













文生圖prompt不再又臭又長!LLM增強(qiáng)擴(kuò)散模型,簡單句就能生成高質(zhì)量圖像
擴(kuò)散模型已經(jīng)成為了主流的文本到圖像生成模型,可以基于文本提示的引導(dǎo),生成高質(zhì)量且內(nèi)容豐富的圖像。
但如果輸入的提示過于簡潔,現(xiàn)有的模型在語義理解和常識推理方面都存在局限,導(dǎo)致生成的圖像質(zhì)量下降明顯。
為了提高模型理解敘述性提示的能力,中山大學(xué)HCP實驗室林倞團(tuán)隊提出了一種簡單而有效的參數(shù)高效的微調(diào)方法SUR-adapter,即語義理解和推理適配器,可應(yīng)用于預(yù)訓(xùn)練的擴(kuò)散模型。

論文地址:https://arxiv.org/abs/2305.05189
開源地址:https://github.com/Qrange-group/SUR-adapter
為了實現(xiàn)該目標(biāo),研究人員首先收集并標(biāo)注了一個數(shù)據(jù)集SURD,包含超過5.7萬個語義校正的多模態(tài)樣本,每個樣本都包含一個簡單的敘述性提示、一個復(fù)雜的基于關(guān)鍵字的提示和一個高質(zhì)量的圖像。
然后,研究人員將敘事提示的語義表示與復(fù)雜提示對齊,并通過知識蒸餾將大型語言模型(LLM)的知識遷移到SUR適配器,以便能夠獲得強(qiáng)大的語義理解和推理能力來構(gòu)建高質(zhì)量的文本語義表征用于文本到圖像生成。

通過集成多個LLM和預(yù)訓(xùn)練擴(kuò)散模型來進(jìn)行實驗,結(jié)果展現(xiàn)了該方法可以有效地使擴(kuò)散模型理解和推理簡潔的自然語言描述,并且不會降低圖像質(zhì)量。
該方法可以使文本到圖像的擴(kuò)散模型更容易使用,具有更好的用戶體驗,可以進(jìn)一步推進(jìn)用戶友好的文本到圖像生成模型的發(fā)展,彌補(bǔ)簡單的敘事提示和復(fù)雜的基于關(guān)鍵字的提示之間的語義差距。
背景介紹
目前,以Stable diffusion為代表的文生圖 (text-to-image)預(yù)訓(xùn)練擴(kuò)散模型已經(jīng)成為目前AIGC領(lǐng)域最重要的基礎(chǔ)模型之一,在包括圖像編輯、視頻生成、3D對象生成等任務(wù)當(dāng)中發(fā)揮著巨大的作用。
然而目前的這些預(yù)訓(xùn)練擴(kuò)散模型的語義能力主要依賴于CLIP等文本編碼器 (text encoder),其語義理解能力關(guān)系到擴(kuò)散模型的生成效果。
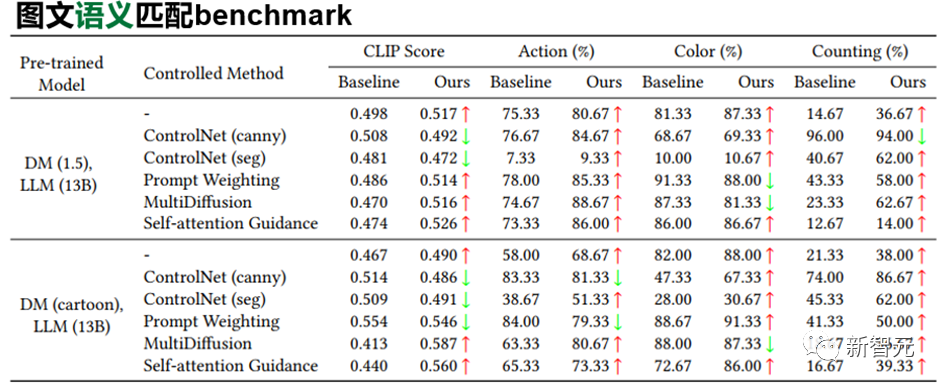
本文首先以視覺問答任務(wù)(VQA)中常用問題類別的"Counting (計數(shù))", "Color (顏色)"以及"Action (動作)"構(gòu)造相應(yīng)的本文提示來人工統(tǒng)計并測試Stable diffusion的圖文匹配準(zhǔn)確度。
下表給出了所構(gòu)造的各種prompt的例子。

