既是自編碼器,也是RNN,DeepMind科學家八個視角剖析擴散模型
如果你嘗試過目前最火的 AI 繪畫工具之一 Stable Diffusion,那你就已經體驗過擴散模型(diffusion model)那強大的生成能力。但如果你想更進一步,了解其工作方式,你會發現擴散模型的形式其實有很多種。
如果你隨機選擇兩篇關于擴散模型的研究論文,看看各自引言中對模型類別的描述,你可能會看到它們的描述大不相同。這可能既讓人沮喪,又具有啟發性:讓人沮喪是因為人們更難發現論文和實現之間的關系,而具有啟發性的原因則是每一種觀點都能揭示出新的聯系,催生出新的思想。
近日,DeepMind 研究科學家 Sander Dieleman 發布了一篇博客長文,概括性地總結了他對擴散模型的看法。
這篇文章是他去年所寫的《擴散模型是自動編碼器》一文的進一步延伸。這個題目有些開玩笑的意味,但也強調了擴散模型和自動編碼器之間存在緊密聯系。他認為人們直到如今依然低估了這種聯系。
感興趣的讀者可訪閱:https://sander.ai/2022/01/31/diffusion.html
而在這篇新文章中,Dieleman 從多個不同視角剖析了擴散模型,包括將擴散模型看作是自動編碼器、深度隱變量模型、預測分數函數的模型、求解逆向隨機微分方程的模型、流模型、循環神經網絡、自回歸模型以及估計期望的模型。他還談了自己對擴散模型研究方向的當前研究現狀的看法。
擴散模型是自動編碼器
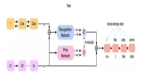
去噪自動編碼器是一種神經網絡,其輸入被噪聲損傷,而它們的任務目標則是預測出干凈的輸入,即消除損傷。要很好地完成這一任務,需要學習干凈數據的分布。它們是非常常用的表征學習方法,而在深度學習發展早期,它們也被用于深度神經網絡的分層預訓練。
事實證明擴散模型中使用的神經網絡通常求解的是一個非常類似的問題:給定一個被噪聲污染的輸入示例,它要預測出與其數據分布相關的一些量。這可以是對應的干凈輸入(如同去噪自動編碼器)、所添加的噪聲或某種介于兩者之間的東西(稍后會詳細介紹)。當損傷過程是線性的時,所有這些都是等價的,即噪聲是添加上去的,只需從有噪聲輸入中減去預測結果,我們就可以將預測噪聲的模型變成預測干凈輸入的模型。用神經網絡術語來說,就是從輸入到輸出添加一個殘差連接。

去噪自動編碼器(左)和擴散模型(右)的示意圖
它們有幾項關鍵性差異:
- 在學習輸入的有用表征時,去噪自動編碼器中部的某個位置往往存在某種信息瓶頸,這會限制其學習表征的能力。去噪任務本身只是達到目的的一種手段,而不是我們在訓練模型后真正使用模型的目的。用于擴散模型的神經網絡通常沒有這樣的瓶頸,因為我們更在乎它們的預測結果,而不是用于得到這些結果的內部表征方式。
- 去噪自動編碼器可以使用多種不同類型的噪聲來訓練。比如說,我們可以將部分輸入遮蔽掉(掩蔽噪聲),我們也可以添加來自某個任意分布(通常是高斯分布)的噪聲。對于擴散模型,我們通常堅持添加高斯噪聲,因為它具有有用的數學特性,可以簡化許多操作。
- 另一個重要差異是去噪自動編碼器的訓練目標只是處理特定強度的噪聲。而使用擴散模型時,我們想要根據帶有很多或少量噪聲的輸入預測一些東西。噪聲水平也是神經網絡的一個輸入。
事實上,作者之前詳細討論過這兩者之間的關系,想更加透徹理解這一關系的讀者可訪問:https://sander.ai/2022/01/31/diffusion.html
擴散模型是深度隱變量模型
