大模型勇闖洛圣都,加封「GTA五星好市民」!南洋理工、清華等發布視覺可編程智能體Octopus:打游戲、做家務全能干
隨著游戲制作技術的不斷發展,電子游戲已然成為現實世界的模擬舞臺。
以游戲《俠盜獵車手》(GTA)為例,在GTA的世界里,玩家可以以第一人稱視角,在洛圣都(游戲虛擬城市)當中經歷豐富多彩的生活。
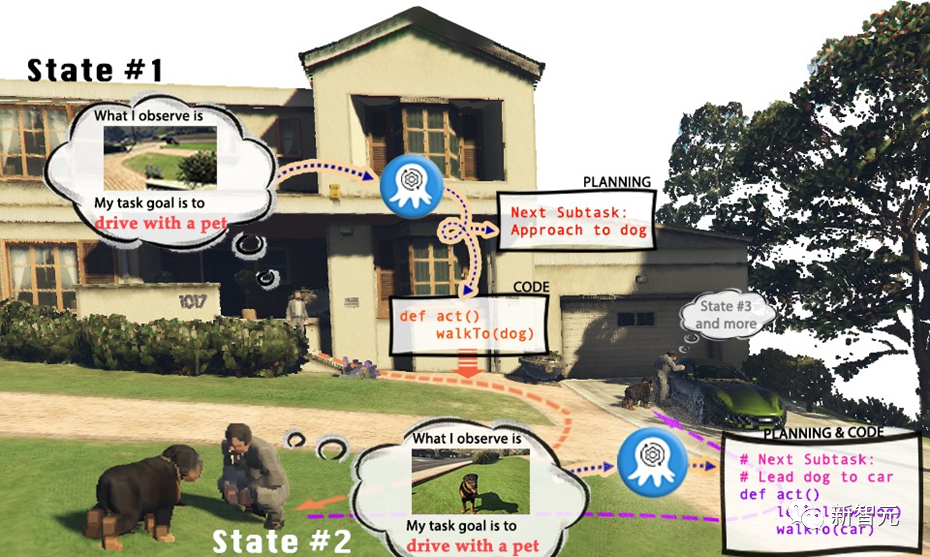
然而,既然人類玩家能夠在洛圣都里盡情遨游完成若干任務,我們是否也能有一個AI視覺模型,操控GTA中的角色,成為執行任務的「玩家」呢?
GTA的AI玩家又是否能夠扮演一個五星好市民,遵守交通規則,幫助警方抓捕罪犯,甚至做個熱心腸的路人,幫助流浪漢找到合適的住所?
目前的視覺-語言模型(VLMs)在多模態感知和推理方面取得了實質性的進步,但它們往往基于較為簡單的視覺問答(VQA)或者視覺標注(Caption)任務。這些任務設定顯然無法使VLM真正完成現實世界當中的任務。
因為實際任務不僅需要對于視覺信息的理解,更需要模型具有規劃推理以及根據實時更新的環境信息做出反饋的能力。同時生成的規劃也需要能夠操縱環境中的實體來真實地完成任務。
盡管已有的語言模型(LLMs)能夠根據所提供的信息進行任務規劃,但其無法理解視覺輸入,極大的限制了語言模型在執行現實世界的具體任務時的應用范圍,尤其是對于一些具身智能任務,基于文本的輸入往往很難詳盡或過于復雜,從而使得語言模型無法從中高效地提取信息從而完成任務。
而當前的語言模型對于程序生成已經進行了若干探索,但是根據視覺輸入來生成結構化,可執行,且穩健的代碼的探索還尚未深入。
為了解決如何使大模型具身智能化的問題,創建能夠準確制定計劃并執行命令的自主和情境感知系統。
來自新加坡南洋理工大學,清華大學等的學者提出了一種基于視覺的可編程智能體Octopus,其目的是通過視覺輸入學習、理解真實世界,并以生成可執行代碼的方式完成各種實際任務。

論文地址:https://arxiv.org/abs/2310.08588
項目網頁:https://choiszt.github.io/Octopus/
開源代碼:https://github.com/dongyh20/Octopus
通過在大量視覺輸入和可執行代碼的數據對的訓練,Octopus學會了如何操控電子游戲的角色完成游戲任務,或者完成復雜的家務活動。
數據采集與訓練
為了訓練能夠完成具身智能化任務的視覺-語言模型,研究者們還開發了OctoVerse,其包含兩個仿真系統用于為Octopus的訓練提供訓練數據以及測試環境。
這兩個仿真環境為VLM的具身智能化提供了可用的訓練以及測試場景,對模型的推理和任務規劃能力都提出了更高的要求。具體如下:
1. OctoGibson:
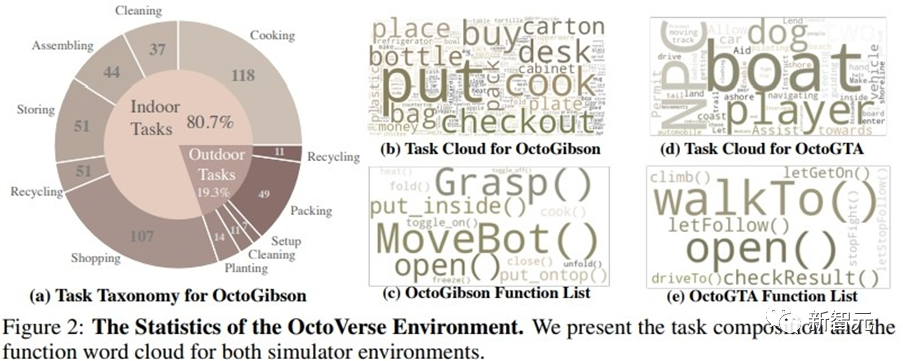
基于斯坦福大學開發的OmniGibson進行開發,一共包括了476個符合現實生活的家務活動。整個仿真環境中包括16種不同類別的家庭場景,涵蓋155個實際的家庭環境實例。模型可以操作其中存在的大量可交互物體來完成最終的任務。
2. OctoGTA:
