













關于世界模型的一點迷思,以及與自動駕駛結合的幾點思考
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
什么是world models?
什么是world models, 可以參考Yann LeCun的PPT解釋。
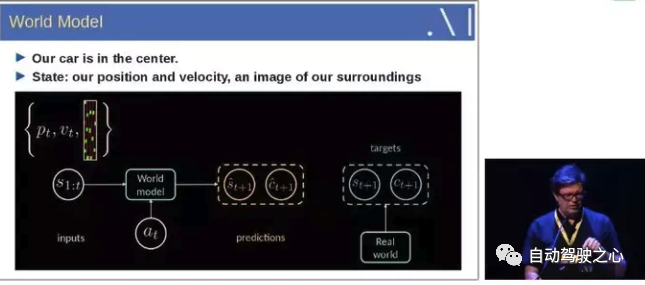
即輸入歷史1到t時刻的狀態信息, 結合當前的動作, 能夠預測接下來的狀態。
通俗地理解, 筆者認為可以把world model理解為世界動態的演化。
world models的研究工作介紹
World models
論文鏈接: https://arxiv.org/abs/1803.10122
這個paper 和 Recurrent World Models Facilitate Policy Evolution 是同一個工作。
這個工作非常重要, 是后面很多工作的思想源泉。
工作導讀
本文構建了一個生成式的world model,它可以用無監督的方式學習周圍時空的表示, 并可以基于這個時空表示, 用一個簡單的Policy模塊來解決具體的任務。
啟發
人類是根據有限的感官來感受并理解這個世界, 我們所做的決策和行為其實都是基于我們自已內部的模型。
為了處理日常生活中大量的信息,我們的大腦會學習這些時空信息。我們能夠觀察一個場景并且記住其中的一些抽象信息。也有證據表明, 我們在任何特定時刻的感知都受到我們的大腦基于內部模型對未來的預測的控制。
比如下面這個圖,看的時候會發現它們好像在動. 但是其實都是靜止的。

方法
通過上面簡單的例子會發現大腦其實預測了未來的感官數據, 即想象了未來可能發生的場景. 基于這個啟示, 作者設計了一套框架, 框架圖如下:

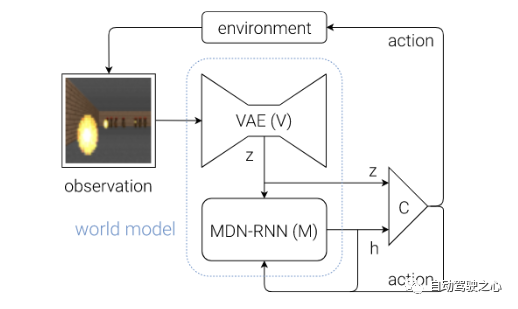
該框架圖有三個主要的模塊組成, 即 Vision Model(V), Memory RNN(M)和 Controller(C)。
首先是Vision Model(V), 這個模塊的主要作用是學習觀測的表示,這里用的方法是VAE, 即變分自編碼器.它的主要作用是將輸入的觀測, 比如圖片,轉成feature。
VAE的網絡結構圖如下:

簡單的解釋就是, 輸入觀測圖片, 先經過encoder提特征, 然后再經過decoder恢復圖像, 整個過程不需要標注, 是自監督的。用VAE的原因個人理解是因為整個設計是生成式的。
其次是Memory RNN(M) ,它的網絡結構如下:

