













譯者 | 朱先忠
審校 | 重樓
引言
時空數據來自手機、氣候傳感器、金融市場交易以及車輛和集裝箱中的傳感器等多種來源,是規模最大、擴展最快的數據類別。IDC估計,到2025年,聯網的物聯網設備產生的數據總量將達到73.1 ZB,復合年增長率從2019年的18.3 ZB增長到26%。
根據《麻省理工科技評論》最近的一份報告顯示,物聯網數據(通常標有位置)的增長速度快于其他結構化和半結構化數據(見下文中的圖示)。然而,由于物聯網數據的復雜集成和有意義的利用帶來的挑戰,大多數組織至今在很大程度上仍未開發物聯網數據。
當前,兩項突破性技術進步的融合將為地理空間和時間序列數據分析領域帶來前所未有的效率和可訪問性。第一種是GPU加速的數據庫,它為時間序列和空間工作負載帶來了以前無法達到的性能和精度水平。第二種是生成式人工智能,這一技術有助于消除對同時擁有GIS專業知識和高級編程敏銳性的高端人才的需求。
上述這些發展成就都是開創性的,它們相互交織,使復雜的空間和時間序列分析越來越普及,使越來越廣泛的數據專業人員比以往任何時候都能夠使用這些技術。在這篇文章中,讓我們來探討這些進步將如何重塑時空數據庫的格局,并開創一個數據驅動的見解和創新的新時代。
GPU如何加速時空分析
GPU最初設計用于加速計算機圖形和渲染,最近在其他需要大規模并行計算的領域推動了有關創新,這包括為當今最強大的生成式人工智能模型提供動力的神經網絡。同樣,時空分析的復雜性和范圍經常受到計算規模的限制。但是,能夠利用GPU加速技術的現代數據庫已經突破了新的性能瓶頸,從而推動新的技術見解。在這里,我將重點介紹基于GPU加速的時空分析方面的兩個特定領域。
具有不同時間戳的時間序列流的不精確聯接
在分析不同的時間序列數據流時,時間戳很少完全對齊。即使設備依賴精確的時鐘或GPS(全球衛星定位系統),傳感器也可能以不同的間隔生成讀數,或提供具有不同延遲的指標。或者,在股票交易和股票報價的情況下,您可能會有交錯的時間戳,而這些時間戳并不完全一致。
為了在任何給定時間獲得機器數據狀態的通用操作畫面,您需要加入這些不同的數據集(例如,了解路線上任何點處的車輛的實際傳感器值,或將金融交易與最新報價進行對賬等)。與客戶數據不同,在客戶數據中,您可以使用固定的客戶ID進行連接;在這里,您需要執行不精確的連接,以根據時間關聯不同的數據流。
我們可以利用GPU的處理能力來完成繁重的任務,而不是試圖構建復雜的數據工程管道來關聯時間序列。例如,借助于Kinetica(一個分布式的、GPU加速的數據庫),您可以利用GPU加速的ASOF聯接,該聯接允許您使用指定的間隔將一個時間序列數據集聯接到另一個數據集,以及確定應返回該間隔內的最小值還是最大值。
例如,在下面的場景中,交易和報價以不同的時間間隔到達。
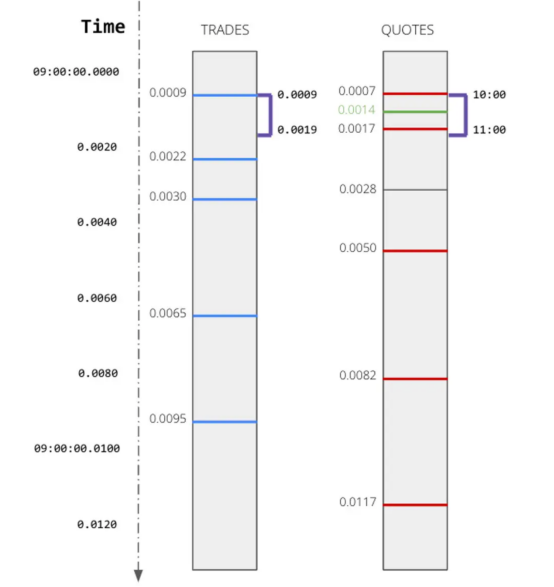
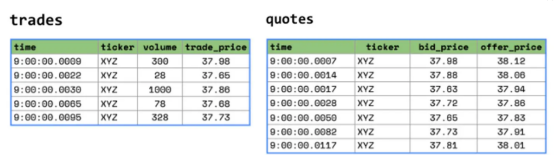
