













大火的World Model是什么?DriveDreamer:首個真實世界驅動的自動駕駛世界模型
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
1.背景意義
世界模型(World Models)由于其理解環境、和環境交互的能力,正在自動駕駛領域引起廣泛關注。世界模型具有生成高質量駕駛視頻和用于端到端駕駛的巨大潛力。然而,目前在自動駕駛領域的世界模型研究主要關注游戲環境或模擬環境,缺乏對真實世界駕駛情景的表現。因此,我們引入了DriveDreamer,這是一個完全源自真實世界駕駛情境的開創性世界模型。考慮到在復雜駕駛場景中對世界進行建模涉及龐大的搜索空間,我們提出使用強大的擴散模型來構建對復雜環境的表征。此外,我們引入了一個兩階段的訓練流程。在初始階段,DriveDreamer獲得了對結構化交通約束的深刻理解,而隨后的階段則賦予了它預測未來狀態的能力。所提出的DriveDreamer是首個建立在真實世界駕駛情境之上的世界模型。我們在具有挑戰性的nuScenes基準上實例化了DriveDreamer,并進行了大量實驗,驗證了DriveDreamer能夠實現精確可控的視頻生成,忠實地捕捉了真實世界交通情景的結構約束。此外,DriveDreamer使得生成逼真和合理的駕駛策略成為可能,為互動和實際應用開辟了途徑。

圖1. 所提出的DriveDreamer展示了對自動駕駛場景的全面理解。它在可控駕駛視頻生成方面表現出色,能夠與文本提示和結構化交通約束完美配合。DriveDreamer還可以與駕駛場景互動,并根據輸入的駕駛動作預測不同的未來駕駛視頻。此外,DriveDreamer還擴展了其實用性,可以預測未來的駕駛動作。
2. 相關工作
2.1 擴散模型(Diffusion Models)