這個模塊的主要作用是學習狀態的演化,可以認為這部分就是world models。
最后是 Controller (C) , 很顯然,這部分的作用就是預測接下來的action,這里設計的非常簡單, 目的就是為了把重心移到前面的模塊中, 前面的模塊可以基于數據來學習.公式如下:
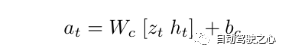
即用歷史的狀態積累 和 當前的 觀測 , 預測接下來的動作。
整個推理流程如下:
即首先是觀測經過V提feature, 然后經過M得到, 最后觀測和歷史信息一塊兒送給C得到動作, 基于動作會和環境交互產生新的觀測...., 這樣可以不斷地進行下去。
PlaNet: Learning Latent Dynamics for Planning from Pixels
論文連接: https://arxiv.org/abs/1811.04551
Blog: https://planetrl.github.io/
工作導讀
本文提出了深度規劃網絡(PlaNet),這是一個基于模型的agent,它從圖像pixels中學習環境的動態變化,之后在緊湊的潛在空間中做規劃并預測動作。為了學習環境的動態變化,提出了一個具有隨機和確定性組件的轉換模型。此外,能做到多步預測。
筆者認為這個工作的最大貢獻是提出了RSSM(Recurrent state space model), 所以接下來主要介紹RSSM。
RSSM
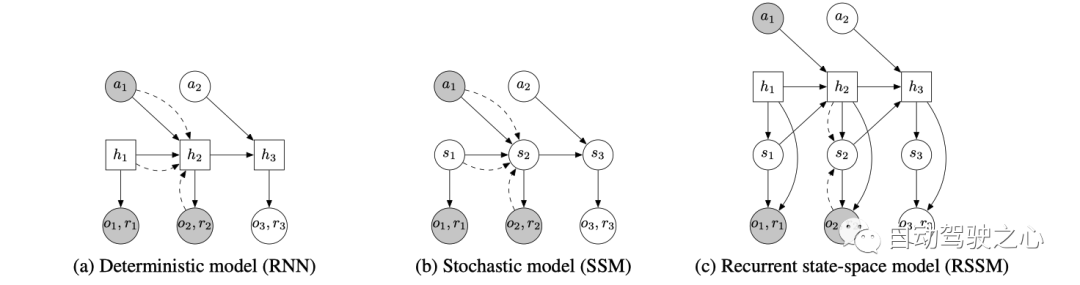
這個圖是本文提出的RSSM與另外兩種方法的比較,如圖所示, 方框代表的是確定式變量, 圓代表的是隨機式變量. 圖a就是一個確定式的模型, 即通過RNN中的 隱式狀態 不斷地傳遞信息, 通過 可以預測action 和reward, 即只要 給定, 預測的 action和reward一定是確定的; 而圖b是隨機式的, 可以看到狀態 是隨機式的, 比如服從某個分布, 那這樣采樣得到的不同, 生成的 action和reward也會隨之而變化, 所以是隨機式的; 圖c可以看到, 預測action和reward的輸入有兩部分組成, 一部分是確定式的, 另一部分是隨機式的。
三種方式的優缺點對比如下:
a. 確定式能夠防止模型隨便預測多種未來, 可以想象, 如果模型不夠準確, 預測的未來就不準, 這對于后面的規劃來說容易出現錯誤的結果。
b. 隨機式的問題是, 隨機的累積多步之后,可能和最初的輸入沒有關系了, 即很難記住信息。
c. 確定式和隨機式相結合, 既有確定部分防止模型隨意發揮, 又有隨機部分提升容錯性。
Dreamer-V1: Dream to Control : Learning behaviors by latent imagination
論文連接: https://arxiv.org/abs/1912.01603
導讀
從題目中可以看出來, Dreamer-V1是基于latent imagination 來學習behaviors, 即dream to control. 有點像周星弛的電影武狀元蘇乞兒里的睡夢羅漢拳. 方法上是基于想象的圖片進行學習.
方法
下圖為DreamerV1的三個組成部分:
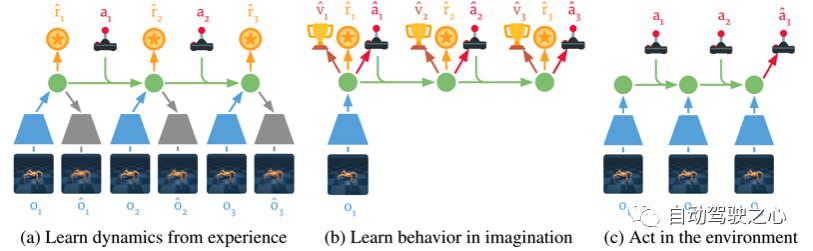
a. 根據歷史的觀測和動作學習環境的dynamics, 主要是學習將觀測和動作提取到compact latent states space中。
b. 通過反向傳播, DreamerV1可以在想象中進行訓練。
c. 基于歷史的狀態和當前的觀測來預測接下來的狀態及動作。
接下來主要介紹如何通過latent 想象學習behaviors。
Learning behaviors by latent imagination
算法流程如下:

