控指標數(shù)據(jù)都是通過不同的搜集工具進行采集,然后錄入到 MySQL 數(shù)據(jù)庫之中。

上圖是第二階段相應的成果。雖然此時已經(jīng)有了 WeiPig 開發(fā)框架,但是我們的人工工作量依然不少。
由于 WeiPig 的插件主要是由平臺方的幾名開發(fā)人員來實現(xiàn),因此插件數(shù)量不但較少,而且他們的工作量也達到了 80%。
另外,代碼的重復率則僅占 50% 左右,這直接導致了異常排查的效率仍處于較低的水平。
同時,在監(jiān)控配置上,我們?nèi)孕枰謩优渲茫约巴ㄟ^編寫腳本,來搜集相關的指標數(shù)據(jù)。
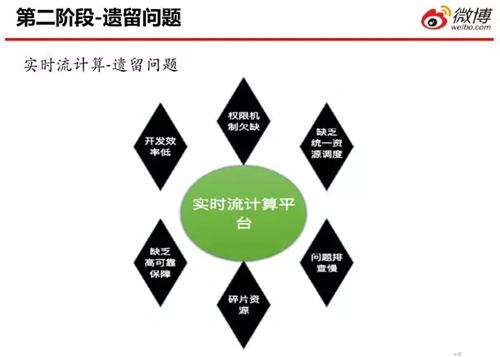
在第二階段之后,我們遺留下了不少問題,包括:
- 權限機制的欠缺
- 缺乏統(tǒng)一的資源調度
- 問題排查相對較慢
- 碎片資源相對較多(主要是因為我們使用的都是些小集群,這導致產(chǎn)生了大量遺留的冗余資源,閑置在系統(tǒng)中)
- 缺乏高可靠的保障
- 開發(fā)效率較低
實時流計算平臺發(fā)展

在步入實時流計算平臺的第三階段之后,我們提高了相應的宏觀目標,即:
- 提高公司的開發(fā)生產(chǎn)效率,節(jié)省重復建設的成本。
- 可視化各項操作。
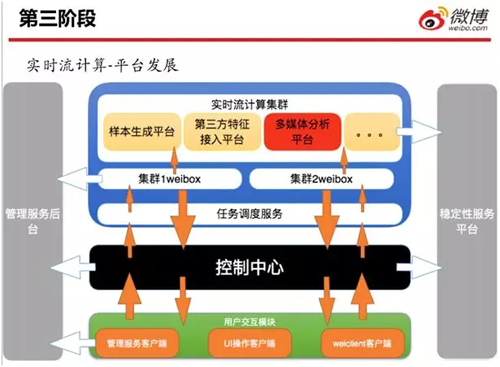
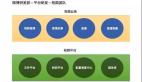
上圖是當前實時流計算平臺的架構圖。數(shù)據(jù)流邏輯如下:
- 用戶通過 UI 交互客戶端、以及 Weiclient 等交互模塊,將作業(yè)提交給控制中心。
- 控制中心進行初步的權限校驗和資源審核之后,將資源提交給任務調度。
- 任務調度將相應的作業(yè)提交給對應的集群 Weibox。
- 如果作業(yè)提交成功,Weibox 會把相應的作業(yè)信息重新返回給控制中心。
- 控制中心將作業(yè)通過用戶交互客戶端返回給用戶結果。同時,它會將作業(yè)信息同步給管理服務后臺。
- 用戶通過管理服務后臺的客戶端,去操作自己在集群上面的功能。控制中心既能減少已占用的資源,又能為每一個團隊實現(xiàn)資源控制。
控制中心初現(xiàn)

