刷新20項代碼任務SOTA,Salesforce提出新型基礎LLM系列編碼器-解碼器Code T5+
大型語言模型 (LLMs) 最近在代碼層面的一系列下游任務中表現(xiàn)十分出彩。通過對大量基于代碼的數(shù)據(jù) (如 GitHub 公共數(shù)據(jù)) 進行預訓練,LLM 可以學習豐富的上下文表征,這些表征可以遷移到各種與代碼相關的下游任務。但是,許多現(xiàn)有的模型只能在一部分任務中表現(xiàn)良好,這可能是架構和預訓練任務限制造成的。
從架構的角度來看,現(xiàn)有的 LLMs 通常采用純編碼器或純解碼器的模型,這些模型通常只在一些理解或生成任務上執(zhí)行的效果出色。純編碼模型通常適用于理解文本、代碼檢索之類的任務,而生成代碼類的生成任務用純解碼器模型能有更出色的性能表現(xiàn)。并且,最近的一些模型用編碼器 - 解碼器這種更統(tǒng)一的架構來應對不同的任務。雖然這些模型可以同時支持理解型、生成型任務,但在特定任務中沒法達到最佳性能。在檢索和代碼完成任務上,編碼器 - 解碼器模型還是不如最先進 (SOTA) 的純編碼器和純解碼器基線。單模塊架構雖然通常可以適用于所有任務,但它的局限性也會導致編碼器 - 解碼器模型的不足。總之,先前的方法在設計時并沒有考慮如何讓單個組件可以被激活以更好地適應不同類型的下游任務。
從學習對象的角度來看,目前的模型通常采用一組有限的預訓練任務。由于預訓練和微調階段的差異,這些預訓練任務會使一些下游任務性能下降。例如,基于 T5 的模型通常以跨度去噪目標進行訓練。然而,在代碼生成等下游任務中,大多數(shù)最先進的模型都是用下一個 token 預測目標進行預訓練的,該目標可以逐 token 自回歸地預測處理。學習對比代碼表征對于理解文本、代碼檢索等任務至關重要,但許多模型沒有接受過這一方面訓練。盡管近期一些研究嘗試引入對比學習任務來緩解這個問題,但這些方法忽略了文本和代碼表征之間的細粒度跨模態(tài)對齊。
為解決上述限制,來自 Salesforce 的研究者提出了「CodeT5+」—— 一個新的基礎 LLM 系列編碼器 - 解碼器,可用于廣泛的代碼理解和生成任務。
- 論文地址:https://arxiv.org/pdf/2305.07922.pdf
- 項目地址:https://github.com/salesforce/CodeT5/tree/main/CodeT5%2B
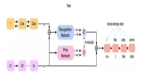
CodeT5 + 是基于編碼器 - 解碼器的模型,但可以靈活地在純編碼器、純解碼器以及編碼器 - 解碼器模式下操作,來適應不同的下游應用。總體架構如下圖 1:

這種靈活性是基于預訓練任務實現(xiàn)的,包括代碼數(shù)據(jù)上的跨度去噪和因果語言建模 (CLM) 任務,以及文本 - 代碼對比學習、匹配和文本 - 代碼數(shù)據(jù)上的 CLM 任務。如此廣泛的預訓練任務可以幫助在代碼和文本數(shù)據(jù)中學習豐富的表征,并彌合各種應用中的預訓練 - 微調差距。研究者發(fā)現(xiàn),將匹配任務與對比學習相結合,對于捕捉細粒度的文本 - 代碼對齊和提高檢索性能至關重要。
通過利用現(xiàn)成的 LLM 代碼來初始化 CodeT5 + 的組件,用高效計算的預訓練策略來擴展 CodeT5 + 的模型大小。CodeT5 + 采用了「淺編碼器和深解碼器」架構,其中編碼器和解碼器都從預訓練的 checkpoints 中進行初始化,并由交叉注意力層連接。此外,該研究還凍結了深度解碼器 LLM,只訓練淺層編碼器和交叉注意力層,從而大大減少了有效調優(yōu)的可訓練參數(shù)數(shù)量。最后,受 NLP 領域的啟發(fā),研究者開始探索 CodeT5 + 在指令調優(yōu)上的效果,以更好地使模型與自然語言指令保持一致。
該研究在 20 多個與代碼相關的基準測試中對 CodeT5 + 進行了廣泛的評估,包括零樣本、微調和指令調優(yōu)。結果表明,與 SOTA 基線相比,CodeT5 + 在許多下游任務上有著實質性的性能提升,例如,8 個文本到代碼檢索任務 (+3.2 avg. MRR), 2 個行級代碼補全任務 (+2.1 avg. Exact Match) 和 2 個檢索增強代碼生成任務 (+5.8 avg. BLEU-4)。
在 MathQA 和 GSM8K 基準上的兩個數(shù)學編程任務中,低于十億參數(shù)大小的 CodeT5 + 模型明顯優(yōu)于許多多達 137B 參數(shù)的 LLM。特別是,在 HumanEval 基準上的零樣本文本到代碼生成任務中,指令調優(yōu)后的 CodeT5+ 16B 與其他開源代碼 LLM 相比,達到了新的 SOTA 結果,為 35.0% pass@1 和 54.5% pass@10,甚至超過了閉源 OpenAI code- cusherman -001 模型。最后,該研究發(fā)現(xiàn) CodeT5 + 可以無縫的看作半?yún)?shù)檢索增強生成系統(tǒng),在代碼生成方面明顯優(yōu)于其他類似方法。所有的 CodeT5 + 模型都將開源,以支持研究和開發(fā)者社區(qū)。
CodeT5+:開源大型語言模型
本文開發(fā)了 CodeT5+,一個新的開源代碼大型語言模型家族,用于代碼理解和生成任務。基于編碼器 - 解碼器架構,CodeT5 + 通過本文提出的在單模態(tài)和雙模態(tài)數(shù)據(jù)上混合預訓練目標的方式,增強了在不同下游任務中以不同模式運行的靈活性。
架構細節(jié)