注意看, 從開始, 首先對于每個 , 根據如下公式得到接下來的 :
因此就有了 , 之后再預測對應的rewards, 在按照下面的方程:

得到 value function的估計。
DreamerV2: Mastering Atari with Discrete World Models
論文鏈接: https://arxiv.org/abs/2010.02193
導讀
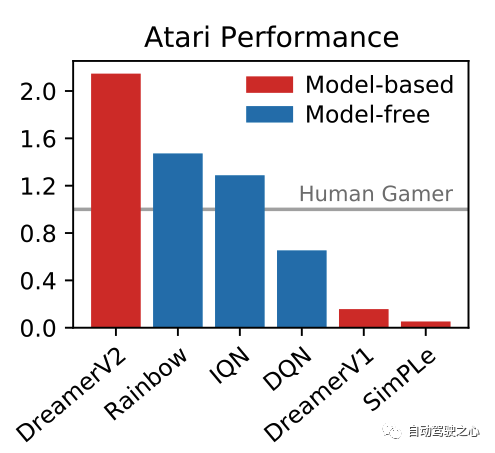
DreamerV1強調的是在latent imagination中學習, DreamerV2強調的是在預測中進行學習;筆者認為二者在學習方式上并無區別. 區別的是 DreamerV2相比DreamerV1用了前面提到的RSSM. 論文題目中提到的 Atari是一個游戲的名字, 而解決這個游戲的方法是離散的世界模型. 這里的離散是因為觀測的輸入剛好可以以離散的形式來表達. DreamerV2是第一個基于模型的方法在Atari這個游戲上超過非模型的方法。
方法
網絡結構如下:
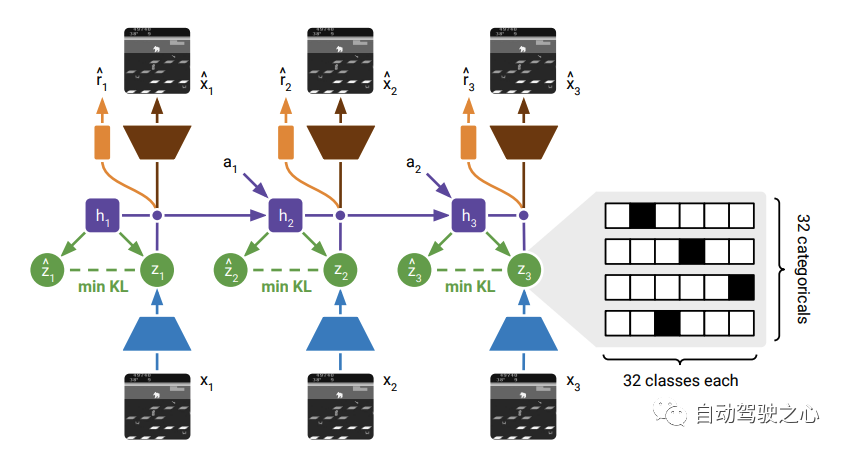
整體結構上和DreamerV1區別不太大, 都有重建圖像的任務. 只不過這里有一項關于先驗與后驗的KL-loss, 即這兩個分布的KL-loss。
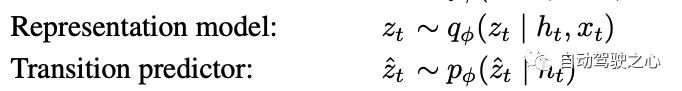
在 Transition 模型這里與DreamerV1也不同, 在V1里面是這樣。
, 即基于歷史的狀態和動作來預測接下來的狀態, 而在V2里面變成了 , 即基于RNN的確定式的隱式狀態來預測接下來的觀測分布. 這里的不同還是主要源于引入了RSSM。
在Actor Critic learning階段的結構如下:
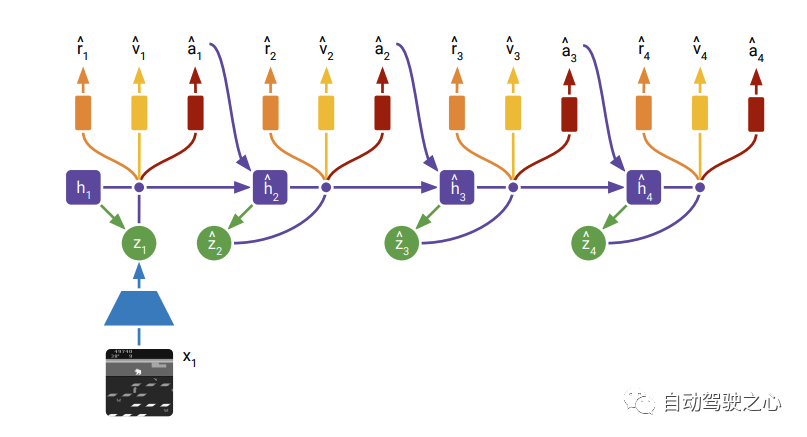
這個過程非常清晰, 即在沒有后續觀測的時候, 直接從先驗的里面進行采樣, 所以在訓練的時候,先驗要逼近后驗。
SEM2:Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
paper鏈接: https://arxiv.org/abs/2210.04017
導讀
從題目中可以看出來, 主要是通過 Semantic Masked World model來提升端自端自動駕駛的采樣效率和魯棒性. 這里Semantic mask指的是接了一個語義分割的head輸出semantic mask, 另外在輸入端也多了lidar。
出發點
作者認為之前的工作中提出的世界模型嵌入的潛在狀態包含大量與任務無關的信息, 導致采樣效率低并且魯棒性差. 并且之前的方法中,訓練數據這塊兒分布是不均衡的, 因此之前的方法學習到的駕駛policy很難應對corner case。
方法概述
針對上面提出的信息冗余, 這里提出了Semantic masked世界模型, 即SEM2. 也就是在decoder部分加入了語義mask 的預測, 讓模型學習到更加緊湊,與駕駛任務更相關的feature; 網絡結構如下:

各部分參數如下:

結構上大體與DreamerV2很相似, 輸入端多了lidar, decoder部分多了一支 Filter用來預測bev的Semantic Mask. 右下角是Semantic Mask的內容信息, 主要包括, 地圖map信息, Routing信息, 障礙物信息和自車的信息。
Multi-Source Sampler
上面作者有提到之前訓練集里面數據不均衡, 比如大直路太多. 這里就用了一種sample的方式, 簡單地說就是在訓練的每個batch中, 均衡的加入各種場景的樣本, 這樣就可以達到訓練樣本平均衡分布的效果。
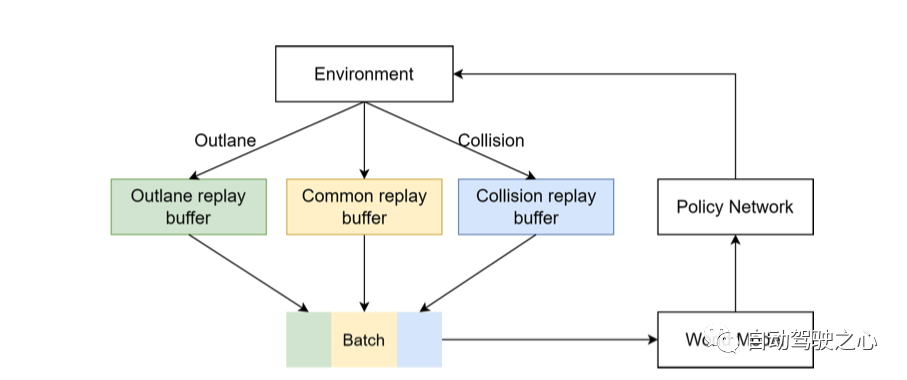
如上圖所示, 正常的數據, 沖出道路的數據,及碰撞的數據在每個batch中混在一起訓練. 這樣模型就能見到各種case的數據, 這有利于泛化解決corner case。
Wayve-MILE: Model-Based Imitation Learning for Urban Driving
代碼: https://github.com/wayveai/mile.
論文: https://arxiv.org/abs/2210.07729
博客: https://wayve.ai/thinking/learning-a-world-model-and-a-driving-policy/
導讀
MILE是Wayve這家公司的研究工作, 有代碼,有詳細的blog解釋, 可謂是好的研究工作。
SEM2的網絡結構中還需要預測reward, 在MILE中就沒有預測reward了, 題目中說是模仿學習, 是因為這里在相同的環境下, 有教練的action作為target, 模型直接學習教練的action,所以叫模仿學習. MILE這個工作很有啟發性, 其中先驗分布, 后驗分布以及采樣的思想, 雖然在前面的幾個工作中也有用到, 但是感覺這些概念在MILE框架下,得到了更好的解釋。
