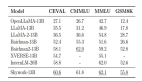
評論能力強于GPT-4,上交開源13B評估大模型Auto-J
隨著生成式人工智能技術的快速發展,確保大模型與人類價值(意圖)對齊(Alignment)已經成為行業的重要挑戰。
雖然模型的對齊至關重要,但目前的評估方法往往存在局限性,這也讓開發者往往困惑:大模型對齊程度如何?這不僅制約了對齊技術的進一步發展,也引發了公眾對技術可靠性的擔憂。
為此,上海交通大學生成式人工智能實驗室迅速響應,推出了一款全新的價值對齊評估工具:Auto-J,旨在為行業和公眾提供更加透明、準確的模型價值對齊評估。

- 論文地址:https://arxiv.org/abs/2310.05470
- 項目地址:https://gair-nlp.github.io/auto-j/
- 代碼地址:https://github.com/GAIR-NLP/auto-j
目前,該項目開源了大量資源,包括:
- Auto-J 的 130 億參數模型(使用方法,訓練和測試數據也已經在 GitHub 上給出);
- 所涉及問詢場景的定義文件;
- 每個場景手工構建的參考評估準則;
- 能夠自動識別用戶問詢所屬場景的分類器等。
該評估器有如下優勢:
1. 功能使用方面
- 支持 50 + 種不同的真實場景的用戶問詢(query)(如常見的廣告創作,起草郵件,作文潤色,代碼生成等)能夠評估各類大模型在廣泛場景下的對齊表現;
- 它能夠無縫切換兩種最常見的評估范式 —— 成對回復比較和單回復評估;并且可以 “一器多用”,既可以做對齊評估也可以做 “獎勵函數”(Reward Model) 對模型性能進一步優化;
- 同時,它也能夠輸出詳細,結構化且易讀的自然語言評論來支持其評估結果,使其更具可解釋性與可靠性,并且便于開發者參與評估過程,迅速發現價值對齊過程中存在的問題。
2. 性能開銷方面
- 在性能和效率上,Auto-J 的評估效果僅次于 GPT-4 而顯著優于包括 ChatGPT 在內的眾多開源或閉源模型,并且在高效的 vllm 推理框架下能每分鐘評估超過 100 個樣本。
- 在開銷上,由于其僅包含 130 億參數,Auto-J 能直接在 32G 的 V100 上進行推理,而經過量化壓縮更是將能在如 3090 這樣的消費級顯卡上部署使用,從而極大降低了 LLM 的評估成本 (目前主流的解決方法是利用閉源大模型(如 GPT-4)進行評估,但這種通過調用 API 的評估方式則需要消耗大量的時間和金錢成本。)

成對回復比較的排行榜結果

評論生成任務的排行榜結果
示例
注:本節提供的示例已由原始英文文本翻譯為中文
下圖例 1 為成對回復比較,紅色字體高亮了顯著區分兩條回復的內容,并且用綠色字體高亮了 Auto-J 給出的評判中與用戶偏好對齊的部分。

