













探索更強(qiáng)中文 Embedding 模型:Conan-Embedding
作者 | ethanntang

一、引言
1.概述
隨著大模型時(shí)代的爆發(fā),檢索增強(qiáng)生成技術(shù)(RAG)在大語(yǔ)言模型中廣泛應(yīng)用。RAG是一種性價(jià)比極高的方案,在大語(yǔ)言模型中占據(jù)重要地位。Embedding模型作為RAG中檢索召回的重要一環(huán),扮演著極其關(guān)鍵的角色。更加準(zhǔn)確的Embedding模型在抑制模型幻覺(jué)、增強(qiáng)新熱知識(shí)表現(xiàn)、提升封閉領(lǐng)域回答能力等方面都能發(fā)揮優(yōu)勢(shì)。
為了提升RAG系統(tǒng)的性能表現(xiàn),我們近期針對(duì)如何訓(xùn)練更強(qiáng)的Embedding模型進(jìn)行探索,訓(xùn)練得到了目前最強(qiáng)中文Embedding模型「Conan-Embedding」,該模型已在C-MTEB上達(dá)到SOTA。
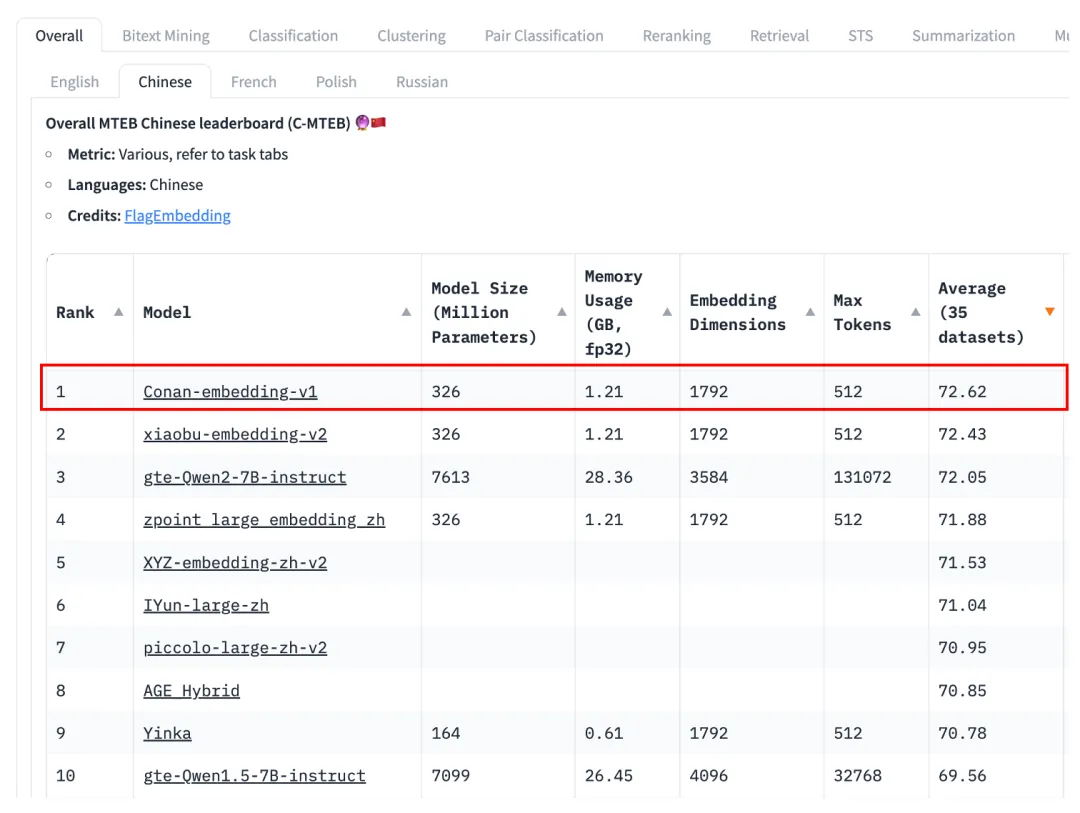
圖1 C-MTEB榜單結(jié)果
模型鏈接:TencentBAC/Conan-embedding-v1 · Hugging Face (模型已上傳開源,歡迎試用)
評(píng)測(cè)榜單:MTEB Leaderboard - a Hugging Face Space by mteb
2.背景介紹
Embedding是一種將高維數(shù)據(jù)轉(zhuǎn)換為低維向量表示的技術(shù),它在自然語(yǔ)言處理、計(jì)算機(jī)視覺(jué)等領(lǐng)域有廣泛應(yīng)用。例如,在文本中,一個(gè)詞或短語(yǔ)會(huì)被轉(zhuǎn)換成一個(gè)固定長(zhǎng)度的向量,這個(gè)向量能夠捕捉詞義和上下文信息。通過(guò) Embedding 模型,可以計(jì)算句子間的相似度,應(yīng)用于檢索,分類,召回,排序等諸多任務(wù)。
目前,Embedding模型已經(jīng)取得了顯著進(jìn)展。例如,Word2Vec、GloVe 等模型能夠生成高質(zhì)量的詞嵌入向量。Transformer架構(gòu)的出現(xiàn),進(jìn)一步推動(dòng)了Embedding模型的進(jìn)步。BERT、GPT等預(yù)訓(xùn)練語(yǔ)言模型通過(guò)大規(guī)模數(shù)據(jù)集訓(xùn)練,生成了更加豐富和精確的詞嵌入表示。
通常,Embedding模型是通過(guò)對(duì)比學(xué)習(xí)來(lái)訓(xùn)練的,而負(fù)樣本的質(zhì)量對(duì)模型性能至關(guān)重要。難負(fù)例挖掘就是利用 Teacher 模型,來(lái)找到與Query有一定相關(guān)性但不如正樣本相關(guān)的段落,從而使對(duì)比損失更難區(qū)分正例和負(fù)例。盡管難負(fù)例挖掘非常重要,但在Embedding工作中,這些方法往往被忽視,研究通常集中在模型架構(gòu)、微調(diào)方法和數(shù)據(jù)選擇上。