基于《俠盜獵車手》(GTA)游戲進行開發,一共構建了20個任務并將其泛化到五個不同的場景當中。通過預先設定好的程序將玩家設定在固定的位置,提供完成任務必須的物品和NPC,以保證任務能夠順利進行。
下圖展示了OctoGibson的任務分類以及OctoGibson和OctoGTA的一些統計結果。
為了在構建的兩個仿真環境中高效的收集訓練數據,研究者構建了一套完整的數據收集系統。
通過引入GPT-4作為任務的執行者,研究者們使用預先實現的函數將在仿真環境當中采集到的視覺輸入處理為文本信息提供給GPT-4,在GPT-4返回當前一步的任務規劃和可執行代碼后,再在仿真環境當中執行代碼,并判斷當前一步的任務是否完成。
如果成功,則繼續采集下一步的視覺輸入;如果失敗,則回到上一步的起始位置,重新采集數據。

上圖以OctoGibson環境當中的Cook a Bacon任務為例,展示了收集數據的完整流程。
需要指出的是,在收集數據的過程中,研究者不僅記錄了任務執行過程中的視覺信息,GPT-4返回的可執行代碼等,還記錄了每一個子任務的成功情況,這些將作為后續引入強化學習來構建更高效的VLM的基礎。
GPT-4的功能雖然強大,但并非無懈可擊,錯誤可以以多種方式顯現,包括語法錯誤和模擬器中的物理挑戰。
例如,如圖3所示,在狀態#5和#6之間,由于agent拿著的培根與平底鍋之間的距離過遠,導致「把培根放到平底鍋」的行動失敗,此類挫折會將任務重置到之前的狀態。
如果一個任務在10個步驟之后仍未完成,則被認定為不成功,我們會因預算問題而終止這個任務,而這個任務的所有子任務的數據對都會認為執行失敗。

在收集一定規模的訓練數據后,研究者利用這些數據訓練出了一個具身智能化的視覺-語言模型Octopus,上圖展現了完整的數據采集和訓練流程。
在第一階段,通過使用采集的數據進行監督式微調,研究者構建出了一個能夠以視覺信息作為輸入,遵從固定格式進行輸出的VLM模型。在這一階段,模型能夠完成視覺輸入信息到任務計劃以及可執行代碼的映射。
在第二階段,研究者引入了RLEF(Reinforcement Learning with Environmental Feedback),通過利用先前采集的子任務的成功情況作為獎勵信號,采用強化學習的算法更進一步的提升VLM的任務規劃能力,從而提高整體任務的成功率。
實驗結果
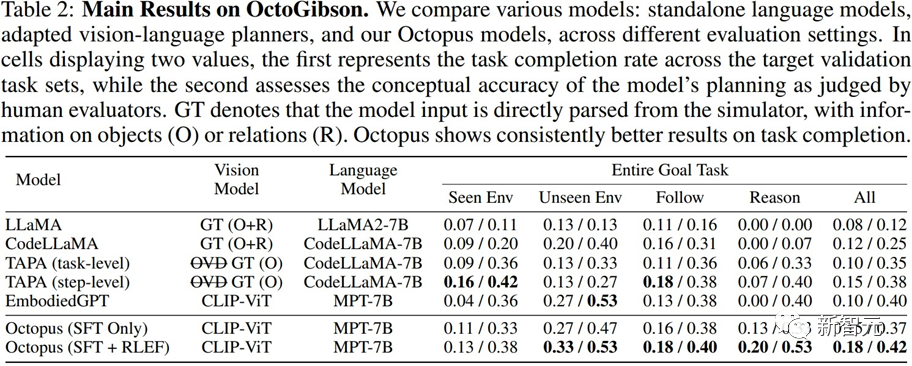
研究者在構建的OctoGibson環境中,對于當前主流的VLM和LLM進行了測試,下表展示了主要實驗結果。
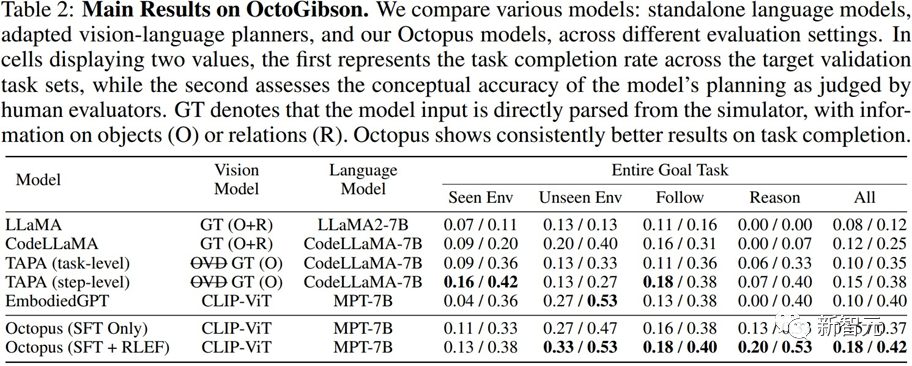
對于不同的測試模型,Vision Model列舉了不同模型所使用的視覺模型,對于LLM來說,研究者將視覺信息處理為文本作為LLM的輸入,其中O代表提供了場景中可交互物體的信息,R代表提供了場景中物體相對關系的信息,GT代表使用真實準確的信息,而不引入額外的視覺模型來進行檢測。
對于所有的測試任務,研究者報告了完整的測試集成功率,并進一步將其分為四個類別,分別記錄在訓練集中存在的場景中完成新任務,在訓練集中不存在的場景中完成新任務的泛化能力,以及對于簡單的跟隨任務以及復雜的推理任務的泛化能力。
