













20B量級(jí)大模型性能媲美Llama2-70B!完全開源,從基座到工具全安排明白了
就在剛剛,國內(nèi)開源模型參數(shù)量紀(jì)錄,又被刷新了!
9月20日,上海人工智能實(shí)驗(yàn)室(上海AI實(shí)驗(yàn)室)與商湯科技聯(lián)合香港中文大學(xué)和復(fù)旦大學(xué),正式開源了200億參數(shù)的InternLM-20B模型。
項(xiàng)目地址:https://github.com/InternLM/InternLM
魔搭社區(qū):https://modelscope.cn/organization/Shanghai_AI_Laboratory
這次的200億參數(shù)版書生·浦語大模型,可以說是「加量不加價(jià)」,參數(shù)量還不到三分之一,性能卻可以劍挑當(dāng)今開源模型的標(biāo)桿——Llama2-70B。而當(dāng)前主流的開源13B模型們,則在所有維度上都被InternLM-20B甩在身后。
不僅如此,面向大模型研發(fā)與應(yīng)用的全鏈條工具體系也同時(shí)升級(jí)。
從開源模型本身,再到全鏈條的開源工具,這一次,上海AI實(shí)驗(yàn)室把自身研發(fā)大模型所沉淀的壓箱底的寶藏,全都拿了出來,希望幫助廣大研究者、機(jī)構(gòu)、社會(huì)從業(yè)者,都能以極低成本和門檻,參與大模型帶來的這場技術(shù)革命。
性能「同級(jí)領(lǐng)先」,門檻「開箱即用」,InternLM-20B,就是大模型走向千行百業(yè)的催化劑和新支點(diǎn)!
這股大模型的浪潮,將惠及每個(gè)人。
我們用的,全部開源
眾所周知,在大模型的整個(gè)研發(fā)體系中,有串在一起的多個(gè)環(huán)節(jié),這是十分復(fù)雜的一套閉環(huán)。
如何用更規(guī)范的代碼方式去組織?拿到基座模型該怎么用?落地到應(yīng)用的一步步過程中,有哪些注意事項(xiàng)?到處都是問題。
在經(jīng)過日常工作中真正的實(shí)踐后,上海AI實(shí)驗(yàn)室的團(tuán)隊(duì)沉淀出來一套寶貴經(jīng)驗(yàn)。
現(xiàn)在,他們?yōu)榱朔睒s開源生態(tài),干脆把模型從數(shù)據(jù)準(zhǔn)備,到預(yù)訓(xùn)練、部署,再到評(píng)測應(yīng)用,這整套流程中會(huì)涉及到的工具,全部開源了。
解密「獨(dú)家配方」
數(shù)據(jù),之于大模型重要性,就好比生產(chǎn)的原材料,沒有動(dòng)力來源,無法驅(qū)動(dòng)智能AI系統(tǒng)運(yùn)轉(zhuǎn)。尤其,高質(zhì)量的數(shù)據(jù)更是大模型產(chǎn)業(yè)化的關(guān)鍵要素之一。
在收集上,不僅需要有效地過濾和清洗從網(wǎng)頁、書籍、專業(yè)報(bào)告論文等各種渠道中爬取的原始素材,還需要充分利用模型內(nèi)測用戶提供的反饋。
不過,要想讓LLM能夠獲取關(guān)鍵能力,比如理解、編程、邏輯推理,成為真正的「六邊形戰(zhàn)士」,更重要的是自己去構(gòu)建數(shù)據(jù)。
在這一方面,學(xué)術(shù)界的研究也是非常活躍,比如微軟「Textbooks Are All You Need」,通過構(gòu)建數(shù)據(jù)訓(xùn)練后的模型phi-1,能夠在基準(zhǔn)上取得相對(duì)領(lǐng)先優(yōu)勢。