擴散模型代表了一類概率生成模型的家族,它們逐漸引入噪聲到數據中,隨后學習逆轉這一過程,以生成樣本。這些模型最近引起了廣泛關注,因為它們在各種應用中表現出卓越性能,為圖像合成、視頻生成和三維內容生成設定了新的基準。ControlNet、GLIGEN、T2I-Adapter和Composer等文章進一步引入了額外的學習參數來增強可控生成能力。它們利用了各種控制輸入,包括深度圖、分割圖、Canny邊緣和草圖。同時,BEVControl和CityDreamer加入了布局條件來增強圖像生成。基于擴散的生成模型的基本本質在于它們理解和理解世界的復雜性。借助這些擴散模型的力量,DriveDreamer旨在理解復雜的自動駕駛場景。
2.2 Video Generation
視頻生成和視頻預測是理解視覺世界的有效方法。在視頻生成領域,已經采用了幾種標準架構,包括變分自編碼器(VAEs)、自回歸模型、基于流的模型和生成對抗網絡(GANs)。最近,新興的擴散模型也已擴展到視頻生成領域,展示了更高質量的視頻生成能力,能夠生成逼真的幀和幀之間的連續過渡,同時提供可控的視頻生成能力。視頻預測模型代表了視頻生成模型的一種專門形式,它們共享許多相似之處。具體而言,視頻預測涉及根據歷史視頻觀察來預測未來視頻變化。DriveGAN通過指定未來的駕駛策略,建立了駕駛動作和像素之間的關聯,從而預測未來的駕駛視頻。相比之下,DriveDreamer將結構化交通條件、文本提示和駕駛動作作為輸入,實現了與真實世界駕駛情景緊密對齊的精確、逼真的視頻和動作生成。
2.3 World Models
世界模型已在基于模型的模仿學習中得到廣泛探討,并在各種應用中取得了顯著的成功。這些方法通常利用VAE和LSTM來建模轉換動態和渲染功能。世界模型的目標是建立環境的動態模型,使代理能夠對未來有預測能力。在自動駕駛領域,這一方面至關重要,因為對未來的精確預測對安全操控至關重要。