













谷歌Gemini大逆轉?斯坦福Meta華人證明其推理性能強于GPT-3.5
Gemini的推理能力,真的比GPT-4弱嗎?
此前,谷歌憋出的重磅復仇神器Gemini Pro,被發現在常識推理任務中落后于OpenAI的GPT模型。
之后又有CMU發布的論文和實驗,證明Gemini Pro的很多能力都略微落后于GPT-3.5 Turbo。
不過最近,斯坦福和Meta的學者為Gemini洗清了這一「冤屈」。
他們發現,這種基于有限數據集(HellaSWAG)的評估,并不能完全捕捉到Gemini真正的常識推理潛力。

論文地址:https://arxiv.org/abs/2312.17661
而在新測試集中,Gemini的推理能力比之前強很多!
Gemini的真正潛力
斯坦福和Meta的研究人員表示,以前的基于有限數據集的評估,對于Gemini不夠公平。
這次,研究人員設計了需要跨模態整合常識知識的任務,以對Gemini在復雜推理任務中的表現進行徹底的評估。
研究人員對12個常識推理數據集進行了全面分析,從一般任務到特定領域的任務。
在其中的4個LLM實驗和2個MLLM實驗中,研究者證明了Gemini具有目前相當強的常識推理能力。
研究者對于當前流行的四大模型——Llama 2-70b、Gemini Pro、GPT-3.5 Turbo和GPT-4 Turbo進行了評估,
他們發現,總體而言,Gemini Pro的性能和GPT-3.5 Pro相當,準確性上落后于GPT-4 Turbo。
實驗
數據集
實驗中采用了12個與不同類型的常識推理相關的數據集,包括11個基于語言的數據集和一個多模態數據集。
基于語言的數據集包括三大類常識推理問題:
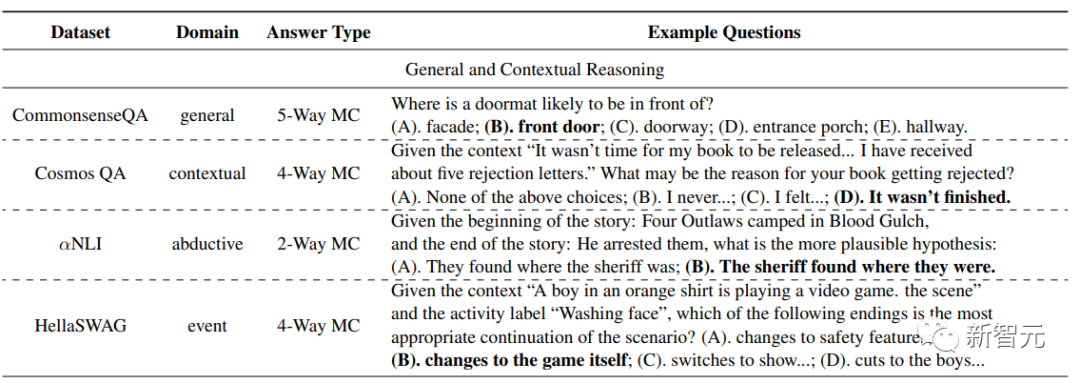
1.一般推理和情境推理:CommonsenseQA,側重于一般常識知識;Cosmos QA,強調語境理解敘事;αNLI,引入演繹推理,包括推斷最合理的解釋;HellaSWAG,以上下文事件序列的推理為中心。