下圖例 2 為單回復評估,綠色字體高亮了 Auto-J 給出的評判中切中要點的部分。

具體方法
訓練數據總體上遵循如下的流程示意圖:
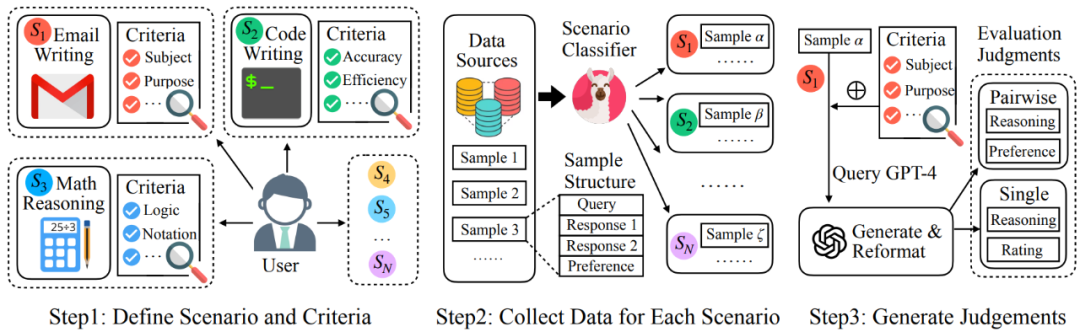
圖1:訓練數據收集流程示意圖
場景的定義和參考評估標準:
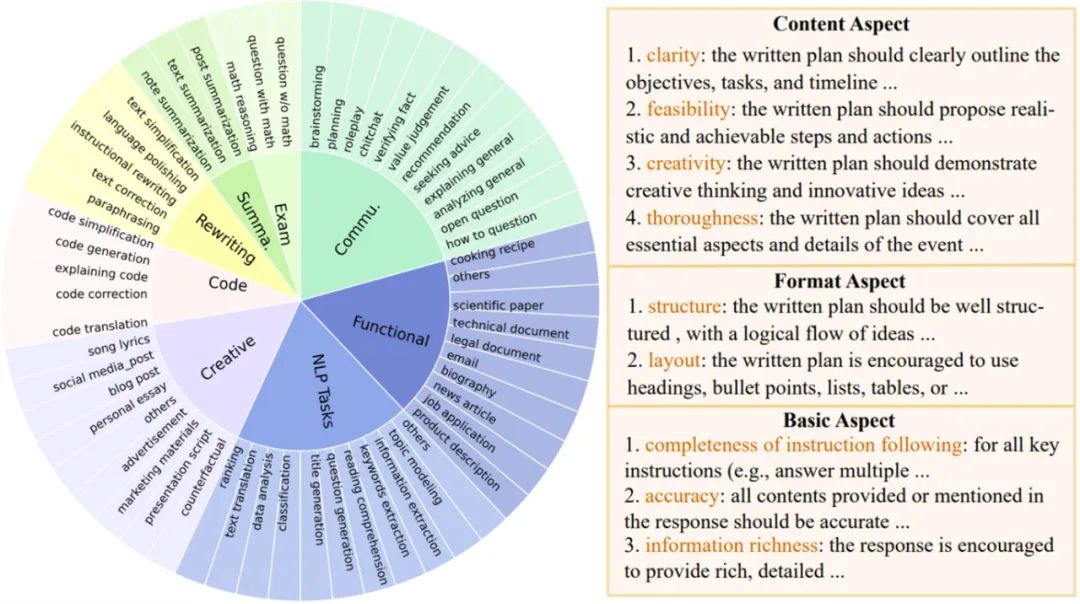
圖 2:場景定義與參考評估標準
為了更廣泛的支持不同的評估場景,Auto-J 定義了 58 種不同的場景,分屬于 8 大類(摘要,重寫,代碼,創作,考題,一般交流,功能性寫作以及其他 NLP 任務)。
對于每個場景,研究者手動編寫了一套用作參考的評估標準(criteria),覆蓋了這類場景下常見的評估角度,其中每條標準包含了名稱和文本描述。評估標準的構建遵循一個兩層的樹狀結構:先定義了若干組通用基礎標準(如文本與代碼的一般標準),而每個場景的具體標準則繼承了一個或多個基礎標準,并額外添加了更多的定制化標準。以上圖的 “規劃”(planning)場景為例,針對這一場景的標準包括了該場景特定的內容與格式標準,以及繼承而來的基礎標準。
收集來自多種場景的用戶問詢和不同模型的回復:
Auto-J 被定位成能夠在定義的多種廣泛場景上均表現良好,因此一個重要的部分就是收集不同場景下相應的數據。為此,研究者手動標注了一定量用戶問詢的場景類別,并以此訓練了一個分類器用以識別任意問詢的所屬場景。在該分類器的幫助下,成功從包含了大量真實用戶問詢和不同的模型回復的若干數據集中(如 Chatbot Arena Conversations 數據集)通過降采樣的方式篩選出了類別更加均衡的 3436 個成對樣本和 960 個單回復樣本作為訓練數據的輸入部分,其中成對樣本包含了一個問詢,兩個不同的針對該問詢的回復,以及人類標注的偏好標簽(哪個回復更好或平局);而單回復樣本則只包含了一個問詢和一個回復。
收集高質量的評判(judgment):
除了問詢和回復,更重要是收集作為訓練數據輸出部分的高質量評估文本,即 “評判”(judgment)。研究者定義一條完整的評判包含了中間的推理過程和最后的評估結果。對于成對回復比較而言,其中間推理過程為識別并對比兩條回復之間的關鍵不同之處,評估結果是選出兩條回復中更好的一個(或平局);而對于單回復樣本,其中間推理過程是針對其不足之處的評論(critique),評估結果則是一個 1-10 的總體打分。
在具體操作上,選擇調用 GPT-4 來生成需要的評判。對于每個樣本,都會將其對應場景的評估標準傳入 GPT-4 中作為生成評判時的參考;此外,這里還觀察到在部分樣本上場景評估標準的加入會限制 GPT-4 發現回復中特殊的不足之處,因此研究者還額外要求其在給定的評估標準之外盡可能地發掘其他的關鍵因素。最終,會將來自上述兩方面的輸出進行融合與重新排版,得到更加全面、具體且易讀的評判,作為訓練數據的輸出部分,其中對于成對回復比較數據,進一步根據已有的人類偏好標注進行了篩選。
訓練:
研究者將來自兩種評估范式的數據合并使用以訓練模型,這使得 Auto-J 僅通過設置相應的提示詞模板即可無縫切換不同的評估范式。另外,還采用了一種類似于上下文蒸餾的(context distillation)技術,在構建訓練序列時刪去了 GPT-4 用以參考的場景評估標準,僅保留了輸出端的監督信號。在實踐中發現這能夠有效增強 Auto-J 的泛化性,避免其輸出的評判僅限制在對評估標準的同義重復上而忽略回復中具體的細節。同時,對于成對回復比較數據部分,還采用了一個簡單的數據增強方式,即交換兩個回復在輸入中出現的順序,并對輸出的評判文本進行相應的重寫,以盡可能消除模型在評估時的位置偏好。
實驗和結果
針對 Auto-J 所支持的多個功能,分別構建了不同的測試基準以驗證其有效性:
在成對回復比較任務上,評估指標為與人類偏好標簽的一致性,以及在交換輸入中兩個回復的順序前后模型預測結果的一致性。可以看到 Auto-J 在兩個指標上均顯著超過了選取的基線模型,僅次于 GPT-4。