然而,在自動駕駛中構建世界模型面臨著獨特的挑戰,主要是由于真實世界駕駛任務中固有的高樣本復雜性。為了解決這些問題,ISO-Dream引入了對視覺動態的明確解纏分為可控狀態和不可控狀態。MILE 將世界建模融入BEV語義分割空間中,通過模仿學習增強了世界建模。SEM2 將Dreamer框架擴展到BEV分割圖中,采用強化學習進行訓練。盡管在世界模型方面取得了進展,但相關研究的一個關鍵局限性在于其主要關注模擬仿真環境。轉向真實世界駕駛情景仍然是一個未充分探索的領域。
3. DriveDremear方法設計
DriveDreamer的總體框架如下圖所示。框架始于初始參考幀及其對應的道路結構信息(即HDMap和3D框)。DriveDreamer利用提出的ActionFormer來在潛在空間中預測即將到來的道路結構特征。這些預測的特征作為條件提供給Auto-DM,后者生成未來的駕駛視頻。同時,利用文本提示允許對駕駛情景風格進行動態調整(例如,天氣和時間)。此外,DriveDreamer還結合了歷史行動信息和從Auto-DM中提取的多尺度潛在特征,這些特征組合在一起生成合理的未來駕駛動作。
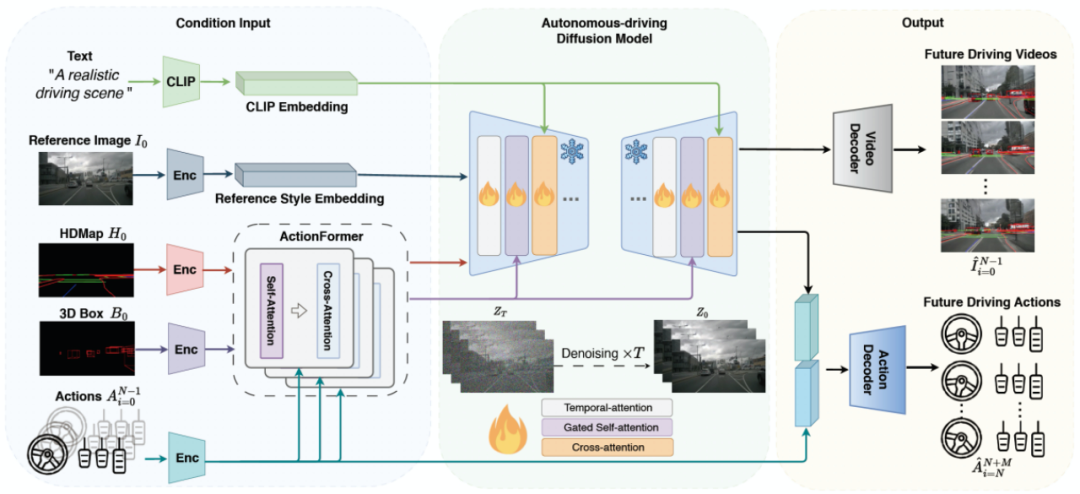
圖2. DriveDreamer框架圖
DriveDreamer集成了多模態輸入,以生成未來的駕駛視頻和駕駛策略,從而提升了自動駕駛系統的能力。關于在真實世界駕駛情景中建立世界模型的龐大搜索空間,我們引入了DriveDreamer的兩階段訓練策略。這個策略旨在顯著提高采樣效率并加速模型的收斂速度。兩階段訓練如下圖所示。在第一階段訓練中有兩個步驟。第一步涉及使用單幀結構化條件,引導DriveDreamer生成駕駛場景圖像,促進其理解結構性交通約束。第二步將其理解擴展到視頻生成。利用交通結構條件,DriveDreamer輸出駕駛場景視頻,進一步增強了其對運動過渡的理解。