













大幅降低計算量!PointOcc:基于點云的3D語義占用預測新思路
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
我們提出了一種基于點云柱坐標三視角表示的高效3D語義占有預測方法PointOcc,通過在nuScenes公開數據集上進行大量實驗,驗證了PointOcc在3D語義占有預測和點云分割任務上可以取得最佳的性能,同時大幅降低計算量。PointOcc僅使用點云數據作為輸入,在mIoU和IoU兩種指標上大幅超越了OpenOccupancy benchmark中的多模態方法。

論文:https://arxiv.org/abs/2308.16896
代碼:https://github.com/wzzheng/PointOcc
1. 提出的背景
當前自動駕駛領域中的語義分割正在經歷從稀疏的點云分割到密集的3D語義占有預測的變革。3D語義占有預測任務的目標是對3D空間中的每一個體素都預測一個語義標簽,以實現對3D場景更加魯棒、準確的感知建模。但由于其密集的預測空間,當前基于點云體素表示的方法將承受巨大的計算和存儲負擔,從而嚴重限制模型的性能。另一類更加高效的點云表示是基于2D投影表示的方法,例如BEV和range-view表示。盡管相比于體素表示更加高效,但由于其在投影過程中的信息損失,僅使用單平面特征難以建模復雜3D場景中的細粒度結構,從而無法處理具有密集預測空間的3D語義占有預測任務。
為了解決這個問題,我們提出了一種新的基于柱坐標三視角的點云表示來高效、完整地建模3D場景,并進一步提出了一個高效的3D語義占有預測模型PointOcc。我們采用彼此互補的三視角平面來高效建模點云特征,并使用高效的2D backbone處理。我們提出柱坐標劃分和空間分組池化來減少投影過程中的信息損失,在保持高效的同時進一步提升模型建模復雜3D場景的能力。實驗表明,我們的模型PointOcc在點云分割任務中達到了基于2D投影表示方法中的最佳性能,而無需復雜的后處理操作;并在3D語義占有預測任務上取得了比OpenOccupancy benchmark上多模態方法更好的性能,同時大幅降低模型的計算和存儲負擔。
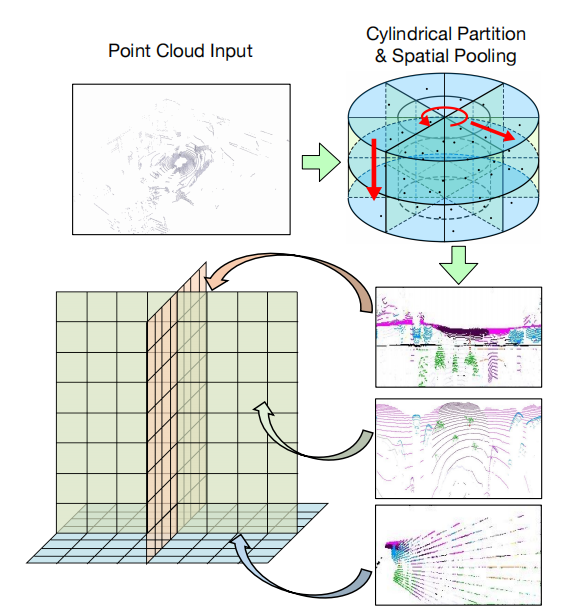
2. 我們的方法
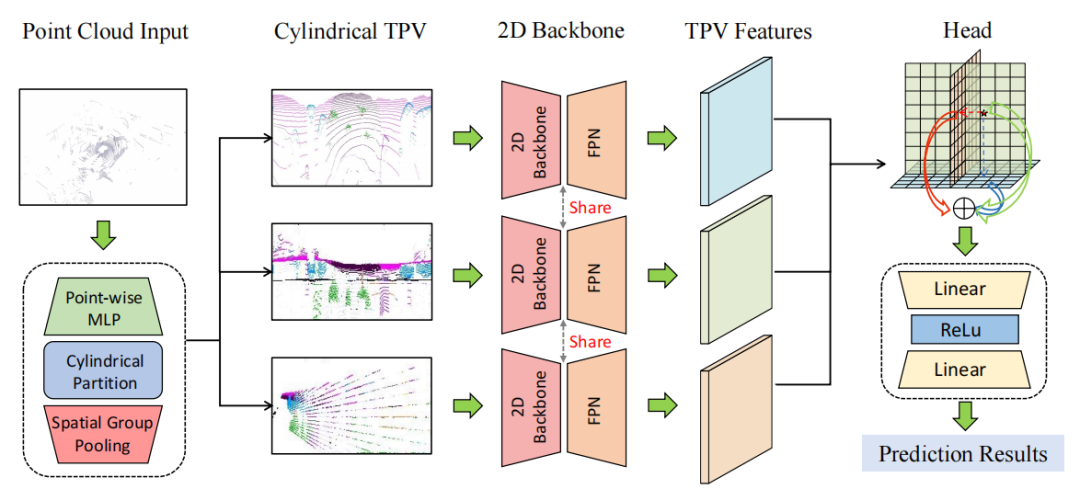
本文提出了一種新的基于柱坐標三視角的點云表示方法,通過彼此互補的三個2D平面來共同建模3D空間特征。我們僅采用2D backbone來高效處理三視角平面特征,并通過柱坐標劃分和空間分組池化來減少投影過程中的信息損失。最后通過聚合三平面中彼此互補的特征視角下的特征,實現對3D空間高效細致的建模。
