性能超越Llama2-13B,可免費商用,姚星創(chuàng)業(yè)公司開源百億參數(shù)通用大模型
高性能、可商用,國產(chǎn)大模型又有開源新動向。
8 月 7 日,百億參數(shù)高性能通用大模型「XVERSE-13B」宣布開源。
- Hugging Face:https://huggingface.co/xverse/XVERSE-13B
- Github:https://github.com/xverse-ai/XVERSE-13B
而 XVERSE-13B 的打造者,正是前騰訊公司副總裁姚星老師于2021年初創(chuàng)立的AI 與元宇宙技術(shù)服務(wù)公司元象 XVERSE。
在離職創(chuàng)業(yè)之前,姚星主導(dǎo)創(chuàng)建了騰訊首個人工智能實驗室 AI Lab(2016 年)和首個機器人實驗室 Robotics X (2018 年),曾推進(jìn)騰訊在機器學(xué)習(xí)、計算機視覺、語音到自然語言處理等前沿 AI 技術(shù)的研究與應(yīng)用,主導(dǎo)推出多個有行業(yè)影響力的應(yīng)用與產(chǎn)品,包括國家圍棋隊 AI 陪練「絕藝」、王者榮耀 AI「絕悟」、中國首款臨床用智能顯微鏡、AI 驅(qū)動的新藥發(fā)現(xiàn)平臺「云深智藥」及騰訊智慧種植方案 iGrow 等。
打造最強性能的開源大模型
XVERSE-13B 是目前同尺寸中效果最好的多語言大模型,可免費商用。它具備了高性能、全開源、可商用等諸多優(yōu)勢,能大大降低高校和企業(yè)部署使用大模型的成本,不僅實現(xiàn)了國產(chǎn)可替代,也是中文應(yīng)用更好的選擇。
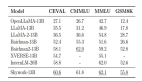
在多項權(quán)威的標(biāo)準(zhǔn)中文和英文測評中,性能超越了 Llama-2-13B、Baichuan-13B 等國內(nèi)外開源大模型(見下圖一)。

圖一:經(jīng)過多項權(quán)威測評,XVERSE-13B 是目前同尺寸中效果最好的多語言大模型。
作為一個通用大模型,XVERSE-13B 可提供文本生成、自動化寫作、數(shù)據(jù)分析、知識問答、多語言翻譯、個性化交互、人物角色扮演、專業(yè)小助手等多方面的生成服務(wù),在醫(yī)療、文旅、金融和娛樂等多個行業(yè)具有廣闊應(yīng)用前景。
據(jù)了解,元象近期還將發(fā)布大模型 Chat 版,開箱即用,持續(xù)優(yōu)化開發(fā)者體驗。
訓(xùn)練語料對大模型效果至關(guān)重要。XVERSE-13B 構(gòu)建了一個高達(dá) 1.4 萬億高質(zhì)量、多樣化 tokens 的訓(xùn)練數(shù)據(jù)集,同時優(yōu)化采樣策略和數(shù)據(jù)組織方式,讓模型支持中、英、俄、西等 40 多種語言,并且多語言任務(wù)處理的性能與效果俱佳。
XVERSE-13B 支持 8192 的上下文窗口,是同尺寸模型中最長的,從而能出色應(yīng)對復(fù)雜場景,比如更長的多輪對話、知識問答與摘要等,應(yīng)用范圍更廣泛。
模型使用標(biāo)準(zhǔn) Transformer 網(wǎng)絡(luò)結(jié)構(gòu),從零開始訓(xùn)練,還自主研發(fā)多項關(guān)鍵技術(shù),包括高效算子、顯存優(yōu)化、并行調(diào)度策略、數(shù)據(jù) - 計算 - 通信重疊、平臺和框架協(xié)同等,讓訓(xùn)練效率更高,模型穩(wěn)定性強,在千卡集群上的峰值算力利用率可達(dá)到 58.5%,位居業(yè)界前列。
多個權(quán)威中文測評中表現(xiàn)優(yōu)異,超越 Baichuan-13B
為驗證模型各項能力,XVERSE-13B 通過 C-Eval、AGIEval 和 GAOKAO-Bench 等三個最具影響力的中文測評基準(zhǔn)的綜合評估(圖二),表現(xiàn)優(yōu)異,超越了同參數(shù)規(guī)模主流模型,如 Baichuan-13B、Llama-2-13B、Ziya-LLaMA-13B 等。