網絡結構
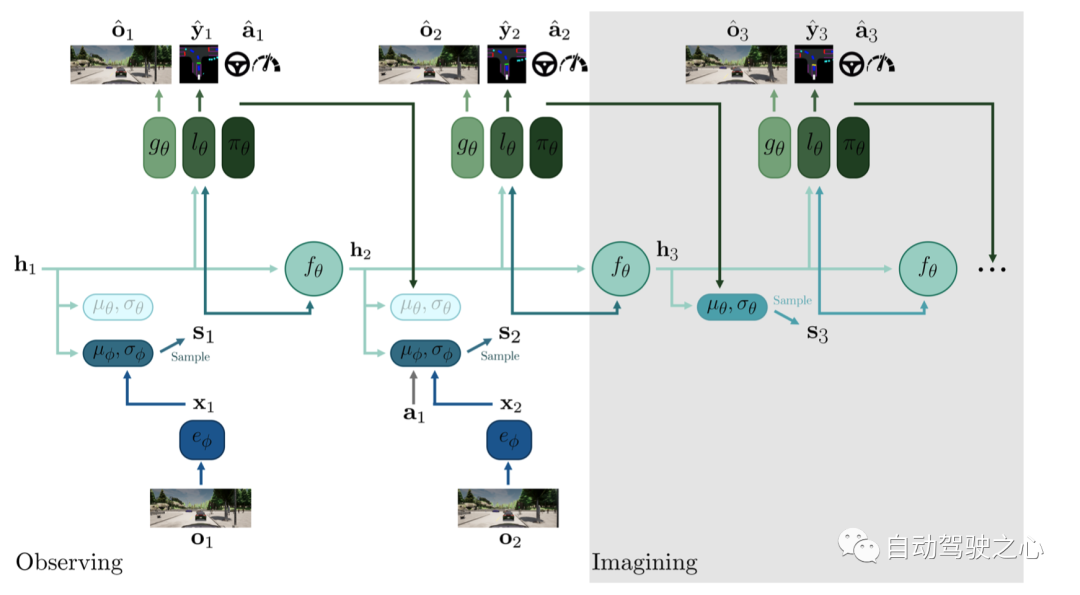
相關參數如下:

- 只看最左側部分,可以認為是VAE的結果, 下半部分是encoder, 上面部分重建圖像是decoder.
- 中間RNN部分, 用的也是RSSM, 這部分可以認為是world model部分,能夠做到生成未來.
- 生成未來的關鍵是要學習到未來的世界的分布, 圖上 就是這個作用, 訓練的時候讓先驗逼近后驗, 推理想象模式下沒有觀測,就從先驗分布中采樣.
- 訓練的時候, 針對先驗后驗那里,采用了dropout機制, 即訓練的時候會以一定的概率從先驗分布中采樣.
- 網絡結構上雖然畫了重建圖像部分, 但是實驗的時候并沒有用到重建圖像的loss.
下面是一個長時間預測的效果圖:

world models的將來發展
筆者認為上面介紹的一些world model的相關工作, 和強化學習、模仿學習等有很大關系, 可以看到世界模型是預測未來的基礎, 筆者認為關于世界模型有幾大思考的方向:
- world model的架構設計, 上面的方法基本上基于RNN, RSSM的框架, 但這種設計是不是最好, 是否有利于訓練,推理,都有待進一步的探索
- world model到底該學習什么, 或者對于具體的任務, 比如自動駕駛中world model應該學習到什么? 2d信息, 3d信息, 軌跡信息,地圖信息,占據信息 。。。。。。, 針對這些信息如何設計方案?
- world model如何與LLM結合, 或者如何利用現有LLM的一些方法、結構和能力。
- 如何做到自監督, 上面的方法中, 比如MILE和SEM2需要semantic mask的標注信息. 但標注但標注數據總是有限且昂貴。

原文鏈接:https://mp.weixin.qq.com/s/VYdMVBpxRd1ETfGf6djK8w
