Sohl-Dickstein et al. 在一篇 ICML 2015 論文中最早建議使用擴散過程來逐漸損傷數據的結構,然后再通過學習逆向該過程來構建生成模型。五年之后,Ho et al. 基于此開發出了去噪擴散概率模型(DDPM),其與基于評分的模型一起構成了擴散模型的藍圖。

DDPM 示意圖
DDPM 如上圖所示,x_T(隱含)表示高斯噪聲,x_0(觀察到的)表示數據分布。這些隨機變量由有限數量的中間隱變量 x_t (通常 T=1000)連接在一起,這會形成一個馬爾可夫鏈,即 x_{t-1} 僅取決于 x_t,而并不直接依賴于該鏈中之前的任意隨機變量。
這個馬爾可夫鏈的參數的擬合方式是使用變分推理來逆向擴散過程,這個擴散過程本身也是一個馬爾可夫鏈(方向相反,圖中表示為 q (x_t∣x_{t?1})),但這條鏈是逐漸向數據添加高斯噪聲。
具體來說,就像是在變分自動編碼器(VAE)中一樣,我們可以寫下一個證據下界(ELBO),即對數似然的一個界限,而對數似然是可以輕松地最大化的。事實上,這一節的小標題也可以是「擴散模型是深度 VAE」,但由于之前已經從另一個視角寫了「擴散模型是自動編碼器」,因此為了避免混淆就選用了當前小標題。
我們知道 q (x_t∣x_{t?1}) 是高斯分布,但我們想使用模型擬合的 p (x_{t?1}∣x_t) 卻不需要是。但事實證明,只要每個單獨的步驟足夠小(即 T 足夠大),我們可以通過參數設置讓 p (x_{t?1}∣x_t) 看起來像是高斯分布,而且其近似誤差將足夠小,該模型依然能生成優質樣本。仔細想想,這有點令人驚訝,因為在采樣過程中,任何錯誤都可能隨著 T 而累積。
擴散模型預測的是分數函數
大多數基于似然的生成模型都是對輸入 x 的對數似然 log p (x∣θ) 進行參數化,然后擬合模型參數 θ 來最大化它,要么是近似地擬合(如 VAE),要么是精確擬合(如流模型或自回歸模型)。由于對數似然表示概率分布,而概率分布必須歸一化,所以通常需要一些約束來確保參數 θ 的所有可能值都產生有效的分布。比如自回歸模型通過因果掩碼(causal masking)來確保這一點,而大多數流模型需要可逆的神經網絡架構。
研究表明,還有另一種擬合分布的方法可以巧妙地避開對歸一化的要求,即分數匹配(score matching)。這基于這一觀察:所謂的分數函數(score matching) 不會隨 p (x∣θ) 的縮放而變化。這很容易看出來:
不會隨 p (x∣θ) 的縮放而變化。這很容易看出來:

施加于概率密度的任何比例因子都會消失。因此,如果我們有一個直接對分數估計 進行參數化的模型,那就可以通過最小化分數匹配損失來擬合分布(而不是直接最大化似然):
進行參數化的模型,那就可以通過最小化分數匹配損失來擬合分布(而不是直接最大化似然):

但是,使用這種形式時,損失函數可能不實用,因為我們沒有為任意數據點 x 計算基本真值分數 的好方法。有一些技巧可用來回避這一要求,并將其轉換為易于計算的損失函數,包括隱式分數匹配(ISM)、切片分數匹配(SSM)和去噪分數匹配(DSM)。這里我們詳細看看最后一種方法:
的好方法。有一些技巧可用來回避這一要求,并將其轉換為易于計算的損失函數,包括隱式分數匹配(ISM)、切片分數匹配(SSM)和去噪分數匹配(DSM)。這里我們詳細看看最后一種方法:

其中,可通過向 x 添加高斯噪聲得到 。這意味著
。這意味著 的分布基于一個高斯分布 N (x,σ^2),其基本真值條件分數函數可以閉式形式計算得到:
的分布基于一個高斯分布 N (x,σ^2),其基本真值條件分數函數可以閉式形式計算得到:

這種形式有非常直觀的解釋:這是向 x 添加噪聲以得到 的一種擴展版本。因此,通過按照分數(= 對數似然的梯度上升)來使
