登Nature兩年,谷歌「AI 6小時設計芯片」遭打臉?大神Jeff Dean論文被官方調查,疑似隱藏源代碼
近日,一篇由谷歌大神Jeff Dean領銜的「AI自主設計芯片」研究,被曝正式接受Nature調查!
谷歌發表這篇論文后,又在GitHub上開源了具體的Circuit Training代碼,直接引起了整個EDA和IC設計社區的轟動。
然而,這項工作卻在此后不斷遭受質疑。
就在9月20日,Nature終于在這篇論文下面附上了一則聲明:
編者按:請讀者注意,本文中的性能聲明已受到質疑,編輯們正在對這些問題進行調查,一旦調查結束,將酌情采取行動。
 圖片
圖片
論文地址:https://www.nature.com/articles/s41586-021-03544-w
同時,一向給AI大模型潑冷水的馬庫斯也發現,與這篇Nature論文相關的評論文章,也被作者撤回了。
馬庫斯在推特上這樣描述道:「又一個被炒得沸沸揚揚的人工智能成果要落空了?」
 圖片
圖片
現在,相關的Nature評論文章前面,已經被貼上了大寫的「retracted article(撤稿)」。
 圖片
圖片
評論文章:https://www.nature.com/articles/d41586-021-01515-9
因為原本的那篇論文受到了質疑,因此寫作相關評論文章的作者也將其撤回。
作者已撤回這篇文章,因為自文章發表以來,關于所報道論文所用方法,已出現了新信息,因此作者對于該論文貢獻的結論發生了改變。而Nature也在對論文中的結論進行獨立調查。
 圖片
圖片
另外,馬庫斯還挖出了這樣一則猛料:對于Jeff Dean團隊的論文,前谷歌研究人員Satrajit Chatterjee早就提出了質疑。
他寫出一篇反駁的論文,但谷歌表示這篇論文不會被發表,隨后,43歲的Chatterjee被谷歌解雇。
 圖片
圖片
對于此事,紐約時報在2022年5月發文進行了報道
代碼和論文不符
他們將質疑寫成論文,并于今年3月收錄在國際頂尖的集成電路物理設計學術會議ISPD 2023中。
 圖片
圖片
論文地址:https://arxiv.org/abs/2302.11014
在GitHub上,谷歌和斯坦福的聯合團隊公開了代碼,而就是在這段代碼中,UCSD團隊發現了「華點」。
UCSD團隊以開源的方式實現了「Circuit Training」(簡稱CT)項目中的關鍵「黑盒」元素,然后發現,CT與Nature論文中存在差異,并不能被復現!
 圖片
圖片
項目地址:https://github.com/google-research/circuit_training#circuit-training-an-open-source-framework-for-generating-chip-floor-plans-with-distributed-deep-reinforcement-learning
在Nature論文中,谷歌表示,不到六個小時,他們的方法就自動生成了芯片布局圖,而該布局圖在所有關鍵指標(包括功耗、性能和芯片面積)上都優于人類生成的布局圖,或與之相當。
而UCSD團隊發現,這篇論文中的數據和代碼都不是完全可用的。在此期間,他們也得到了谷歌工程師就相關問題的回復。
此外,一篇名為「Stronger Baselines for Evaluating Deep Reinforcement Learning in Chip Placement」的論文聲稱,更強的模擬退火基線優于Nature論文,但顯然使用了谷歌內部版本的CT,以及不同的基準和評估指標。
總之,Nature中的方法和結果,都無法被復現。
 圖片
圖片
UCSD團隊使用了CT、CMP、SA、ReP1Ace和AutoDMP生成了宏布局解決方案,還包括由人類專家生成的宏布局解決方案。在谷歌工程師的指導下,他們使用了0.5作為密度權重,而不是1
文中,UCSD團隊描述了CT關鍵「黑盒」元素的逆向工程一一強制定向放置和智能體成本計算。
這兩個部分,在Nature論文中既沒有被明確記錄,也沒有開源。
另外,UCSD團隊還實現了基于網格的模擬退火宏放置,用于比較Nature論文和更強的基線。
 圖片
圖片
由不同宏放置器生成的Ariane-NG45宏放置
UCSD團隊出具了一份實驗評估報告,揭示了CT的以下幾個方面——
(1)使用商業物理合成工具的初始放置信息會如何影響CT結果
(2)CT的穩定性
(3)CT智能體的成本與商業EDA工具的「真實情況」輸出之間的相關性
(4)更強基線手稿中研究的ICCADO4測試用例的性能
總的來說,UCSD團隊發現,CT和Nature論文所述有幾個顯著的不匹配之處。