由于前期各種作業(yè)(如 Storm)在向集群提交的時候,許多開發(fā)人員會自行配置一個本地環(huán)境,以實現(xiàn)直接提交,這就造成了平臺方很難對集群進行有效的管控。
因此對于我們第三階段的控制中心而言,其主要目標是:
- 解決作業(yè)隨意提交,治理集群上作業(yè)混亂的現(xiàn)象。
- 對集群資源進行統(tǒng)一管理,從而避免過多的資源浪費。
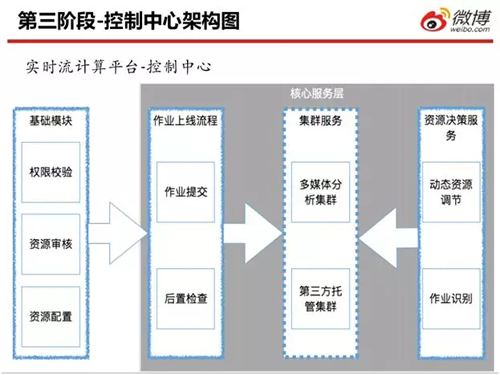
上圖是實時流計算平臺的控制中心架構圖。其流程如下:
- “基礎模塊”通過權限校驗和資源審核,將作業(yè)提交給“作業(yè)上線流程”服務。
- “作業(yè)上線流程”調用后置的檢查模塊,檢查該作業(yè)是否在集群上運行成功,以及判斷該作業(yè)所占用的資源、是否為它在提交時指定了資源量。
- 如果“作業(yè)上線流程”服務提交作業(yè)成功,那么“資源決策服務”調用動態(tài)資源調節(jié)模塊,在集群上定時(如:每小時或每天)檢查該作業(yè)所使用和處理的數(shù)據(jù)量,以及每條數(shù)據(jù)的處理時長。籍此,該模塊運用簡單的公式,來判斷該作業(yè)是否需要占這么多資源。
上述提到過,一些開發(fā)人員可能會通過在自己的本機上配置相應的作業(yè)提交環(huán)境,以實現(xiàn)將作業(yè)提交到集群之中。
那么為了管控對應的業(yè)務組在集群上占用的資源量,我們在“資源決策服務”里,調用到了作業(yè)識別模塊。
資源配置策略
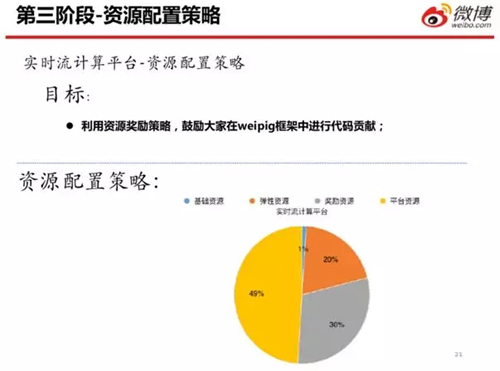
為了提高公司的生產(chǎn)開發(fā)效率,我們在第三階段實施了資源配置策略。同時,我們的核心目標點是:通過第二階段的 WeiPig 開發(fā)框架,來鼓勵各個業(yè)務團隊貢獻相應的插件。
其實 WeiPig 是一套規(guī)范協(xié)議,大家在貢獻插件之前需要增加學習上的投入。因此,對于一些已經(jīng)實施了計算能力的業(yè)務方來說,雖然有利于將舊平臺遷移過來,但是他們不太愿意投入此類學習的成本。
所以我們想出了用資源去換取 WeiPig 前向發(fā)展的方法。我們將所有的平臺資源按照基礎資源、彈性資源、獎勵資源和平臺資源,四個方向進行劃分。
其中基礎資源僅占 1%,基本上只有一、兩臺機器。彈性資源有 20%,各個公司根據(jù)業(yè)務量和業(yè)務等級進行劃分,當業(yè)務量多的時候,每一個業(yè)務都可以有自己的重要程度和優(yōu)先級。
值得一提的是:獎勵資源為 30%。它通過兩方面標準:WeiPig 里貢獻的 Function 數(shù)量,和這些通用 Function 會被多少業(yè)務方所使用到,來進行公式算法上的衡量。
如果你貢獻的多,而且被其他業(yè)務方使用的也比較多,那么我們就會從所有平臺資源的 30% 中,給你劃分出更多的資源。
實時對賬系統(tǒng)

為了滿足某些高成功率場景的需求,我們在第三階段自行設計了一個實時對賬系統(tǒng)。
該系統(tǒng)的主要成績是:滿足實時計算平臺完成 6 個 9 的數(shù)據(jù)成功率需求。

上圖是實時對賬系統(tǒng)的一個簡單架構圖。在數(shù)據(jù)處理開始時,我們會將數(shù)據(jù)寫入實時對賬系統(tǒng),并打上開始標志。
同時,實時對賬系統(tǒng)會將該數(shù)據(jù)的開始處理、和結束處理的標志,存放到存儲服務上。
而圖中下方的離線定時服務,會定時查詢實時對賬系統(tǒng),并進行如下判斷:
- 如果一條數(shù)據(jù)既有入賬,又有根據(jù)處理結束值所求的出賬,則認為該條數(shù)據(jù)已處理完成,即對賬成功。
- 如果一條數(shù)據(jù)只有數(shù)據(jù)處理的開始,卻沒有處理結束的標志,則該條數(shù)據(jù)可能出現(xiàn)被丟掉的情況,我們需要重試。
- 如果一條數(shù)據(jù)只有數(shù)據(jù)處理結束,卻沒有數(shù)據(jù)處理成功的標志,則會發(fā)出相應的報警,我們需要查找相應的問題。
穩(wěn)定性服務平臺

