













LeCun和xAI聯創對嗆,GPT-4重大推理缺陷無解?網友:人類也是「隨機鸚鵡」
最近,包括LeCun在內的一眾大佬又開始針對LLM開炮了。最新的突破口是,LLM完全沒有推理能力!
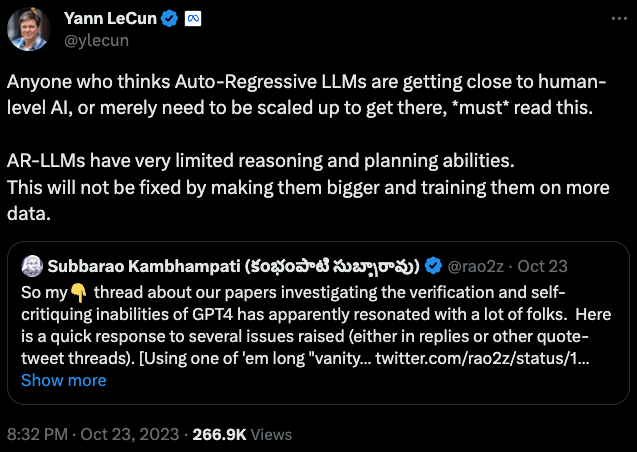
在LeCun看來,推理能力的缺陷幾乎是LLM的「死穴」,無論未來采用多強大的算力,多廣闊和優質的數據集訓練LLM,都無法解決這個問題。
而LeCun拋出的觀點,引發了眾多網友和AI大佬針對這個問題的討論,其中包括xAI的聯合創始人之一Christian Szegedy。
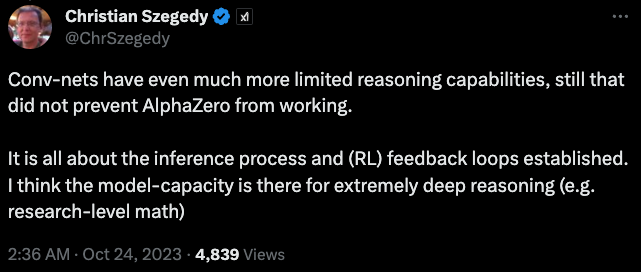
AI科學家Christian Szegedy回復LeCun:
卷積網絡的推理能力更加有限,但這并沒有影響 AlphaZero的能力。
從兩位大佬的進一步討論中,我們甚至能窺探到xAI未來的技術方向——如何利用大模型的能力突破AI的推理能力上限。
而網友們在這個問題之下,對于LLM推理能力的寬容,也展現出了AI與人類智能關系的另一種思考:
人類也不是所有人都擅長推理,難道因為有人不擅長推理,就要否認人類智能的客觀性嗎?
也許人類和LLM一樣,也只是一種不同形式的「隨機鸚鵡」罷了!
大佬對話透露出xAI的技術方向
論文在arXiv上公布后,特別經過LeCun的轉發,引起了網友和學者的廣泛討論。
馬老板牽頭成立的xAI的聯合創始人,AI科學家Christian Szegedy回復到:
卷積網絡的推理能力更加有限,但這并沒有影響 AlphaZero的能力。
關鍵在于推理過程和建立的 (RL) 反饋循環。他認為模型能力可以進行極其深入的推理。(例如進行數學研究)
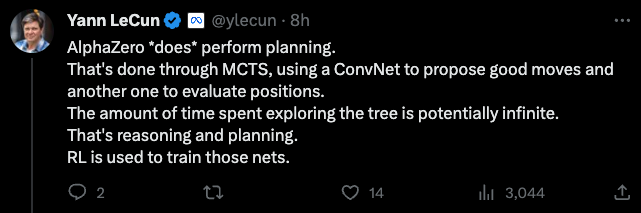
LeCun也直接回復到:
AlphaZero「確實」可以執行規劃。但是通過MCTS完成的,使用卷積網絡提出好的行為,另一個卷積網絡來評估位置。
然而探索這棵樹所花費的時間可能是無限的。這就是推理和計劃。而強化學習是用來訓練這些網絡的。
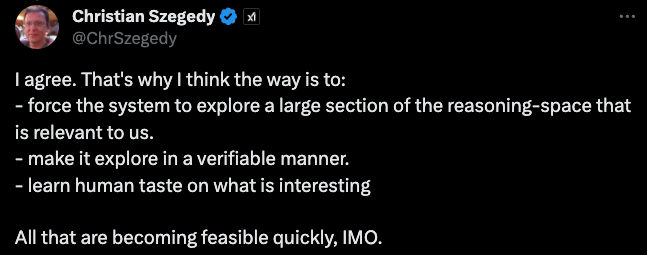
Christian Szegedy繼續回復到:
我同意。所以我認為的方法是:
- 迫使系統探索與我們相關的推理空間的大部分內容。
- 使其以可驗證的方式進行探索。
- 了解人類對有趣事物的品味。
在我看來,所有這些都很快變得可行。
而從xAI聯創嘴里說出來的觀點,加上最后這句:「在我看來,所有這些都很快變得可行」,不由得讓人浮想連篇。
畢竟如此肯定地說「可行」,最直接的原因也許就是「我們已經做出來了。」

也許在不久的將來,我們將能看到xAI抓住LLM推理能力弱的「痛點」,窮追猛打,打造出一個「強推理」的大模型,彌補了像ChatGPT等市面上一干大模型產品的最大缺陷。
LeCun:說多少次了,LLM就是不行!
而LeCun最近批駁LLM推理能力的依據,是ASU大學的教授Subbarao Kambhampati最近的幾篇論文。