對于每一種類別的統計,研究者報告了兩種評價指標,其中第一個為任務的完成率,以衡量模型完成具身智能任務的成功率;第二個為任務規劃準確率,用于體現模型進行任務規劃的能力。
此外,研究者還展示了不同模型對于OctoGibson仿真環境中采集的視覺數據的響應實例。下圖展示了TAPA+CodeLLaMA,Octopus以及GPT-4V對于OctoGibson當中視覺輸入生成的回復。
可以看到,相較于TAPA+CodeLLaMA以及只進行了監督式微調的Octopus模型,使用RLEF進行訓練之后的Octopus模型的任務規劃更加合理,即使是對于較為模糊的任務指令(find a carboy)也能提供更加完善的計劃,這些表現都更進一步說明了RLEF訓練策略對于提升模型的任務規劃能力以及推理能力的有效性。

總體來說,現有的模型在仿真環境中表現出的實際任務完成度和任務規劃能力依舊有很大的提升空間。研究者們總結了一些較為關鍵的發現:
1. CodeLLaMA能夠提升模型的代碼生成能力,但不能提升任務規劃能力。
研究者指出,通過實驗結果可以看出,CodeLLaMA能夠顯著的提升模型的代碼生成能力。
然而,盡管一些模型使用了CodeLLaMA進行代碼生成,但整體任務的成功率依然會受到自身任務規劃能力的限制。
而反觀Octopus,盡管未使用CodeLLaMA,代碼的可執行率有所下降,但得益于其強大的任務規劃能力,整體任務成功率依舊優于其他模型。
2. LLM在面對大量的文本信息輸入時,處理較為困難。
在實際的測試過程中,研究者通過對比TAPA和CodeLLaMA的實驗結果得出了一個結論,即語言模型很難較好地處理長文本輸入。
研究者們遵從TAPA的方法,使用真實的物體信息來進行任務規劃,而CodeLLaMA使用物體和物體之間的相對位置關系,以期提供較為完整的信息。
但在實驗過程中,研究者發現由于環境當中存在大量的冗余信息,因此當環境較為復雜時,文本輸入顯著增加,LLM難以從大量的冗余信息當中提取有價值的線索,從而降低了任務的成功率。
這也體現了LLM的局限性,即如果使用文本信息來表示復雜的場景,將會產生大量冗余且無價值的輸入信息。
3. Octopus表現出了較好的任務泛化能力。
通過實驗結果可以得出,Octopus具有較強的任務泛化能力,其在訓練集當中未出現的新場景中完成任務的成功率和任務規劃的成功率均優于已有的模型,也展現出了視覺-語言模型的一些內在優勢,針對同一類別的任務,其泛化性優于傳統的LLM。
4. RLEF能夠增強模型的任務規劃能力。
在實驗結果中,研究者們提供了只經過第一階段監督式微調的模型以及經過RLEF訓練之后模型的性能比。
可以看出,在經過RLEF訓練之后,模型在需要較強的推理能力和任務規劃能力的任務上,整體成功率和規劃能力有了顯著提升。
與已有的VLM訓練策略相比,RLEF也更加的高效。上圖所展示的示例也能夠體現RLEF訓練之后模型在任務規劃能力上的提升,經過RLEF訓練之后的模型能夠懂得在面對較為復雜的任務時,如何在環境當中進行探索;
此外,模型在任務規劃上能夠更加遵從仿真環境中的實際要求(如,模型需要先移動到要交互的物體,才能開始交互),從而降低任務規劃的失敗比率。