的一種擴展版本。因此,通過按照分數(= 對數似然的梯度上升)來使 的可能性更高這一做法直接對應于消除(部分)噪聲:
的可能性更高這一做法直接對應于消除(部分)噪聲:

如果我們選擇步長 η=σ^2,則就能在一步之內恢復干凈數據 x。
L_SM 和 L_DSM 是不同的損失函數,但巧妙之處在于它們具有相同的期望最小值:
 ,其中 C 是一個常數。Pascal Vincent 早在 2010 年就推導出了這種等價性,如果你想加深理解,強烈建議你閱讀他的技術報告:http://www.iro.umontreal.ca/~vincentp/Publications/smdae_techreport.pdf
,其中 C 是一個常數。Pascal Vincent 早在 2010 年就推導出了這種等價性,如果你想加深理解,強烈建議你閱讀他的技術報告:http://www.iro.umontreal.ca/~vincentp/Publications/smdae_techreport.pdf
這一方法引出了一個重要問題:我們應該添加多少噪聲,即 σ 應為多少?為這一超參數選取一個固定值在實踐中效果并不好。在低噪聲水平下,在低密度區域中準確估計分數是非常困難的。在高噪聲水平下,這算不上是一個問題,因為添加的噪聲會分散在所有方向的密度上 —— 然后我們正在建模的分布會因噪聲而顯著扭曲。一種很好的方法是在許多不同噪聲水平下建模密度。一旦我們有了這樣一個模型,我們就可以在采樣過程中對 σ 進行退火 —— 從大量噪聲開始,然后逐漸降低。Song & Ermon 在他們 2019 年的論文中詳細描述了這些問題并提出了這種優雅的解決方案。
這種方法是將多種不同噪聲水平下的去噪分數匹配與采樣期間噪聲逐漸退火組合起來,得到的模型實質上等效于 DDPM,但推導過程卻完全不同 —— 完全看不見 ELBO!
有關這一方法的更詳細論述請參閱論文作者之一宋飏的博客:https://yang-song.net/blog/2021/score/
擴散模型求解的是逆向隨機微分方程
前面兩個看待擴散模型的視角(深度隱變量模型和分數匹配)考慮的是離散的和有限的步驟。這些步驟對應于不同的高斯噪聲水平,我們可以寫出一個單調映射 σ(t),其步驟索引 t 映射到該步驟的噪聲的標準差。
如果我們讓步數趨于無窮大,則可以將這些離散的索引變量替換為區間 [0,T] 上的連續值 t,這可被解釋為一個時間變量,即 σ(t) 現在描述的是噪聲的標準差隨時間的演變。在連續時間中,我們可以用以下隨機微分方程(SDE)來描述逐漸向數據點 x 添加噪聲的擴散過程:

該方程將 x 的無窮小變化與 t 的無窮小變化聯系了起來,dw 表示無窮小高斯噪聲,也被稱為維納過程(Wiener process)。f 和 g 分別稱為漂移系數和擴散系數。f 和 g 的特定選擇可得到用于構建 DDPM 的連續時間版本馬爾可夫鏈。
SDE 將微分方程和隨機變量組合到了一起,乍一看似乎有點生畏。幸運的是,我們不需要太多現有的先進 SDE 機制來理解這種視角可以如何用于擴散模型。然而,有一個非常重要的結果可供我們使用。給定一個像上面那樣描述擴散過程的 SDE,我們可以寫出另一個描述另一方向的過程的 SDE,即反轉時間:

該方程還描述了一個擴散過程。
 是逆向維納過程,
是逆向維納過程, 是時間依賴型分數函數。這種時間依賴性源自這一事實:噪聲水平會隨時間變化。
是時間依賴型分數函數。這種時間依賴性源自這一事實:噪聲水平會隨時間變化。