在第二階段,訓練的重點是使DriveDreamer能夠與環境互動并有效地預測未來狀態。這個階段將初始幀圖像及其對應的結構化信息作為輸入。同時,提供了順序駕駛動作,模型被期望生成未來的駕駛視頻和未來的駕駛動作。這種互動賦予了DriveDreamer預測和操控未來駕駛情景的能力。在接下來的章節中,我們將深入探討模型架構和訓練流程的具體細節。
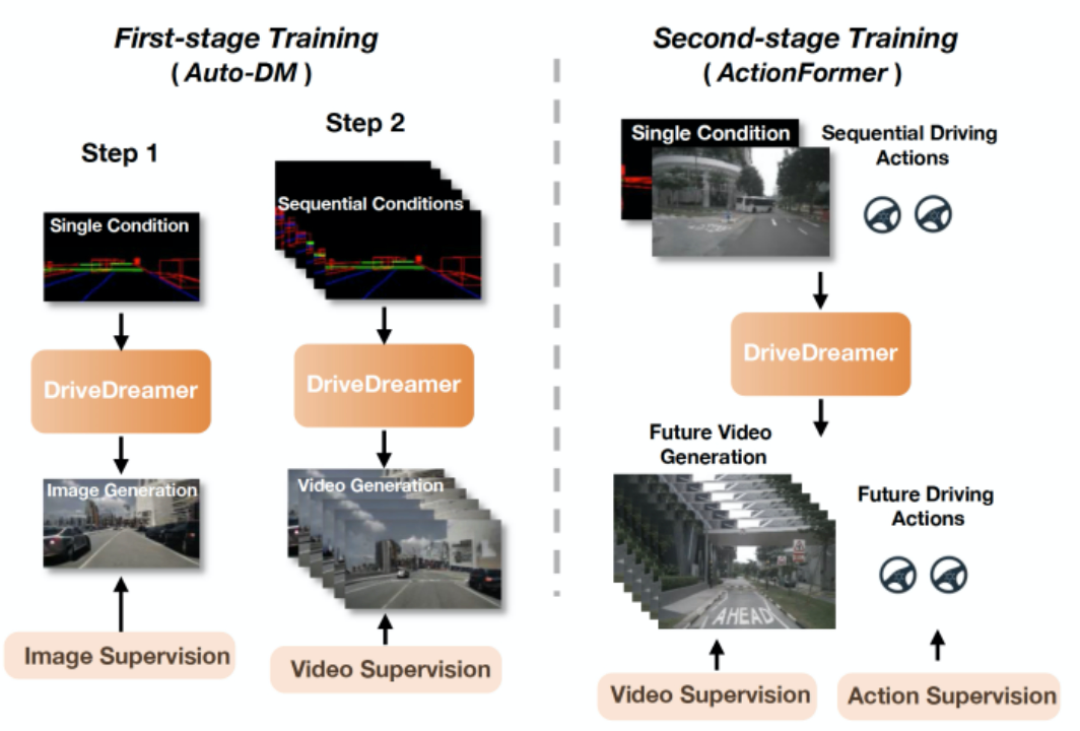
圖3. 兩階段訓練流程圖
3.1 一階段訓練
在DriveDreamer中,我們引入了Auto-DM,用于從真實世界駕駛視頻中建模和理解駕駛情景。值得注意的是,僅從像素空間理解駕駛場景在真實世界駕駛情景中存在挑戰,因為搜索空間非常廣泛。為了緩解這一問題,我們明確地將結構化交通信息作為條件輸入。Auto-DM的總體結構如下圖所示,結構化交通條件被投影到圖像平面上,生成HDMap條件,以及3D框條件,還有框的類別。為了實現可控性,HDMap條件被2D卷積編碼后與由前向擴散過程生成的嘈雜的潛在特征進行串聯處理。對于3D框條件,我們利用Gated Self-attention(參考GLIGEN)進行控制條件的嵌入。為了進一步增強Auto-DM對駕駛動態的理解能力,我們引入了Temporal-attention,這些層增強了生成的駕駛視頻中的幀的連貫性:首先,我們將視覺信號從N×C×H×W重塑為RC×NHW的形狀。這種形狀變換有助于后續的自注意力層學習幀間的動態關系。此外,還使用了Cross-attention來促進文本輸入和視覺信號之間的特征交互,使文本描述能夠影響駕駛場景屬性,如天氣和時間。
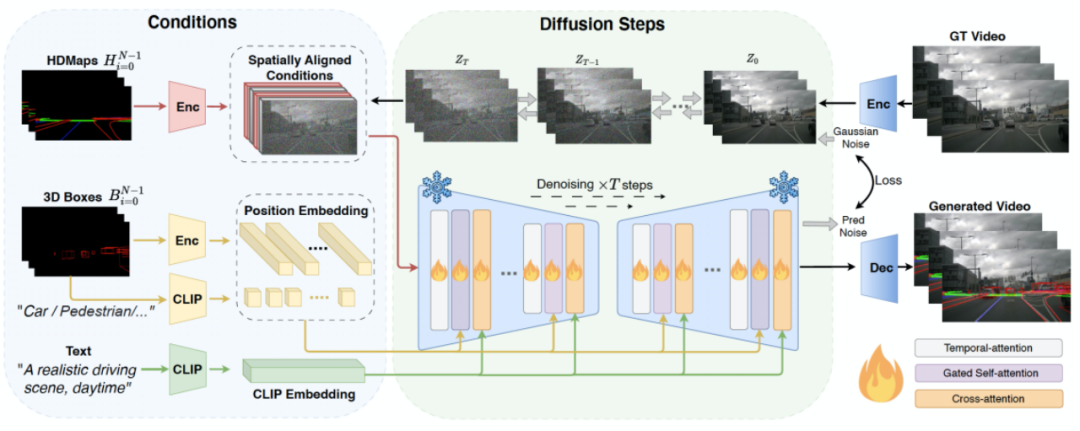
圖4. Auto-DM框架圖
3.2 二階段訓練