CT假設輸入netlist中的所有實例都有(x,y)位置,也就是說,netlist在輸入到CT之前,就已經被放置了。
CT的分組、網格化和聚類過程,都使用了位置信息。
 力導向放置
力導向放置
然而,這些信息在review中并不明顯,在Nature論文中也未被提及。
同樣,解釋CT的兩個關鍵「黑盒」元素——強制定向放置和智能體成本計算,也都沒有在Nature論文中明確記錄,也在CT中也不可見。
這些示例代表了理解和重新實現方法所需的逆向工程,這些方法迄今為止只能通過某些API可見。
 擁塞成本計算
擁塞成本計算
 圖片
圖片
NG45中Ariane的CT訓練曲線,由UCSD團隊和谷歌工程師生成
除了這篇論文外,UCSD團隊還有一個更加詳細的項目主頁,全面記錄了他們針對谷歌這篇Nature論文的研究。
 圖片
圖片
項目地址:https://tilos-ai-institute.github.io/MacroPlacement/Docs/OurProgress/
概括來說,共有十八個「靈魂拷問」。
 圖片
圖片
Nature共同一作長文回應
對此,谷歌和斯坦福聯合團隊的共同一作給出了一份非常詳盡的聲明:
「我們認為,這篇最近在ISPD上發表的特邀論文,對我們的工作進行了錯誤的描述。」
 圖片
圖片
聲明地址:https://www.annagoldie.com/home/statement
首先,介紹一些重要背景:
- 論文提出的RL方法已經用在了多代谷歌旗艦AI加速器(TPU)的生產上(包括最新的一代)。也就是說,基于該方法生成的芯片,已經被制造了出來,并正在谷歌數據中心運行。
亞10納米的驗證程度,遠遠超出了幾乎所有論文的水平。
ML生成的布局必須明顯優于谷歌工程師生成的布局(即超越人類水平),否則不值得冒險。
- Nature進行了長達7個月的同行評審,其中,審稿人包括2名物理設計專家和1名強化學習專家。
- TF-Agents團隊獨立復現了Nature論文的結果。
 圖片
圖片
- 團隊于2022年1月18日開源了代碼。
截至2023年3月18日,已有100多個fork和500多顆星。
開發并開源這個高度優化的分布式RL框架是一個巨大的工程,其應用范圍已經超出了芯片布局,甚至電子設計自動化領域(EDA)。
值得注意的是,在商業EDA領域,開源項目代碼的做法并不常見。
- 在團隊的方法發布之后,有很多基于其工作的論文在ML和EDA會議上發表,此外,英偉達(NVIDIA)、新思科技(Synopsys)、Cadence和三星等公司也紛紛宣布,自己在芯片設計中使用了強化學習。
 圖片
圖片
接著,是針對ISPD論文技術方面的回應:
- ISPD論文并沒有為「電路訓練」(Circuit Training,CT)進行任何預訓練,這意味著RL智能體每次看到一個新的芯片時都會被重置。
基于學習的方法如果從未見過芯片,學習時間當然會更長,性能也會更差!
團隊則先是對20個塊進行了預訓練,然后才評估了表1中的測試案例。
 圖片
圖片
- 訓練CT的計算資源遠遠少于Nature論文中所用到的(GPU數量減半,RL環境減少一個數量級)。
- ISPD論文附帶的圖表表明,CT沒有得到正確的訓練,RL智能體還在學習時就被中斷了。
- 在發表Nature論文時,RePlAce是最先進的。此外,即使忽略上述所有問題,團隊的方法不管是在當時還是在現在,表現都比它更加出色。
- 雖然這項研究標題是「對基于強化學習的宏布局的學習評估」,但它并沒有與任何基于該工作的RL方法進行比較,甚至都沒有承認這些方法。
- ISPD論文將CT與AutoDMP(ISPD 2023)和CMP的最新版本(一款黑盒閉源商業工具)進行了比較。當團隊在2020年發表論文時,這兩種方法都還沒有問世。
- ISPD論文的重點是使用物理合成的初始位置來聚類標準單元,但這與實際情況無關。
- 物理合成必須在運行任何放置方法之前執行。這是芯片設計的標準做法,這也反映在ISPD論文的圖2中。
 圖片
圖片
作為預處理步驟,團隊會重復使用物理合成的輸出來對標準單元進行聚類。需要說明的是,團隊的方法不會放置標準單元,因為之前的方法(如DREAMPlace)已經很好地對它們進行了處理。
在每個RL事件中,團隊都會向RL智能提供一個未放置宏(內存組件)和未放置的標準單元簇(邏輯門),然后RL智能體會將這些宏逐一放置到空白畫布上。
九個月前,團隊在開源存儲庫中記錄了這些細節,并提供了執行此預處理步驟的API。然而,這與論文中的實驗結果或結論沒有任何關系。
最后,團隊表示,目前的方法并不完美,并且肯定會存在效果不太好的情況。
但這只是一個開始,基于學習的芯片設計方法必將對硬件和機器學習本身產生深遠的影響。
用AI,6小時就能設計一款芯片?