解釋這種情況的原因超出了本文的范圍,感興趣的讀者可閱讀宋飏等人為擴散模型引入基于 SDE 的形式化的原始論文《Score-Based Generative Modeling through Stochastic Differential Equations》。
具體來說,如果我們有一種方法,可以估計時間依賴型分數函數,那么我們可以模擬逆向擴散過程,從而從噪聲開始的數據分布中抽取樣本。我們可以再次訓練一個神經網絡來預測這個量,并將其插入到逆向 SDE 中以獲得連續時間擴散模型。
在實踐中,模擬這個 SDE 需要再次對時間變量 t 執行離散化,因此你可能想知道為什么要這么做。其巧妙之處就在于現在我們可以在采樣時間決定該離散化,而且在我們訓練好分數預測模型之前不必固定下來。換句話說,通過選擇采樣步驟數,我們無需修改模型,就能非常自然地權衡考慮采樣質量和計算成本。
擴散模型是流模型
還記得流模型嗎?流模型并非現如今常用的生成模型,主要原因可能是它們需要更多參數才能在性能上趕上其它模型。這是由于它們的表達能力有限:流模型中使用的神經網絡需要是可逆的,并且其雅可比行列式的對數行列式必須易于計算,這就嚴重限制了可能的計算類型。
至少,離散的歸一化流就是這種情況。連續的歸一化流(CNF)也存在,并且通常的形式為用神經網絡參數化的常微分方程(ODE),其描述的是數據分布中的樣本與一個簡單基礎分布的對應樣本之間的一個確定性路徑。CNF 不受前面提到的神經網絡架構約束的影響,但其原始形式需要用反向傳播通過一個 ODE 求解器來訓練。盡管可以使用一些技巧來更加高效地完成這件事,但這也可能會阻礙更多人使用它。
我們回顧一下擴散模型的 SDE 形式化,其描述的隨機過程是將簡單基礎分布的樣本映射到數據分布的樣本。有趣的問題出現了:中間樣本的分布 p_t (x) 是怎樣的,又會怎樣隨時間變化?這由福克 - 普朗克方程(Fokker-Planck equation)控制。如果你想了解實踐中的情況,請查看論文 Song et al. (2021) 的附錄 D.1。
瘋狂的來了:有一個 ODE 所描述的確定性過程的時間依賴型分布與該 SDE 所描述的隨機過程的完全一樣!這被稱為概率流 ODE。不僅如此,它有一個簡單的閉式形式:

該方程描述了前向和后向過程(只需翻轉符號即可變換方向),注意時間依賴型分數函數 依然在其中。要證明這一點,你可以寫下該 SDE 和概率流 ODE 的福克 - 普朗克方程,然后做一些代數運算,你會發現它們其實是一樣的,因此必定具有形同的解 p_t (x)。
依然在其中。要證明這一點,你可以寫下該 SDE 和概率流 ODE 的福克 - 普朗克方程,然后做一些代數運算,你會發現它們其實是一樣的,因此必定具有形同的解 p_t (x)。
請注意,該 ODE 描述的過程與該 SDE 并不一樣,這也不可能,因為確定性的微分方程無法描述一個隨機過程。它描述的是一個不同的過程,其具有獨特的屬性,即兩個過程的分布 p_t (x) 是一樣的。
這一現象揭示出了重要的意義:來自簡單基礎分布的特定樣本與來自數據分布的樣本之間存在雙射映射。對于所有隨機性都包含在初始基礎分布樣本中的采樣過程 —— 一旦采樣完成,基于此得到數據樣本的過程就是完全確定性的。這也意味著我們可以通過前向模擬 ODE 來將數據點映射到其相應的隱含表征,然后操作它們,再通過后向模擬 ODE 將它們映射回數據空間。
由這個概率流 ODE 描述的模型是一個連續歸一化流模型,但我們不必反向傳播通過 ODE 也能訓練它,使該方法的擴展性好得多。
我們竟然可以做到這一點,而不會改變模型的訓練方式,是不是很神奇?我們可以將分數預測器插入到前一節提到的逆向 SDE 或這一節的 ODE 中,然后得到兩個以不同方式建模同一分布的不同生成模型。是不是很炫酷?