個人介紹:https://rakaposhi.eas.asu.edu/
在他看來,在很多能力上號稱達到和超越人類水平的LLM,在推理和規劃能力上有重大缺陷。

論文地址:https://arxiv.org/abs/2310.12397

論文地址:https://arxiv.org/abs/2310.08118
論文地址:https://arxiv.org/abs/2305.15771
在人類專家級的規劃推理難題面前,GPT-4的正確率只有12%。
而且,在推理任務中,如果讓LLM對自己的答案進行自我修正,輸出質量會不增反降。
也就是說,LLM根本沒有能力推理出正確答案,一切只能靠猜。
而教授在論文發表之后,還針對網友和學者對于論文的討論,發了一條長推,進一步闡述了自己的觀點。

教授認為LLM是出色的「創意發生器」,但是無論是在語言還是代碼方面,但它們不能自主規劃或推理。
教授指出,對于LLM的自我糾正能力,學界存在很多誤解。
一些論文的作者過度人格化LLM,誤以為它們能像人類一樣產生錯誤并自我修正。
他批評了使用隨意整理的Q&A數據集來制定和評估自評聲明的做法,認為這種做法在社區中造成了混淆。
教授還指出外部驗證和人類參與的重要性。盡管GPT-4不能驗證顏色配置,但可以幫助生成Python代碼,需要人類修正后可以作為外部驗證器。
同時,與人類和專業推理器合作的模型,也將有助于模型推理能力的提升。
教授列出了一些論文,展示了如何從LLM中提取規劃域模型,通過人類和專用推理器的幫助進行優化,并用于計劃驗證器或獨立域計劃器。
進一步優化LLM的驗證能力也很重要。通過特定的微調來增強LLM的驗證能力,盡管這不會讓LLM突然在推理或驗證方面表現得更好,但可以使自我糾正能力得以小幅改進。
說LLM是「隨機鸚鵡」,難道人類就不是了嗎?
而一位網友同樣也在LeCun的推特下指出,其實規劃和推理對于很多人類來說也不是強項,言下之意,不應該因此否認大語言模型的智能水平。

曾創立了兩個工作社交平臺Glint和Whip的連續創業者Goutham Kurra最近也發表了一篇長博客:「我們都是隨機鸚鵡」,認為LLM背后的能力和人類智能沒有本質的區別。

文章鏈接:https://hyperstellar.substack.com/p/let-me-finish-your-sentences#%C2%A7were-all-stochastic-parrots
如果人類坐下來冥想,并不會意識到自己產生想法的機制到底是如何運作,而且,人類對塑造自己的思想的本質也并不存在有意識的控制。
假設一個人在大熱天外出散步,并且出汗了。這會導致他想到氣候變化,會帶來一些思想中的困擾。
他決定將他的想法轉移到更愉快的主題上,這個過程感覺像是有意識的控制,但該選擇哪個主題去思考呢?
人類的大腦也許會盡職盡責地彈出幾個選項供他參考:也許會考慮晚上晚些時候要玩的游戲,或本周末要參加的音樂會。
但這些新的選擇從何而來?你的大腦是如何決定彈出這些而不是其他東西的?人類是否有意識地了解所有可能選擇的枚舉過程?
當他繼續散步并思考這些事情時,他用眼角的余光注意到一只松鼠跑上樹,就會對它濃密的尾巴感到驚訝。
這時候,人類的「智能思維」又消失了,開始像一只隨機鸚鵡一樣自動思考?
當我們認識到我們對自己的想法實際上是如何形成的知之甚少時,問題是:想法的無意識起源有多隨機?
難道不也是某種程度的「隨機鸚鵡」?我們的敘事生成機制有多像LLM?
以意大利作家Elena Ferrante為例,據報道,她「可能是你從未聽說過的最好的當代小說家」。
她的《我的天才女友》系列已在40個國家售出超過1100萬冊,評論家們紛紛表示:「女性友誼從未被如此生動地呈現出來過。」
她的回憶錄「In the Margins」中描述了自己二戰后在意大利的成長經歷。
與同時代的其他女作家一樣,她出生在男性文學傳統中,閱讀的大部分是男性作家的作品,因此開始模仿男性作家進行寫作。
她在自傳中寫到:
即使在我十三歲左右的年紀……感覺自己的寫作水平還不錯,我也一直感覺有個男性的聲音在告訴我應該寫什么,以及如何寫。
我甚至不知道那個聲音是和我同齡還比我年紀大,也許已經是個老人了。......我想象自己成為男性,但同時仍然是女性。
在自傳中,人類中一位偉大的當代作家,以現代意大利文學的獨特而充滿活力的聲音,坦率地描述了她擺脫「隨機鸚鵡」狀態的努力和掙扎。
因為她的獨有的語言和思想被數百年來形成的男性為主的文學經典所不知不覺地塑造著。
如果我們真正審視自己,我們頭腦中出現的大部分想法都是別人的聲音:我們的父母和老師的聲音。
我們讀的書,我們看的電視,我們的思想建立在非常深厚和粘性的文化基礎之上。
我們的語言、思想和表達能力是我們所閱讀的內容的函數,過去的文字會影響未來。
我們過著與祖先基本相同的生活,重復著昨天的絕大多數相同想法,寫下與其他人相同的文字,差別非常小。
隨便看看好萊塢的電影,讀幾本書,就會發現很多故事幾乎是相同的,只是背景不同而已。
時不時地,人類似乎能夠擺脫鸚鵡學舌的束縛,說出一點原創的想法,思考一點原創的想法。
通過這一點點原創的內容,我們的文化就取得了巨大的飛躍。






























