DriveGPT4:自動駕駛或將迎來GPT時刻?結合LLM的端到端系統來了!
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
筆者的個人理解
在過去的十年里,自動駕駛在學術界和工業界都得到了快速發展。然而其有限的可解釋性仍然是一個懸而未決的重大問題,嚴重阻礙了自動駕駛的發展進程。以前使用小語言模型的方法由于缺乏靈活性、泛化能力和魯棒性而未能解決這個問題。近兩年隨著ChatGPT的出現,多模態大型語言模型(LLM)因其通過文本處理和推理非文本數據(如圖像和視頻)的能力而受到研究界的極大關注。因此一些工作開始嘗試將自動駕駛和大語言模型結合起來,今天汽車人為大家分享的DriveGPT4就是利用LLM的可解釋實現的端到端自動駕駛系統。DriveGPT4能夠解釋車輛動作并提供相應的推理,以及回答用戶提出的各種問題以增強交互。此外,DriveGPT4以端到端的方式預測車輛的運動控制。這些功能源于專門為無人駕駛設計的定制視覺指令調整數據集。DriveGPT4也是世界首個專注于可解釋的端到端自動駕駛的工作。當與傳統方法和視頻理解LLM一起在多個任務上進行評估時,DriveGPT4表現出SOTA的定性和定量性能。
項目主頁:https://tonyxuqaq.github.io/projects/DriveGPT4/
總結來說,DriveGPT4的主要貢獻如下:
- 為可解釋的自動駕駛開發了一個新的視覺指令調整數據集。
- 提出了一個全新的多模態LLM—DriveGPT4。DriveGPT4對創建的數據集進行了微調,可以處理多模態輸入數據,并提供文本輸出和預測的控制信號。
- 在多個任務上評估所有方法,DriveGPT4的性能優于所有基線。此外,DriveGPT4可以通過零樣本泛化處理看不見的場景。
通過ChatGPT生成指令數據
具體來說,DriveGPT4訓練使用的視頻和標簽是從BDD-X數據集中收集的,該數據集包含約20000個樣本,包括16803個用于訓練的clip和2123個用于測試的clip。每個clip采樣8個圖像。此外,它還提供每幀的控制信號數據(例如,車輛速度和車輛轉彎角度)。BDD-X為每個視頻clip提供了關于車輛行動描述和行動理由的文本注釋,如圖1所示。在以前的工作中,ADAPT訓練caption網絡來預測描述和理由。但是,提供的描述和標簽是固定的和剛性的。如果人類用戶希望了解更多關于車輛的信息并詢問日常問題,那么過去的工作可能會功虧一簣。因此,僅BDD-X不足以滿足可解釋自動駕駛的要求。

由ChatGPT/GPT4生成的指令調整數據已被證明在自然語言處理、圖像理解和視頻理解中對性能增強是有效的。ChatGPT/GPT4可以訪問更高級別的信息(例如,圖像標記的captions、GT目標邊界框),并可以用于提示生成對話、描述和推理。目前,還沒有為自動駕駛目的定制的視覺指令跟隨數據集。因此,我們在ChatGPT的輔助下,基于BDD-X創建了自己的數據集。
修正問題回答。由于BDD-X為每個視頻clip提供了車輛動作描述、動作理由和控制信號序列標簽,因此我們直接使用ChatGPT基于這些標簽生成一組三輪問答(QA)。首先,我們創建三個問題集:Qa、Qj和Qc。
- Qa包含相當于“這輛車目前的行動是什么?”的問題。
- Qj包含相當于“為什么車輛會有這種行為?”的問題。
- Qc包含相當于“預測下一幀中車輛的速度和轉彎角度”的問題。
LLM可以同時學習預測和解釋車輛動作。但是如前所述,這些QA具有固定和嚴格的格式。由于缺乏多樣性,僅對這些QA進行訓練會降低LLM的推理能力,使其無法回答其他形式的問題。
ChatGPT生成的對話。為了解決上述問題,ChatGPT作為一名教師以生成更多關于自車的對話。提示通常遵循LLaVA中使用的提示設計。為了使ChatGPT能夠“看到”視頻,YOLOv8用于檢測視頻每幀中常見的目標(例如,車輛、行人)。所獲得的目標框作為更高級別的信息饋送到ChatGPT。除了目標檢測結果外,ChatGPT還可以訪問視頻clip的真實控制信號序列和captions。基于這些特權信息,ChatGPT會被提示生成關于自車、紅綠燈、轉彎方向、變道、周圍物體、物體之間的空間關系等的多輪和類型的對話。詳細提示見附錄。
最后,我們收集了28K的視頻文本指令如下樣本,包括由ChatGPT生成的16K固定QA和12K對話。生成的示例如表1所示。