不僅如此,概率流 ODE 還能讓擴散模型實現似然計算,參見 Song et al. (2021) 的附錄 D.2。這也需要求解 ODE,所以成本幾乎和采樣一樣高。
由于以上原因,概率流 ODE 范式最近變得相當受歡迎。比如 Karras et al. 將其用作探究不同擴散模型設計選擇的基礎,本文作者也與其合作者在他們的擴散語言模型中使用了它。這也被泛化和擴展到了擴散過程之外,以學習任意一對分布之間的映射,形式包括流匹配(Flow Matching)、修正流(Rectified Flows)和隨機插值(Stochastic Interpolants)。
旁注:DDIM 給出了另一種可為擴散模型獲取確定性采樣過程的方法,該方法基于深度隱變量模型視角。
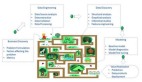
擴散模型是循環神經網絡(RNN)
從擴散模型采樣涉及到使用神經網絡反復進行預測并使用這些預測來更新「畫布」,而這畫布一開始全是隨機噪聲。如果我們考慮這個過程的完整計算圖,它看起來很像循環神經網絡(RNN)。RNN 中有一個隱藏狀態會反復通過一個循環單元來獲得更新,而這個循環單元由一個或多個非線性的已參數化的運算(比如 LSTM 的門控機制)構成。其中,隱藏狀態就是畫布,因此它位于輸入空間中,并且其中的單元由我們為擴散模型訓練的去噪神經網絡構成。

展開的擴散采樣回路示意圖
RNN 的訓練通常使用通過時間的反向傳播(BPTT),其中梯度是通過循環傳播的。反向傳播通過的循環步驟數通常受限于某個最大值,以降低計算成本,這被稱為截斷式 BPTT。擴散模型也是通過反向傳播訓練,但一次僅通過一步。從某種意義上說,擴散模型提供了一種訓練深度循環神經網絡的方法。該方法完全無需通過循環進行反向傳播,從而可得到更具可擴展性的訓練過程。
RNN 通常是確定性的,因此這個類比對于基于上一節中描述的概率流 ODE 的確定性過程最有意義 —— 盡管將噪聲注入 RNN 的隱藏狀態作為正則化的一種方法并非是前所未聞的事情,所以作者認為這個類比也適用于隨機過程。
在非線性層的數量方面,這個計算圖的總深度是由神經網絡的層數乘以采樣步驟數給定的。我們可以將展開的循環看作是一個非常深的神經網絡,甚至可能有成千上萬層。深度很大,但也說得過去,因為對真實世界數據進行生成式建模就需要如此深度的計算圖。
我們還可以想想,如果我們在每個擴散采樣步驟不使用同樣的神經網絡,對于不同的噪聲水平范圍可能使用不同的神經網絡,那么會發生什么?這些網絡可以單獨且獨立地訓練,甚至可以使用不同的架構。這意味著我們可以有效地「解開」非常深的神經網絡中的權重,將其從一個 RNN 變成一個普通的老式深度神經網絡,但我們仍然無法避免一次性反向傳播通過它們全部。Stable Diffusion XL 在其 Refiner 模型中使用這種方法達到了很好的效果,所以這種方法的熱度可能會趕上來。
作者表示他在 2010 年開始讀博時,訓練隱藏層超過 2 層的神經網絡可是個苦累活:反向傳播不是一拿出來就好用,因此他們的做法是使用無監督的逐層預訓練來尋找一個能夠讓反向傳播成為可能的優良初始化。現如今,即使有數百隱藏層,也不再是阻礙。因此,不難想象未來幾年之后,使用反向傳播訓練數萬層的神經網絡也有可能實現。到那時,擴散模型提供的「分而治之」的方法可能會失去光彩,也許我們都會回頭去訓練深度變分自動編碼器!(注意,同樣的「分而治之」視角也適用于自回歸模型,因此如果未來果真如此,那么自回歸模型也可能會過時。)
