













部署新思路 | Minuet:在 GPU 上加速 3D 稀疏卷積
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
原標題:Minuet: Accelerating 3D Sparse Convolutions on GPUs
論文鏈接:https://arxiv.org/pdf/2401.06145.pdf
代碼鏈接:https://github.com/UofT-EcoSystem/Minuet
作者單位:多倫多大學 Vector Institute Amazon Meta Samsung AI Centre Toronto CentML
會議:EuroSys'24

論文思路:
稀疏卷積(Sparse Convolution) (SC) 廣泛用于處理本質上稀疏的 3D 點云。與密集卷積不同,SC 通過僅允許輸出到特定位置來保留輸入點云的稀疏性。為了有效地計算 SC,現有的 SC 引擎(engines)首先使用哈希表來構建內核映射(kernel map),該映射存儲要執行的必要的通用矩陣乘法(GEMM)操作 (Map 步驟),然后使用 Gather-GEMM-Scatter 過程來執行這些 GEMM 操作 (GMaS 步驟)。在這項工作中,本文分析了現有最先進的 SC 引擎的缺點,并提出了 Minuet,一種專為現代 GPU 量身定制的新型內存高效 SC 引擎。Minuet 提出 (i) 用一種新穎的分段排序雙遍歷二分搜索算法(segmented sorting double-traversed binary search algorithm) 替換 Map 步驟中使用的哈希表,該算法高度利用 GPU 的 on-chip 內存層次結構,(ii) 使用輕量級方案在 GMaS 步驟的 Gather 和 Scatter 操作中自動調整 tile 大小,以便使執行適應每個 SC 層、數據集和 GPU 架構的特定特征,以及 (iii) 采用填充高效的 GEMM 聚合方法(grouping approach),減少內存填充和內核啟動開銷。本文的評估表明,對于端到端點云網絡執行,Minuet 的性能明顯優于之前的 SC 引擎,平均性能提高 1.74 倍(最大 2.22 倍)。本文新穎的分段排序雙遍歷二分搜索算法在 Map 步驟中比之前的 SC 引擎平均實現了 15.8 倍(最大 26.8 倍)的卓越加速。
主要貢獻:
本文研究了現有 SC 引擎的缺點,并提出了 Minuet,這是一種內存高效的引擎,可以加速現代 GPU 架構上的 SC 執行。
本文提出了一種新穎的分段排序雙遍歷二分搜索算法來在 SC 中構建內核映射。本文提出的算法高度利用了 GPU 的 on-chip 內存層次結構。本文還在 Gather 和 Scatter 操作中動態選擇性能最佳的 tile 大小,并在對 GEMM 操作進行聚合(group)之前重新排序,以最大程度地減少不必要的數據訪問和計算。
本文使用廣泛的真實數據集、稀疏 3D 網絡和 GPU 架構來評估 Minuet,并表明它在分層和端到端執行方面都顯著優于先前的工作。Minuet 還在 SC 的 Map 步驟中提供了卓越的加速。
論文方法:
在這項工作中,本文使用各種點云網絡、真實數據集和 GPU 架構來描述現有 SC 引擎 [8,9,43],并發現它們存在三個關鍵缺點。首先,他們使用哈希表(例如,cuckoo 哈希表 [1])來構建內核映射,其中存儲必要的 GEMM 操作。然而,在哈希表中執行大量查詢會導致不規則的數據訪問,其中大部分由昂貴的GPU全局內存來服務,從而導致較高的數據訪問成本。其次,最先進的 SC 引擎在 Gather 和 Scatter 操作中將 在 tiles 中的 SC 的多個輸入/輸出特征通道處理為一組連續的特征通道,以提高 GPU 內存吞吐量。然而,本文觀察到他們總是采用單一的固定 tile 大小,這會導致性能不佳。在圖 4 中,本文證明了性能最佳的 tile 大小取決于點云網絡的每個特定 SC 層、真實數據集和 GPU 架構的特征。第三,在 GMaS 步驟中,現有的SC引擎執行與批處理方案中的多個權重偏移相對應的GEMM操作:它們通過用零值填充GEMM操作數將多個GEMM操作聚合在一起,即,它們在所有GEMM操作數中提供相同的大小,并且將它們作為單個批處理 GEMM 內核執行。通過這種方式,他們可以最大限度地減少 GPU 內核啟動開銷并提高 GPU 硬件利用率 [43]。然而,本文發現先前的 SC 引擎在 GMaS 步驟中按照 Map 步驟產生的順序(即權重偏移的順序)將 GEMM 操作聚合。這種方法會導致高填充開銷(第3節),即添加大量零值,從而產生許多冗余數據訪問和計算。
為了解決上述問題,本文提出了 Minuet,這是一種專為現代 GPU 量身定制的新型內存高效 SC 引擎。Minuet 高度利用 GPU 的 on-chip 內存層次結構,使 SC 執行適應輸入數據集和 GPU 架構的特點,減少不必要的數據訪問和計算。在 Map 步驟中,本文挑戰了基于哈希表的搜索比 GPU 上的二分搜索性能優越的普遍觀念 [1, 2],并提出了一種基于二分搜索的創新算法,專門用于在現代 GPU 架構上的 SC 的 Map 步驟中構建內核映射。本文利用在執行排序查詢時,二分搜索實現高系統效率的關鍵觀察結果,利用連續排序查詢之間的數據局部性,并提出分段排序雙遍歷二分搜索算法(segmented sorting double-traversed binary search algorithm)。
本文提出的 SC 算法可以實現與基于哈希表的搜索類似的理論計算復雜度(第 5.1.3 節),并提供顯著更高的內存效率,提高 GPU on-chip caches 的命中率(圖 16b)。在GMaS執行步驟中,Minuet提供了兩種優化。首先,本文在每次 Gather 和 Scatter 操作中即時調整用于處理多個輸入/輸出特征通道的 tile 大小。這項關鍵技術使 Minuet 能夠使 SC 執行適應點云網絡、真實數據集和 GPU 架構中每個 SC 層的特定特征,從而在 Gather 和 Scatter 操作中提供高系統性能。其次,Minuet 集成了一種填充高效的 GEMM 聚合策略,該策略首先根據輸入/輸出特征向量的大小對 GEMM 操作進行重新排序,然后將 GEMM 操作聚合到批量的 GEMM 內核啟動中。通過這種方式,Minuet 可以優化 (i) 零值填充量,從而最大限度地減少對 GEMM 內核中無用數據的不必要的數據訪問和計算,以及 (ii) GEMM 內核啟動(kernel launch) 開銷。
本文使用各種 3D 點云網絡、真實數據集和 GPU 架構對 Minuet 進行了廣泛評估,并證明 Minuet 顯著優于之前的作品。與最先進的 SC 引擎相比,Minuet 的端到端性能平均提高了 1.74 倍(最高 2.22 倍),并且在 Map 步驟比之前的 SC 引擎實現了平均 15.8 倍的卓越加速(最高 26.8倍),在 GMaS 步驟中平均提高 1.39倍(最高 2.38倍)。

