













全面的中文大語言模型評測來啦!香港中文大學研究團隊發布
ChatGPT 的一聲號角吹響了2023年全球大語言模型的競賽。
2023年初以來,來自工業界和研究機構的各種大語言模型層出不窮,特別值得一提的是,中文大語言模型也如雨后春筍般,在過去的半年里不斷涌現。
與此同時,和如何訓練大語言模型相比,另一些核心的難題同時出現在學術界和產業界的面前:究竟應該如何理解和評價中文大語言模型的能力?在中文和英文大模型的理解和評測上又應該有什么聯系與區別?
帶著問題的思考,我們發現,近期的一系列中文大模型的評測研究陸續呈現,盡管極大地推進了中文大語言模型理解,但仍然有一些關鍵的研究問題需要關注和討論。
想要準確全面地理解和評測中文大語言模型,這些問題亟須解決:
- 評測數據與指標的選擇需要更加全面。傳統的自動評測工作往往基于數量有限的考試題或部分開源數據集,采用的評測指標大多只關注廣義的準確率。數據的選擇不夠豐富多樣,指標上也忽視了魯棒性、公平性等在模型應用中很重要的其他維度。而人工評測大模型因高昂的人力成本,在數據與指標的選擇上更受制約。
- 不一致的評測過程容易損害評測結果的可比性。提示(prompt)模板、超參數、數據預處理等環節都會對模型最終的結果有直接影響。
- 難以避免的數據污染(data contamination)風險讓評測對比難上加難。隨著訓練語料不斷擴大,模型在訓練過程中見過考試題和開源數據集的可能性也不斷升高。
針對這些挑戰,有研究團隊已經給出了自己的探索與方案。
近日,EMNLP 2023的論文結果公布。來自香港中文大學計算機科學與工程學系的王歷偉助理教授研究團隊的CLEVA: Chinese Language Models EVAluation Platform 被EMNLP 2023 System Demonstrations 錄取。
據CLEVA項目負責人王歷偉教授介紹,CLEVA是其帶領的港中文語言和視覺實驗室(CUHK LaVi Lab)聯合上海人工智能實驗室合作研究的全面的中文大語言模型評測方法。
值得一提的是,CLEVA目前已經被全球前沿的英文大語言模型評測體系-斯坦福大學的HELM 評測體系認可和接入!
目前,用戶已經可以通過斯坦福的HELM評測平臺來調用和測試CLEVA的中文大模型評測。“能得到國際前沿大模型評測研究團隊的認可,是對我們研究工作的極大鼓勵。” LaVi實驗室的同學自豪地說。
CLEVA:全面的中文評測
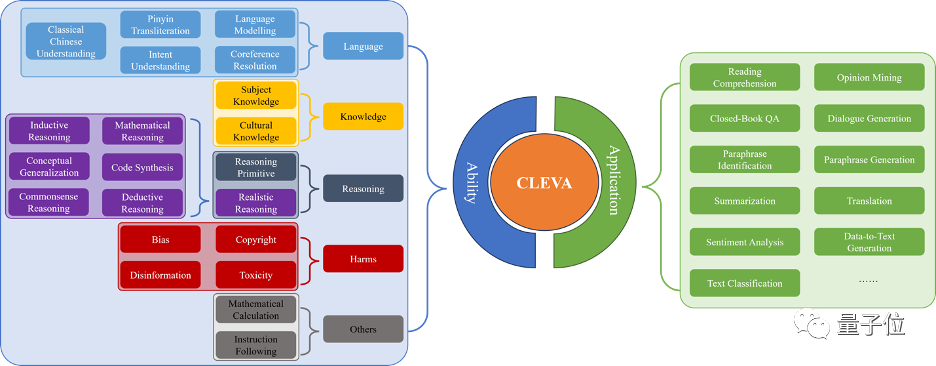
全面的大語言模型評測離不開海量的數據和完整的評測指標。CLEVA目前覆蓋 31個任務(11個應用評估+20個能力評測),囊括目前最多的來自84個數據集的370K個中文測試樣本。中文測試樣本數是過往同類工作最大值的四倍,讓大語言模型在不同任務上的能力都完整地呈現出來。
指標上,CLEVA不僅關注過往評測中大家最在乎的準確性(Accuracy),還借鑒了HELM在英文評測中的做法,針對中文評測設計了魯棒性(Robustness)、公平性(Fairness)、效率(Efficiency)、校準與不確定性(Calibration and Uncertainty)、偏見與刻板印象(Bias and Stereotypes)和毒性(Toxicity)的指標。另外,CLEVA還引入了多樣性(Diversity)和隱私性(Privacy)評測,幫助人們做出綜合的判斷。這對大模型應用至關重要。
標準的評測流程
在使用大模型時,人們經常發現大模型對提示等細節變化不夠魯棒。不同的提示模版會帶來較明顯的差異。過往的大模型評測很多只提供了評測數據,并沒有提供或只提供了一兩個提示模版,而這直接導致不同工作得到的評測結果不直接可比。