目前一階段的Auto-DM可以基于序列結構信息生成駕駛視頻。然而,在視頻預測任務中,超過當前時間戳的未來交通結構條件是不可用的。為了解決這個挑戰,我們在第二階段的訓練中引入了ActionFormer,它利用駕駛動作來迭代預測未來的結構條件。ActionFormer的總體架構如下圖所示。首先,初始結構條件被編碼并展平為1D特征。該特征特征通過自注意力和MLP層進行串聯和匯總,生成隱藏狀態h0。隨后,利用交叉注意力層構建了隱藏狀態和駕駛動作之間的關聯。為了預測未來的隱藏狀態,我們使用門控循環單元(GRUs)進行迭代更新:這些隱藏狀態與動作特征進行串聯,然后被解碼為未來的交通結構條件。值得注意的是,ActionFormer在特征級別預測未來的交通結構條件,這有助于減輕像素級別的噪音干擾,從而產生更魯棒的預測。除了ActionFormer生成的交通結構條件和文本提示條件外,我們參考Video-LDM處理初始的圖像觀測。最后,我們將得到的交通結構化條件、初始幀圖像條件、以及文本條件一起作為Auto-DM的輸入。在二階段訓練中,視頻預測和動作預測部分可以被建模為高斯分布和拉普拉斯分布。因此,我們使用均方差誤差和L1損失來優化視頻預測的訓練。對于駕駛策略的預測,我們首先從Auto-DM中池化多尺度UNet特征。然后,將這些特征與歷史動作特征串聯在一起,然后通過MLP層解碼生成未來的駕駛動作。基于這兩階段的訓練,DriveDreamer已經獲得了對駕駛世界的全面理解,包括交通結構的結構約束、未來駕駛狀態的預測以及與已建立的世界模型進行互動。
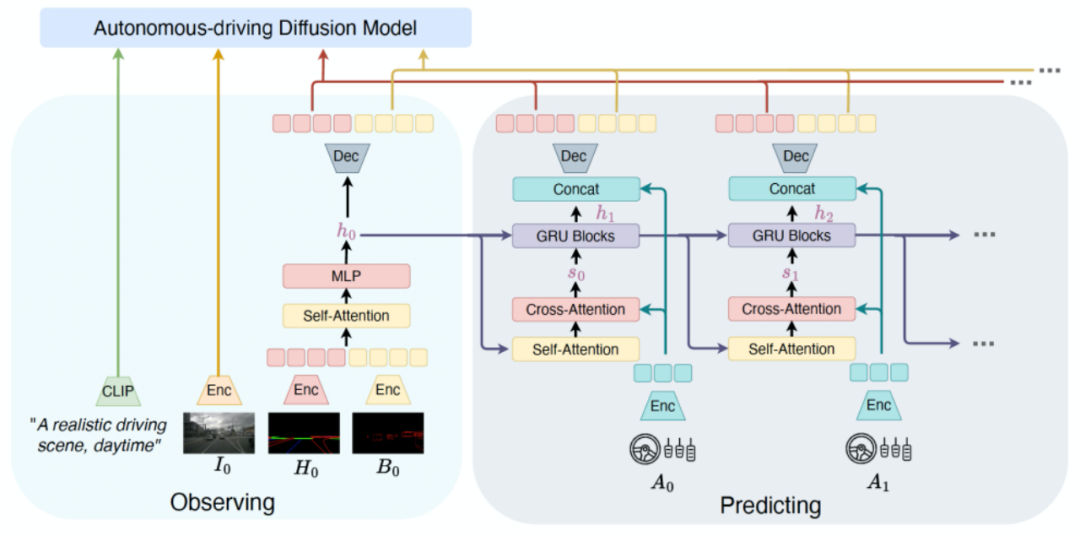
圖5. ActionFormer結構圖
4. 實驗結果
4.1 可控視頻生成