結(jié)果如下表所示,文章揭示了目前文生圖預(yù)訓(xùn)練擴(kuò)散模型有嚴(yán)重的語義理解問題,大量問題的圖文匹配準(zhǔn)確度不足50%,甚至在一些問題下,準(zhǔn)確度只有0%。

因此,需要想辦法增強(qiáng)預(yù)訓(xùn)練擴(kuò)散模型中本文編碼器的語義能力以獲得符合文本生成條件的圖像。
方法概述
1. 數(shù)據(jù)準(zhǔn)備
首先從常用的擴(kuò)散模型在線網(wǎng)站lexica.art,civitai.com,stablediffusionweb中大量獲取圖片文本對,并清洗篩選獲得超過57000張高質(zhì)量 (complex prompt, simple prompt, image) 三元組數(shù)據(jù),并構(gòu)成SURD數(shù)據(jù)集。
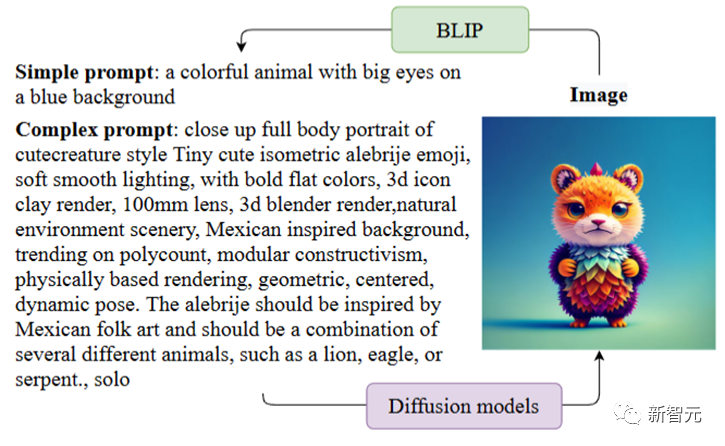
如圖所示,complex prompt是指生成image時擴(kuò)散模型所需要的文本提示條件,一般這些文本提示帶有復(fù)雜的格式和描述。simple prompt是通過BLIP對image生成的文本描述,是一種符合人類描述的語言格式。
一般來說符合正常人類語言描述的simple prompt很難讓擴(kuò)散模型生成足夠符合語義的圖像,而complex prompt(對此用戶也戲稱之為擴(kuò)散模型的“咒語”)則可以達(dá)到令人滿意的效果。
2. 大語言模型語義蒸餾
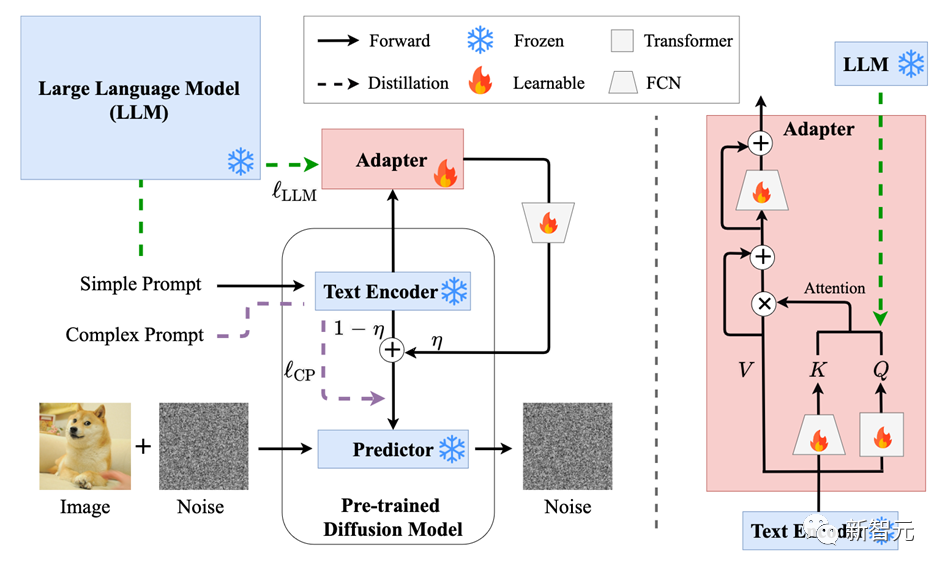
本文引入一個transformer結(jié)構(gòu)的Adapter在特定隱含層中蒸餾大語言模型的語義特征,并將Adapter引導(dǎo)的大語言模型信息和原來文本編碼器輸出的語義特征做線性組合獲得最終的語義特征。
其中大語言模型選用的是不同大小的LLaMA模型。擴(kuò)散模型的UNet部分在整個訓(xùn)練過程中的參數(shù)都是凍結(jié)的。