CLEVA為每一個評測任務準備了一組多個提示模版。所有模型用同樣一組提示模版進行統一評測,不僅可以更公平比較模型能力,還可以通過不同模版帶來的性能差異分析一個模型對提示模版的敏感程度,指導模型的下游應用。
更可信的評測結果
隨著大模型訓練用的語料越來越龐大,數據污染的風險也與日俱增。數據污染會使模型測試結果不可信,很難公平地體現出模型的能力。如何盡量減輕數據污染的問題,之前的中文評測工作還沒有針對這一問題給出充分的探索和方案。
CLEVA通過多種方法在評測開始之前就主動降低數據污染帶來的風險。從源頭上,33.98%的測試數據是CLEVA新采集構造的。更關鍵的是,CLEVA基于規模最大的中文測試數據,在每輪評測時都會通過不重復采樣得到一個全新的測試集。每一輪測試集在經過多種數據增強策略的調整后,才用來評測大模型,進一步緩解數據污染的風險。
如何進行CLEVA 評測?
CLEVA已經評測了23個目前最有影響力的中文大模型,還會持續用更多的數據和指標,評測更多的模型。對大模型評測感興趣的研究團隊,可以通過CLEVA網站提交和對接評測后續的進展。詳細的教程請參考CLEVA官方網頁或GitHub repo。
對于CLEVA已經具有的評測需求,CLEVA還提供了清晰好用的網絡界面進行操作。用戶可以用可交互的可視化工具,仔細對比不同模型在不同任務和評測指標上的差異。在申請權限后,用戶可以讓自己感興趣的模型通過網絡接口跟CLEVA進行交互,只需按幾次鼠標即可開始一次全面評測,十分便利。
“團隊很努力地做了很久的CLEVA,不僅僅是研究上的理解加深,細節上也在不斷打磨,不斷優化。在此過程中,非常感謝上海人工智能實驗室的合作與支持。” CLEVA 團隊在提起打造這個研究工作的時候,能感覺出來研究積累的力量。
大模型能力的認知和評測需要學術界和工業界的共同關注
筆者也了解到,學術界和工業界對大模型能力評測關注的角度也有一些區別與聯系。
王歷偉教授,在2020年加入香港中文大學任助理教授之前,已經在北美有數年的工業界工作經驗。他也曾作為商湯科技大語言模型“商量SenseChat”的技術總負責人,帶領團隊于2023年4月,發布最早的國內中文大語言模型的代表之一,“商量SenseChat”。

△王歷偉
當他提起學術界和工業界關注大模型評測的角度的區別和聯系的時候,說道:“工業界的大模型會不僅僅關注模型的基本通用能力,還會關注大模型如何服務垂直場景和垂直產業,所以評測能力會更加在場景中具象化;而學校或者研究機構則更適合從基本的模型理解能力、認知能力、通用智能等角度來理解和評測大模型。”
針對大模型評測領域的許多開放問題,王歷偉教授提到,短期內他的港中文研究團隊會持續關注的幾點:
“第一,就是進一步優化解決數據污染的辦法。CLEVA 通過增加新數據和采樣的方式減少數據污染的可能。但是未來應該可以通過新的數據生成范式來構造更多的評測數據。”
“第二,就是目前評測工作還存在很多需要提高的方面,比如應該如何定義推理(reasoning)?應該如何評價推理的過程,而不僅僅是簡單地看推理的結果?再比如,針對什么是智能的理解問題上,應該如何跨學科地合作,來設計新的問題,來檢驗大模型的智能。當然還有很多方面,比如AI 安全問題,如何評價幻覺問題,等等。”
“第三,多模態場景下的涌現能力和純語言學習下有哪些不同?我們有十年左右的vision+language 研究經驗和積累。CUHK LaVi Lab在不斷加強大語言模型和多模態大模型的各個課題研究的同時,也會不斷探索多模態場景下的大模型的能力認知和評測。”
“對大模型能力認知和評測的研究本身,也一定會幫助研究團隊理解和加強持續提高大模型的能力。”




