這一視角下的一個問題是:如果我們反向傳播通過采樣過程兩步或更多步,擴散模型的表現是否會更好。這種方法并不常見,這可能說明這種方法實際做起來成本很高。不過也有一個重要的例外(一定程度上的例外),循環接口網絡(RIN)等使用自調節(self-conditioning)的模型除了會在擴散采樣步驟之間傳遞更新的畫布之外,還會傳遞某種形式的狀態。要讓模型學會使用這個狀態,可以在訓練期間通過運行額外的前向傳遞來提供該狀態的近似值。不過,這里不會有額外的向后傳遞,所以這實際上不算是兩步 BPTT—— 更像是 1.5 步。
擴散模型是自回歸模型
對于自然圖像的擴散模型,采樣過程往往會首先產生大尺度的結構,然后迭代地添加越來越細粒的細節。事實上,噪聲水平與特征尺度之間似乎有近乎直接的對應關系。
但為什么會這樣呢?為了理解這一點,從空間頻率的角度思考會有所幫助。圖像中的大尺度特征對應于低空間頻率,而細粒度細節對應于高頻率。我們可以使用 2D 傅立葉變換(或其某種變體)將圖像分解為其空間頻率分量。這通常是圖像壓縮算法的第一步,因為眾所周知人類視覺系統對高頻不太敏感,壓縮時可以利用這一點,即更多地壓縮高頻,更少地壓縮低頻。

8x8 離散余弦變換(比如 JPEG 壓縮方法就使用了它)的空間頻率分量的可視化
自然圖像以及許多其它自然信號的頻域會表現出一個有趣的現象:不同頻率分量的幅度往往與頻率的倒數成比例下降: (如果你看的是功率譜而不是幅度譜,那么就是頻率平方的倒數)。
(如果你看的是功率譜而不是幅度譜,那么就是頻率平方的倒數)。
另一方面,高斯噪聲的譜形很平坦:在期望中,所以頻率的幅度一樣。由于傅里葉變換是線性運算,因此向自然圖像添加高斯噪聲會產生新圖像,其頻譜是原始圖像的頻譜與噪聲的平坦頻譜之和。在對數域中,兩個光譜的疊加看起來像一個鉸鏈,它表明添加噪聲會以某種方式模糊更高空間頻率中存在的任何結構(見下圖)。這個噪聲的標準差越大,受影響的空間頻率就越多。

自然圖像、高斯噪聲和有噪聲圖像的幅度譜
由于擴散模型的構建方式是逐漸向輸入樣本添加更多噪聲,我們可以說這個過程會逐漸淹沒越來越低頻的內容,直到清除所有結構(至少對自然圖像來說是這樣的)。當從模型采樣時,就調轉方向,在越來越高的空間頻率上有效地添加結構。這基本上就和自回歸一樣,卻是在頻率空間!Rissanen et al. (2023) 討論了他們在使用逆向散熱(inverse heat dissipation,這是高斯擴散的一種替代方法)的生成式建模方面觀察到這一現象,但他們并未將其與自回歸模型聯系起來。這種聯系是本文作者自己提出的,可能會具有爭議。
一個重要的警告是:這種解釋依賴于自然信號的頻率特征,因此對于擴散模型在其它領域的應用(如語言建模),這種類比可能沒有意義。
擴散模型估計的是期望
轉移密度(transition density) p (x_t∣x_0) 描述的是:基于原始的干凈輸入 x_0,其衍生(通過添加噪聲)出的有噪聲數據示例 x_t 在時間 t 的分布。擴散模型中神經網絡的任務是基于這一分布的樣本預測其期望 E [x_0∣x_t](或期望的某個線性的時間依賴型函數)。這可能看起來再明顯不過,但這也能說明一些東西,這里強調一下。
首先,這提供了一個佐證,說明訓練擴散模型時使用均方誤差(MSE)作為損失函數是正確的選擇。在訓練期間,期望 E [x_0∣x_t] 是未知的,所以我們使用 x_0 本身來監督模型。因為 MSE 損失的最小值正是期望值,所以我們最終可以恢復 E [x_0∣x_t](的近似值),即使我們事先不知道這個量。這和典型的監督學習問題有些不同。對于典型的監督學習問題,理想的結果是模型能準確預測出用于監督的目標(排除任何標注錯誤)。這里,我們故意不希望這樣。更一般而言,估計條件期望的概念(即便我們只是通過樣本提供監督)是非常強大的。