2.1 點云的柱坐標三視角表示
在基于點云的自動駕駛感知中,一個重要問題是學習到有效且高效的3D場景表示。而在當前的主流方法中,3D體素表示會造成巨大的計算和存儲負擔,2D投影表示會由于信息損失而無法恢復出密集的3D空間特征。為了實現在2D平面高效處理點云特征并保留3D結構信息,我們將Tri-Perspective View (TPV)的思想引入點云,采用三視角下的平面特征來建模3D場景。每個平面負責建模特定視角下的3D場景特征,三個平面彼此正交互補,通過聚合三平面的特征就能恢復出3D空間中任意一點的結構信息。考慮到激光雷達點云在空間中分布的不均勻特性,即近處的點云更加密集而遠處更加稀疏,我們進一步提出在柱坐標系下建立點云的三視角表示,以實現對近處區域更加細粒度的建模,并在投影過程中采用空間分組池化來更好地保留3D結構信息。
2.2 PointOcc
基于點云的柱坐標三視角表示,我們提出了一個高效的3D語義占有預測模型PointOcc,僅利用2D backbone實現模型在性能和效率上的最佳表現。PointOcc主要分為三個模塊:點云的三視角轉化、三視角特征編碼、重構3D空間特征
- 點云的三視角轉化:給定輸入點云,首先需要通過體素化(voxelization)和空間池化操作(spatial max pooling)其轉化為三個視角下的平面特征。考慮到激光雷達點云在空間中的分布密度不一致性,采用直角坐標系下均勻的方格劃分會導致體素中點云密度分布極不均勻,近處點云極度密集而遠處存在大量空體素,造成計算效率下降。因此我們采用柱坐標系下的體素劃分,由于柱坐標系中對近處劃分更加密集而遠處更加稀疏,從而使點云密度分布更加均勻。對點云進行體素劃分后,我們沿柱坐標系下的三個坐標軸分別進行分組池化+特征聯結,得到點云在柱坐標下的三視角特征。
- 三視角特征編碼:我們采用2D圖像backbone來編碼每個三視角特征平面,并由FPN聚集每個平面的多尺度特征,最終解碼出高分辨率的三視角特征表示。由于僅在2D空間中進行特征的表示和編碼,我們的模型在計算和存儲上具有高效性。
- 重構3D空間特征:基于點云的三視角特征平面,我們可以高效完整地重構出3D空間的特征表示。對于3D空間中的任意一個查詢點,我們首先通過柱坐標轉換將其分別投影到三視角平面上并采樣相應特征。我們通過相加的方式聚合該點在三視角平面上的特征,并作為最終的3D特征表示。在進行點云分割和3D語義占有預測時,只需要查詢相應點的三視角特征,并由輕量級的分類頭進行預測。