二、主要方法
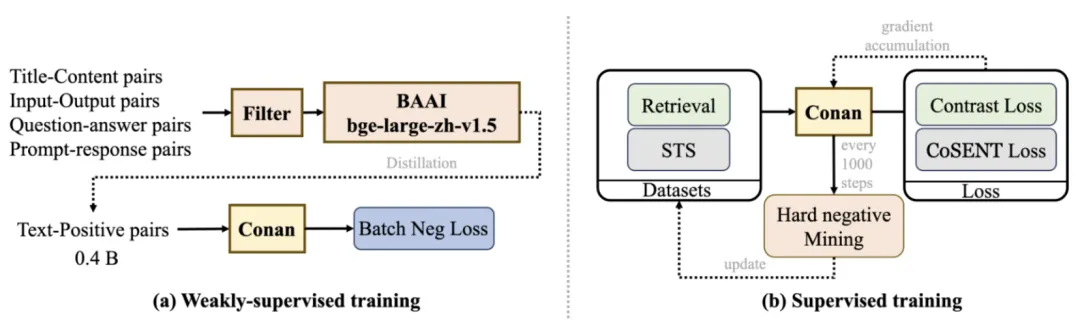
圖2 訓(xùn)練方法概覽
在弱監(jiān)督訓(xùn)練階段,我們收集了 7.5 億對(duì)數(shù)據(jù)集,并從中挑選出 4 億對(duì)。在有監(jiān)督訓(xùn)練階段,使用動(dòng)態(tài)難負(fù)例挖掘策略來(lái)更精確地微調(diào)模型。
Language Embedding模型訓(xùn)練通常采用多階段方案,分為弱監(jiān)督的預(yù)訓(xùn)練以及有監(jiān)督的精調(diào)訓(xùn)練。我們遵循這種訓(xùn)練方式,將訓(xùn)練分為預(yù)訓(xùn)練和微調(diào)兩個(gè)階段。以下介紹了我們的詳細(xì)訓(xùn)練流程和主要的方法,包含了動(dòng)態(tài)的難負(fù)例挖掘和跨GPU的多任務(wù)均衡訓(xùn)練方式。
1.訓(xùn)練流程
(1) 預(yù)訓(xùn)練
如圖2(a)所示,在預(yù)訓(xùn)練階段,我們首先使用Internlm2.5中描述的標(biāo)準(zhǔn)數(shù)據(jù)過(guò)濾方法。首先,通過(guò)文檔提取和語(yǔ)言識(shí)別進(jìn)行格式化處理;接著,在基于規(guī)則的階段,文本會(huì)經(jīng)過(guò)規(guī)范化和啟發(fā)式過(guò)濾;然后,通過(guò)MinHash方法進(jìn)行去重;在安全過(guò)濾階段,執(zhí)行域名阻止、毒性分類和色情內(nèi)容分類;最后,在質(zhì)量過(guò)濾階段,文本會(huì)經(jīng)過(guò)廣告分類和流暢度分類,以確保輸出文本的高質(zhì)量。通過(guò)過(guò)濾,我們篩選了約 4.5 億對(duì)數(shù)據(jù),留存率約60%。
bge-large-zh-v1.5 是由智源發(fā)布的廣泛使用的基礎(chǔ)embedding 模型。我們認(rèn)為,該模型在對(duì)數(shù)據(jù)進(jìn)行評(píng)分時(shí),能夠有效地識(shí)別并保留高質(zhì)量數(shù)據(jù)。在數(shù)據(jù)經(jīng)過(guò)標(biāo)準(zhǔn)過(guò)濾后,我們使用bge-large-zh-v1.5模型對(duì)每一條數(shù)據(jù)進(jìn)行評(píng)分,丟棄所有得分低于0.4的數(shù)據(jù)。通過(guò)評(píng)分,我們篩選了約 4 億對(duì)數(shù)據(jù),留存率約 89%。
在預(yù)訓(xùn)練階段,為了高效且充分地利用數(shù)據(jù),我們使用InfoNCE Loss with In-Batch Negative:
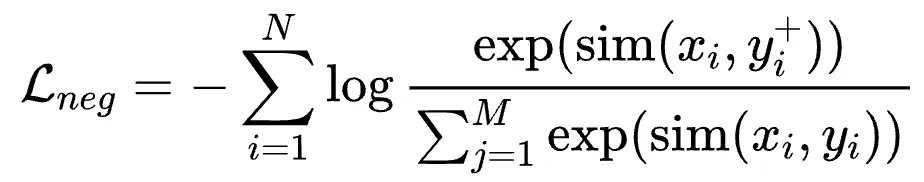