圖二:在多個權(quán)威中文測評中,XVERSE-13B 表現(xiàn)超越了同參數(shù)規(guī)模的主流模型。
在中文 C-Eval 的測評中(圖三),XVERSE-13B 綜合評分達(dá)到了 54.7 分,超越了同參數(shù)規(guī)模的主流模型。C-EVAL 測評基準(zhǔn)由上海交通大學(xué)、清華大學(xué)以及愛丁堡大學(xué)聯(lián)合創(chuàng)建,是面向中文語言模型的綜合考試測試集,覆蓋了 52 個來自不同行業(yè)領(lǐng)域的學(xué)科。

圖三:C-Eval 中文測評結(jié)果。
在 AGIEval 測評里,XVERSE-13B 綜合評分達(dá)到 41.4 分,超越了同參數(shù)規(guī)模主流模型(圖二)。AGIEval 測評基準(zhǔn)由微軟研究院發(fā)起,旨在全面評估基礎(chǔ)模型在人類認(rèn)知和問題解決相關(guān)任務(wù)上的能力,包含了中國的高考、司法考試,以及美國的 SAT、LSAT、GRE 和 GMAT 等 20 個公開且嚴(yán)謹(jǐn)?shù)墓俜饺雽W(xué)和職業(yè)資格考試。
在 GAOKAO-Bench 測評中,XVERSE-13B 綜合評分達(dá)到了 53.9 分,顯著領(lǐng)先于同參數(shù)規(guī)模的主流模型(圖二)。GAOKAO-Bench 測評基準(zhǔn)是復(fù)旦大學(xué)研究團隊創(chuàng)建的測評框架,以中國高考題目作為數(shù)據(jù)集,用于測評大模型在中文語言理解和邏輯推理能力方面的表現(xiàn)。
英文測評表現(xiàn)領(lǐng)先 Llama-2-13B
XVERSE-13B 的英文表現(xiàn)同樣出色,在英文最權(quán)威評測 MMLU 中,其綜合評分高達(dá) 55.1 分,幾乎在所有維度超越了同參數(shù)規(guī)模的主流模型(圖四),包括 Llama-2-13B、Baichuan-13B 等。

圖四:MMLU 英文測評結(jié)果。
MMLU 由加州大學(xué)伯克利分校等知名高校共同打造,集合了科學(xué)、工程、數(shù)學(xué)、人文、社會科學(xué)等領(lǐng)域的 57 個科目,主要目標(biāo)是對模型的英文跨學(xué)科專業(yè)能力進(jìn)行深入測評。其內(nèi)容廣泛,從初級水平一直涵蓋到高級專業(yè)水平。
需要強調(diào)的是,測評只反映了大模型底座的核心能力,元象將持續(xù)迭代優(yōu)化,全面提升模型能力。
免費可商用 哈工大率先使用助力研究
秉持開源精神,XVERSE-13B 代碼采用 Apache-2.0 協(xié)議,向?qū)W術(shù)研究完全開源,企業(yè)只需簡單登記,即可免費商用。
哈爾濱工業(yè)大學(xué)(下稱「哈工大」)作為我國最早從事自然語言處理研究的頂級科研團隊,已經(jīng)率先使用 XVERSE-13B 大模型推進(jìn)相關(guān)研究工作。哈工大計算機科學(xué)與技術(shù)學(xué)院張偉男教授表示,「開源是互聯(lián)網(wǎng)時代主流模式,不僅能貢獻(xiàn)社區(qū),推動技術(shù)持續(xù)創(chuàng)新,還能利用協(xié)同解決算法透明性、穩(wěn)定性、公眾信任度等共性問題。」
元象 XVERSE 創(chuàng)始人姚星表示:「真實世界的感知智能(3D),與真實世界的認(rèn)知智能(AI),是探索通用人工智能(AGI)的必由之路,也是元象持續(xù)探索 3D 與 AI 前沿技術(shù)的動力。XVERSE-13B 是我們在國產(chǎn)技術(shù)自立自強上邁出的一小步,而開源開放將激發(fā)大模型生態(tài)活力,讓 AI 的未來發(fā)展邁出一大步,為實體經(jīng)濟、數(shù)字經(jīng)濟的發(fā)展注入強勁動力。我們期待與眾多企業(yè)與開發(fā)者攜手,開創(chuàng)大模型商用新紀(jì)元。」