就上海AI實(shí)驗(yàn)室團(tuán)隊(duì)來說,他們沒有選擇從單點(diǎn)方向去構(gòu)建數(shù)據(jù),而是從「全維度」,對(duì)整個(gè)知識(shí)體系梳理后構(gòu)建語料。
因此,這些語料在知識(shí)和邏輯的密度上,是非常高的。
在大量的常規(guī)內(nèi)容中加入少量的「催化劑」,不僅可以更好地激發(fā)出LLM的關(guān)鍵能力,而且模型對(duì)于相關(guān)信息的吸收和理解也會(huì)更強(qiáng)。
用上海AI實(shí)驗(yàn)室領(lǐng)軍科學(xué)家林達(dá)華的話來說,「從某種意義上來說,這里的1個(gè)token,可以等同于10個(gè),甚至100個(gè)傳統(tǒng)token的效力」。
就算力方面,除了互聯(lián)網(wǎng)大廠坐擁著豐富的資源外,開源社區(qū)大部分的開發(fā)者很難獲取更多的算力。
「希望能夠有輕量級(jí)的工具,能夠把模型用起來」。這是上海AI實(shí)驗(yàn)室收到最多的社區(qū)反饋。
通過開源XTuner輕量級(jí)微調(diào)工具,用戶可以在8GB消費(fèi)級(jí)GPU上,用自己的數(shù)據(jù)就能微調(diào)上海AI實(shí)驗(yàn)室開源的模型。
此外,在模型應(yīng)用方向上,「聊天對(duì)話」依舊是模型非常重要的能力的一部分。
上海AI實(shí)驗(yàn)室還想突出一點(diǎn)是,大模型作為中央Hub,使用工具解決問題,類似于Code Interpreter的方式去調(diào)用工具。
同時(shí),在這個(gè)過程中,大模型還能進(jìn)行自我反思,這便是LLM加持下智能體展現(xiàn)的巨大潛力。
林達(dá)華認(rèn)為,Agent會(huì)是一個(gè)長期發(fā)展非常有價(jià)值的需要去探索的方向。
最終智能體的世界,整個(gè)組織分工也會(huì)在不斷的升級(jí)和演進(jìn),未來肯定是非常多的智能體的共同存在,有各自擅長的領(lǐng)域,相互之間會(huì)有很多技術(shù)能夠促進(jìn)它們之間的交流。
那么,此次工具鏈具體升級(jí)的地方在何處?
- 數(shù)據(jù):OpenDataLab開源「書生·萬卷」預(yù)訓(xùn)練語料
數(shù)據(jù)上,書生·萬卷1.0多模態(tài)訓(xùn)練語料8月14日正式開源,數(shù)據(jù)總量超總量超過2TB,包含了文本數(shù)據(jù)集、圖文數(shù)據(jù)集、視頻數(shù)據(jù)集三部分。
通過對(duì)高質(zhì)量語料的「消化」,書生系列模型在語義理解、知識(shí)問答、視覺理解、視覺問答等各類生成式任務(wù)表現(xiàn)出的優(yōu)異性能。
截止目前,已經(jīng)有近10萬的下載量。

