無編碼器架構潛力或被低估,首個無編碼器3D多模態(tài)LLM大模型來了
本文一作湯軼文本科畢業(yè)于上海科技大學,導師是李學龍教授,在上海人工智能實驗室實習。他的研究興趣是 3D 視覺,大模型高效遷移,多模態(tài)大模型和具身智能等。主要工作有 Any2Point, Point-PEFT, ViewRefer 等。

- 論文標題: Exploring the Potential of Encoder-free Architectures in 3D LMMs
- 作者單位:上海人工智能實驗室,西北工業(yè)大學,香港中文大學,清華大學
- 代碼鏈接:https://github.com/Ivan-Tang-3D/ENEL
- 論文鏈接:https://arxiv.org/pdf/2502.09620v1
許多近期的研究致力于開發(fā)大型多模態(tài)模型(LMMs),使 LLMs 能夠解讀多模態(tài)信息,如 2D 圖像(LLaVA)和 3D 點云(Point-LLM, PointLLM, ShapeLLM)。主流的 LMM 通常是依賴于強大但計算量大的多模態(tài)編碼器(例如,2D 的 CLIP 和 3D 的 I2P-MAE)。
雖然這些預訓練編碼器提供了強大的多模態(tài)嵌入,富含預先存在的知識,但它們也帶來了挑戰(zhàn),包括無法適應不同的點云分辨率,以及編碼器提取的點云特征無法滿足大語言模型的語義需求。
因此,作者首次全面研究了無編碼器架構在 3D 大型多模態(tài)模型中應用的潛力,將 3D 編碼器的功能直接整合到 LLM 本身。最終,他們展示了首個無編碼器架構的 3D LMM—ENEL,其 7B 模型與當前最先進的 ShapeLLM-13B 相媲美,表明無編碼器架構的巨大潛力。
背景和動機
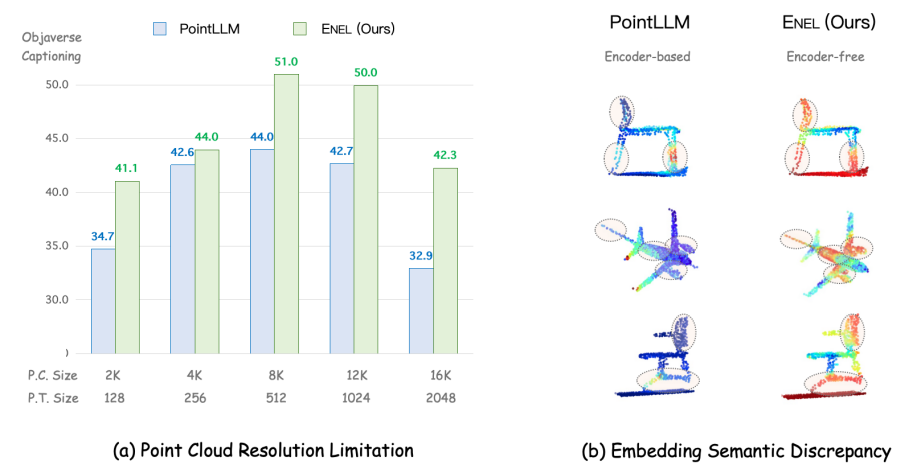
對于 3D LMMs,基于編碼器的架構有以下潛在缺點:
- 點云分辨率限制:3D 編碼器通常在固定分辨率的點云數據上進行預訓練,例如 PointLLM 的編碼器 Point-BERT 使用 1,024 個點。然而,在推理過程中,輸入點云的分辨率可能會有所不同(例如,8,192 個點或 512 個點)。訓練和推理分辨率之間的差異可能導致在提取 3D 嵌入時丟失空間信息,從而使 LLMs 理解變得困難。如(a)所示,PointLLM 在不同的點云分辨率輸入下性能差異過大,而我們提出的 ENEL 顯示出了一定的魯棒性。
- 嵌入語義差異:3D 編碼器通常采用自監(jiān)督方法(如掩碼學習和對比學習)進行預訓練,但 3D 編碼器和大語言模型的訓練分離導致訓練目標可能與 LLMs 的特定語義需求不一致,無法捕捉到 LLMs 理解 3D 物體所需的最相關語義。即使使用投影層將 3D 編碼器與 LLMs 連接,簡單的 MLP 也往往不足以進行完全的語義轉換。如圖(b)所示,ENEL 架構中 text token 更能關注到點云物體的關鍵部位,如椅腳和機翼。