其中是title,input,question,prompt等,是對(duì)應(yīng)的 content,output,answer,response等,認(rèn)為是正樣本;是同 batch 其他樣本的content,output,answer,response,認(rèn)為是負(fù)樣本。In-Batch Negative InfoNCE Loss 是一種用于對(duì)比學(xué)習(xí)的損失函數(shù),它利用了 mini-batch 中的其他樣本作為負(fù)樣本來(lái)優(yōu)化模型。具體來(lái)說(shuō),在每個(gè) mini-batch 中,除了目標(biāo)樣本的正樣本對(duì)外,其余樣本都被視為負(fù)樣本。通過(guò)最大化正樣本對(duì)的相似度并最小化負(fù)樣本對(duì)的相似度,In-Batch Negative InfoNCE Loss 能夠有效地提高模型的判別能力和表征學(xué)習(xí)效果。這種方法通過(guò)充分利用 mini-batch 中的樣本,提升了訓(xùn)練效率并減少了對(duì)額外負(fù)樣本生成的需求。
(2) 有監(jiān)督精調(diào)
微調(diào)階段,我們針對(duì)不同的下游任務(wù)進(jìn)行特定任務(wù)的微調(diào)。如圖2(b)所示,我們參考以往的工作,并在其基礎(chǔ)上移除了分類(CLS)任務(wù),將任務(wù)分為兩類:檢索(Retrieval)和語(yǔ)義文本相似性(STS)。檢索任務(wù)包括查詢、正樣本和負(fù)樣本,經(jīng)典的損失函數(shù)是InfoNCE Loss。STS任務(wù)涉及區(qū)分兩段文本之間的相似性,經(jīng)典的損失函數(shù)是交叉熵?fù)p失。在STS任務(wù)上,根據(jù)以往工作的結(jié)論,CoSENT損失略優(yōu)于交叉熵?fù)p失。因此,我們也采用CoSENT損失來(lái)優(yōu)化STS任務(wù):

其中是縮放溫度,是余弦相似度函數(shù),是 和之間的相似性。
2.動(dòng)態(tài)難負(fù)例挖掘訓(xùn)練
在embedding模型準(zhǔn)備數(shù)據(jù)時(shí),難負(fù)例挖掘用于為query選擇負(fù)樣本。其思想是使用一個(gè) teacher模型來(lái)找到與query有一定相關(guān)性但不如正樣本相關(guān)的段落,從而使對(duì)比損失更難區(qū)分正例和負(fù)例。這些難負(fù)例應(yīng)該比隨機(jī)負(fù)例更難與正例區(qū)分,從而帶來(lái)更高效和更有效的微調(diào)。