2.專業推理和知識推理:TRAM,測試關于時間的推理;NumerSense,側重于數值理解;PIQA,評估物理相互作用知識;QASC,處理與科學相關的推理;RiddleSense,通過謎語挑戰創造性思維。
3.社會和道德推理:Social IQa,測試對社會互動的理解;ETHICS,評估道德和倫理推理。
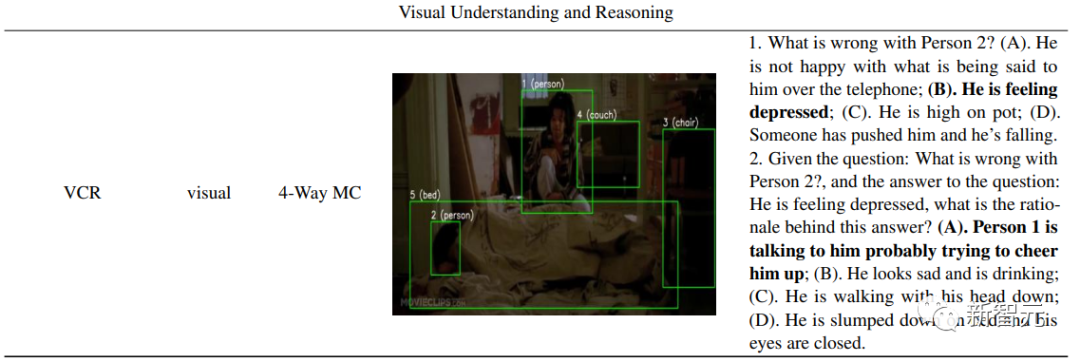
對于多模態數據集(視覺和語言),這里選擇VCR,一個用于認知水平視覺理解的大規模數據集。
對于包含多個任務的TRAM和ETHICS等數據集,研究人員提取了實驗的常識推理部分。
實驗中采用準確性作為所有數據集的性能指標。下表給出了數據集的概述以及示例問題。


模型
采用最流行的四個大模型:開源的Llama-2-70b-chat和閉源的Gemini Pro、GPT-3.5 Turbo、GPT-4 Turbo。
每個模型都使用相應的API密鑰進行訪問:通過Google Vertex AI訪問Gemini,通過OpenAI API訪問GPT,通過DeepInfra訪問Llama2。
對于多模態數據集,實驗中考慮了GPT-4V(API中的gpt-4-vision-preview)和 Gemini Pro Vision(API中的gemini-pro-vision)。
考慮到API成本和速率的限制,研究人員從每個基于語言的數據集的驗證集中隨機選擇了200個示例,從VCR數據集的驗證集中隨機選擇了50個示例。
對于所有評估,在模型響應生成期間采用貪婪解碼(即溫度=0)。
提示
在評估基于語言的數據集時,研究人員采用了兩種提示設置:零樣本標準提示(SP),旨在衡量模型在語言環境中的固有常識能力,以及少樣本思維鏈(CoT)提示,用于觀察模型性能的潛在增強。
對于多模態數據集,利用零樣本標準提示,來評估MLLM的端到端視覺常識推理能力。
結果
整體的性能比較結果如下表所示:
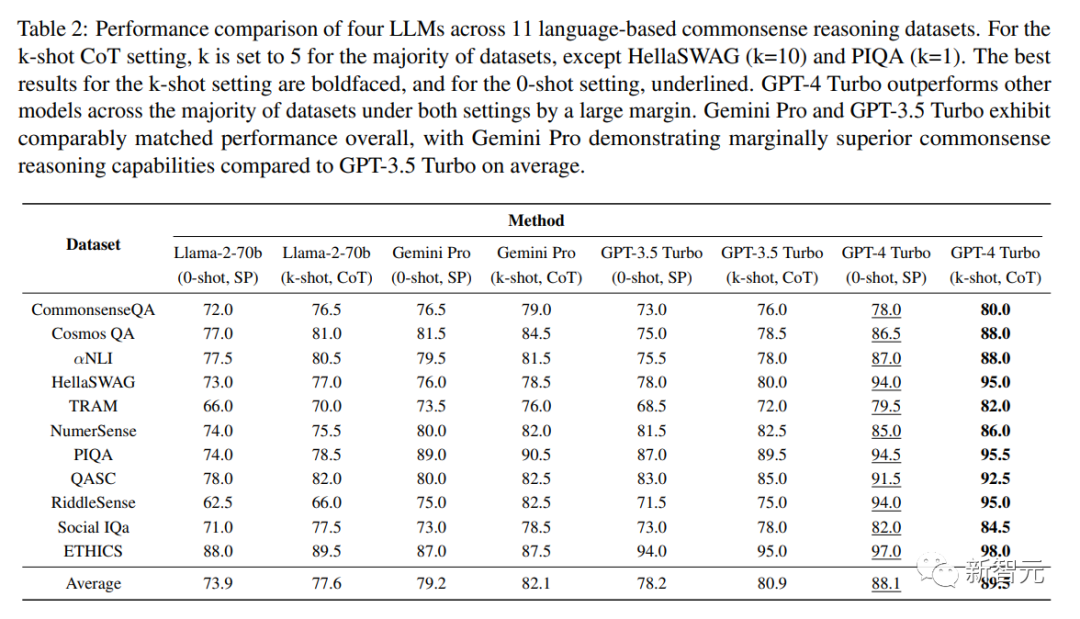
從模型的角度來看,GPT-4 Turbo的平均表現最好。在零樣本學習中,它比第二名的Gemini Pro高出7.3%,在少樣本學習中優勢更大(9.0%)。
而Gemini Pro的平均準確率略高于 GPT-3.5 Turbo(0-shot,SP下高1.3%,k-shot,CoT下高1.5%)。
關于提示方法,CoT提高了所有數據集的性能,在 CommonsenseQA、TRAM和Social IQa等數據集中有明顯的收益。
下表是在多模態VCR數據集上的性能比較:
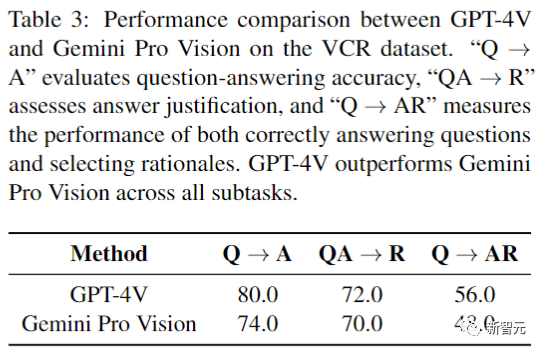
VCR的三個子任務分別為:Q → A,根據視覺上下文生成問題的答案;QA→R,要求模型為給定的答案提供基本原理;Q → AR,既要回答問題,又要用適當的理由來證明回答的合理性。
將11個基于語言的數據集分為三組,在圖1中展示了每組中每種設置的性能。
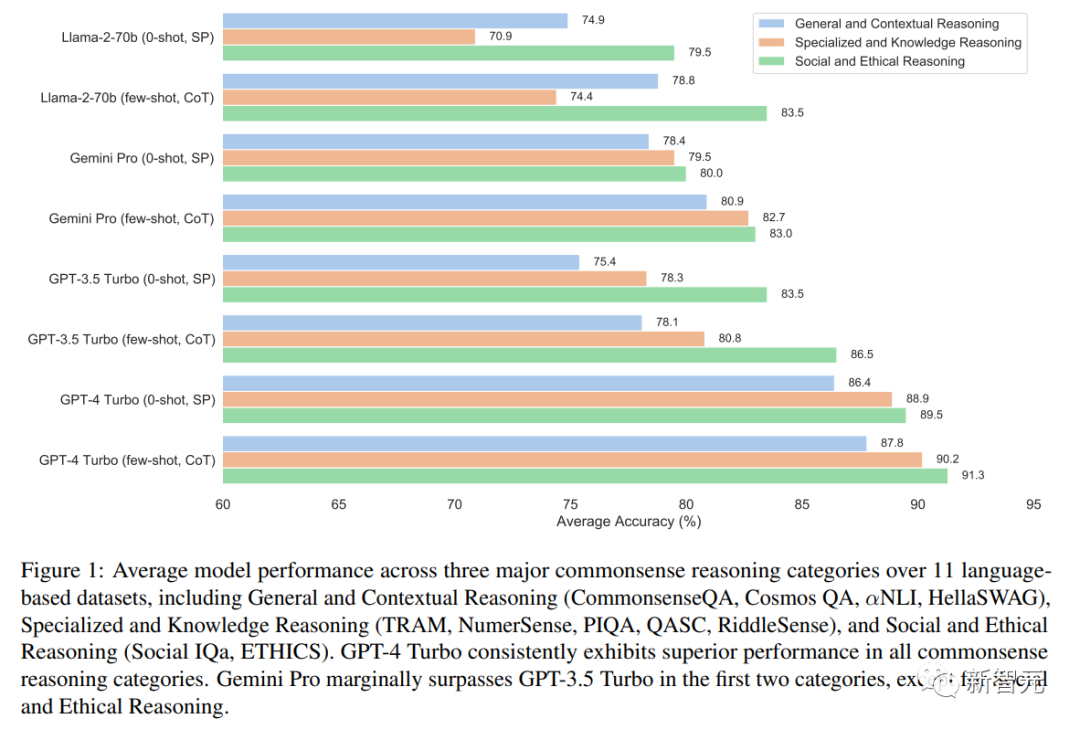
研究結果表明,GPT-4 Turbo在所有類別的性能方面始終領先。
Gemini Pro和GPT-3.5 Turbo的性能相當;不過,Gemini Pro在三個類別中的兩個類別中,略勝于GPT-3.5 Turbo。
總體而言,所有模型在處理社會和道德推理數據集方面,都表現出強大的能力。
然而,它們在一般推理和語境推理任務上的表現,存在顯著差異。
這也表明,它們對更廣泛的常識原則,及其在不同背景下的應用理解,存在潛在差距。
而在專業和知識推理類別,特別是在時間和基于謎語的挑戰領域,模型在處理復雜時間序列、破譯謎語所需的抽象和創造性思維能力上,都表現出了缺陷。
關于多模態數據集,圖2詳細介紹了GPT-4V和GeminiPro Vision在不同問題類型上的性能比較。
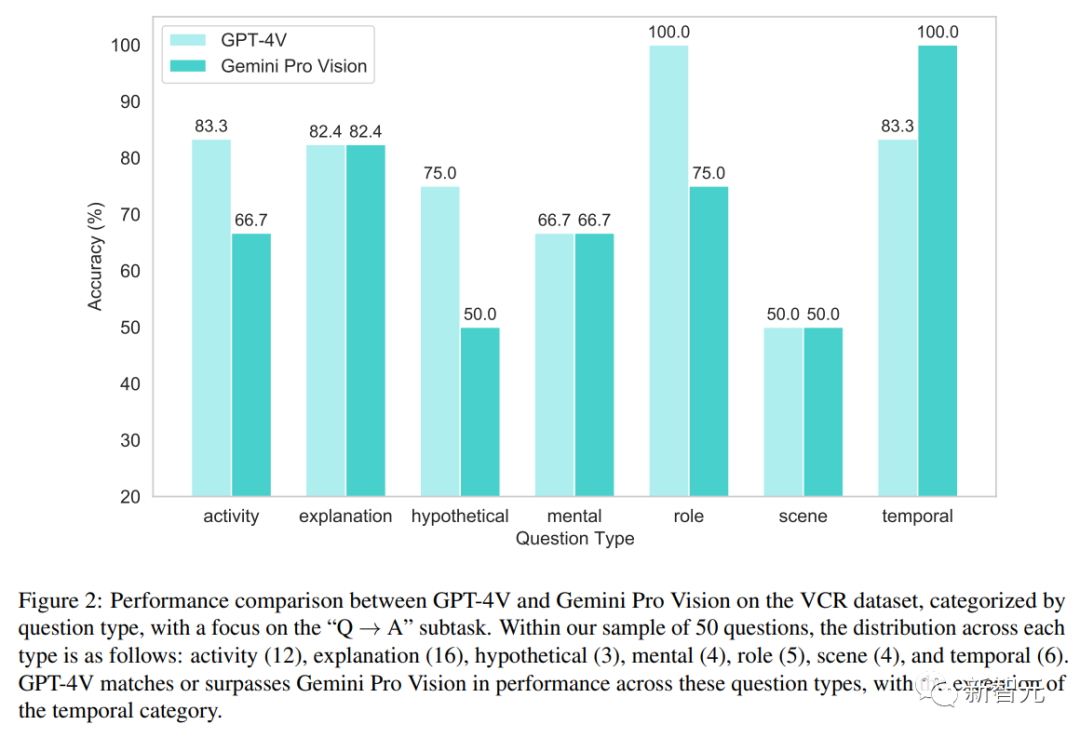
