如何僅需幾個(gè)步驟在您的設(shè)備上運(yùn)行Alpaca-LoRA?
譯文譯者 | 布加迪
審校 | 重樓

ChatGPT是一種人工智能(AI)語言模型,近幾個(gè)月備受關(guān)注。它有兩個(gè)流行的版本:GPT-3.5和GPT-4。GPT-4是GPT-3.5的升級(jí)版,生成的答案更準(zhǔn)確。但是ChatGPT存在的主要問題是它不是開源的,也就是說,不允許用戶查看和修改其源代碼。這導(dǎo)致了許多問題,比如定制、隱私和AI民主化。
我們需要這樣一種AI語音聊天機(jī)器人:可以像ChatGPT一樣工作,但又是免費(fèi)開源的,而且消耗的CPU資源更少。本文介紹的Alpaca LoRA就是這樣一種AI模型。看完本文后,您就比較了解它,而且可以使用Python在本地機(jī)器上運(yùn)行它。下面不妨先討論一下什么是Alpaca AoRA。
Alpaca LoRA的定義
Alpaca是由斯坦福大學(xué)的研究小組開發(fā)的一種AI語言模型。它使用Meta的大規(guī)模語言模型LLaMA。它使用OpenAI的GPT(text- davincii -003)來微調(diào)擁有70億個(gè)參數(shù)的LLaMA模型。它可供學(xué)術(shù)界和研究界免費(fèi)使用,對(duì)計(jì)算資源的要求很低。
該團(tuán)隊(duì)從LLaMA 7B模型入手,用1萬億token對(duì)其進(jìn)行預(yù)訓(xùn)練。他們從175個(gè)由人工編寫的指令輸出對(duì)開始,讓ChatGPT的API使用這些指令輸出對(duì)生成更多對(duì)。他們收集了52000個(gè)樣本對(duì)話,用來進(jìn)一步微調(diào)其LLaMA模型。
LLaMA模型有幾個(gè)版本,即70億個(gè)參數(shù)、130億個(gè)參數(shù)、300億個(gè)參數(shù)和650億個(gè)參數(shù)。Alpaca可擴(kuò)展到70億個(gè)參數(shù)、130億個(gè)參數(shù)、300億個(gè)參數(shù)和650億個(gè)參數(shù)的模型。
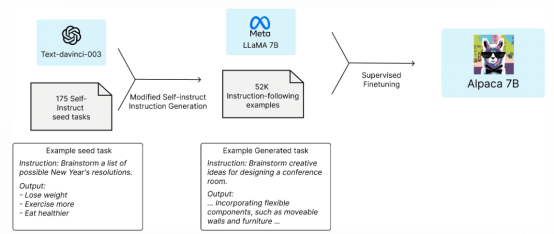
圖1 Aplaca 7B架構(gòu)
Alpaca- LoRA是Stanford Alpaca的小型版,耗電量更少,可以在Raspberry Pie等低端設(shè)備上運(yùn)行。Alpaca-LoRA使用低秩自適應(yīng)(LoRA)來加快大型模型的訓(xùn)練,同時(shí)消耗更少的內(nèi)存。
Alpaca LoRA的Python實(shí)現(xiàn)
我們將創(chuàng)建一個(gè)Python環(huán)境在本地機(jī)器上運(yùn)行Alpaca-Lora。您需要一個(gè)GPU來運(yùn)行這個(gè)模型。它無法在CPU上運(yùn)行(或者輸出很緩慢)。如果您使用70億個(gè)參數(shù)模型,需要至少12GB的內(nèi)存。如果使用130億參數(shù)或300億參數(shù)模型,需要更高的內(nèi)存。
如果您沒有GPU,可以在Google Colab中執(zhí)行相同的步驟。文末附上了Colab鏈接。
我們將遵循Alpaca-LoRA的這個(gè)GitHub代碼存儲(chǔ)庫(kù)。
1. 創(chuàng)建虛擬環(huán)境
我們將在虛擬環(huán)境中安裝所有庫(kù)。這一步不是強(qiáng)制性的,而是推薦的。以下命令適用于Windows操作系統(tǒng)。(這一步對(duì)于Google Colab來說并非必需)。
創(chuàng)建venv的命令:
$ py -m venv
激活它的命令:
$ .\venv\Scripts\activate
禁用它的命令:
$ deactivate2. 克隆GitHub代碼存儲(chǔ)庫(kù)
現(xiàn)在,我們將克隆Alpaca LoRA的代碼存儲(chǔ)庫(kù)。
$ git clone https://github.com/tloen/alpaca-lora.git
$ cd .\alpaca-lora\
安裝庫(kù):
$ PIP install -r .\requirements.txt3.訓(xùn)練
名為finettune.py的python文件含有LLaMA模型的超參數(shù),比如批處理大小、輪次數(shù)量和學(xué)習(xí)率(LR),您可以調(diào)整這些參數(shù)。運(yùn)行finetune.py不是必須的。否則,執(zhí)行器文件從tloen/alpaca-lora-7b讀取基礎(chǔ)模型和權(quán)重。
$ python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-alpaca' \
--batch_size 128 \
--micro_batch_size 4 \
--num_epochs 3 \
--learning_rate 1e-4 \
--cutoff_len 512 \