預訓練細節(jié)
在單模態(tài)預訓練階段,研究者使用大量的代碼數(shù)據(jù),用計算高效的目標預訓練模型。在雙模態(tài)預訓練階段,繼續(xù)用較小的具有跨模態(tài)學習目標的代碼 - 文本數(shù)據(jù)集預訓練模型。對于每個階段,使用相同的權重聯(lián)合優(yōu)化多個預訓練目標。
研究者發(fā)現(xiàn)這種分階段訓練方法可以有效地讓模型接觸更多樣化的數(shù)據(jù),以學習豐富的上下文表征。此外,他們探索了用現(xiàn)成的代碼 LLM 初始化 CodeT5+,以有效地擴展模型。最后,CodeT5 + 中的模型組件可以動態(tài)組合以適應不同的下游應用任務。
實驗
研究者實現(xiàn)了一系列 CodeT5 + 模型,模型大小從 220M 到 16B 不等。
CodeT5+ 220M 和 770M 采用與 T5 相同的架構,并從頭開始進行預訓練,而 CodeT5+ 2B、6B、16B 采用「淺層編碼器和深層解碼器」架構,編碼器分別從 CodeGen-mono 350M 初始化,解碼器從 CodeGen-mono 2B、6B、16B 初始化。研究者將 CodeT5 + 與 SOTA 代碼模型進行了比較,這些 LLM 可以分為 3 種類型:純編碼器、純解碼器和編碼器 - 解碼器模型。
文本到代碼生成任務的零樣本評估
在給定自然語言規(guī)范的情況下,研究者評估了模型在零樣本設置下生成 Python 代碼的能力,通過在單元測試中測試生成的代碼來評估模型性能。表 2 中展示了合格率 pass@k。

評估數(shù)學編程任務
研究者同時考察了其他代碼生成任務,特別是兩個數(shù)學編程基準 MathQAPython 和 GSM8K 。如表 3 所示,CodeT5 + 取得了顯著的性能提升,超過了許多更大規(guī)模的代碼 LLM。

圖 6 展示了通過 MathQA-Python 上數(shù)學編程問題的復雜性來分析模型性能。對于每個問題,提取解決問題所需的推理步驟數(shù)。與 CodeT5 相比,CodeT5 + 對問題的復雜性 (即所需的推理步驟數(shù)量) 更魯棒。

評估代碼摘要任務
代碼摘要任務旨在將代碼片段總結為自然語言文檔字符串。研究者使用了六種編程語言的 Clean 版本的 CodeSearchNet 數(shù)據(jù)集來評估這項任務的模型。
從表 4 中可以發(fā)現(xiàn),編碼器 - 解碼器模型 (CodeT5 和 CodeT5+) 的性能通常優(yōu)于純編碼器模型、純解碼器模型以及 UniLM-style 的模型 UniXcoder 。

評估代碼補全任務
研究者通過 line-level 補全任務評估了 CodeT5 + 僅解碼器的生成能力,旨在根據(jù)上下文完成下一行代碼。
如表 5 所示,CodeT5+(在純解碼器的模式下) 和純解碼器模型 (top block) 的性能都明顯優(yōu)于編碼器 - 解碼器模型(the middle block),驗證了純解碼器的模型可以更好地適應代碼補全任務。

評估文本到代碼的檢索任務
研究者還通過跨多個 PL 的文本到代碼檢索任務評估 CodeT5 + 的代碼理解能力。
從表 6 中可以看出,CodeT5+ 220M 明顯優(yōu)于所有現(xiàn)有的純編碼器 / 純解碼器模型 (頂部塊) 和編碼器 - 解碼器模型 (中間塊)。

更多研究細節(jié),可參考原論文。