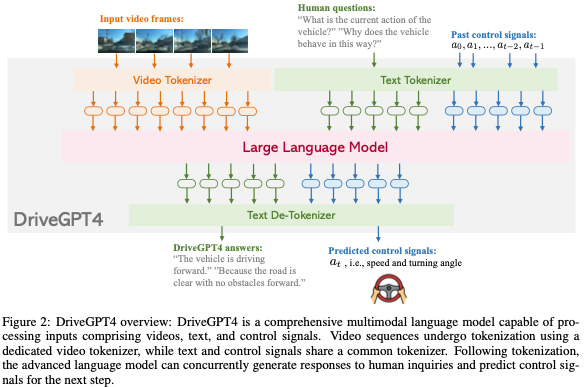
DriveGPT4
模型架構
DriveGPT4是一個多功能多模態的LLM,能夠處理各種輸入類型,包括視頻、文本和控制信號。視頻被均勻地采樣到固定數量的圖像中,并使用基于Valley的視頻標記器將視頻幀轉換為文本域標記。從RT-2中汲取靈感,文本和控制信號使用相同的文本標記器,這意味著控制信號可以被解釋為一種語言,并被LLM有效地理解和處理。所有生成的令牌都被連接起來并輸入到LLM中。本文采用LLaMA 2作為LLM。在生成預測的令牌后,de-tokenizer對其進行解碼以恢復人類語言。解碼文本包含固定格式的預測信號。DriveGPT4的整體架構如圖2所示。
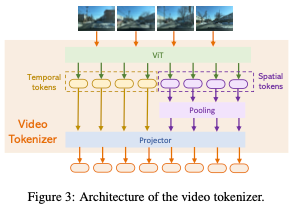
視頻標記器。視頻標記器基于Valley。對于每個視頻幀,使用預訓練的CLIP視覺編碼器來提取其特征。的第一個通道表示的全局特征,而其他256個通道響應的patch特征。為了簡潔地表示,的全局特征被稱為,而的局部patch特征被表示為。然后,整個視頻的時間視覺特征可以表示為:

同時,整個視頻的空間視覺特征由下式給出:
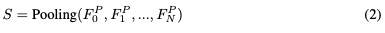
最終,使用projector將視頻的時間特征T和空間特征S都投影到文本域中。tokenizer的詳細結構如圖3所示。
文本和控制信號。受RT-2的啟發,控制信號的處理類似于文本,因為它們屬于同一域空間。控制信號直接嵌入文本中進行提示,并使用默認的LLaMA標記器。在本研究中,ego車輛的速度v和轉向角?被視為目標控制信號。轉向角度表示當前幀和初始幀之間的相對角度。在獲得預測的令牌后,LLaMA的tokenizer用于將令牌解碼回文本。DriveGPT4預測后續步驟的控制信號,即(vN+1,?N+1)。預測的控制信號使用固定格式嵌入輸出文本中,通過簡單的后處理可以輕松提取。表2中給出了DriveGPT4的輸入和輸出示例。

訓練
與以往LLM相關研究一致,DriveGPT4的訓練包括兩個階段:(1)預訓練階段,重點是視頻文本對齊;以及(2)微調階段,旨在訓練LLM回答與端到端自動駕駛相關的問題。
預訓練。與LLaVA和Valley一致,該模型對來自CC3M數據集的593K個圖像-文本對和來自WebVid-10M數據集的100K個視頻-文本對進行了預訓練。預訓練圖像和視頻包含各種主題,并不是專門為自動駕駛應用設計的。在此階段,CLIP編碼器和LLM權重保持固定。只有視頻標記器被訓練為將視頻與文本對齊。
微調。在這個階段,DriveGPT4中的LLM與可解釋的端到端自動駕駛的視覺標記器一起進行訓練。為了使DriveGPT4能夠理解和處理主要知識,它使用前文中生成的28K視頻文本指令進行訓練。為了保持DriveGPT4回答日常問題的能力,還使用了LLaVA生成的80K指令跟蹤數據。因此,在微調階段,DriveGPT4使用28K視頻文本指令跟隨數據以及80K圖像文本指令跟隨的數據進行訓練。前者確保了DriveGPT4可以應用于可互操作的端到端自動駕駛,而后者增強了數據靈活性,有助于保持DriveGPT4的通用問答能力。
實驗
可解釋的自動駕駛
在本節評估了DriveGPT4及其解釋生成的基線,包括車輛行動描述、行動理由和有關車輛狀態的其他問題。ADAPT是最先進的基線工作。最近的多模式視頻理解LLM也被考慮進行比較。ADAPT采用32幀視頻作為輸入,而其他方法則采用8幀視頻作為輸出。
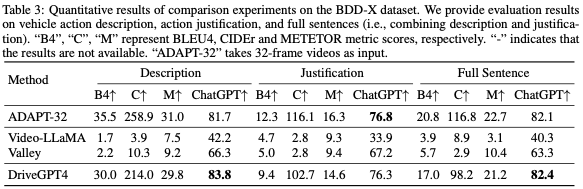
評估指標。為了詳細評估這些方法,本文報告了NLP社區中廣泛使用的多個指標得分,包括BLEU4、METEOR和CIDEr。然而,這些指標主要衡量單詞級別的性能,而沒有考慮語義,這可能會導致意想不到的評估結果。鑒于ChatGPT強大的推理能力,它被用來衡量預測質量,并提供更合理的分數。ChatGPT會被提示分配一個介于0和1之間的數字分數,分數越高表示預測精度越高。基于ChatGPT的評估的詳細提示見附錄。度量比較示例如圖4所示。與傳統指標相比,Chat-GPT生成的分數為評估提供了更合理、更令人信服的依據。

