













AI研究也能借鑒印象派?這些栩栩如生的人竟然是3D模型

在 19 世紀,印象主義的藝術(shù)運動在繪畫、雕塑、版畫等藝術(shù)領(lǐng)域盛行,其特點是以「短小的、斷斷續(xù)續(xù)的筆觸,幾乎不傳達形式」為特征,就是后來的印象派。簡單來說印象派筆觸未經(jīng)修飾而顯見,不追求形式的精準,模糊的也合理,其將光與色的科學觀念引入到繪畫之中,革新了傳統(tǒng)固有色觀念。
在 D3GA 中,作者的目標反其道而行之,是希望創(chuàng)建像照片般逼真的表現(xiàn)。在 D3GA 中,作者對高斯?jié)姙R(Gaussian Splatting)進行創(chuàng)造性的運用,作為現(xiàn)代版的「段筆觸」,來創(chuàng)造實時穩(wěn)定的虛擬角色的結(jié)構(gòu)和外觀。

印象派畫家莫奈代表作《日出?印象》。

對于虛擬形象的構(gòu)建工作來說,創(chuàng)造驅(qū)動型(即可以生成動畫新內(nèi)容)的逼真人類形象目前需要密集的多視角數(shù)據(jù),因為單目方法缺乏準確性。此外,現(xiàn)有的技術(shù)依賴于復雜的預處理,包括精確的 3D 配準。然而,獲取這些配準需要迭代,很難集成到端到端的流程中去。而其它不需要準確配準的方法基于神經(jīng)輻射場(NeRFs),通常對于實時渲染來說太慢,或者在服裝動畫方面存在困難。
Kerbl 等人在經(jīng)典 Surface Splatting 渲染方法基礎上引入了 3D Gaussian Splatting(3DGS)。與基于神經(jīng)輻射場的最先進方法相比,這種方法在更快的幀率下呈現(xiàn)更高質(zhì)量的圖像,并且不需要任何高度準確的 3D 初始化。
但是,3DGS 是為靜態(tài)場景設計的。并且已經(jīng)有人提出基于時間條件的 Gaussian Splatting 可用來渲染動態(tài)場景,這些模型只能回放先前觀察到的內(nèi)容,所以不適用于表達新的或其未曾見過的運動。
在驅(qū)動型的神經(jīng)輻射場的基礎上,作者對 3D 的人類的外觀及變形進行建模,將其放置在一個規(guī)范化的空間中,但使用 3D 高斯而不是輻射場。除性能更好以外,Gaussian Splatting 還不需要使用相機射線采樣啟發(fā)式方法。
剩下的問題是定義觸發(fā)這些 cage 變形的信號。目前在驅(qū)動型的虛擬角色中的最新技術(shù)需要密集的輸入信號,如 RGB-D 圖像甚至是多攝像頭,但這些方法可能不適用于傳輸帶寬比較低的情況。在本研究中,作者采用基于人體姿勢的更緊湊輸入,包括以四元數(shù)形式的骨骼關(guān)節(jié)角度和 3D 面部關(guān)鍵點。
通過在九個高質(zhì)量的多視圖序列上訓練個體特定的模型,涵蓋各種身體形狀、動作和服裝(不僅限于貼身服裝),以后我們就可以通過任何主體的新姿勢對人物形象進行驅(qū)動了。
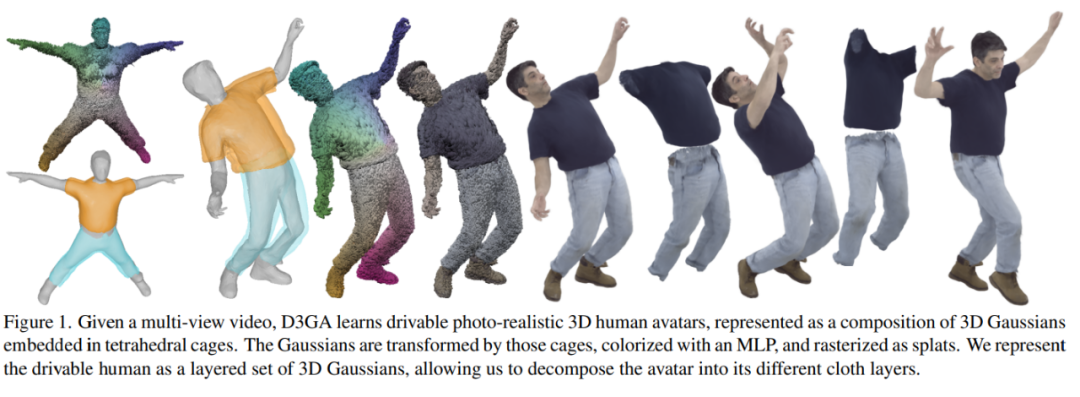

