













大模型商業化落地,用初創企業的靠譜嗎?
自去年年底,ChatGPT 橫空出世后,全球掀起了大模型熱潮。當下,“百模大戰”如火如荼,據說僅國內的大模型,就超過了100個。下場的既有百度、阿里這樣的巨頭,也有二、三線科技公司和為數不少的創業公司。行業充滿了熱情,自然是件好事,但任何科技賽道都逃不過“二八定律”,未來的大模型賽道,又有幾家能笑到最后呢?
時至今日,眾多大模型“后輩”中,能與GPT 相比的就沒有幾個。現實很殘酷,對絕大多數中小型公司來說,大模型的“大”,無論是算力上還是數據上,都是它們難以企及的,不少大模型更像是“打腫臉充胖子”,實際并未達到預期的水準。
而更大的問題,出現在大模型從ToC向ToB的轉變中。
據數據公司SimilarWeb的統計,從5月到6月,ChatGPT的全球流量下降了9.7%,美國境內流量下降了10.3%。大模型在C端的應用似乎暫時達到了天花板,還需要更加“殺手級”的應用出現。而在B端,大模型則展現了驚人的潛力,最直接的表現,就是對之前較為簡單的AI工具的替代。比如智能客服,在大模型的加持下,智能水平較以往有明顯的提升。在代碼生成、金融決策、生命科學等領域,大模型也有極大的想象空間。
對此,企業也表現出了高漲的熱情,由于訓練大模型的成本過高,廣大開發者和企業,還是要選擇某個大模型。但是,正如百度所主張的,大模型正在引發IT架構的巨變,從以往的三層架構向“芯片-框架-模型-應用”四層架構轉變,選擇大模型,正變得像以往企業選擇操作系統、數據庫一樣重。
參考歷史經驗,這需要廠商具備強大的技術水平,以及不斷迭代升級的能力。要滿足可控和合規的要求,也需要廠商有較強的綜合能力,能夠長期穩定的投入人力物力。
其次,大模型廠商不僅僅是提供一個聊天機器人,要針對企業需求,要能夠提供易用性、完備度、安全性、穩定性都有保證的工具鏈。企業用戶的需求各不相同,選擇大模型并不是有強大的通用能力就可以,在關注大模型技術棧完備性的同時,企業還需要選擇適合自身業務的廠商。這要求廠商有充分的產業應用經驗積累,能夠將技術應用到實際業務場景中。
對初創團隊來說,大模型深入行業內落地顯然是很難達到的。即使創始人有比較深厚的行業背景或者技術背景,但初創團隊的不確定性較大,可能因人成事,也可能因關鍵人物的離開而一蹶不振。今年年初,王慧文的光年之外一度是大模型領域最耀眼的創業項目,但隨著他因個人健康原因不得不離開,光年之外也被美團收購和接手。
高昂的投入成本,讓初創公司隨時可能因資金流斷裂倒閉,進而造成企業項目的爛尾。
在Meta開源大模型Llama 2之后,很多大模型創業項目,可以說剛開始就夭折了,遑論與主流大模型競爭。
實際上,即使是二線互聯網公司,比如科大訊飛,也被外界質疑公司虧損嚴重,沒有能力持續投入到大模型上,更不用說還無法規模商業化,主要資金來源依靠融資和借債的初創公司了。
而即使是初創團隊最容易追趕的單項指標——技術水平上,在SuperCLUE不久前發布的最新測評榜單中,可以看到,憑“硬實力”說話,還是大廠更勝一籌,其中百度的最新版本的文心一言,在中文領域已經超過了GPT-3.5,足以對標國外主流大模型了。
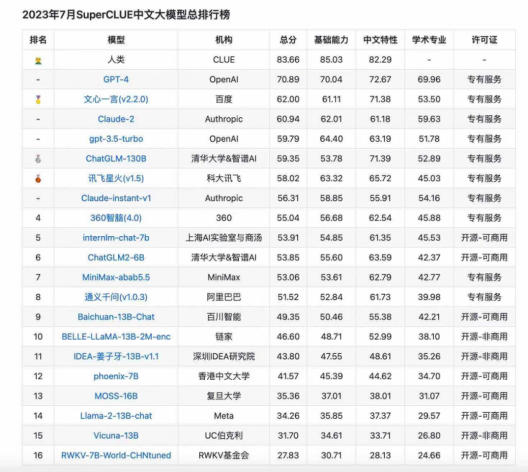
而且,目前國內排名靠前的大模型廠商,如百度文心大模型,阿里云通義千問,還有華為盤古大模型,都在積極拓展ToB業務。不久前,IDC發布的《AI大模型技術能力評估報告,2023》中,就圍繞著產品技術、服務生態以及行業應用三大維度,考察大模型的10余項指標,對國內主流大模型,包括百度、阿里、騰訊、華為、科大訊飛、360、商湯等14家廠商參進行了評估。
其中,百度文心大模型獲得綜合評分第一。在算法模型、服務能力、生態合作、行業覆蓋等方面,幾大主流大模型也可謂是各有千秋。
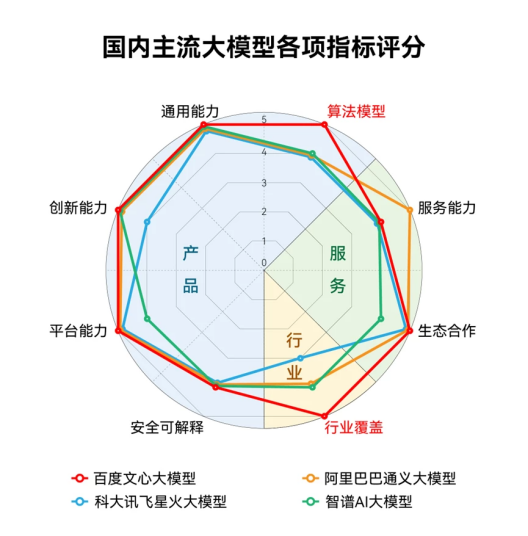
這無疑體現了,大廠在大模型競賽中的絕對優勢。在產品技術和行業應用上,遠勝過二三線的競品。比如排名第一的文心大模型,據其官方透露,已經有15萬家企業申請接入文心一言測試,百度智能云與300多家生態伙伴,在超過400個場景中已取得相當不錯的測試效果,并聯合多家企業單位合作發布了11個行業大模型。
對大多數大模型來說,可能這就足以讓它們輸在了起點上。而對百度、阿里、華為來說,競賽卻剛剛開始,長期投入和深耕行業,對大廠而言,不是口號,而是一定會去執行的事情。