- 預(yù)訓(xùn)練:InternLM高效預(yù)訓(xùn)練框架
預(yù)訓(xùn)練階段,InternLM倉庫也開源了預(yù)訓(xùn)練框架InternLM-Train。
一方面,深度整合了Transformer模型算子,使得訓(xùn)練效率得到提升,另一方面則提出了獨(dú)特的Hybrid Zero技術(shù),實(shí)現(xiàn)了計(jì)算和通信的高效重疊,訓(xùn)練過程中的跨節(jié)點(diǎn)通信流量大大降低。
得益于極致的性能優(yōu)化,這套開源體系實(shí)現(xiàn)了千卡并行計(jì)算的高效率,訓(xùn)練性能達(dá)到了行業(yè)領(lǐng)先水平。
- 微調(diào):InternLM全參數(shù)微調(diào)、XTuner輕量級(jí)微調(diào)
低成本大模型微調(diào)工具箱XTuner也在近期開源,支持了Llama等多種開源大模型,以及LoRA、QLoRA等微調(diào)算法。
硬件要求上,XTuner最低只需8GB顯存,就可以對(duì)7B模型進(jìn)行低成本微調(diào),20B模型的微調(diào)也能在24G顯存的消費(fèi)級(jí)顯卡上完成。
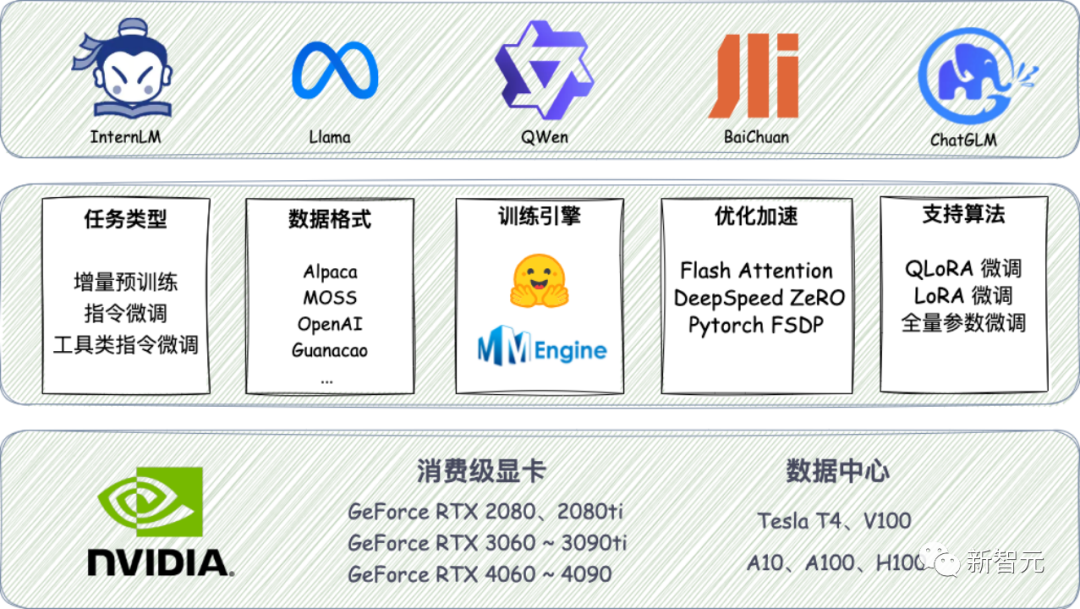
XTuner為各類開源模型提供了多樣的微調(diào)框架
- 部署:LMDeploy支持十億到千億參數(shù)語言模型的高效推理
部署方面,LMDeploy涵蓋了大模型的全套輕量化、推理部署和服務(wù)解決方案。
它支持了從十億到千億參數(shù)的高效模型推理,在吞吐量等性能上超過了社區(qū)主流開源項(xiàng)目FasterTransformer,vLLM,Deepspeed等。

- 評(píng)測:OpenCompass一站式、全方位大模型評(píng)測平臺(tái)
評(píng)測部分,開源的大模型評(píng)測平臺(tái)OpenCompass提供了學(xué)科、語言、知識(shí)、理解、推理五大維度的評(píng)測體系。
同時(shí),它還支持50+評(píng)測數(shù)據(jù)集、30萬道評(píng)測題目,支持零樣本、小樣本及思維鏈評(píng)測,是目前最全面的開源評(píng)測平臺(tái)。

- 應(yīng)用:Lagent輕量靈活的智能體框架
在最后的應(yīng)用環(huán)節(jié),上海AI實(shí)驗(yàn)室團(tuán)隊(duì)將重點(diǎn)放在了智能體上,開發(fā)并開源了Lagent輕量靈活的智能體框架。
它能夠支持用戶快速地將一個(gè)大語言模型轉(zhuǎn)變?yōu)槎喾N類型的智能體,并提供典型工具為大語言模型賦能。

這套開源框架集合了多種類型的智能體能力,包括經(jīng)典的ReAct、AutoGPT和ReWoo等。
這個(gè)框架的代碼結(jié)構(gòu)不僅清晰,而且簡單。只用不到20行代碼,開發(fā)者就能創(chuàng)建一個(gè)屬于自己的智能體。
另外,Lagent支持包括InternLM,Llama,ChatGPT在內(nèi)的多個(gè)大模型。
在Lagent加持下,這些智能體能夠調(diào)用大語言模型進(jìn)行規(guī)劃推理和工具調(diào)用,并在執(zhí)行過程中及時(shí)進(jìn)行反思和自我修正。
國內(nèi)首發(fā)16k上下文,200億參數(shù)打平Llama2-70B
除了全套的大模型工具鏈外,上海AI實(shí)驗(yàn)室還全新開源了高達(dá)200億參數(shù)的InternLM-20B。
評(píng)測結(jié)果顯示,在同量級(jí)開源模型中,InternLM-20B是當(dāng)之無愧的綜合性能最優(yōu)。
- 超長上下文支持
首先,在語境長度上,InternLM-20B可以支持高達(dá)16K的上下文窗口。
如下圖所示,InternLM-20B閱讀了某知名咖啡品牌的長新聞后,能夠?qū)θ齻€(gè)提問做出準(zhǔn)確回答。