方法概覽

- 論文鏈接:https://arxiv.org/pdf/2311.08581.pdf
- 項目鏈接:https://zielon.github.io/d3ga/
目前用于動態(tài)體積化虛擬角色的方法要么將點從變形空間映射到規(guī)范空間,要么僅依賴正向映射。基于反向映射的方法往往在規(guī)范空間中會累積誤差,因為它們需要一個容易出錯的反向傳遞,并且在建模視角相關(guān)效果時存在問題。
因此,作者決定采用僅正向映射的方法。D3GA 是基于 3DGS 的基礎上通過神經(jīng)表示和 cage 進行擴展,分別對虛擬角色的每個動態(tài)部分的顏色和幾何形狀進行建模。
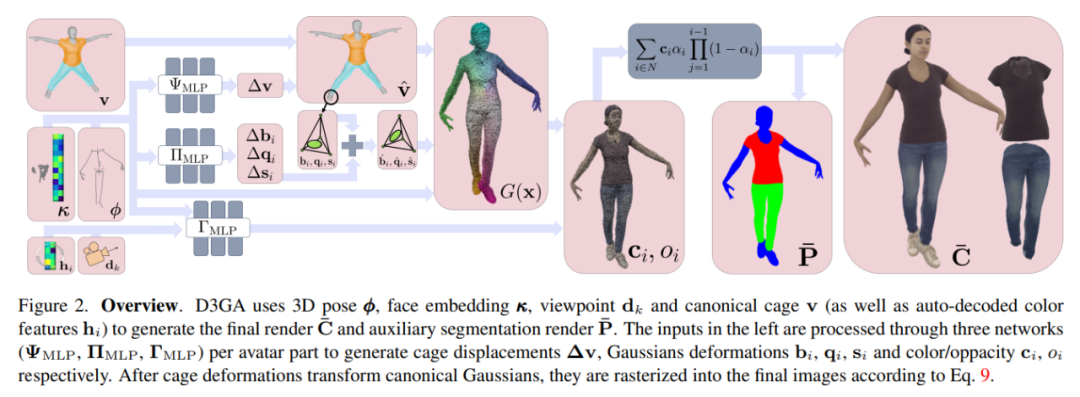
D3GA 使用 3D 姿勢 ?、面部嵌入 κ、視點 dk 和規(guī)范 cage v(以及自動解碼的顏色特征 hi)來生成最終的渲染 Cˉ 和輔助分割渲染 Pˉ。左側(cè)的輸入通過每個虛擬角色部分的三個網(wǎng)絡(ΨMLP、ΠMLP、ΓMLP)進行處理,以生成 cage 位移?v、高斯變形 bi、qi、si 以及顏色 / 透明度 ci、oi。
在 cage 變形將規(guī)范高斯變形后,通過方程式 9,它們被光柵化成最終的圖像。

實驗結(jié)果
D3GA 在 SSIM、PSNR 和感知度量 LPIPS 等指標上進行評估。表 1 顯示,D3GA 在只使用 LBS 的方法中(即不需要為每個幀掃描 3D 數(shù)據(jù))其在 PSNR 和 SSIM 上的表現(xiàn)是最佳的,并在這些指標中勝過所有 FFD 方法,僅次于 BD FFD,盡管其訓練信號較差且沒有測試圖像(DVA 是使用所有 200 臺攝像機進行測試的)。

定性比較顯示,與其它最先進方法相比,D3GA 能更好地建模服裝,特別是像裙子或運動褲這樣的寬松服裝 (圖 4)。FFD 代表自由形變網(wǎng)格,其包含比 LBS 網(wǎng)格更豐富的訓練信號 (圖 9)。


與其基于體積方法相比,作者的方法可以將虛擬角色的服裝分離出來,并且服裝也是可驅(qū)動的。圖 5 顯示了每個單獨的服裝層,可以僅通過骨骼關(guān)節(jié)角度控制,而不需要特定的服裝配準模塊。