--val_set_size 2000 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[q_proj,v_proj]' \
--train_on_inputs \
--group_by_length4. 運(yùn)行模型
名為generate.py的python文件將從tloen/alpaca-lora-7b讀取Hugging Face模型和LoRA權(quán)重。它使用Gradio運(yùn)行用戶界面,用戶可以在文本框中寫入問題,并在單獨(dú)的文本框中接收輸出。
注意:如果您在Google Colab中進(jìn)行處理,請(qǐng)?jiān)趃enerate.py文件的launch()函數(shù)中標(biāo)記share=True。它將在公共URL上運(yùn)行界面。否則,它將在localhost http://0.0.0.0:7860上運(yùn)行。
$ python generate.py --load_8bit --base_model 'decapoda-research/llama-7b-hf' --lora_weights 'tloen/alpaca-lora-7b'輸出:
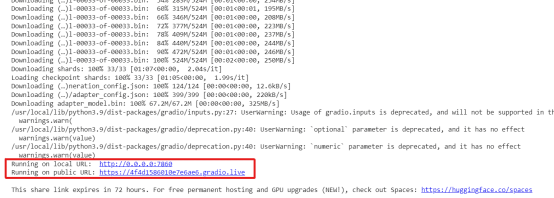
它有兩個(gè)URL,一個(gè)是公共的,另一個(gè)在本地主機(jī)上運(yùn)行。如果您使用Google Colab,公共鏈接可以訪問。
5. Docker化應(yīng)用程序
如果您想要將應(yīng)用程序?qū)С龅侥硞€(gè)地方或面臨一些依賴項(xiàng)問題,可以在Docker容器中Docker化應(yīng)用程序。Docker是一個(gè)創(chuàng)建應(yīng)用程序不可變映像的工具。然后可以共享該映像,并將其轉(zhuǎn)換回成應(yīng)用程序,該應(yīng)用程序可在容器中運(yùn)行,擁有所有必要的庫(kù)、工具、代碼和運(yùn)行時(shí)環(huán)境。您可以從這里下載Docker for Windows:https://docs.docker.com/desktop/install/windows-install/。
注意:如果您使用Google Colab,可以跳過此步驟。
構(gòu)建容器映像:
$ docker build -t alpaca-lora運(yùn)行容器:
$ docker run --gpus=all --shm-size 64g -p 7860:7860 -v ${HOME}/.cache:/root/.cache --rm alpaca-lora generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \
--lora_weights 'tloen/alpaca-lora-7b'它將在https://localhost:7860上運(yùn)行您的應(yīng)用程序。
Alpaca-LoRA用戶界面
現(xiàn)在,我們已讓Alpaca-LoRA運(yùn)行起來。接下來,我們將探討它的一些特點(diǎn),讓它為我們編寫些東西。
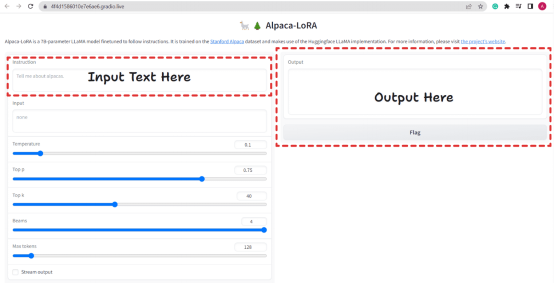
圖2. Alpaca-LoRA用戶界面
它提供了類似ChatGPT的UI,我們可以在其中提出問題,它會(huì)相應(yīng)地回答問題。它還接受其他參數(shù),比如溫度、Top p、Top k、Beams和Max Tokens。基本上,這些是在評(píng)估時(shí)使用的生成配置。
有一個(gè)復(fù)選框Stream Output。如果勾選該復(fù)選框,聊天機(jī)器人將每次回復(fù)一個(gè)token(即逐行寫入輸出,類似ChatGPT),如果不勾選該選項(xiàng),它將一次性寫入。
不妨向它提一些問題。
問題1:寫一段Python代碼,求一個(gè)數(shù)的階乘。
輸出:
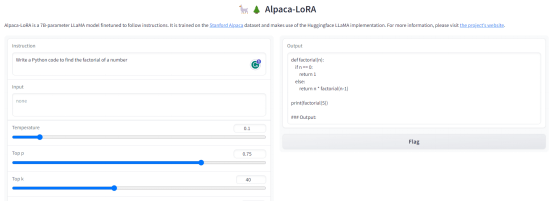
圖3. 輸出-1
問題2:將“KDnuggets is a leading site on Data Science, Machine Learning, AI and Analytics.”翻譯成法語。
輸出:
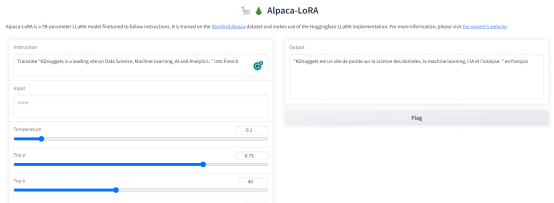
圖4. 輸出-2
與ChatGPT不同,它也有一些限制。它可能無法為您提供最新的信息,因?yàn)樗鼪]有聯(lián)網(wǎng)。此外,它可能會(huì)向社會(huì)弱勢(shì)群體傳播仇恨和錯(cuò)誤信息。盡管如此,它仍是一款出色的免費(fèi)開源工具,計(jì)算需求較低。它對(duì)研究人員和學(xué)者開展道德AI和網(wǎng)絡(luò)安全活動(dòng)大有助益。
谷歌Colab鏈接:
https://colab.research.google.com/drive/1t3oXBoRYKzeRUkCBaNlN5u3xFvhJNVVM?usp=sharing
原文標(biāo)題:Learn How to Run Alpaca-LoRA on Your Device in Just a Few Steps,作者:Aryan Garg