先前的工作基本都在數(shù)據(jù)預(yù)處理階段進(jìn)行難負(fù)例挖掘。對(duì)于Embedding模型來(lái)說(shuō),一個(gè)既定的權(quán)重狀態(tài)下的模型,難負(fù)例是一定的。然而,隨著訓(xùn)練的進(jìn)行,每當(dāng)模型權(quán)重更新時(shí),當(dāng)前權(quán)重下的模型對(duì)應(yīng)的難負(fù)例就會(huì)變化。在數(shù)據(jù)預(yù)處理階段挖掘的難負(fù)例在經(jīng)過(guò)訓(xùn)練迭代后,就會(huì)變得不那么難了。基于這一觀點(diǎn),我們提出了一種動(dòng)態(tài)難負(fù)例挖掘方法。對(duì)于每個(gè)數(shù)據(jù),我們記錄當(dāng)前難先前的工作基本都在數(shù)據(jù)預(yù)處理階段進(jìn)行難負(fù)例挖掘。對(duì)于Embedding模型來(lái)說(shuō),一個(gè)既定的權(quán)重狀態(tài)下的模型,難負(fù)例是一定的。然而,隨著訓(xùn)練的進(jìn)行,每當(dāng)模型權(quán)重更新時(shí),當(dāng)前權(quán)重下的模型對(duì)應(yīng)的難負(fù)例就會(huì)變化。在數(shù)據(jù)預(yù)處理階段挖掘的難負(fù)例在經(jīng)過(guò)訓(xùn)練迭代后,就會(huì)變得不那么難了。
基于這一觀點(diǎn),我們提出了一種動(dòng)態(tài)難負(fù)例挖掘方法。對(duì)于每個(gè)數(shù)據(jù),我們記錄當(dāng)前難負(fù)例與Query的平均分?jǐn)?shù)。每 100 次迭代后,如果分?jǐn)?shù)的 1.15 倍小于初始分?jǐn)?shù)且分?jǐn)?shù)絕對(duì)值小于 0.8時(shí),我們就認(rèn)為該負(fù)例不再困難,并進(jìn)行新一輪的難負(fù)例挖掘。每次進(jìn)行動(dòng)態(tài)難負(fù)例挖掘時(shí),如果需要替換難負(fù)例,我們使用到個(gè)案例作為負(fù)樣本,其中表示第次替換,表示每次使用的難負(fù)例數(shù)。整個(gè)過(guò)程產(chǎn)生的成本僅相當(dāng)于一個(gè) step迭代。相比于In-Batch Negative InfoNCE Loss,我們認(rèn)為更高質(zhì)量(更符合當(dāng)前模型權(quán)重下)的難負(fù)例更為重要。圖3 展示了動(dòng)態(tài)難負(fù)例挖掘與標(biāo)準(zhǔn)難負(fù)例挖掘的樣本正負(fù)例Score - Steps 變化曲線。可以看到,隨著步數(shù)的增加,Standard-HNM的負(fù)例評(píng)分不再下降,而是出現(xiàn)震蕩,這表明模型對(duì)該批負(fù)例的學(xué)習(xí)已完成。而Dynamic-HDM在檢測(cè)到負(fù)例學(xué)習(xí)完畢后,會(huì)進(jìn)行難負(fù)例的替換。。