對(duì)于超級(jí)長篇的論文和報(bào)告,InternLM-20B也能準(zhǔn)確地提取摘要。
比如,輸入經(jīng)典的ResNet論文后,它立馬寫出了摘要,準(zhǔn)確概括了ResNet的核心思想和實(shí)驗(yàn)效果。
- 調(diào)用工具,自學(xué)成才
其次,在長語境的支持下,模型的能力被大大拓展,無論是工具調(diào)用、代碼解釋,還是反思修正,都有了更大的空間。而這也成了在InternLM-20B之上打造智能體的關(guān)鍵技術(shù)。
現(xiàn)在,InternLM-20B不僅可以支持日期、天氣、旅行、體育等數(shù)十個(gè)方向的內(nèi)容輸出,以及上萬個(gè)不同的API,而且還能過類似Code Interpreter的方式去進(jìn)行工具的調(diào)用。
與此同時(shí),在這個(gè)過程中,它還能進(jìn)行反思修正,跟現(xiàn)實(shí)場景產(chǎn)生聯(lián)系。
在清華等機(jī)構(gòu)聯(lián)合發(fā)布的大模型工具調(diào)用評(píng)測集ToolBench中,InternLM-20B和ChatGPT相比,達(dá)到了63.5%的勝率,在該榜單上取得了最優(yōu)結(jié)果。
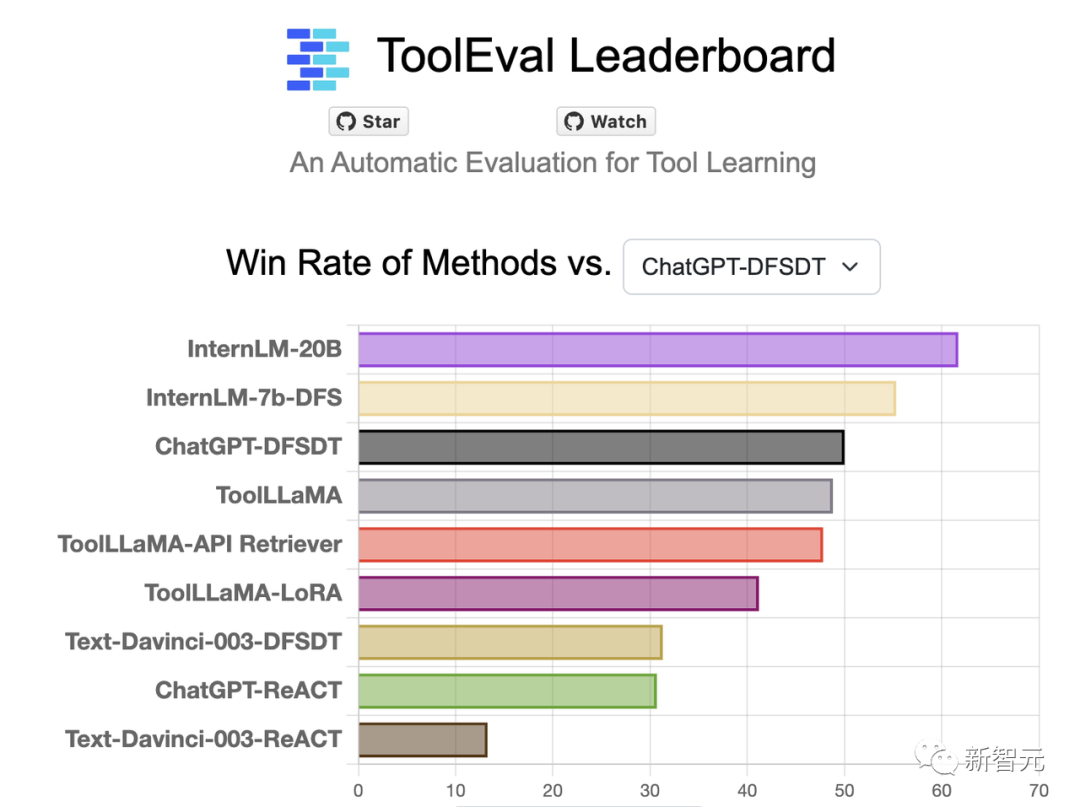
而且,InternLM-20B模型還展現(xiàn)出一定的零樣本泛化能力。即使模型在訓(xùn)練過程中并沒有學(xué)過一些工具,它竟然也能根據(jù)工具描述和用戶提問來調(diào)用工具。
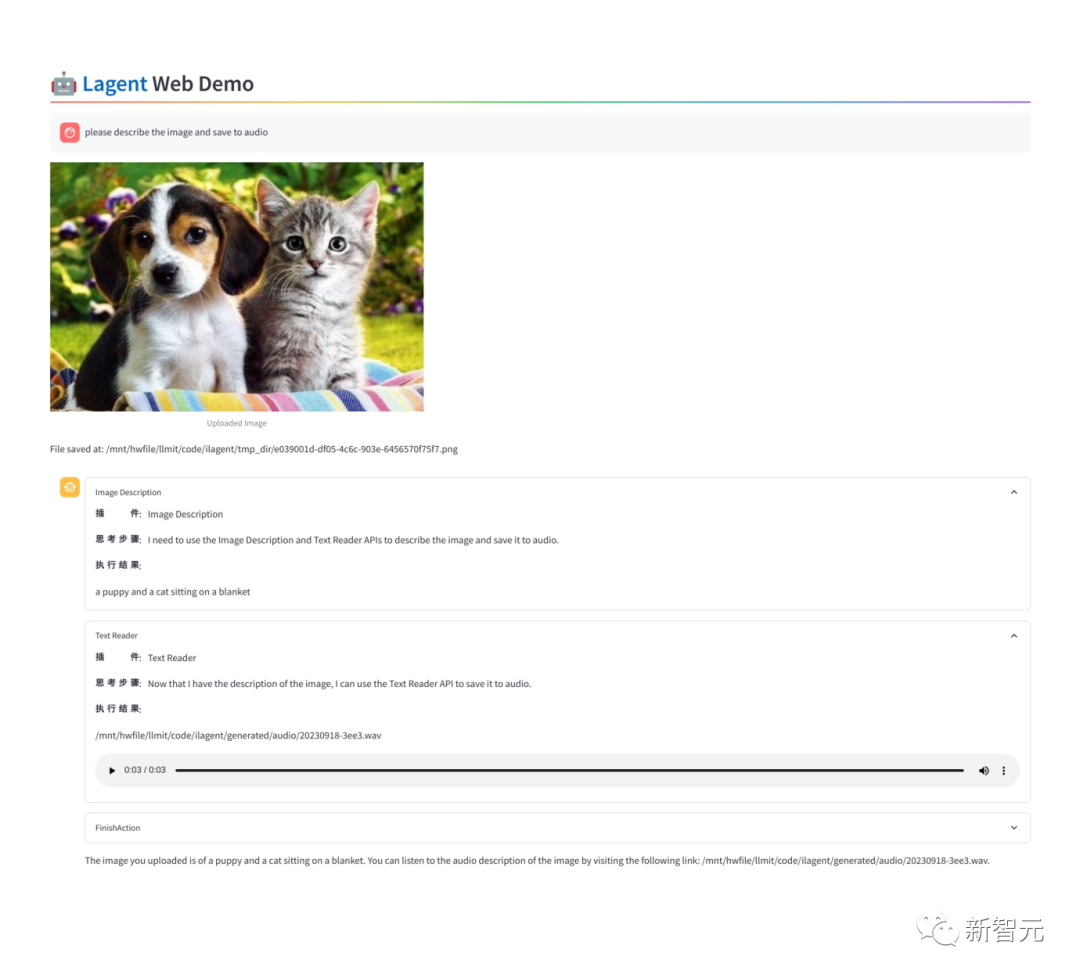
如下圖所示,給它提供一些AI工具,它就可以自己進(jìn)行規(guī)劃和推理,完成用戶問題。