3. 圖像質(zhì)量恢復(fù)
由于本文結(jié)構(gòu)在預(yù)訓(xùn)練大模型推理過程引入了可學(xué)習(xí)模塊,一定程度破壞了預(yù)訓(xùn)練模型的原圖生成質(zhì)量,因此需要將圖像生成的質(zhì)量拉回原預(yù)訓(xùn)練模型的生成質(zhì)量水平。

本文利用SURD數(shù)據(jù)集中的三元組在訓(xùn)練中引入相應(yīng)的質(zhì)量損失函數(shù)以恢復(fù)圖像生成質(zhì)量,具體地,本文希望simple prompt通過新模塊后獲得的語義特征可以和complex prompt的語義特征盡可能地對齊。
下圖展示了SUR-adapter對預(yù)訓(xùn)練擴(kuò)散模型的fine-tuning框架。右側(cè)為Adapter的網(wǎng)絡(luò)結(jié)構(gòu)。
實驗結(jié)果
本文從語義匹配和圖像質(zhì)量兩個角度來看SUR-adapter的性能。
一方面,如下表所示,SUR-adapter可以有效地在不同的實驗設(shè)置下緩解了文生圖擴(kuò)散模型中常見的語義不匹配問題。在不同類別的語義準(zhǔn)則下,準(zhǔn)確度有一定的提升。
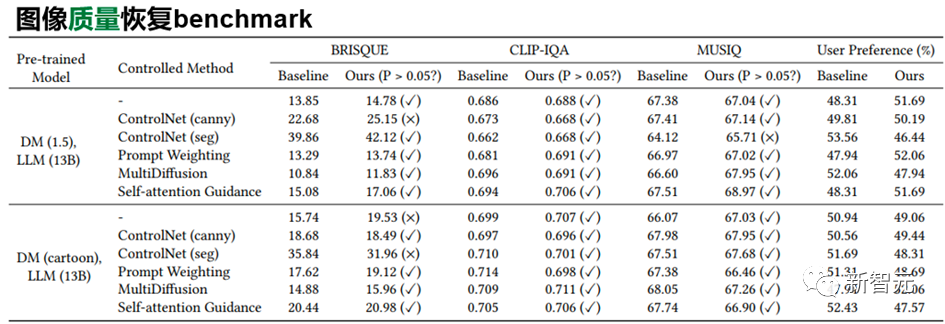
另一方面,本文利用常用的BRISQUE等常用的圖像質(zhì)量評價指標(biāo)下,對原始pretrain擴(kuò)散模型和使用了SUR-adapter后的擴(kuò)散模型所生成圖片的質(zhì)量進(jìn)行統(tǒng)計檢驗,我們可以發(fā)現(xiàn)兩者沒有顯著的差異。
同時,我們還對此進(jìn)行了人類偏好的調(diào)查問卷測試。
以上分析說明,所提出的方法可以在保持圖像生成質(zhì)量的同時,緩解固有的預(yù)訓(xùn)練text-to-image固有的圖文不匹配問題。
另外我們還可以定性地展示如下圖所示的圖像生成的例子,更詳細(xì)的分析和細(xì)節(jié)請參見本文文章和開源倉庫。


HCP實驗室簡介
中山大學(xué)人機(jī)物智能融合實驗室 (HCP Lab) 由林倞教授于 2010 年創(chuàng)辦,近年來在多模態(tài)內(nèi)容理解、因果及認(rèn)知推理、具身智能等方面取得豐富學(xué)術(shù)成果,數(shù)次獲得國內(nèi)外科技獎項及最佳論文獎,并致力于打造產(chǎn)品級的AI技術(shù)及平臺。


