回到Nature的這篇文章,2021年,由Jeff Dean領銜的谷歌大腦團隊以及斯坦福大學的科學家們表示:
「一種基于深度強化學習(DL)的芯片布局規劃方法,能夠生成可行的芯片設計方案。」
 圖片
圖片
為了訓練AI干活兒,谷歌研究員可真花了不少心思。
與棋盤游戲,如象棋或圍棋,的解決方案相比較,芯片布局問題更為復雜。
 圖片
圖片
在不到6小時的時間內,谷歌研究人員利用「基于深度強化學習的芯片布局規劃方法」生成芯片平面圖,且所有關鍵指標(包括功耗、性能和芯片面積等參數)都優于或與人類專家的設計圖效果相當。
要知道,我們人類工程師往往需要「數月的努力」才能達到如此效果。
 圖片
圖片
人類設計的微芯片平面圖與機器學習系統設計
在論文中,谷歌研究人員將芯片布局規劃方法當做一個「學習問題」。
潛在問題設計高維contextual bandits problem,結合谷歌此前的研究,研究人員選擇將其重新制定為一個順序馬可夫決策過程(MDP),這樣就能更容易包含以下幾個約束條件:
(1)狀態編碼關于部分放置的信息,包括netlist(鄰接矩陣)、節點特征(寬度、高度、類型)、邊緣特征(連接數)、當前節點(宏)以及netlist圖的元數據(路由分配、線數、宏和標準單元簇)。
(2)動作是所有可能的位置(芯片畫布的網格單元) ,當前宏可以放置在不違反任何硬約束的密度或擁塞。
(3)給定一個狀態和一個動作,「狀態轉換」定義下一個狀態的概率分布。
(4)獎勵:除最后一個動作外,所有動作的獎勵為0,其中獎勵是智能體線長、擁塞和密度的負加權。
研究人員訓練了一個由神經網絡建模的策略(RL智能體),通過重復的事件(狀態、動作和獎勵的順序),學會采取將「累積獎勵最大化」的動作。
然后,研究人員使用鄰近策略優化(PPO)來更新策略網絡的參數,給定每個放置的累積獎勵。
 圖片
圖片
研究人員將目標函數定義如下:
 圖片
圖片
如前所述,針對芯片布局規劃問題開發領域自適應策略極具挑戰性,因為這個問題類似于一個具有不同棋子、棋盤和贏條件的博弈,并且具有巨大的狀態動作空間。
為了應對這個挑戰,研究人員首先集中學習狀態空間的豐富表示。
谷歌研究人員表示,我們的直覺是,能夠處理芯片放置的一般任務的策略也應該能夠在推理時將與新的未見芯片相關的狀態編碼為有意義的信號。
因此,研究人員訓練了一個「神經網絡架構」,能夠預測新的netlist位置的獎勵,最終目標是使用這個架構作為策略的編碼層。
為了訓練這個有監督的模型,就需要一個大型的芯片放置數據集以及相應的獎勵標簽。
因此,研究人員創建了一個包含10000個芯片位置的數據集,其中輸入是與給定位置相關聯的狀態,標簽是該位置的獎勵。
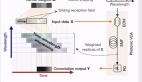
為了準確地預測獎勵標簽并將其推廣到未知數據,研究人員提出了一種基于邊的圖神經網絡結構,稱之為Edge-GNN(Edge-Based Graph Neural Network)。
在Edge-GNN中,研究人員通過連接每個節點的特征(包括節點類型、寬度、高度、x和y坐標以及它與其他節點的連通性)來創建每個節點的初始表示。
然后再迭代執行以下更新:
(1)每個邊通過應用一個完全連通的網絡連接它連接的兩個節點更新其表示;
(2)每個節點通過傳遞所有的平均進出邊到另一個完全連通的網絡更新其表示。
 圖片
圖片
Edge-GNN的作用是嵌入netlist,提取有關節點類型和連通性的信息到一個低維向量表示,可用于下游任務。
 基于邊的神經結構對泛化的影響
基于邊的神經結構對泛化的影響
研究人員首先選擇了5個不同的芯片凈網表,并用AI算法為每個網表創建2000個不同的布局位置。
該系統花了48個小時在「英偉達Volta顯卡」和10個CPU上「預訓練」,每個CPU都有2GB的RAM。
 圖片
圖片
左邊,策略正在從頭開始訓練,右邊,一個預訓練的策略正在為這個芯片進行微調。每個矩形代表一個單獨的宏放置
在一項測試中,研究人員將他們的系統建議與手動基線——谷歌TPU物理設計團隊創建的上一代TPU芯片設計——進行比較。
結果顯示,系統和人類專家均生成符合時間和阻塞要求的可行位置,而AI系統在面積、功率和電線長度方面優于或媲美手動布局,同時滿足設計標準所需的時間要少得多。
但現在,這篇曾引起整個EDA和IC設計社區的轟動的論文,如今在被Nature重新調查,不知后續會如何發展。
參考資料:
https://tilos-ai-institute.github.io/MacroPlacement/Docs/OurProgress/
https://www.nature.com/articles/s41586-021-03544-w
https://www.nature.com/articles/s41586-021-03544-w
https://twitter.com/GaryMarcus/status/1706861649762869330