另外,在第三階段,我們將第二階段的“統(tǒng)一監(jiān)控平臺”升級成了“穩(wěn)定性服務平臺”。
其目標有如下三點:
- 通用監(jiān)控指標的數(shù)據(jù)統(tǒng)一生成。前面在第二階段的監(jiān)控統(tǒng)一平臺中,我們必須在界面上去配置要監(jiān)控的指標項目,通過編寫相應的采集代碼,然后把腳本部署到服務器上,以方便監(jiān)控的采集。
但是在第三階段的穩(wěn)定性服務平臺上,一個作業(yè)被提交到集群上之后,穩(wěn)定性服務平臺會對集群上處理的數(shù)據(jù)量、處理延遲、錯誤量等通用指標進行統(tǒng)一生成。
- 集群資源負載均衡的監(jiān)控。其實 Storm 不像 Hadoop、Flink、Yum,它并沒有資源調度的管理系統(tǒng)。
因此,它在自己做管理資源時,會出現(xiàn)在一個集群中,某個服務器的 CPU 利用率已達 90%,而其他服務器的 CPU 利用率只占有 50%~60% 的情況。所以我們自行研發(fā)了對集群資源負載均衡的監(jiān)控。
- 監(jiān)控指標采集平臺,統(tǒng)一所有監(jiān)控數(shù)據(jù)的采集。
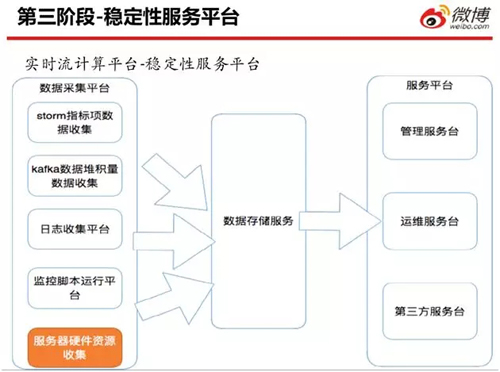
這里展示的是實時流計算平臺穩(wěn)定性服務的架構圖。左側的數(shù)據(jù)采集平臺包括:Storm 指標項目數(shù)據(jù)收集、Kafka 數(shù)據(jù)堆積量的數(shù)據(jù)收集、日志收集平臺、監(jiān)控腳本運行平臺、和服務器硬件資源的收集。
這是一個比較簡易的、便捷的資源負載均衡的監(jiān)控服務。完成統(tǒng)一采集之后,系統(tǒng)調用數(shù)據(jù)存儲服務,經(jīng)由服務平臺的管理服務平臺、運維服務平臺、和第三方服務平臺,對外面開發(fā)人員提供相應的服務。