具體方案
作者選擇 PointLLM 作為基準模型進行探索,并使用 GPT-4 評分標準在 Objaverse 數據集上評估不同策略的表現。在無編碼器結構的探索中他們提出以下兩個問題:
- 如何彌補 3D 編碼器最初提取的高層次 3D 語義?在 3D LMMs 中,完全跳過編碼器會導致難以捕捉 3D 點云的復雜空間結構。
- 如何將歸納偏置整合到 LLM 中,以便更好地感知 3D 幾何結構?傳統(tǒng)的 3D 編碼器通常將顯式的歸納偏置嵌入到其架構中,以逐步捕捉多層次的 3D 幾何。例如,像 Point-M2AE 這樣的模型使用局部到全局的層次結構,這一概念在 2D 圖像處理的卷積層中也很常見。
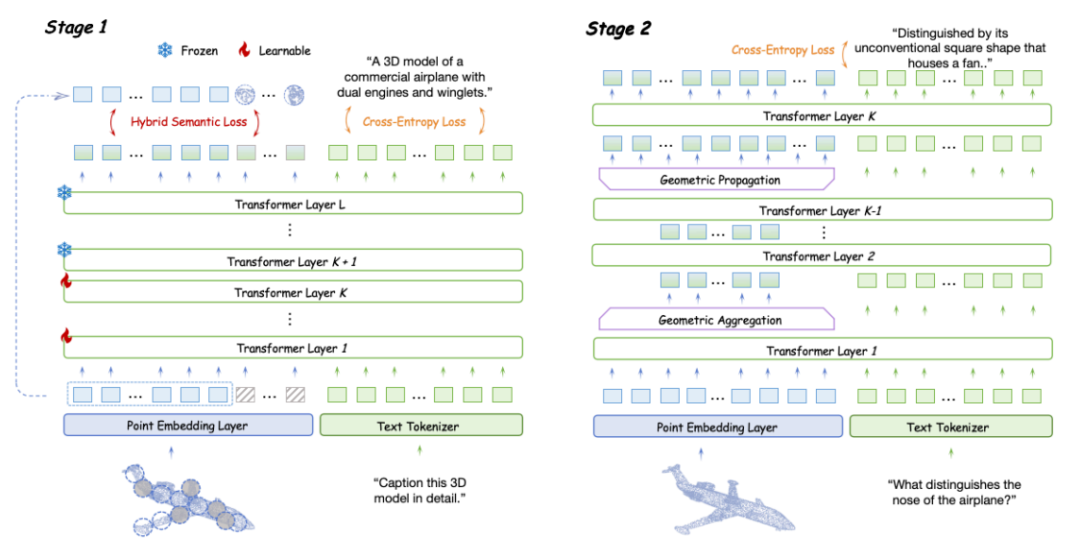
LLM 嵌入的語義編碼
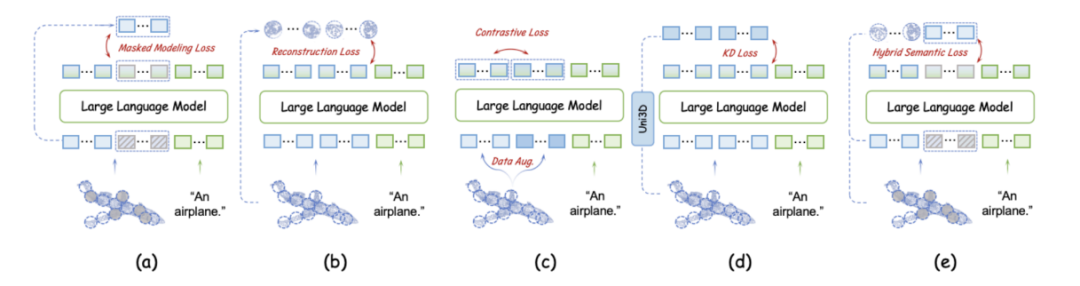
因為缺乏 3D 編碼器導致點云語義信息的編碼不足,極大地阻礙了 LLM 理解點云的結構細節(jié)。現有的大多數 3D 編碼器使用自監(jiān)督損失將點云的高層語義嵌入到 Transformer 中,主要分為四種類型:掩蔽建模損失 (a)、重建損失 (b)、對比損失 (c) 和知識蒸餾損失 (d)。基于 token embedding 模塊和 LLM 可學習層,作者在預訓練階段實現并評估了這些損失對無編碼器 3D LMM 的影響,并提出混合語義損失。
- 點云自監(jiān)督學習損失通常有助于無編碼器 3D LMM。自監(jiān)督學習損失通過特定的任務設計對復雜的點云進行變換,促使 LLM 學習潛在的幾何關系和高層次的語義信息。
- 在這些自監(jiān)督學習損失中,掩蔽建模損失展示了最強的性能提升。掩蔽比率與訓練優(yōu)化難度直接相關,從 30% 增加到 60% 會導致性能下降。此外,顯式重建點云 patch 不如掩蔽建模有效,但有助于 LLM 學習點云中的復雜模式。相比前兩種損失,知識蒸餾損失的效果較差。最后,對比損失未能提取詳細的語義信息,表現最差。
- 基于上述實驗結果,作者提出混合語義損失 (Hybrid Semantic Loss),他們對于掩蔽部分采用掩蔽建模,而對于可見部分,他們使用重建策略。這種方法不僅將高層次的語義嵌入 LLM 中,而且確保在整個點云學習過程中保持幾何一致性。
層次幾何聚合策略
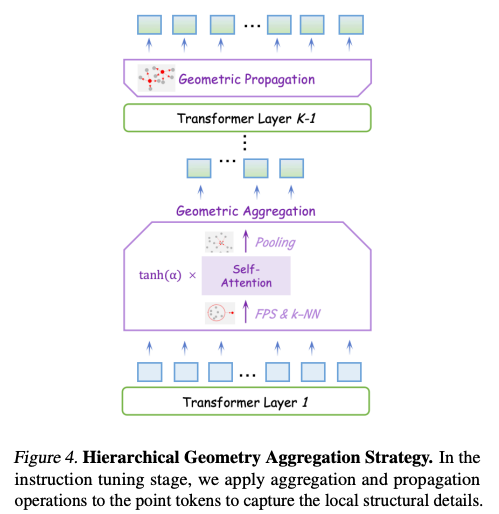
在無編碼器架構中,LLM 本身并沒有明確的局部建模模塊。自注意力機制主要用于建模全局交互。因此,基于提出的混合語義損失,作者在指令調優(yōu)階段探索如何使 LLM 主動感知 3D 局部細節(jié),并補充學到的全局語義。為此,他們提出了層次幾何聚合策略。