- 同量級(jí)全面領(lǐng)先
在多達(dá)50款各個(gè)維度的主流評(píng)測集上,InternLM-20B也一舉實(shí)現(xiàn)了同量級(jí)開源模型的綜合性能最優(yōu)。
與此同時(shí),在平均成績上也明顯超越了規(guī)模更大的Llama-33B,甚至在部分評(píng)測中還能小勝Llama2-70B。
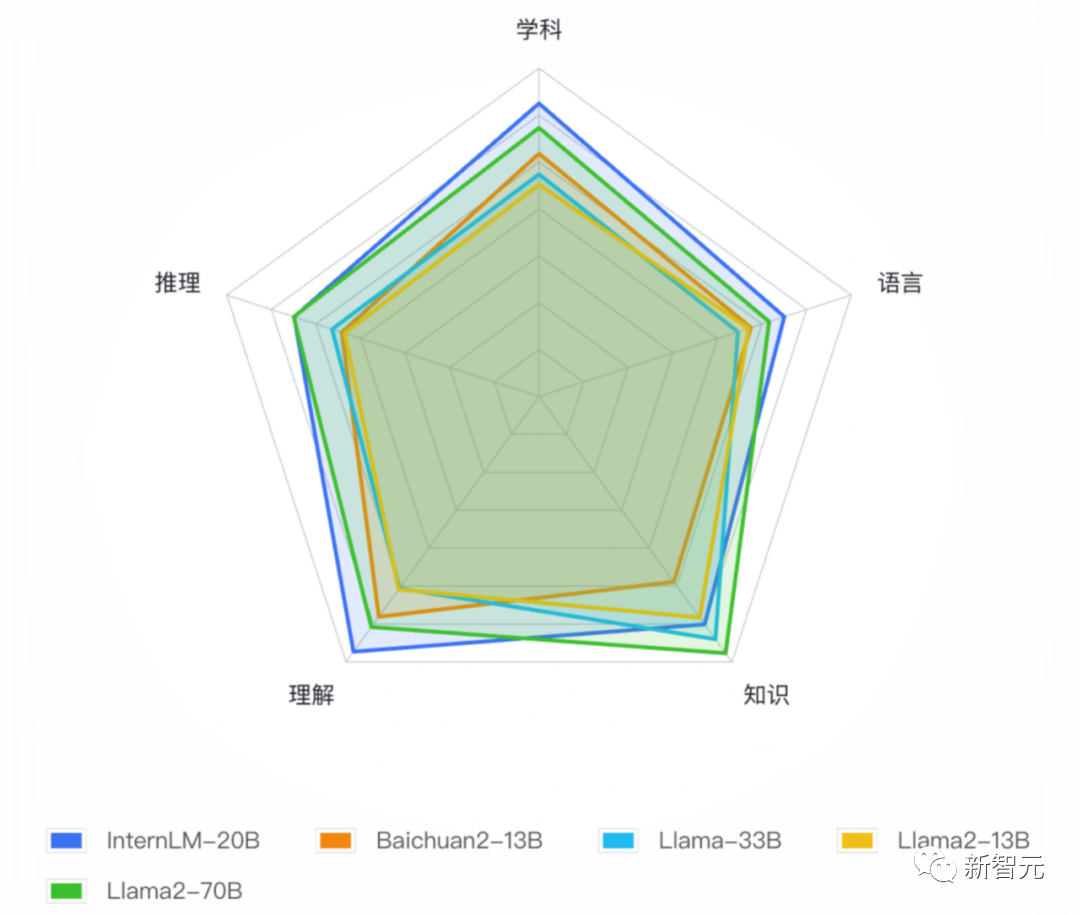
具體來說,InternLM-20B在MMLU、C-Eval、AGIEval綜合性學(xué)科評(píng)測中成績優(yōu)異,在同量級(jí)開源模型中處于領(lǐng)先位置。
尤其是在包含中文學(xué)科考試的C-Eval和AGIEval上,表現(xiàn)明顯超過了Llama2-70B。