圖3 展示了動(dòng)態(tài)難負(fù)例挖掘與標(biāo)準(zhǔn)難負(fù)例挖掘的樣本正負(fù)例Score - Steps 變化曲線。可以看到,隨著步數(shù)的增加,Standard-HNM的負(fù)例評(píng)分不再下降,而是出現(xiàn)震蕩,這表明模型對(duì)該批負(fù)例的學(xué)習(xí)已完成。而Dynamic-HDM在檢測(cè)到負(fù)例學(xué)習(xí)完畢后,會(huì)進(jìn)行難負(fù)例的替換。
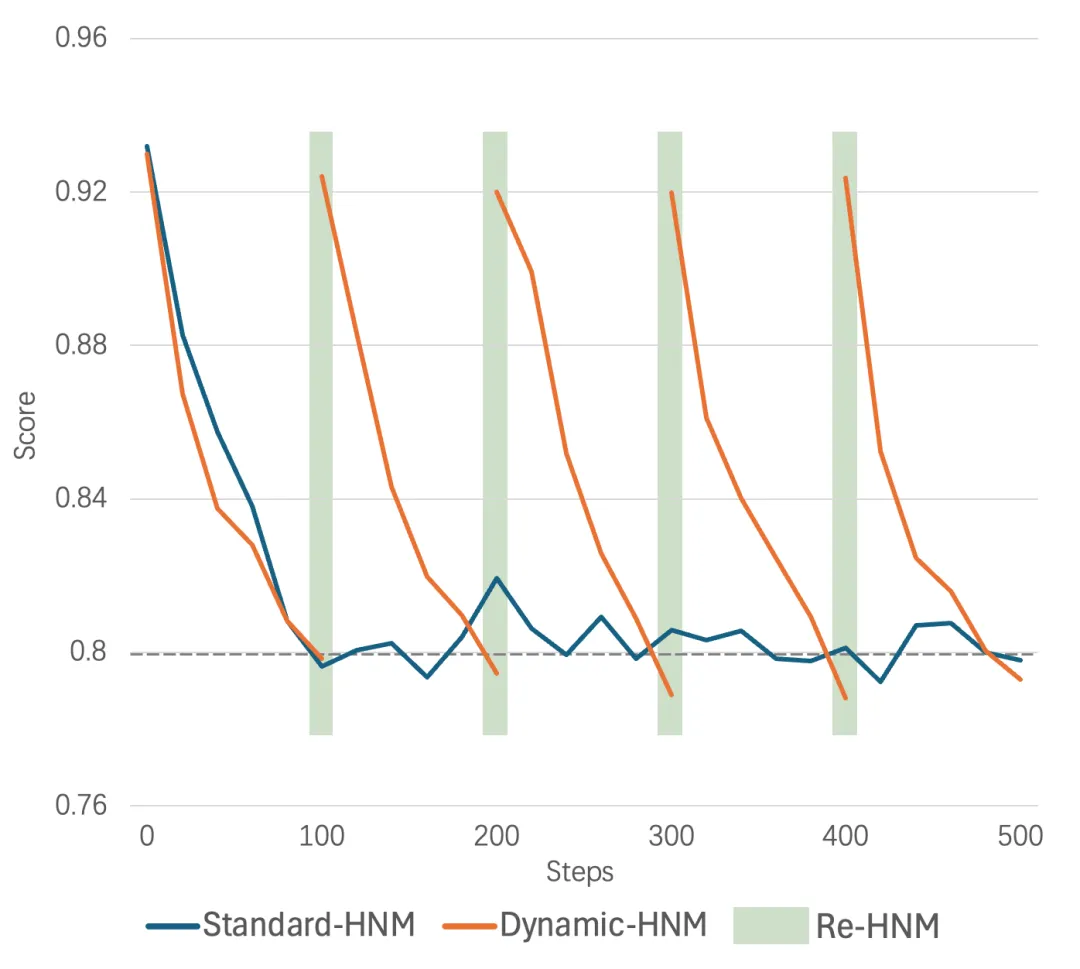
圖3 動(dòng)態(tài)難負(fù)例挖掘與標(biāo)準(zhǔn)難負(fù)例挖掘的樣本正負(fù)例Score-Steps變化曲線。
在訓(xùn)練過(guò)程中,每 100steps 檢查一次難負(fù)例。當(dāng)分?jǐn)?shù)的 1.15 倍小于初始得分,且分?jǐn)?shù)絕對(duì)值小于 0.8 時(shí),我們認(rèn)為該負(fù)例不再困難,并替換成新的難負(fù)例。
3.跨GPU的Batch均衡訓(xùn)練

圖4 跨 GPU 的Batch均衡訓(xùn)練的示意圖
對(duì)于Retri任務(wù),我們利用多個(gè) GPU 來(lái)合并更多難負(fù)例。對(duì)于 STS 任務(wù),我們?cè)黾覤atchSize以包含更多樣本進(jìn)行學(xué)習(xí),以獲得更魯棒的排名關(guān)系。
為了更好地利用難樣本,我們采用了跨 GPU 批次平衡損失 (CBB)。之前的方案通常在訓(xùn)練流程中隨機(jī)的在每個(gè)Batch中分配一個(gè)任務(wù)。例如:在iter0中采樣STS的樣本,并使用STS對(duì)應(yīng)Loss進(jìn)行反向傳播獲取梯度并更新權(quán)重,而iter1中分配了Retri任務(wù)或者CLS任務(wù),我們稱之為順序隨機(jī)任務(wù)訓(xùn)練。這樣訓(xùn)練幾乎一定會(huì)導(dǎo)致單次的優(yōu)化搜索空間與Embedding模型的全局優(yōu)化搜索空間不一致,從而導(dǎo)致訓(xùn)練過(guò)程的震蕩以及無(wú)法求得全局最優(yōu)解。我們?cè)谥蟮姆治鲋姓宫F(xiàn)了這一現(xiàn)象。
為此,我們考慮在每次的Forward-Loss-Backward-Update的更新過(guò)程中都均衡的引入每一個(gè)任務(wù),以此來(lái)獲得穩(wěn)定的搜索空間,并盡可能的縮小單次模型更新方向和全局最優(yōu)解的一致性。因此,CBB策略不僅考慮了不同 GPU 之間的通信,還考慮了不同任務(wù)之間的通信,從而實(shí)現(xiàn)了更好的Batch均衡。如圖4所示,為了在檢索任務(wù)中利用更多難樣本,我們確保 GPU(gpu0、gpu1、gpu2、gpu3)各自具有不同的負(fù)樣本,同時(shí)共享相同的查詢和相同的正樣本。對(duì)于Retri任務(wù),每個(gè) GPU 計(jì)算對(duì)應(yīng)Batch的Loss,然后將結(jié)果匯總到 gpu1 上。對(duì)于STS任務(wù),在gpu4上,運(yùn)行STS任務(wù)并獲得對(duì)應(yīng)Loss。最終匯總并計(jì)算當(dāng)前Iter的合并 CBB Loss。對(duì)應(yīng)公式如下:
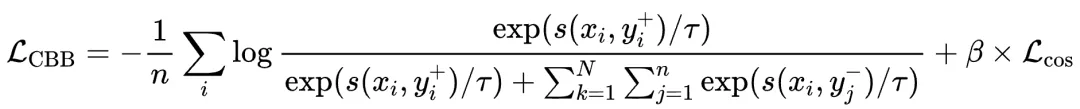
其中是 Query 和正樣本段落之間的評(píng)分函數(shù),通常定義為余弦相似度,是查詢和正樣本段落共享的GPU數(shù)量,是縮放溫度。根據(jù)經(jīng)驗(yàn),我們將設(shè)置為 0.8。
三、實(shí)驗(yàn)
1.實(shí)驗(yàn)細(xì)節(jié)
與大多數(shù)Embedding模型一樣,Conan-Embedding也采用BERT模型作為基礎(chǔ)模型,并使用FC Layer將輸出維度從1024擴(kuò)展到1792。模型的參數(shù)量為326M。Conan-Embedding的最大輸入長(zhǎng)度為 512 個(gè) token。此外,受到 OpenAI的text-embedding-v3的啟發(fā),我們還利用了多尺度表征學(xué)習(xí)(Matryoshka Representation Learning, MRL)技術(shù)來(lái)實(shí)現(xiàn)靈活的輸出維度長(zhǎng)度,提升模型表征性能和魯棒性。對(duì)于 MRL 訓(xùn)練,表示維度配置為256、 512、 768、1024、1536 和 1792。
為了提高效率,我們使用了混合精度訓(xùn)練和 DeepSpeed ZERO-Stage 1。
弱監(jiān)督預(yù)訓(xùn)練階段,我們使用 AdamW優(yōu)化器,初始學(xué)習(xí)率為 1e-5,Warmup設(shè)置為 0.05,Decay設(shè)置為 0.001。整個(gè)預(yù)訓(xùn)練過(guò)程使用了 64張華為Ascend 910B GPU,單次精調(diào)訓(xùn)練約消耗138 個(gè)小時(shí)。
有監(jiān)督精調(diào)階段,檢索任務(wù)的BatchSize設(shè)置為 4,STS 任務(wù)的BatchSize設(shè)置為32。我們使用了與預(yù)訓(xùn)練階段相同的優(yōu)化器參數(shù)和學(xué)習(xí)率。整個(gè)微調(diào)過(guò)程使用了 16 張華為Ascend 910B GPU,單次精調(diào)訓(xùn)練約消耗13 個(gè)小時(shí)。
2.數(shù)據(jù)情況
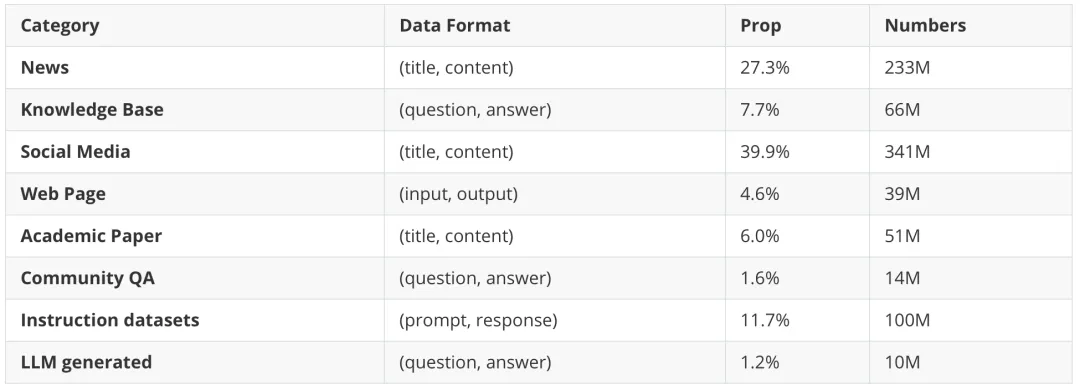
在預(yù)訓(xùn)練階段,我們收集了約7.5 億個(gè)文本對(duì),包含Wudao、Zhihu-KOL、SimCLUE等,數(shù)據(jù)分為標(biāo)題-內(nèi)容對(duì)、輸入-輸出對(duì)和問(wèn)答對(duì)等。我們還發(fā)現(xiàn),高質(zhì)量的 LLM 指令調(diào)優(yōu)數(shù)據(jù)(例如:提示-響應(yīng)對(duì))經(jīng)過(guò)規(guī)則過(guò)濾和篩選后,可以提升 Embedding 模型的性能。此外,我們利用現(xiàn)有的文本語(yǔ)料庫(kù),使用 LLM 生成了一批數(shù)據(jù)。詳細(xì)的數(shù)據(jù)描述可以在下表中展示:
表1 預(yù)訓(xùn)練數(shù)據(jù)概覽
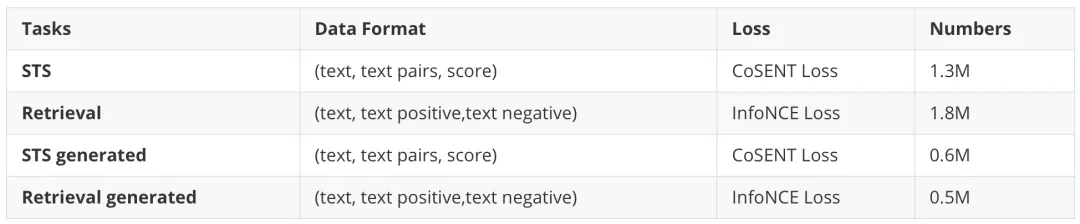
在精調(diào)階段,為了讓模型更適應(yīng)各種任務(wù),我們選擇了常見(jiàn)的Retri、CLS和 STS數(shù)據(jù)集。對(duì)于CLS任務(wù),我們將它與Retri合并,將同一類別的數(shù)據(jù)視為文本正例,將不同類別的數(shù)據(jù)視為文本負(fù)例。微調(diào)階段使用的數(shù)據(jù)量如下表所示:
表2 精調(diào)訓(xùn)練數(shù)據(jù)概覽
3.結(jié)果
(1) 消融實(shí)驗(yàn)結(jié)果
為了證明我們方法的有效性,我們?cè)?CMTEB 基準(zhǔn)上進(jìn)行了全面的消融研究。如下表所示,動(dòng)態(tài)難負(fù)樣本挖掘(DHNM)和跨 GPU 批次平衡(CBB)都明顯優(yōu)于直接微調(diào)模型的Vanilla方法。除此之外,Conan-Embedding在Retri和Rerank任務(wù)中表現(xiàn)出顯著的改進(jìn),這表明隨著負(fù)樣本數(shù)量的增加和質(zhì)量的提高,模型能夠看到更具有學(xué)習(xí)價(jià)值的難負(fù)樣本,從而增強(qiáng)了其召回能力。
表3 消融實(shí)驗(yàn)結(jié)果
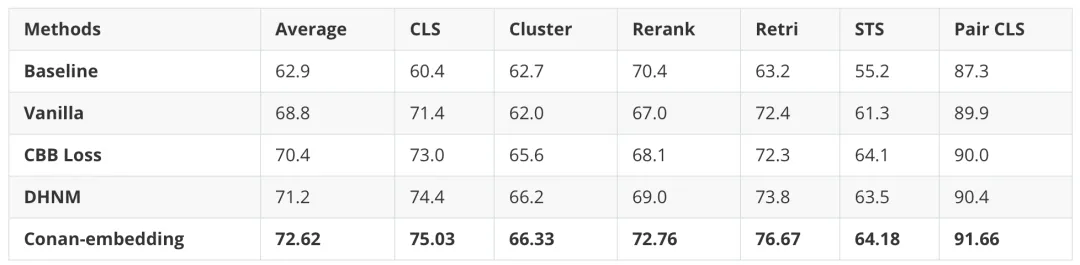
Baseline 表示我們?cè)陬A(yù)訓(xùn)練階段之后的結(jié)果;Vanilla 表示直接使用標(biāo)準(zhǔn)對(duì)比和 CoSENT 損失進(jìn)行微調(diào);
DHNM 表示僅使用動(dòng)態(tài)硬負(fù)挖掘方法;CBB Loss 表示僅使用跨 GPU 批次平衡損失。
(2) C-MTEB結(jié)果
MTEB(Massive Text Embedding Benchmark)是評(píng)估大規(guī)模文本Embedding模型的最權(quán)威和最流行的基準(zhǔn)。MTEB創(chuàng)建了一個(gè)中文 Embedding評(píng)估Benchmark,稱為 C-MTEB。C-MTEB 有 35 個(gè)數(shù)據(jù)集,涵蓋 6 個(gè)類別:分類、聚類、文本對(duì)分類、重排序、檢索和 STS。下表展示了我們的模型與 C-MTEB 基準(zhǔn)上其他模型的比較。我們的模型在幾乎所有任務(wù)上都超越了之前最先進(jìn)的模型,包含參數(shù)量更大的Decoder-Only模型。
表4 C-MTEB結(jié)果