- 從 LLM 的第二層開始,輸入的點云 token 基于它們對應的坐標使用最遠點采樣進行下采樣,將 token 數量從 M 減少到??/2, 作為局部中心。然后,使用 k-NN 算法獲得鄰近點。針對鄰近點他們采用門控自注意力機制進行組內交互,捕捉局部幾何結構。最后,他們應用池化操作融合每個鄰居的特征,結果特征長度為 M/2。總共進行 l-1 次幾何聚合。
- 為了確保 LLM 充分提取局部信息,作者選擇在聚合操作后經過多層 LLM 層進行進一步的語義建模,避免丟失細粒度的幾何細節(jié)。
- 隨后,他們進行 l 次幾何傳播。按照 PointNet++ 的方法,他們將聚合后的特征從局部中心點傳播到它們周圍的 k 個鄰近點,經過 l 次后重新得到長度為 M 的點云特征。
定量分析
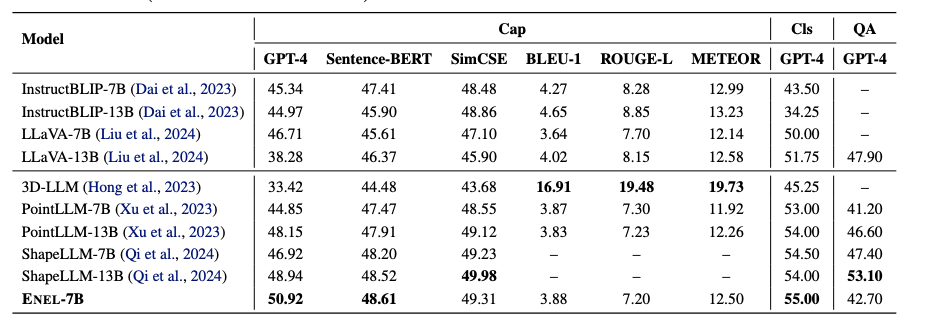
- 在 Objaverse 基準測試中,ENEL-7B 在 3D 物體描述任務中取得了 50.92% 的 GPT-4 得分,創(chuàng)下了新的 SOTA 性能。在傳統(tǒng)指標中,SentenceBERT 和 SimCSE 分別達到了 48.61% 和 49.31% 的得分,表現與 ShapeLLM-13B 相當。對于 3D 物體分類任務,ENEL-7B 超越了先前基于編碼器的 3D LMMs,取得了 55% 的 GPT 得分。
- 此外,在 3D MM-Vet 數據集的 3D-VQA 任務上,盡管訓練集中缺乏空間和具身交互相關的數據,ENEL 仍取得了 42.7% 的 GPT 得分,超過了 PointLLM-7B 1.5%。
- 考慮到與 PointLLM 相同的訓練數據集,這些結果驗證了作者提出的 LLM 嵌入式語義編碼和層次幾何聚合策略在無編碼器架構中的有效性。
實現、訓練和推理細節(jié)
作者使用 7B Vicuna v1.1 的檢查點。在嵌入層中,點云首先通過一個線性層處理,將其維度從 6 擴展到 288。輸入點云初始包含 8192 個點,隨后經過三次最遠點采樣(FPS),分別將點云數量減少到 512、256 和 128。每次 FPS 操作后,使用 k 近鄰進行聚類,聚類大小為 81,并通過三角編碼提取幾何特征,隨后通過線性層逐步將維度增加到 576、1152 和 2304。最后,投影層將特征映射到 LLM 的 4096 維度。
在兩階段訓練過程中,每個階段使用的數據集和預處理方法與 PointLLM 一致。所有訓練均在 4 張 80G 的 A100 GPU 上以 BF16 精度進行,使用了 FlashAttention、AdamW 優(yōu)化器以及余弦學習率調度策略。在預訓練階段,模型訓練了 3 個 epoch,批量大小為 128,學習率為 4e-4。在指令微調階段,訓練進行了 3 個 epoch,批量大小為 32,學習率為 2e-5。
用于分類和描述任務評估的 GPT-4 模型為「gpt-4-0613」版本,與 PointLLM 一致;而用于問答性能評估的 GPT-4 模型為「gpt-4-0125」版本,與 ShapeLLM 對齊。