如圖6所示,DriveDreamer在生成各種各樣嚴格遵循結構化交通條件(包括HD地圖和3D框等元素)的駕駛場景視頻方面表現出效果。重要的是,我們還可以操控文本提示來誘發生成視頻的變化,包括天氣和一天中時間的變化。這種增強的適應性顯著提高了生成視頻輸出的多樣性。除了利用結構化交通條件生成駕駛視頻外,DriveDreamer還具備通過適應不同駕駛動作來增加生成的駕駛視頻多樣性的能力。如圖7所示,從初始幀及其對應的結構信息開始,DriveDreamer可以基于各種駕駛動作生成不同的視頻,例如顯示左轉和右轉的視頻。總之,DriveDreamer在生成廣泛范圍的駕駛場景視頻方面表現出色,具有高度可控性和多樣性。因此,DriveDreamer在培訓自動駕駛系統上具有巨大潛力,涵蓋了各種任務,甚至包括邊際情況和長尾場景。為了量化我們的兩階段訓練方法的優勢,我們提供了定量評估(如表1所示),與DriveGAN相比,我們的方法在沒有第一階段訓練的情況下獲得了更高的FID和FVD分數。此外,我們的研究結果表明,經過第一階段訓練后的DriveDreamer表現出對駕駛場景中的結構化信息的理解能力提高,從而生成更高質量的視頻。最后,我們觀察到,所提出的ActionFormer有效地利用了第一階段訓練期間獲得的交通結構信息知識。進一步提高了生成視頻的質量。

圖6. 使用結構化交通條件(HDMap和3D框)生成駕駛視頻,其中利用文本提示來調整駕駛情景的風格(例如,天氣和時間)。
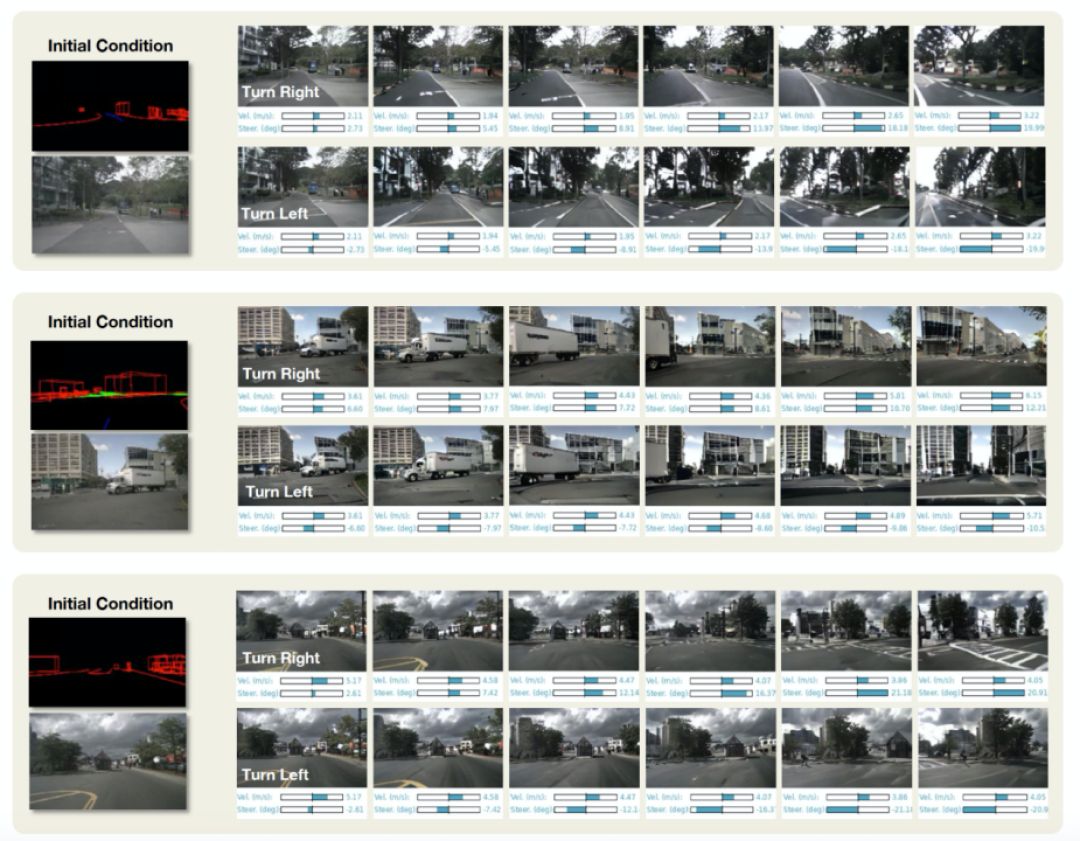
圖7. 基于駕駛策略生成未來駕駛視頻,不同的駕駛動作(例如,左轉,右轉)可以產生相應的駕駛視頻。
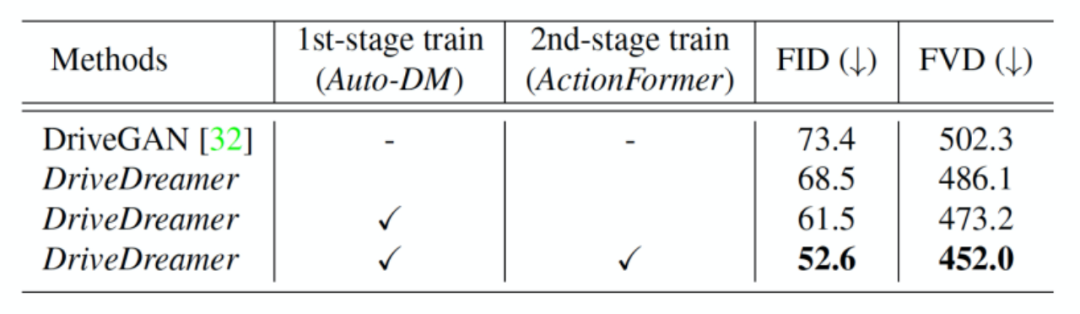
表1. 在nuScenes驗證集上的視頻生成性能評測。
4.2 駕駛策略生成