表 1 & 圖 3:成對回復比較任務的結果
在單回復評論生成任務上,將 Auto-J 生成的評論與其他模型的評論進行了一對一比較,可以看到不管是基于 GPT-4 的自動比較還是人類給出的判決,Auto-J 所生成的評論都顯著優于大部分基線,且略微優于 GPT-4。

圖 4:Auto-J 在單回復評論生成任務上相比基線的勝率
研究者還探索了 Auto-J 作為獎勵模型(Reward Model)的潛力。在常用的檢測獎勵模型有效性的 Best-of-N 設定下(即基座模型生成多個候選答案,獎勵模型根據自身輸出選擇最佳回復),Auto-J 給出的單回復打分比各類基線模型能選出更好的回復(以 GPT-4 評分為參考)。同時,其打分也顯示了與 GPT-4 打分更高的相關性。

表 2:不同模型作為獎勵模型的表現
最后,開發者也探究了 Auto-J 在系統級別的評估表現。對 AlpacaEval(一個流行的基于GPT-4評估的大模型排行榜)上提交的開源模型使用 Auto-J 的單樣本打分進行了重新排序。可以看到,基于 Auto-J 的排序結果與 GPT-4 的排序結果有極高的相關性。


圖 5 & 表 3:Auto-J 與 GPT-4 對 AlpacaEval 排行榜提交的開源模型排序之間的相關性及具體排名數據
總結和展望
總結來說,GAIR 研究組開發了一個具有 130 億參數的生成式評價模型 Auto-J,用于評估各類模型在解決不同場景用戶問詢下的表現,并旨在解決在普適性、靈活性和可解釋性方面的挑戰。實驗證明其性能顯著優于諸多開源與閉源模型。此外,也公開了模型之外的其他資源,如模型的訓練和多個測試基準中所使用的數據,在構建數據過程中得到的場景定義文件和參考評估標準,以及用以識別各類用戶問詢所屬場景的分類器。