圖 6.Minuet 的高層概述。

圖 1. 密集卷積與稀疏卷積。

圖 2. SC 執行可以分為兩個步驟。為了簡單起見,本文使用二維坐標進行說明。

圖 5. 在 SC 中執行 GEMM 操作的各種方法,其中一個藍色和白色方塊分別表示一個實際輸入特征向量和一個零填充特征向量。假設 ?? 和?? 分別是填充特征向量和實際輸入特征向量的數量,則填充開銷定義為(??/??)。

圖 7. 隨機遍歷查詢時執行四個查詢的二分搜索示例(即未排序查詢(左)與排序查詢方法(右))。

圖 8. 完整查詢排序(頂部)和分段查詢排序(底部)的示例。綠色實心框代表在 GPU 全局內存中具體化的(materialized)數組。綠色虛線框表示未在內存中具體化的(materialized)數組,它們的值是即時計算的。

圖 9. 優化相鄰 SC 層中權重偏移和輸出坐標的排序開銷。

圖 10. 當對已排序源數組中的排序查詢段執行二分搜索時(表示為二叉搜索樹 ),使用反向二分搜索查找查詢數組段中 pivot 的下界以減少比較次數的示例。

圖 11. 雙重遍歷二分搜索執行步驟。


實驗結果:




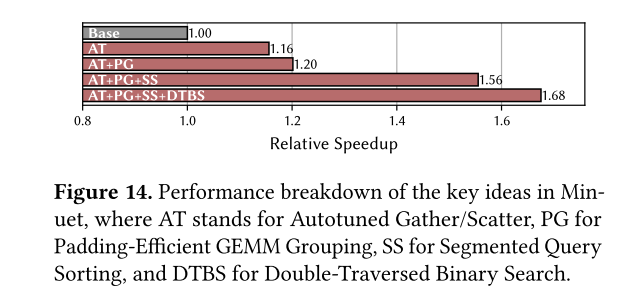






總結:
Minuet 是一款高效 SC 引擎,可在 GPU 上加速 3D 點云網絡。Minuet 高度利用 GPU on-chip 內存層次結構,提高執行并行性和元數據成本,并減少 SC 執行時不必要的數據訪問和計算。本文的評估表明,在各種稀疏點云網絡、數據集和 GPU 架構中,Minuet 在端到端執行時的平均加速明顯優于之前最先進的 SC 引擎 1.74 倍。本文的結論是 Minuet 是一種專為現代 GPU 量身定制的新型內存高效 SC 引擎,并希望本文的工作能夠鼓勵對點云網絡和其他稀疏深度學習網絡的進一步全面研究和優化策略。
原文鏈接:https://mp.weixin.qq.com/s/0K-LUMnQZ8fovouJiqkflw





