我們可以看到,在最后一個關于時間類別的問題上,GeminiPro Vision實現了反超。
MLLM的推理正當性
為了評估MLLM的推理能力,尤其是不僅提供正確答案,還能就常識問題提供合理且基于上下文推理的能力,研究者采用了系統抽樣方法。
對于評估四個LLM的11個基于語言的數據集,研究者隨機選擇了30個回答正確的問題,和30個回答錯誤的問題。
如果數據集提供的錯誤答案少于30 個,研究者就會包含進所有可用的錯誤答案,以確保分析的全面性。
選擇這些問題后,他們會讓每個模型解釋:「問題答案背后的基本原理是什么?」 然后手動檢查模型提供的推理過程,并根據其邏輯合理性和與問題的相關性被判為True或False。
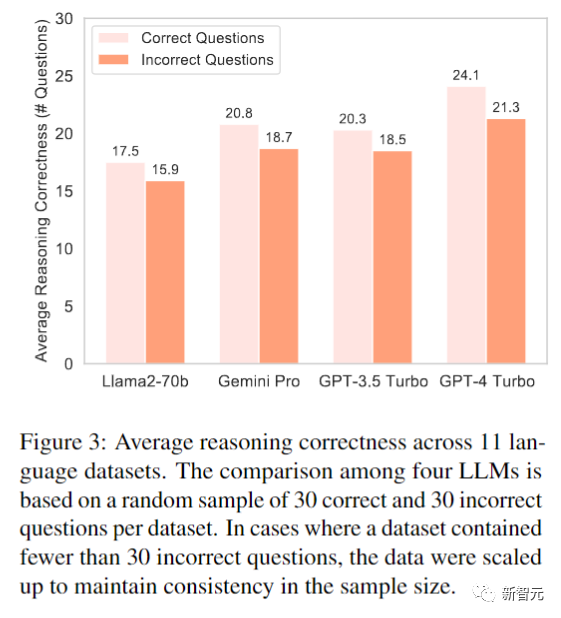
圖3顯示,GPT-4 Turbo在正確和錯誤的答案上,都顯示出先進的推理機制,即使最終答案不準確,它也有保持邏輯連貫的能力。
另外,Gemini Pro也表現出了值得稱贊的推理能力,提供了全面的常識推理方法。
下圖展示了Gemini Pro和GPT-3.5的兩個真實示例,展現了正確答案和正確理由,以及錯誤答案和錯誤理由的情況。

示例問題來自QASC數據集,紅色粗體為正確答案。在上圖中,Gemini Pro表現出有條不紊的推理,仔細考慮所有選項以得出最合乎邏輯的結論。

相反,由于GPT-3.5 Turbo對非常規邏輯的傾向,導致了富有想象力但不正確的答案。
這表明不同模型應對常識推理任務的不同策略,有自己的獨特能力和局限性。
Gemini Pro的常識推理能力
一般常識(CommonsenseQA)
在使用CommonsenseQA數據集的一般常識評估中,有這樣一道示例問題:「當你是陌生人時,人們會怎樣?」
A.火車 B.奇怪 C.人類 D.愚蠢 E.危險
Gemini Pro選擇了B。
它的推理過程也值得注意:它認識到,雖然所有選項都和「陌生人」的概念相關,但只有「奇怪」準確概括了問題的中立和開放性本質。
這個選擇,凸顯出了Gemini Pro解釋和應用一般常識知識的能力。