在考驗(yàn)事實(shí)性知識(shí)的評(píng)測上,InternLM-20B全面超越了13B模型,并且能與Llama-33B一較高下。
但相比于Llama-65B或者Llama2-70B仍有一定差距。

在理解能力維度,InternLM-20B的表現(xiàn)更是突出,全面超越了包括Llama2-70B在內(nèi)的各量級(jí)開源模型。

推理,是考倒了不少模型的「攔路虎」,考驗(yàn)的是大模型真金白銀的本事,也很大程度上決定了模型是否能支撐實(shí)際應(yīng)用。
在下述四個(gè)推理測評(píng)集上,InternLM-20B的成績均超越了主流的13B開源模型,甚至已經(jīng)接近了Llama-65B的推理能力。

編程能力上,InternLM-20B也有了顯著提升。在HumanEval和MBPP兩個(gè)典型評(píng)測集上,接近了Llama2-70B。

注:上述截圖中的粗體為13B-33B量級(jí)范圍內(nèi),各項(xiàng)最佳成績。
在HuggingFace最新公布的Open LLM Leaderboard評(píng)測榜單上,InternLM-20B在參數(shù)量60B以下基模型中平均成績領(lǐng)先,也超過了Llama-65B。

- 更安全的開源模型
最后,在價(jià)值對(duì)齊上,InternLM-20B也更加完善、更為安全。
如果你向它提出帶有偏見的問題,它就會(huì)立馬識(shí)別出其中的不安全因素,給出正確的價(jià)值引導(dǎo)。

大模型,從來都不是大廠的專利
大模型浪潮掀起后,我們需要關(guān)注的,不僅僅是在測評(píng)榜單上拔得頭籌,還有如何讓大模型從「AI皇冠上的明珠」,成為千行百業(yè)都可用的「全新生產(chǎn)力」。
縱觀歷史,真正引領(lǐng)時(shí)代的技術(shù),不只是顛覆性的創(chuàng)新,更重要的,是做到低成本、低門檻、人人可用。但OpenAI、谷歌這樣的大廠是絕對(duì)不會(huì)把其中具體的細(xì)節(jié)公之于眾。
而這,正是上海AI實(shí)驗(yàn)室的初心之所在。
自6月首發(fā)以來,書生·浦語已經(jīng)完成了多輪升級(jí),在開源社區(qū)和產(chǎn)業(yè)界產(chǎn)生了廣泛影響。

而且,除了把代碼在GitHub上開放、把模型放在HuggingFace和魔搭社區(qū),上海AI實(shí)驗(yàn)室甚至每天都會(huì)派專人去看社區(qū)里的反饋,對(duì)用戶提問悉心解答。
此前,Meta的LLaMA模型開源,引爆了ChatGPT替代狂潮,讓文本大模型迎來了Stable Diffustion時(shí)刻。
就如同今天羊駝家族的繁榮生態(tài),上海AI實(shí)驗(yàn)室的開源努力,必將給社區(qū)帶來不可估量的價(jià)值。
對(duì)于全球范圍內(nèi)活躍的開發(fā)者和研究者,書生·浦語會(huì)提供一個(gè)體量適中、但能力非常強(qiáng)的基座。
大部分企業(yè),尤其是中小企業(yè),雖然看到了大模型的趨勢,但是不太可能像大廠一樣花很大代價(jià)去購買算力,并且吸引最頂尖的人才。
實(shí)際上,從7月6號(hào)的人工智能大會(huì)開始,上海AI實(shí)驗(yàn)室就已經(jīng)在做全鏈條地做開源。比如XTuner能以非常輕量級(jí)的方式,讓用戶只用自己的一些數(shù)據(jù),就能訓(xùn)出自己的模型。
不僅如此,一個(gè)團(tuán)隊(duì)把開源社區(qū)的問題、語料、文檔和XTuner模型結(jié)合,訓(xùn)練出了一個(gè)開源社區(qū)客服。這就是對(duì)開源社區(qū)實(shí)打?qū)嵉呢暙I(xiàn)。
甚至,上海AI實(shí)驗(yàn)室把自己的整個(gè)技術(shù)體系,都分享給了社區(qū)(也就是上文提到的全鏈條工具體系)。
全社會(huì)如此多的行業(yè),如此多的企業(yè),如此多的機(jī)構(gòu)和研發(fā)者,如果能實(shí)實(shí)在在把大模型的價(jià)值落地,將是非常重要的力量。
他們擁有無窮的創(chuàng)造力,唯一缺的就是資源。
而上海AI實(shí)驗(yàn)室的「雪中送炭」,必然會(huì)讓大模型在落地領(lǐng)域發(fā)揮出巨大的價(jià)值。
正如林達(dá)華所言——
作為實(shí)驗(yàn)室,我們能提供基礎(chǔ)模型以及將各行業(yè)的know-how融匯成數(shù)據(jù)、模型能力的一系列工具,并且將它們做得非常易用、教會(huì)更多人用,讓它們能在各個(gè)行業(yè)里開花結(jié)果。
全鏈條工具體系開源鏈接
「書生·萬卷」預(yù)訓(xùn)練語料:
https://github.com/opendatalab/WanJuan1.0
InternLM預(yù)訓(xùn)練框架:
https://github.com/InternLM/InternLM
XTuner微調(diào)工具箱:
https://github.com/InternLM/xtuner
LMDeploy推理工具鏈:
https://github.com/InternLM/lmdeploy
OpenCompas大模型評(píng)測平臺(tái):
https://github.com/open-compass/opencompass
Lagent智能體框架:
https://github.com/InternLM/lagent





