上圖是第三階段相應的成果。目前,我們的平臺每天能處理大約一千多億的數(shù)據(jù)量,TPS 大約有百萬每秒,作業(yè)個數(shù)則每天約有 150~200 個。
如今無論是多媒體相關的數(shù)字計算需求,還是微博相關的處理需求,我們的人工工作量已相對較少了,主要的工作量集中在編寫 WeiPig 相應的配置文件上。相應的代碼重復率也比較低,同樣主要集中在 WeiPig 文件上。
另外,由于我們主要是到 HDFS 上去搜集和管控相應的日志,因此異常排查的效率適中。
而對于監(jiān)控方式而言,我們大部分采用的是自動生成的方式,所以只對一些特殊要求才進行監(jiān)控配置。
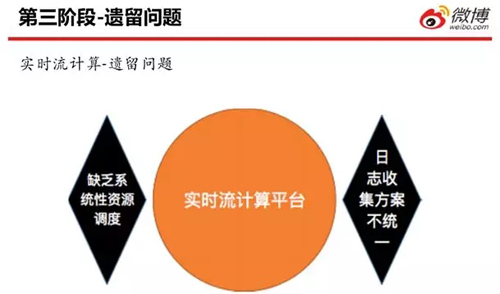
當然,目前的實時流計算平臺仍有兩個遺留問題:
- 缺乏系統(tǒng)性的資源調度。我們需要有一個資源調度系統(tǒng),來實時獲知集群上的作業(yè)到底應該運行在哪一臺服務器上。
目前我們采用的一種簡易方式是:搜集各臺服務器上的資源情況,然后用自己的程序進行判斷和處理。如果某一臺機器利用率高于其他服務器20%的話,那么我們認為其負載是不均衡的。
- 日志收集方案不統(tǒng)一。
總結 DQRA 設計模式
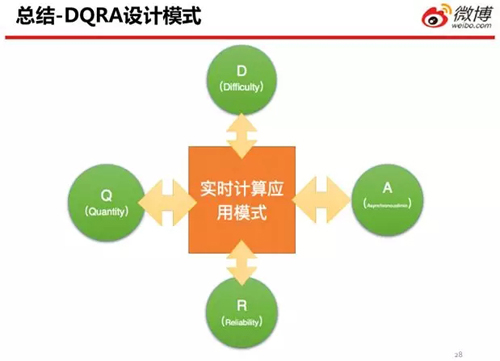
我們在實時流計算開發(fā)的過程中,一邊搭建業(yè)務平臺,一邊解決了不少問題。因此我們總結出了一套 DQRA 的設計模式。
DQRA 詳解
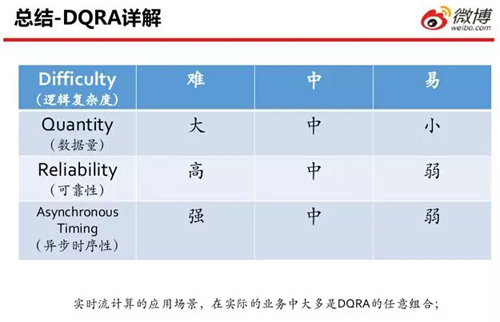
它們分別是:
- Difficulty(邏輯復雜度)
- Quantity(數(shù)據(jù)量)
- Reliability(可靠性)
- Asynchronous(異步時序性)
因此,我們認為:面對大多數(shù)的需求,我們可以把問題的實現(xiàn)拆解為上述四個屬性中的某種。
例如:邏輯復雜度有難、中、易;數(shù)據(jù)量有大、中、小;可靠性是高、中、弱;等方面。

上述便是 DQRA 可能出現(xiàn)的不同組合,以及所對應的不同解決方法。
DQRA 案例分析

下面我們會介紹一個簡單案例,它包含如下特性:
- D 難,表示實現(xiàn)的復雜度,即實時流作業(yè)中需要處理的邏輯比較難。
- Q 中,表示數(shù)據(jù)量可能一般,可能是從幾千萬到十億之間。
- R 高,表示可靠性高,即成功率要求高,如前面提到的 6 個 9 的數(shù)據(jù)處理成功率。

具體來說,它是一個圖像分析與處理類系統(tǒng),需要具有持續(xù)穩(wěn)定的服務保證。因此,系統(tǒng)穩(wěn)定是第一位的。
其次,它要求數(shù)據(jù)處理的成功率大于 6 個 9,從而能應對單日 5000 萬的數(shù)據(jù)量。
因此,我們通過上述三個方面來實現(xiàn)該系統(tǒng)的需求:
- 首先,針對系統(tǒng)的穩(wěn)定性,我們采用的是內(nèi)網(wǎng)和阿里云的“雙保險”網(wǎng)絡部署方式。
- 其次,由于涉及到圖片的下載,而我們在做分析時,調用的是在線模型預測方式。
因此,為了避免可能出現(xiàn)的圖片分析失敗,我們采用了實時對賬系統(tǒng),實現(xiàn)了必要的重試處理。
廖博,新浪微博實時流技術平臺負責人,曾就職于搜狐、雅虎研究院、支付寶等公司參與 Data Highway、大數(shù)據(jù)系統(tǒng)、數(shù)據(jù)倉庫、UUS(User Understanding Service)等第一代大數(shù)據(jù)生態(tài)系統(tǒng)的搭建工作;現(xiàn)就職于新浪微博,主導和開發(fā)實時流計算平臺,基于該平臺之上完成多媒體分析平臺、物料池系統(tǒng)、樣本生成平臺等多個子系統(tǒng)的開發(fā)和建設。
【51CTO原創(chuàng)稿件,合作站點轉載請注明原文作者和出處為51CTO.com】