時間(TRAM)
TRAM數據集的時間常識評估中的示例問題:「他還承諾會來找他。」
他需要多長時間才能「來到他身邊」?
A.100年 B.一分鐘內 C.幾個小時
由于缺乏足夠的背景信息,特別是關于所涉及的身份和「來到」的含義,Gemini Pro無法提供明確的答案。
這說明了,模型需要依賴特定的上下文信息,來做出準確的時間判斷。
在現實世界的信息傳播中,模糊或不完整的信息,也會造成這種局限性。
社交(Social IQa)
在使用Social IQa數據集評估GeminiPro在社會常識推理方面的表現時,出現了一個有趣的場景: 人們一直欺負在Sasha,Sasha報復了回去,接下來人們會做什么?
A.按Sasha說的去做 B.報仇 C.逃離Sasha
正確答案是C,但Gemini Pro的選擇卻顯得很有洞察力。
它選擇了B,理由是Sasha的行動很可能點燃了人們復仇的欲望。
這一回應表明,Gemini Pro對于社會動態和情感動機有了細致入微的理解。
Visual(VCR)
在VCR數據集中,研究者分析了Gemini Pro Vision對涉及人身安全和潛在危險場景的響應。
如果此時4號推了3號,會發生什么?
Gemini Pro Vision回答:3號會掉下懸崖,危及生命。

這個結果表明,Gemini Pro Vision已經能夠做出視覺常識推理,分析視覺場景并預測這些場景中動作的潛在后果。
這表明模型已經掌握了空間關系和物理后果,具備了類似人類認知的復雜視覺信息能力。
作者介紹
Yuqing Wang目前是斯坦福大學的博士后研究員。
此前,她在明尼蘇達大學獲得學士學位,在在加利福尼亞大學圣芭芭拉分校獲得博士學位。

Yun Zhao目前是Meta的研究員,研究方向是機器學習(包括深度學習與強化學習)的應用、人工智能與數據挖掘。
此前,他在清華大學獲得碩士學位,并且同樣在加利福尼亞大學圣芭芭拉分校獲得博士學位。




