3. 實驗
3.1 3D語義占有預測實驗結果
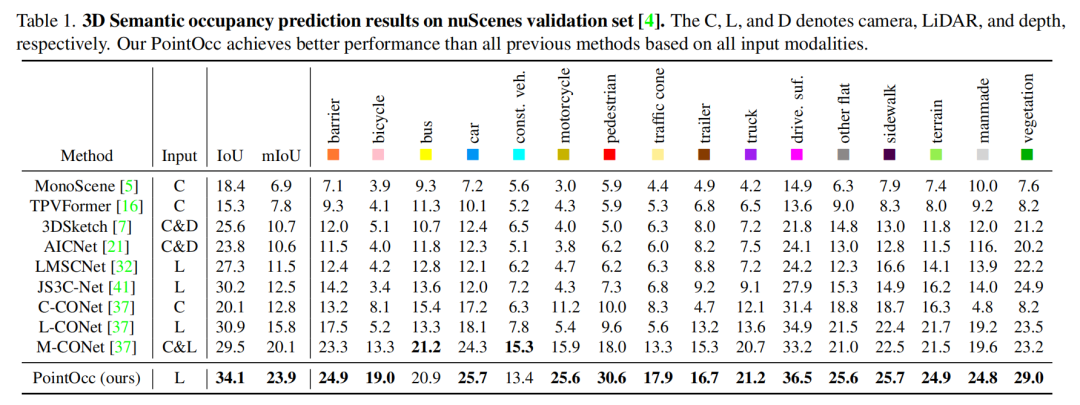
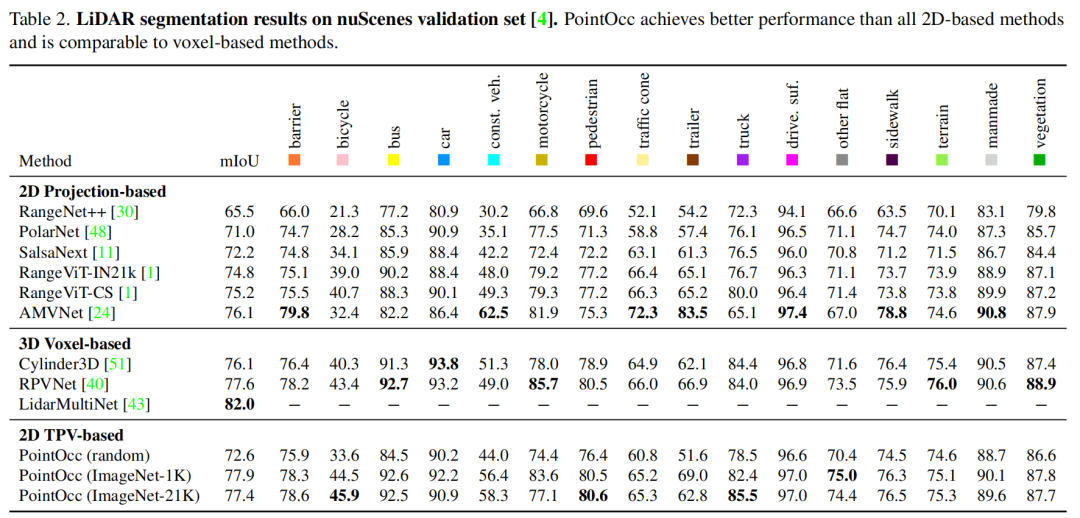
如下表所示,本文方法在nuScenes 3D語義占有預測任務中在mIoU和IoU兩項指標上都達到了最佳性能。本文方法僅使用點云輸入,就在性能上大幅超越了OpenOccupancy中的多模態方法,顯示了PointOcc方法的優越性。
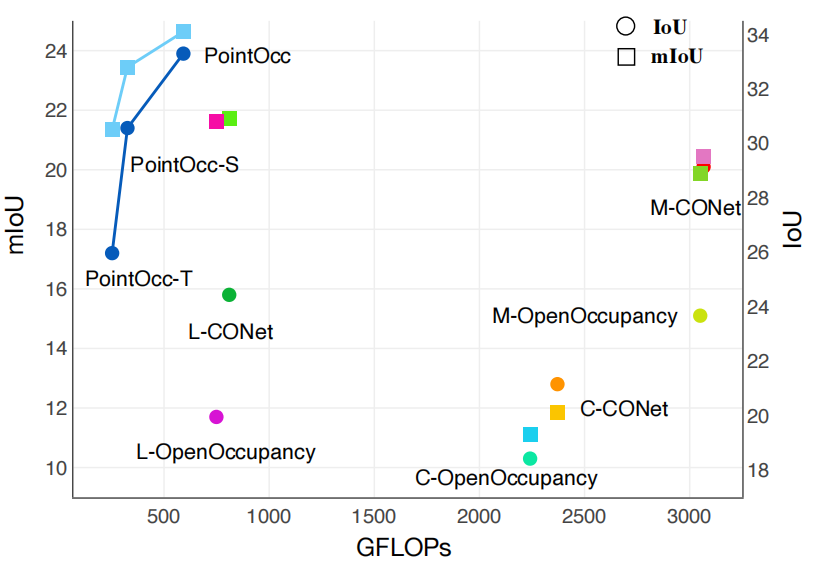
我們進一步比較了PointOcc與其他方法在性能和計算量上的綜合表現。如下圖所示,PointOcc在保持優越性能的同時大幅降低了模型的計算量,顯示了本文方法在處理密集預測任務時具有高效建模復雜3D場景的能力。
3.2 點云分割實驗結果
我們同樣在nuScenes點云分割任務上驗證本文方法的有效性。如下圖所示,本文方法在性能上超越了所有基于2D投影表示的方法而不需要任何后處理操作,并達到了與基于3D體素表示方法相當的性能。此外,我們驗證了2D圖像backbone在圖像數據上預訓練后,能夠提升其在點云感知任務上的性能。
3.3 消融實驗
