













田淵棟給OpenAI神秘Q*項目潑冷水:合成數據不是AGI救星,能力僅限簡單數學題
Q*猜想,持續在AI社區火爆。
大家都在猜測,Q*是否就是「Q-learning + A*」。
AI大牛田淵棟也詳細分析了一番,「Q*=Q-learning+A*」的假設,究竟有多大可能性。
與此同時,越來越多人給出判斷:合成數據,就是LLM的未來。
不過,田淵棟對這種說法潑了冷水。
我部分不同意「AGI只需通過放大合成數據就能解決」的說法。
搜索之所以強大,是因為如果環境設計得當,它將創造出無限多的新模式供模型學習和適應。
然而,學習這樣的新模式是否需要數十億的數據,仍是一個未決問題,這可能表明,我們的架構/學習范式存在一些根本性缺陷。
相比之下,人類往往更容易通過「啊哈」時刻,來發現新的范式。

而英偉達高級科學家Jim Fan也對此表示同意:合成數據將發揮重要作用,但僅僅是通過盲目擴展,并不足以達到 AGI。

Q*=Q-learning+A,有多大可能
田淵棟表示,根據自己過去在 OpenGo(AlphaZero 的再現)上的經驗,A* 可被視為只帶有值(即啟發式)函數Q的確定性MCTS版本。

A*很適用于這樣的任務:給定行動后,狀態很容易評估;但給定狀態后,行動卻很難預測。符合這種情況的一個典型例子,就是數學問題。
相比之下,圍棋卻是另一番景象:下一步候選棋相對容易預測(只需通過檢查局部形狀),但要評估棋盤形勢,就棘手得多。
這就是為什么我們也有相當強大的圍棋機器人,但它們只利用了策略網絡。
對于LLM,使用 Q(s,a)可能會有額外的優勢,因為評估 Q(s,a) 可能只需要預填充,而預測策略a = pi(s) ,則需要自回歸采樣,這就要慢得多。另外,在只使用解碼器的情況下,s的KV緩存可以在多個操作中共享。
傳說中的Q*,已經在解決數學問題上有了重大飛躍,這種可能性又有多大呢?
田淵棟表示,自己是這樣猜測的:因為解決的入門級數學問題,所以值函數設置起來應該相對容易一些(例如,可以從自然語言形式的目標規范中預測)。
如果想要解決困難的數學問題,卻不知道如何該怎么做,那么這種方法可能還不夠。

LeCun轉發了田淵棟的討論,對他的觀點表示贊同——「他解釋了A*(在圖形中搜索最短路徑)和MCTS(在指數增長的樹中搜索)之間適用性的差異。」

對于LeCun的轉發,田淵棟表示,自己一直在做許多不同的事情,包括規劃、理解Transformers/LLM和高效的優化技術,希望能把這些技術都結合起來。
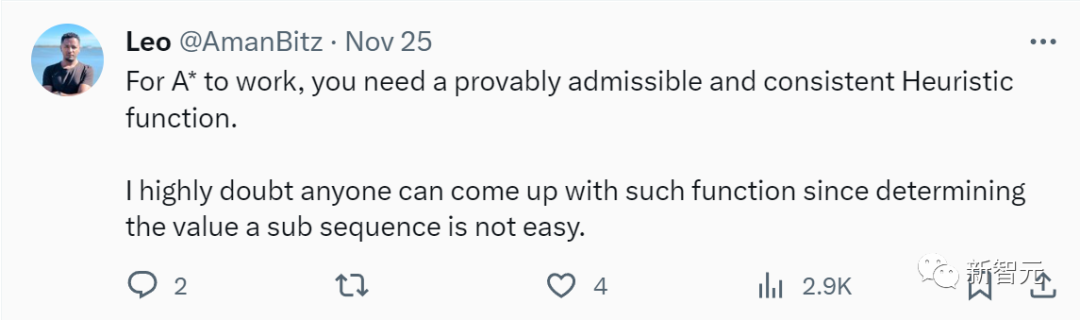
有網友表示懷疑稱,「要使A*有效,就需要一個可證明的、可接受且一致的啟發式函數。但我非常懷疑能有人想出這樣的函數,因為確定子序列的值并不容易。」

即使做出的是小學數學題,Q*也被寄予厚望
對大模型稍微有些了解的人都知道,如果擁有解決基本數學問題的能力,就意味著模型的能力取得了重大飛躍。
這是因為,大模型很難在訓練的數據之外進行泛化。
AI訓練初創公司Tromero的聯合創始人Charles Higgins表示,現在困擾大模型的關鍵按難題,就是怎樣對抽象概念進行邏輯推理,如果實現了這一步,就是毫無疑問的重大飛躍。
數學是關于符號推理的學問,比如,如果X比Y大,Y比Z大,那么X就比Z大。