除了生成可控的駕駛視頻外,DriveDreamer還展示了預測合理駕駛動作的能力。如圖8所示,給定初始幀條件和過去的駕駛動作,DriveDreamer可以生成與真實世界情景相符的未來駕駛動作。與相應的實際視頻進行的生成動作的比較分析表明,即使在復雜情況下,如十字路口、遵守交通信號燈和執行轉彎,DriveDreamer仍然能夠一致地預測合理的駕駛動作。此外,我們進行了預測準確性的定量評估。在nuScenes數據集上進行的開環評估結果如表2所示。值得注意的是,僅使用歷史駕駛動作作為輸入,DriveDreamer在預測未來駕駛動作方面實現了高準確性。偏航角的平均預測誤差僅為0.49°,速度預測誤差僅為0.15 m/s。此外,通過將多尺度UNet特征與歷史駕駛動作結合使用,我們進一步提高了預測準確性。需要注意的是,開環評估具有固有的限制,限制了駕駛動作預測的上限。因此,我們未來的工作將集中在閉環評估上,以進一步驗證和增強DriveDreamer的性能。
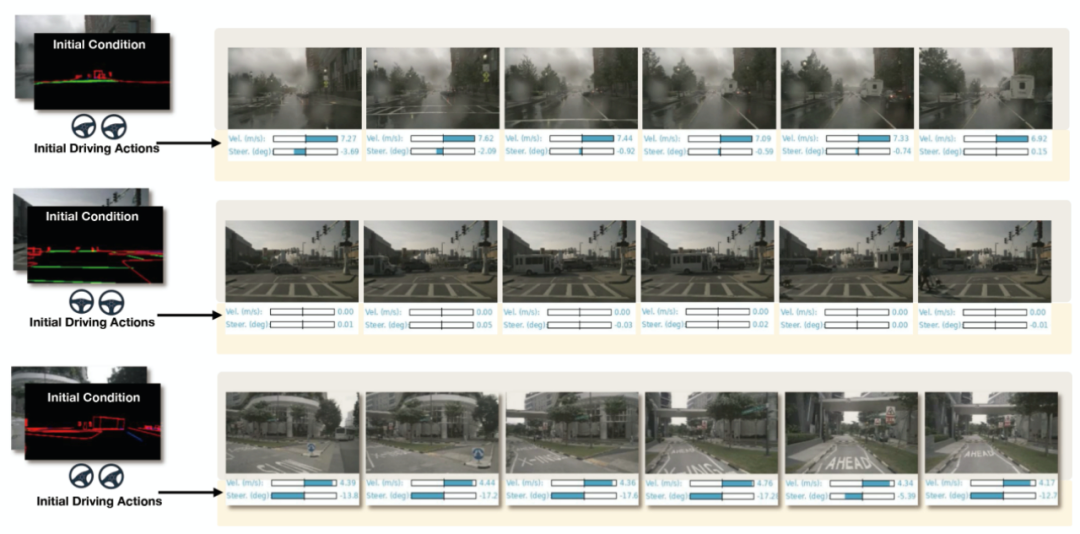
圖8. 預測未來駕駛動作的可視化,以及相應的實際駕駛視頻。

表2.在nuScenes驗證集上的駕駛策略預測性能評測。
5. 總結和展望
DriveDreamer代表了在自動駕駛領域中世界模型的重要探索,通過專注于真實世界的駕駛情境,并利用擴散模型的能力,DriveDreamer展示了其理解復雜環境、生成高質量駕駛視頻和預測駕駛策略的能力。未來的工作將包括使用由DriveDreamer生成的數據來訓練駕駛的foundation model。此外,我們計劃擴展DriveDreamer的能力,以進行長時間和高分辨率的視頻生成。此外,我們打算在閉環場景中評估DriveDreamer。這些努力將共同有助于增強世界建模在自動駕駛應用中的實用性。

原文鏈接:https://mp.weixin.qq.com/s/igon7SWjxqVL_gjGNm0H8A




