我們在nuScenes點云分割任務上進行消融實驗,首先驗證三視角平面彼此互補的特性。如下表所示,相比于單平面特征,同時利用三個平面來共同建模3D場景時能夠獲得更大的性能提升。

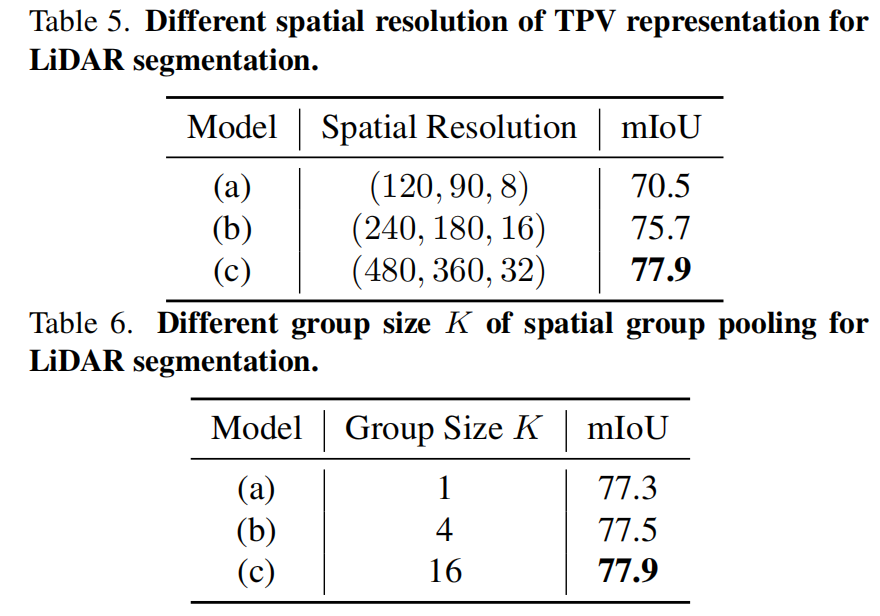
我們還驗證了三視角表示的分辨率和空間分組池化的分組數對模型性能的影響。如下表所示,當三視角表示分辨率越高、空間池化分組越多時,模型的性能越高。這也證明了對3D場景進行更細粒度的建模能夠有效提升模型的性能。
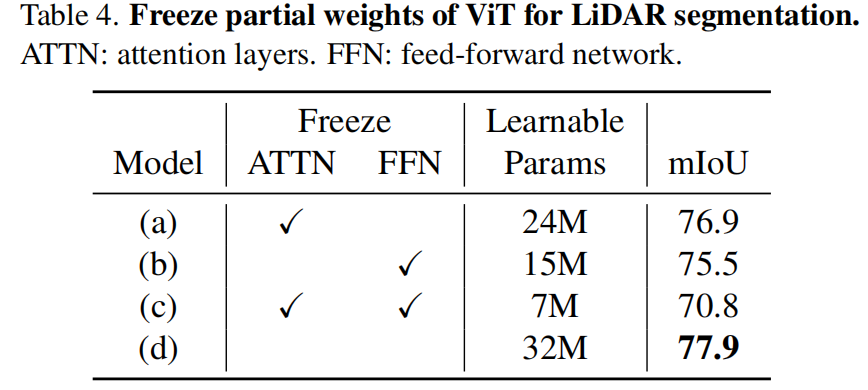
考慮到ViT模型在從圖像遷移到點云數據時展現出驚人的性能,我們進一步探索了將在ImageNet上預訓練的ViT中部分權重凍結時對模型性能的影響。如下表所示,當僅凍結注意力層或FFN層時模型性能并沒有大幅下降,顯示了在圖像數據上預訓練的ViT模型可以很好地泛化到點云感知任務上。
3.4 可視化結果
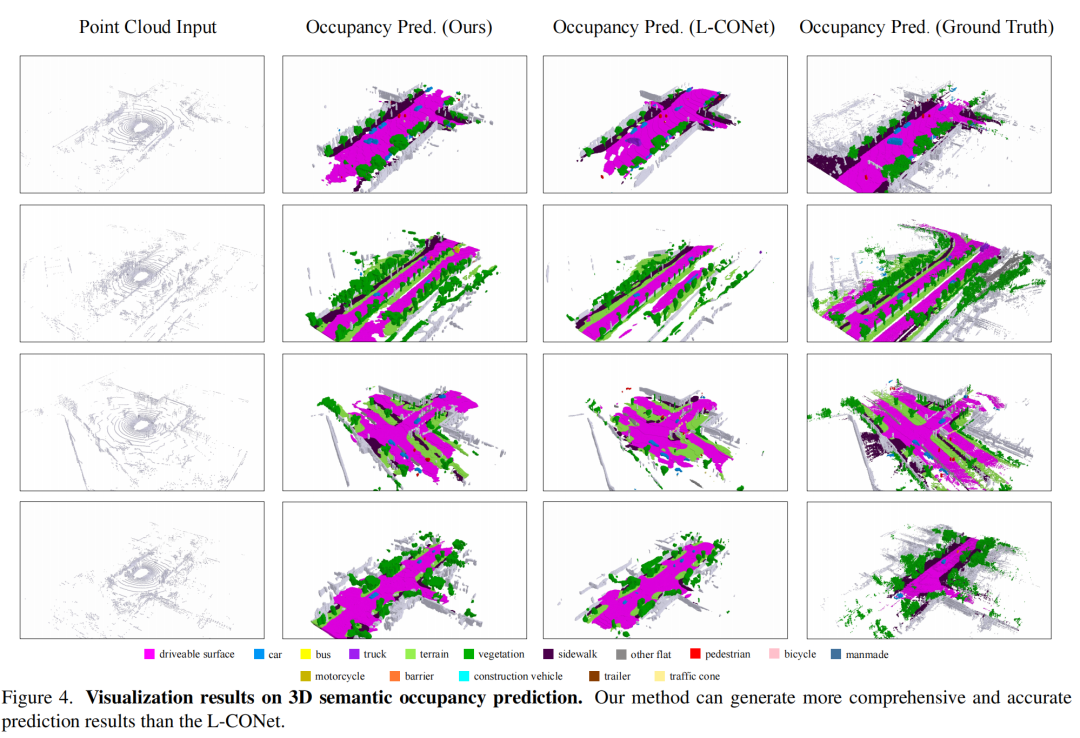
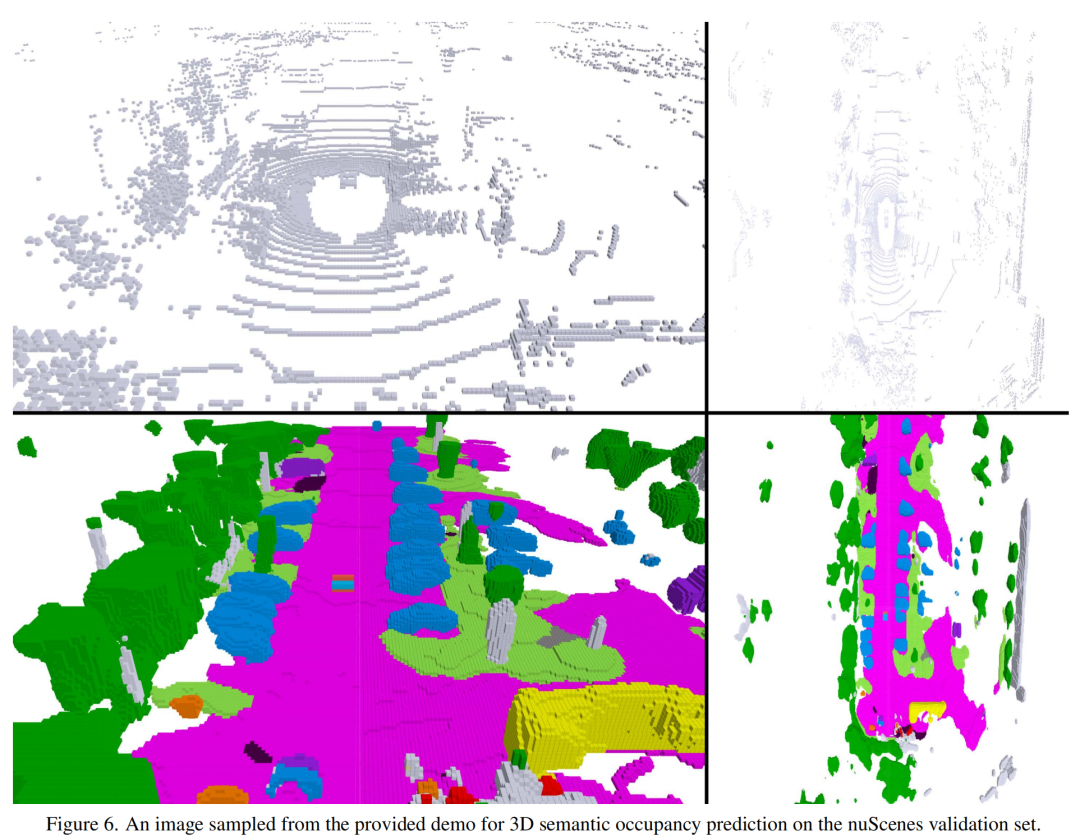

原文鏈接:https://mp.weixin.qq.com/s/7l-hG-y3o51dBzKbNlVJeA






