如果Q*的確就是Q-learning+A*,這就表明,OpenAI的全新模型可以將支持ChatGPT的深度學習技術與人類編程的規則相結合。而這種方法,可以幫助解決LLM的幻覺難題。
Tromero聯創Sophia Kalanovska表示,這具有非常重要的象征意義,但在實踐層面上,它不太可能會終結世界。
那為什么坊間會有「Q*已現AGI雛形」的說法傳出呢?
Kalanovska認為,從目前傳出的說法看來,Q*能夠結合大腦的兩側,既能從經驗中了解一些事情,還能同時推理事實。
顯然,這就離我們公認的智能又近了一步,因為Q*很可能讓大模型有了新的想法,而這是ChatGPT做不到的。
現有模型的最大限制,就是僅能從訓練數據中反芻信息,而不能推理和發展新的想法。
解決看不見的問題,就是創建AGI的關鍵一步。
薩里人類中心AI研究所的所長Andrew Rogoyski表示,現在已有的大模型,都可以做本科水平的數學題,但一旦遇到更高級的數學題,它們就全部折戟了。
但如果LLM真的能夠解決全新的、看不見的問題,這就是一件大事,即使做出的數學題是相對簡單的。
合成數據是未來LLM的關鍵?
所以,合成數據是王道嗎?
Q*的爆火引起一眾大佬的猜想,而對于傳聞中「巨大的計算資源,使新模型能夠解決某些數學問題」,大佬們猜測這重要的一步有可能是RLAIF(來自 AI 反饋的強化學習)。
RLAIF是一種由現成的 LLM 代替人類標記偏好的技術,通過自動化人工反饋,使針對LLM的對齊操作更具可擴展性。

之前在LLM訓練中大放異彩的RLHF(基于人類反饋的強化學習) 可以有效地將大型語言模型與人類偏好對齊,但收集高質量的人類偏好標簽是一個關鍵瓶頸。

于是Anthropic、Google等公司已經嘗試轉向RLAIF,使用AI來代替人類完成反饋訓練的過程。
這也就意味著,合成數據才是王道,并且使用樹形結構為以后提供越來越多的選擇,以得出正確的答案。
不久前Jim Fan就在推特上表示,合成數據將提供下一萬億個高質量的訓練數據。

「我敢打賭,大多數嚴肅的LLM小組都知道這一點。關鍵問題是如何保持質量并避免過早停滯不前。」
Jim Fan還引用了Richard S. Sutton的文章《The Bitter Lesson》,來說明,人工智能的發展只有兩種范式可以通過計算無限擴展:學習和搜索。
「在撰寫這篇文章的2019 年是正確的,而今天也是如此,我敢打賭,直到我們解決 AGI 的那一天。」
Richard S. Sutton是加拿大皇家學會和英國皇家學會的院士,他被認為是現代計算強化學習的創始人之一,對該領域做出了多項重大貢獻,包括時間差異學習和策略梯度方法。

在這篇文章中,Sutton主要表達了這樣幾個觀點:
利用計算的通用方法最終是最有效的,而且效率很高。但有效的原因在于摩爾定律,更確切地說是由于每單位計算成本持續呈指數下降。
最初,研究人員努力通過利用人類知識或游戲的特殊功能來避免搜索,而一旦搜索得到大規模有效應用,所有這些努力都會顯得無關緊要。
統計方法再次戰勝了基于人類知識的方法,這導致了整個自然語言處理領域的重大變化,幾十年來,統計和計算逐漸成為了主導。
人工智能研究人員經常試圖將知識構建到系統中,這在短期內是有幫助的,但從長遠來看,有可能會阻礙進一步的進展。
突破性的進展最終將通過基于搜索和學習的方法來實現。
心靈的實際內容是極其復雜的,我們應該停止嘗試尋找簡單的方法來表示思想,相反,我們應該只構建可以找到并捕獲這種任意復雜性的元方法。
——所以,看起來Q*似乎抓住了問題的關鍵(搜索和學習),而合成數據將進一步使它突破以往的限制,達成自己的飛躍。
對于合成數據,馬斯克也表示人類確實打不過機器。
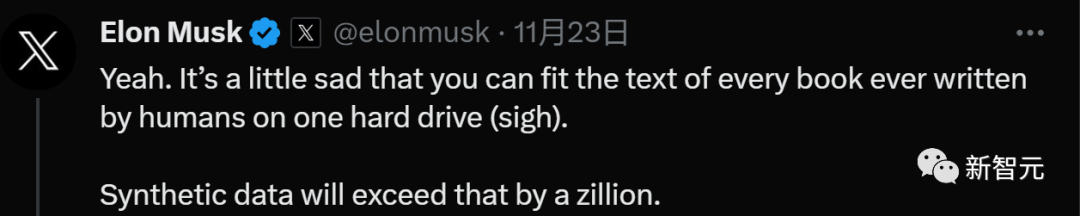
「你可以把人類寫的每本書的文字都放在一個硬盤上(嘆氣),而合成數據將遠遠超過這些。」
對此,Jim Fan與馬斯克互動說,