行動描述和理由。考慮到評估的成本和效率,DriveGPT4在來自BDD-X測試集的500個隨機采樣的視頻clip上進行了測試。目標是盡可能根據給定標簽預測車輛行動描述和理由。評估結果顯示在表3中。結果表明,與之前最先進的(SOTA)方法ADAPT相比,DriveGPT4實現了卓越的性能,盡管ADAPT使用32幀視頻,而DriveGPT4只有8幀視頻作為輸入。
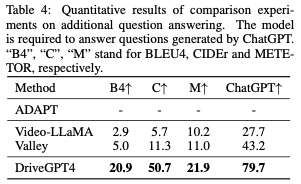
附加問答。上述車輛行動描述和理由具有相對固定的格式。為了進一步評估DriveGPT的可解釋能力和靈活性,在第3節中生成了其他問題。BDD-X測試集中的100個隨機采樣的視頻片段用于生成問題。與行動描述和理由相比,這些問題更加多樣化和靈活。評價結果如表4所示。ADAPT無法回答除車輛操作說明和理由之外的其他問題。之前的視頻了解LLM可以回答這些問題,但他們沒有學習到駕駛領域的知識。與所有基線相比,DriveGPT4呈現出優異的結果,展示了其靈活性。
端到端控制
在本節評估了DriveGPT4及其開環控制信號預測的基線,特別關注速度和轉向角。所有方法都需要基于順序輸入來預測下一單個幀的控制信號。
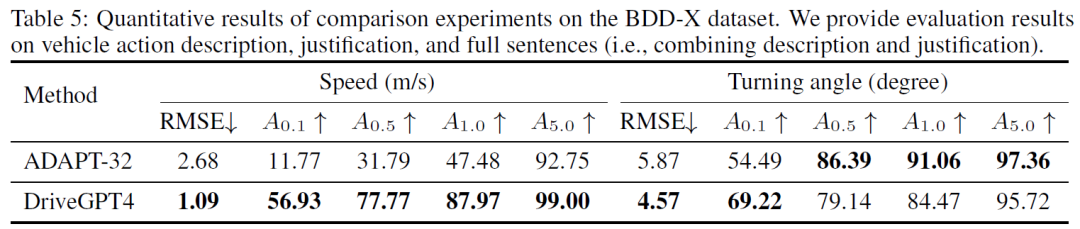
評估指標。繼之前關于控制信號預測的工作之后,我們使用均方根誤差(RMSE)和閾值精度(Aτ)進行評估。τ測量預測誤差低于τ的測試樣本的比例。為了進行全面比較,我們將τ設置為多個值:{0.1,0.5,1.0,5.0}。
定量結果。在去除帶有錯誤控制信號標簽的樣本后,BDD-X測試集中的所有其他樣本用于控制評估。先前最先進的(SOTA)方法ADAPT和DriveGPT4的定量結果如表5所示。DriveGPT4實現了卓越的控制預測結果。
定性結果
我們進一步提供了多種定性結果,便于直觀比較。首先,BDD-X測試集的兩個示例如圖5所示。然后,為了驗證DriveGPT4的泛化能力,我們將DriveGPT4應用于圖6中零樣本會話生成的NuScenes數據集。最后,我們在視頻游戲上嘗試DriveGPT4,以進一步測試其泛化能力。一個例子如圖7所示。


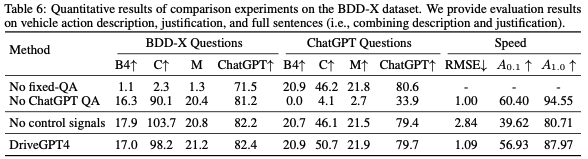
消融實驗
消融實驗如表6所示:
結論
本文介紹了DriveGPT4,一個使用多模態LLM的可解釋的端到端自動駕駛系統。在ChatGPT的幫助下,開發了一個新的自動駕駛解釋數據集,并用于微調DriveGPT4,使其能夠響應人類對車輛的提問。DriveGPT4利用輸入視頻、文本和歷史控制信號來生成對問題的文本響應,并預測車輛操作的控制信號。它在各種任務中都優于基線模型,如車輛動作描述、動作論證、一般問題分析和控制信號預測。此外,DriveGPT4通過零樣本自適應表現出強大的泛化能力。

原文鏈接:https://mp.weixin.qq.com/s/tIuMUdTlp1_R-D06kRO8Qg