













BEV下的Radar-Camera跨數據集融合實驗研究
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
原標題:Cross-Dataset Experimental Study of Radar-Camera Fusion in Bird’s-Eye View
論文鏈接:https://arxiv.org/pdf/2309.15465.pdf
作者單位:Opel Automobile GmbH Rheinland-Pfalzische Technische Universitat Kaiserslautern-Landau German Research Center for Artificial Intelligence

論文思路:
通過利用互補的傳感器信息,毫米波雷達和camera融合系統有潛力為先進的駕駛員輔助系統和自動駕駛功能提供高度穩健和可靠的感知系統。基于相機的目標檢測的最新進展提供了新的毫米波雷達相機與鳥瞰特征圖融合的可能性。本文提出了一種新穎且靈活的融合網絡,并評估其在兩個數據集上的性能:nuScenes 和 View-of-Delft。本文的實驗表明,雖然camera分支需要大量且多樣化的訓練數據,但毫米波雷達分支從高性能毫米波雷達中受益更多。使用遷移學習,本文提高了camera在較小數據集上的性能。本文的結果進一步表明,毫米波雷達-camera融合方法顯著優于僅camera和僅毫米波雷達基線。
網絡設計:
最近3D目標檢測的一個趨勢是將圖像的特征轉換成一種常見的鳥瞰圖(BEV)表示,它提供了一種靈活的融合架構,可以在多個camera之間進行融合,也可以使用測距傳感器進行融合。在這項工作中,本文擴展了原本用于激光camera融合的BEVFusion方法來進行毫米波雷達camera融合。本文用選定的毫米波雷達數據集訓練和評估了本文提出的融合方法。在幾個實驗中,本文討論了每個數據集的優缺點。最后,本文應用遷移來實現進一步的改進。

圖1基于BEVFusion的BEV毫米波雷達-camera融合流程圖。在生成的camera圖像中,本文包括投影毫米波雷達探測和 ground truth 邊界框。
本文遵循BEVFusion的融合架構。圖1展示了本文在BEV中進行毫米波雷達-camera融合的網絡概況。請注意,融合發生時,camera和毫米波雷達特征在BEV連接。下面,本文將為每個區塊提供進一步的細節。
A. Camera Encoder and Camera-to-BEV View Transform
camera編碼器和視圖變換采用了[15]的思想,它是一種靈活的框架,可以提取任意camera外部和內部參數的圖像BEV特征。首先,使用tiny-Swin Transformer網絡從每個圖像中提取特征。接下來,本文利用[14]的 Lift 和 Splat 步驟將圖像的特征轉換到BEV平面。為此,密集深度預測之后是基于規則的block,其中的特征被轉換成偽點云,并進行柵格化并累積到BEV網格中。
B. Radar Pillar Feature Encoder
此塊的目的是將毫米波雷達點云編碼到與圖像BEV特征相同的網格上的BEV特征中。為此,本文使用了[16]的 pillar 特征編碼技術,將點云光柵化為無限高的體素,即所謂的pillar。
C. BEV Encoder
與[5]相似,毫米波雷達和camera的BEV特征是通過級聯融合的。融合的特征然后由聯合卷積BEV編碼器處理,使網絡能夠考慮空間錯位和使用不同模態之間的協同效應。
D. Detection Head
本文使用CenterPoint檢測頭來預測每個類的目標中心的heatmaps。進一步的回歸頭預測物體的尺寸、旋轉和高度,以及nuScenes的速度和類屬性。而 heatmaps 采用 Gaussian focal loss 進行訓練,其余的檢測頭采用 L1 loss 進行訓練。
實驗結果:

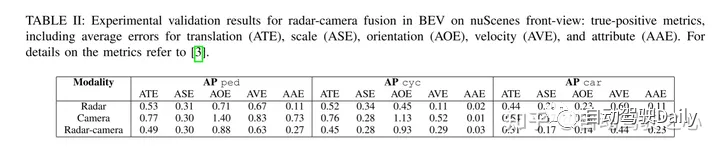

引用:
St?cker, L., Heidenreich, P., Rambach, J., & Stricker, D. (2023). Cross-Dataset Experimental Study of Radar-Camera Fusion in Bird's-Eye View. ArXiv. /abs/2309.15465

原文鏈接:https://mp.weixin.qq.com/s/ayZl9tnm47y9VpfgmIG2qg



