「如果我們能大規模模擬它們,大量的合成數據將來自具身智能體,例如Tesla Optimus。」
Jim Fan認為 RLAIF 或者來自 groundtruth 反饋的 RLAIF 如果正確擴展將有很長的路要走。此外,合成數據還包括模擬器,原則上可以幫助LLM開發世界模型。

「理想情況下是無限的。但令人擔憂的是,如果自我提升循環不夠有效,就有可能會停滯不前。」
對于兩人的一唱一和,LeCun表示有話要說:
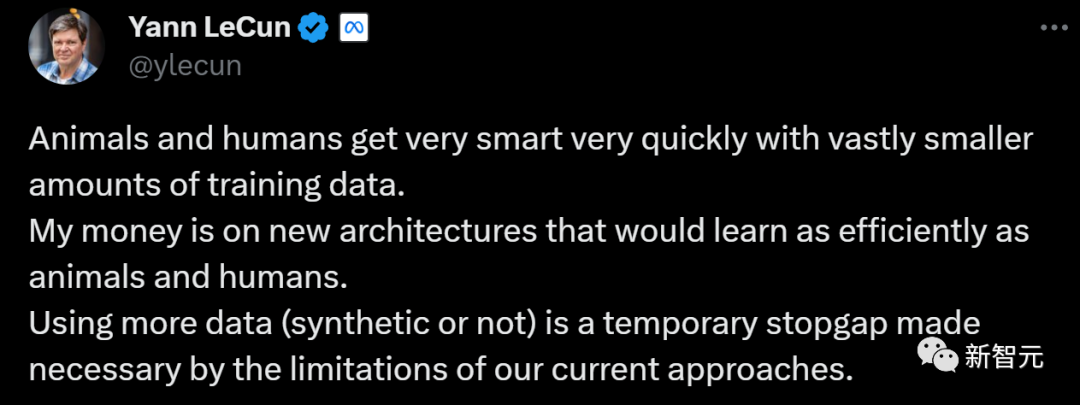
LeCun認為,動物和人類在訓練數據量極少的情況下,很快就變得非常聰明。
所以,使用更多的數據(合成或非合成)是一種暫時的權宜之計,只是因為我們目前的方法有局限性。
對此,支持「大數據派」的網友表示不服:

「難道不應該是數百萬年的進化適應類似于預訓練,而我們一生的經驗類似于持續的微調嗎?」
LeCun于是給出一個例子作為解釋,人類用于承接幾百萬年進化成果的手段只有基因,而人類基因組中的數據量很小,只有800MB。

連一個小型的 7B LLM 都需要 14GB的存儲空間,相比之下,人類基因中確實沒有太多的數據。
另外,黑猩猩和人類基因組之間的差異約為1%(8MB)。這一點點差別完全不足以解釋人與黑猩猩之間能力的差異。
而說到后天學習的數據量,一個 2 歲的孩子看到的視覺數據總量是非常小的, 他所有的學習時間約 3200 萬秒(2x365x12x3600)。
人類有 200 萬根光神經纖維,每根神經纖維每秒傳輸大約 10 個字節。——這樣算下來總共有 6E14 個字節。
相比之下,LLM 訓練的數據量通常為 1E13 個token,約為 2E13 個字節。——所以2歲孩子獲得的數據量只相當于LLM的 30 倍。
不論大佬們的爭論如何,大型科技公司如Google、Anthropic、Cohere 等正在通過過程監督或類似 RLAIF 的方法創建預訓練大小的數據集,為此耗費了巨大的資源。
所以大家都清楚,合成數據是擴大數據集的捷徑。在短期內,我們顯然可以利用它創建一些有用的數據。
只是這是否就是通往未來的道路?只能等待時間來告訴我們答案。
