其實,這解釋了為什么擴散模型的蒸餾是一個如此引人注目的命題:在這種情況下,我們可以直接使用我們希望預測的目標期望 E [x_0∣x_t] 的近似值來監督擴散模型,因為教師模型已經提供了這一點。由此導致的結果是,其訓練損失的方差將遠遠低于從頭開始訓練時的情況,收斂速度也會快得多。當然,只有當你手上已經有一個已訓練好的模型可用作教師時,這才會有用。
離散和連續的擴散模型
到目前為止,我們已經從幾個視角考慮了一些離散噪聲水平的情況,也有幾個視角使用了連續時間概念,其與映射函數 σ(t) 相組合,可將時間步驟映射到噪聲中對應的標準差。這些通常分別被稱為離散時間或連續時間。一件非常巧妙的事情是:這主要就是一個如何解釋的問題:在離散時間視角下訓練的模型通常可以很容易地重新調整用途,以在連續時間設置中生效,反之亦然。
看擴散模型是離散還是連續的另一種方式是看輸入空間。作者發現,文獻中常常不會清楚說明「連續」或「離散」是相對于時間還是相對于輸入。這非常重要,因為某些視角僅對連續輸入才真正有意義,因為它們依賴于輸入的梯度(即基于分數函數的所有視角)。
離散性 / 連續性存在四種組合方式:
- 時間離散,輸入連續:原始的深度隱變量模型視角(DDPM)以及基于分數的視角;
- 時間連續,輸入連續:基于 SDE 和 ODE 的視角;
- 時間離散,輸入離散:D3PM、MaskGIT、Mask-predict、ARDM、多項式擴散和 SUNDAE 都是對離散輸入使用迭代式精細化的方法 —— 是否所有這些都應該被視為擴散模型尚不完全清楚(這取決于你提問的對象);
- 時間連續,輸入離散:連續時間馬爾可夫鏈(CTMC)、基于分數的連續時間離散擴散模型和 Blackout Diffusion 都是搭配了離散輸入和連續時間 —— 這一設置通常的處理方式是將離散數據嵌入到歐幾里得空間中,然后在該空間中對輸入執行連續的擴散,例如 Analog Bits、Self-conditioned Embedding Diffusion 和 CDCD。
其它形式
最近有些論文基于第一性原理為這類模型提出了新的推導方式,由于已有后見之明,所以它們完全避開了微分方程、ELBO 或分數匹配。然而,這些研究為擴散模型提供了另一種視角,這可能更容易理解,因為所需的背景知識更少。
通過直接迭代進行反演(InDI/Inversion by Direct Iteration)這種形式根植于圖像恢復,其目的是利用迭代式精細化來提升感知質量。其沒有對圖像劣化的本質做任何假設,并且模型的訓練使用的是配對的低質量和高質量樣本。Iterative α-(de) blending 通過在來自兩個不同分布的樣本之間進行線性插值作為起點,來得到這兩個分布之間的確定性映射。這兩種方法都與之前討論的流匹配、修正流和隨機插值方法緊密相關。
一致性
近期的文獻對擴散模型的一致性(consistency)有著不同的概念。
- 一致性模型(CM)被訓練用于將概率流 ODE 的任何軌跡上的點映射到軌跡的原點(即干凈的數據點),從而實現在單一步驟中完成采樣。其完成方式是間接的,即通過在特定軌跡上獲取成對的點并確保模型對于兩者的輸出結果一樣(因此有一致性)。其有一個蒸餾式的變體,它是從已有的擴散模型開始的,但也可能從頭開始訓練出一致性模型。
- 一致擴散模型(CDM)的訓練使用了明確鼓勵一致性的正則化項,其將一致性定義為:去噪器的預測結果應當對應于條件期望 E [x_0∣x_t]。
- FP-Diffusion 的任務是讓福克 - 普朗克方程描述 p_t (x) 隨時間的演變,其中引入了一個顯式的正則化項以確保其成立。
對理想的擴散模型(完全收斂又能力無限)而言,這些屬性中的每一個都很容易實現。但是,現實中的擴散模型都是近似模型,并不是理想模型,所以它們在實踐中并不成立,所以需要通過新增機制來顯式地施行它們。
