













GPT-4抽象推理PK人類差距巨大!多模態遠不如純文本,AGI火花難以獨立燃燒
GPT-4,可能是目前最強大的通用語言大模型。一經發布,除了感嘆它在各種任務上的出色表現之外,大家也紛紛提出疑問:GPT-4是AGI嗎?他真的預示了AI取代人類那一天的到來嗎?
推特上也有一眾網友發起了投票:
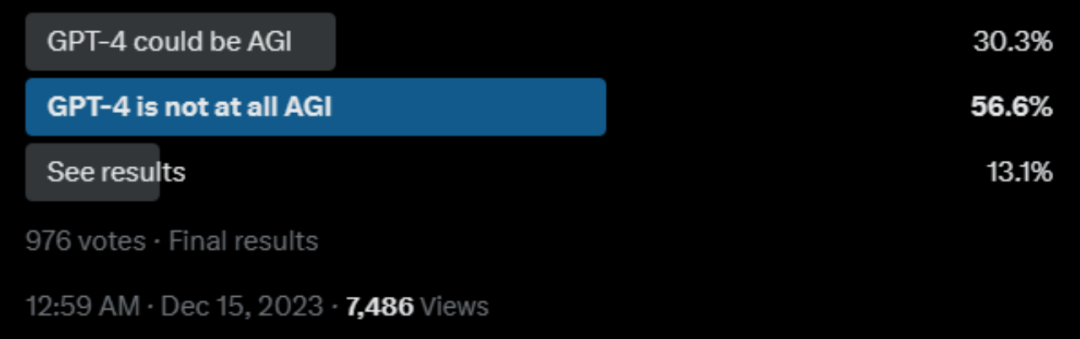
其中,反對的觀點主要在于:
- 有限的推理能力:GPT-4被詬病最多的就是不能執行「反向推理」,而且難以形成對世界的抽象模型進行估計。
- 任務特定的泛化: 雖然GPT-4可以在形式上進行泛化,但在跨任務的目標方面可能會遇到困難。
那到底GPT-4的推理能力和抽象能力和人類相比,有多大的差距,大家的這種感性似乎一直沒有定量的研究作為支撐。
而最近圣達菲研究所的科研人員,系統性地對比了人類和GPT-4在推理和抽象泛化方面的差距。

論文鏈接:https://arxiv.org/abs/2311.09247
研究人員在GPT-4的抽象推理能力方面,通過ConceptARC基準測試評估了GPT-4文本版和多模態版的表現。結果說明,GPT-4仍與人類有較大差距。
ConceptARC是如何測試的?
ConceptARC基于ARC之上,ARC是一組1000個手動創建的類比謎題(任務),每個謎題包含一小部分(通常是2-4個)在網格上進行變換的演示,以及一個「測試輸入」網格。
挑戰者的任務是歸納出演示的基礎抽象規則,并將該規則應用于測試輸入,生成一個經過變換的網格。
如下圖,通過觀察演示的規則,挑戰者需要生成一個新的網格。

ARC設計的目的在于,它強調了捕捉抽象推理的核心:從少量示例中歸納出普遍規律或模式,并能夠靈活地應用于新的、以前未見過的情況;而弱化了語言或學到的符號知識,以避免依賴于先前訓練數據的「近似檢索」和模式匹配,這可能是在基于語言的推理任務上取得表面成功的原因。
而ConceptARC在此基礎上,改進為480個任務,這些任務被組織成特定核心空間和語義概念的系統變化,如Top和Bottom(上和下)、Inside和Outside、Center(里面,外面,中間),以及Same和Different(相同,不同)。每個任務以不同的方式實例化該概念,并具有不同程度的抽象性。
在這種改動下,概念更加抽象,也就是說對人類來說更加容易,結果也更能說明GPT-4和人類在抽象推理方面的能力對比。
測試結果,GPT-4比起人類還有很大差距
研究人員分別對純文本的GPT-4和多模態的GPT-4進行了測試。
對于純文本的GPT-4來說,研究人員使用更加表達豐富的提示對GPT-4的純文本版本進行評估,該提示包括說明和已解決任務的示例,如果GPT-4回答錯誤,會要求它提供不同的答案,最多嘗試三次。
但在不同的溫度設置下(溫度是一個可調節的參數,用于調整生成的文本的多樣性和不確定性。溫度越高,生成的文本更加隨機和多樣,可能包含更多的錯別字和不確定性。),對于完整的480個任務,GPT-4的準確率表現都遠遠不如人類,如下圖所示。

而在多模態實驗中,研究人員對GPT-4V進行了評估,在最簡單的ConceptARC任務的視覺版本上(即僅僅48個任務),給予它與第一組實驗中類似的提示,但使用圖像而不是文本來表示任務。
結果如下圖所示,將極簡的任務作為圖像提供給多模態GPT-4的性能甚至明顯低于僅文本情況。

這不難得出結論,GPT-4,可能是目前最強大的通用LLM,仍然無法穩健地形成抽象并推理關于基本核心概念的內容,而這些概念出現在其訓練數據中之前未見過的上下文中。
網友分析
有位大牛網友對于GPT-4在ConceptARC上的表現,發了足足5條評論。其中一條主要原因解釋道:
基于Transformer的大型語言模型的基準測試犯了一個嚴重錯誤,測試通常通過提供簡短的描述來引導模型產生答案,但實際上這些模型并非僅僅設計用于生成下一個最可能的標記。
如果在引導模型時沒有正確的命題邏輯來引導和鎖定相關概念,模型可能會陷入重新生成訓練數據或提供與邏輯不完全發展或正確錨定的概念相關的最接近答案的錯誤模式。
也就是說,如果大模型設計的解決問題的方式是上圖的話,那實際需要解決問題可能是下圖。


研究人員說,對于提升GPT-4和GPT-4V在抽象推理能力的下一步,可能嘗試通過其他提示或任務表示方法實現。
只能說,對于大模型真的能完全能達到人類水平,還是任重而道遠啊。






