4.分析
為了更好地評(píng)估跨GPU多任務(wù)批次均衡的效果,我們?cè)趫D5展示了使用CBB策略前后的Loss-Iter曲線。loss_retri和loss_STS代表在不啟用CBB策略時(shí),多個(gè)任務(wù)隨機(jī)按Iter進(jìn)行訓(xùn)練時(shí),兩個(gè)任務(wù)的獨(dú)立Loss。可以觀察到,在不啟用CBB策略時(shí),每個(gè)獨(dú)立任務(wù)的Loss震蕩都比較嚴(yán)重,并且下降緩慢,且不同步。以上現(xiàn)象說(shuō)明,不同的任務(wù)之間優(yōu)化目標(biāo)存在GAP,優(yōu)化方向不一致,且每個(gè)單一優(yōu)化目標(biāo)和全局優(yōu)化目標(biāo)不一致。因此,順序隨機(jī)任務(wù)訓(xùn)練不能在優(yōu)化中取得近似的全局最優(yōu)結(jié)果。loss_cross代表啟用CBB策略時(shí)訓(xùn)練過(guò)程中的Loss-Iter曲線,可以看到,隨著訓(xùn)練的進(jìn)行,Loss在幾乎在非常平穩(wěn)地持續(xù)的下降,最終的Loss(0.08)遠(yuǎn)小于Retri和STS Loss之和(0.38)。CBB策略可以看作是一種正則化策略。

圖5 使用跨GPU多任務(wù)批次均衡(CBB)方法前后的損失曲線比較
四、展望
在實(shí)際業(yè)務(wù)中,由于業(yè)務(wù)體系龐大、業(yè)務(wù)標(biāo)準(zhǔn)靈活多變、不同業(yè)務(wù)標(biāo)準(zhǔn)不一,運(yùn)用Embedding模型配合RAG技術(shù)來(lái)提升實(shí)際業(yè)務(wù)的召回性能、快速適應(yīng)標(biāo)準(zhǔn)變化、降低模型訓(xùn)練開銷,是優(yōu)化成本與精度的不錯(cuò)選擇。
另外,Embedding模型也可以在多業(yè)務(wù)場(chǎng)景下獨(dú)立提供召回服務(wù),目前我們已有Conan- Embedding推理服務(wù)上線提供給業(yè)務(wù)方使用,并能適配多種特征長(zhǎng)度的需求。我們正在推進(jìn)Conan-Embedding在實(shí)際業(yè)務(wù)中的落地,例如:不同體系標(biāo)準(zhǔn)的標(biāo)簽業(yè)務(wù)、推薦系統(tǒng)相似樣本召回、以及通用RAG系統(tǒng)等等。
最后,歡迎大家聯(lián)系我們使用Conan-Embedding,并提出寶貴意見(jiàn)。當(dāng)前訓(xùn)練數(shù)據(jù)可能仍存在短板,不能直接在所有類型業(yè)務(wù)上都取得最佳表現(xiàn),其中還面臨一些有待解決問(wèn)題和算法挑戰(zhàn),非常歡迎大家與我們進(jìn)行合作,推進(jìn)Conan-Embedding技術(shù)探索和迭代,共同解決業(yè)務(wù)落地中的各種問(wèn)題。


