本文之所以有這一節,是因為作者想重點說明近期的一篇論文《On the Equivalence of Consistency-Type Models: Consistency Models, Consistent Diffusion Models, and Fokker-Planck Regularization》,來自 Lai et al. (2023),其中表明這三種不同的一致性概念本質上是不同視角下的同一東西。作者表示這個結果很優雅,非常契合本文的主題。
打破常規
除了這些在概念層面上的不同視角,作者表示,擴散模型方面的論文也在重新發明符號和違反慣例方面特別令人擔憂。有時候,對于同一概念,人們使用的兩套描述看起來簡直像是一點關系都沒有。這無益于人們理解和學習,提高了進入門檻。(對此我很抱歉。)
還有一些其它看似無害的細節和參數化選擇也可能產生深遠影響。以下是需要注意的三點:
- 總的來說,人們使用的是方差保持(VP/variance-preserving)擴散過程,即除了在每一步添加噪聲,當前畫布的尺寸也會得到調整以保持整體的方差。不過,方差爆炸(VE/variance-exploding)方法也有不少擁躉,其中不會調整畫布尺寸,所添加的噪聲的方差會無限增大。最值得注意的是 Karras et al. (2022) 使用的方法。某些對于 VP 擴散方法成立的結果對 VE 擴散就不一定成立,反之亦然;并且這一點可能不會被明確提及。如果你在讀一篇擴散論文,要確保你知道所使用的構建方法,以及論文中是否做了有關于其的假設。
- 有時擴散模型中使用的神經網絡的參數被設計成為了預測添加到輸入中的(標準化)噪聲,即分數函數,有時則是為了預測干凈的輸入或甚至這兩者的時間依賴型組合(如 v-prediction)。所有這些目標都是等效的,因為它們都是彼此和有噪聲輸入 x_t 的時間依賴型線性函數。但重要的是,要了解其與訓練期間不同時間步驟的損失貢獻的相對權重的作用方式,這會極大影響模型的性能表現。對于圖像數據而言,預測標準化噪聲似乎是個絕佳選擇。人們發現,當建模其它某些量(如隱含擴散中的隱含量)時,預測干凈輸入的效果更好。這主要是因為它暗含了對噪聲水平的不同加權,因此特征尺度也就不同。
- 人們普遍認為,損傷過程所添加的噪聲的標準偏差會隨時間而增加,即熵會隨時間增加,就像我們的宇宙。因此,x_0 對應于干凈數據,x_T(當 T 足夠大時)對應于純噪聲。流匹配等一些研究顛倒了這種慣例,如果你一開始沒注意到,可能會深感困惑。
最后,值得注意的是,在生成式建模的語境下,「擴散」的定義范圍已經變得相當廣泛,現在幾乎就等同于「迭代式精細化」。許多用于離散輸入的「擴散模型」實際上并不基于擴散過程,但是它們當然是緊密相關的,因此擴散這一標簽的范圍會逐漸擴大并將它們囊括進來。界線在哪目前尚未可知:如果通過逆向逐漸損傷的過程而實現迭代式精細化的任何模型都算是擴散模型,那么所有自回歸模型也算是擴散模型。作者認為,這樣就太混淆了,會讓「擴散」這個術語變得毫無用處。
結語
目前,學習有關擴散模型的知識肯定很讓人困惑,但對這些不同視角的探索已經催生出了廣泛多樣的方法和工具,這些方法可以組合起來使用,畢竟其底層模型都是一樣的。另外,了解這些不同視角的相關性還能加深理解。在一個視角下看起來神秘難解的東西在另一個視角看來可能就很明晰。
如果你才剛開始學習擴散模型,希望這篇文章能為你提供引導,幫助你找到更進一步的學習材料。如果你已經經驗豐富,也希望這篇文章能拓寬你對擴散模型的理解,讓你溫故而知新。感謝閱讀!
對于擴散,你最喜歡的視角是哪一個?文中還沒提到哪些有用的視角?請與我們分享你的看法。