討論
消融實驗
在對模型的實際能力進行評估之后,研究者們更進一步探究了一些影響模型性能的可能因素。如下圖所示,研究者從三個方面開展了實驗。

1. 訓練參數的比重
研究者對比了只訓練視覺模型與語言模型的連接層,訓練連接層和語言模型,以及完整訓練的模型的性能。
可以看出,隨著訓練參數的增加,模型的性能逐漸獲得了提升。這說明,訓練參數的多少對于模型是否能夠在一些固定的場景當中完成任務至關重要。
2. 模型的大小
研究者們比較了較小的3B參數模型與基線7B模型在兩個訓練階段的性能差異。通過比較可以看出,當模型整體參數量較大時,模型的性能也會得到明顯的提升。
如何選定合適的模型訓練參數,使得模型能夠擁有完成對應任務的能力,同時也能夠保證模型的輕量化和較快的推理速度,將是未來VLM領域研究中較為關鍵的一點。
3. 視覺輸入的連續性
為了探究不同的視覺輸入對于實際VLM性能的影響,研究者對視覺信息的輸入順序進行了實驗。
在測試的過程中,模型會在仿真環境當中順序轉動,采集第一視角圖像,并采集兩張鳥瞰圖,之后這些視覺圖像會按順序輸入VLM當中。
而在實驗中,當研究者隨機打亂視覺圖像順序再輸入VLM中時,VLM產生了較大的性能損失。
這一方面說明了完整且結構化的視覺信息對于VLM的重要性,另一方面也從某種程度上反映了VLM在對視覺輸入進行響應時需要依靠視覺圖像的內在聯系,而一旦這種視覺上的聯系被破壞,將會極大的影響VLM的表現。
GPT-4 & GPT-4V(ision)
此外,研究者還對GPT-4以及GPT-4V在仿真環境當中的性能進行了測試和統計。
1. GPT-4
針對GPT-4,在測試過程中研究者提供與使用其采集訓練數據時完全相同的文本信息作為輸入。在測試任務上,GPT-4能夠完成一半的任務,這一方面說明現有的VLM相對于GPT-4這樣的語言模型,從性能上還有很大的提升空間;
另一方面也說明,即使是GPT-4這樣性能較強的語言模型,在面對具身智能任務時,其任務規劃能力和任務執行能力依然需要更進一步的提升。
2. GPT-4V
由于GPT-4V剛剛發布可以直接調用的API,研究者還沒來得及嘗試,但是研究者們之前也手動測試了一些實例來展現GPT-4V的性能。
通過一些示例,研究者認為GPT-4V對于仿真環境當中的任務具有較強的零樣本泛化能力,也能夠根據視覺輸入生成對應的可執行的代碼,但其在一些任務規劃上稍遜色于在仿真環境采集的數據上微調之后的模型。
局限性
研究者們指出了目前工作的一些局限性。
1. 當前的Octopus模型在較為復雜的任務上性能并不令人滿意。在面對復雜任務時,Octopus往往會做出錯誤的規劃,并且嚴重依賴于環境給出的反饋信息,最終往往難以完成整體的任務。
2. Octopus模型僅在仿真環境當中進行訓練,而如何將其遷移到真實世界當中將會面臨一系列的問題。例如,真實環境當中模型將難以得到較為準確的物體相對位置信息,如何構建起物體對于場景的理解將變得更加困難
3. Octopus目前的視覺輸入為離散的靜態圖片,如何使其能夠處理連續的視頻將是未來的挑戰。
連續的視頻可以更進一步提高模型完成任務的性能,但如何高效地處理和理解連續視覺輸入將成為進一步提升VLM性能的關鍵。