如果我想分析蘋果公司的交易及其相應的報價,我可以使用Kinetica的ASOF聯接來立即找到在每次蘋果交易的特定間隔內發生的相應報價。相應的SQL腳本如下所示:
SELECT *
FROM trades t
LEFT JOIN quotes q
ON t.symbol = q.symbol
AND ASOF(t.time, q.timestamp, INTERVAL '0' SECOND, INTERVAL '5' SECOND, MIN)
WHERE t.symbol = 'AAPL'這里僅使用一行SQL腳本并結合GPU的強大功能,從而取代了時空數據的復雜數據工程管道的實現成本和處理延遲。此查詢將在交易后五秒內為每個交易找到最接近該交易的報價。時間序列或空間數據集上的這些類型的不精確連接是幫助治理時空數據泛濫的關鍵工具。
數十億點的交互式地理可視化
通常,探索或分析時空物聯網數據的第一步是可視化。特別是對于地理空間數據,根據參考地圖渲染數據將是對數據進行視覺檢查、覆蓋率問題檢查、數據質量問題或其他異常情況檢查的最簡單方法。例如,與開發其他算法或流程來驗證GPS信號質量相比,視覺掃描地圖并確認車輛的GPS軌跡實際上比遵循道路網絡的速度要快得多。或者,如果你在幾內亞灣的空島周圍看到虛假數據,你可以快速識別和隔離發送0度緯度和0度經度的無效GPS數據源。
然而,使用傳統技術大規模分析大型地理空間數據集往往需要妥協。傳統的客戶端渲染技術通常可以處理數萬個點或地理空間特征,然后渲染會出現問題,良好的交互式探索體驗根本不可能存在。探索數據的子集,例如在有限的時間窗口或非常有限的地理區域,有可能會將數據量減少到更易于管理的數量級。然而,一旦開始對數據進行采樣,就有可能丟棄那些顯示特定數據質量問題、趨勢或異常的數據,而這些數據本可以通過可視化分析輕松發現。
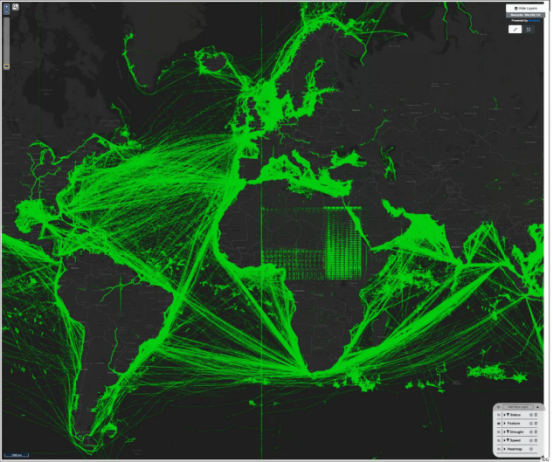
對航運交通中近3億個數據點的目視檢查可以快速發現數據質量問題,例如非洲的異常數據或本初子午線處的波段。
幸運的是,GPU恰好擅長可視化的加速。例如,具有服務器端GPU渲染功能的現代數據庫平臺,如Kinetica,可以實現數百萬甚至數十億個地理空間點和特征的實時探索和可視化。這種巨大的加速使您能夠即時可視化所有地理空間數據,而不會進行下采樣、聚合或降低數據保真度。即時渲染在平移和縮放操作時提供非常流暢的可視化體驗,從而非常有利于這些數據領域的探索和發現。可以選擇性地啟用諸如熱圖或裝箱之類的附加聚合,以便對完整的數據語料庫執行進一步分析。
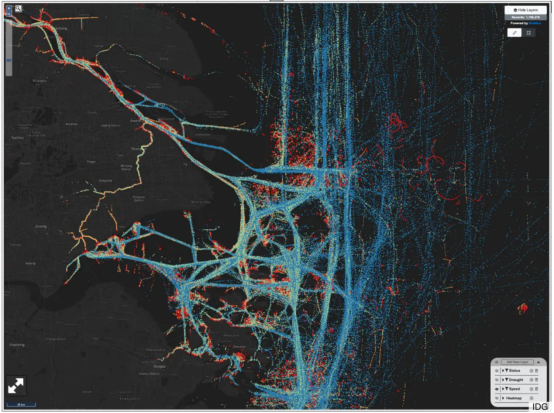
上圖中使用放大方法來分析中國東海區域的航運交通模式和船只速度。
用LLM實現時空分析的普及化
時空問題涉及數據中空間和時間之間的關系,通常會引起外行的直覺共鳴,因為它們反映了現實世界的經驗。人們可能會想知道一件商品從下單到成功交付的過程。然而,即使對于經驗豐富的程序員來說,將這些看似簡單的查詢轉換為函數代碼也是一項艱巨的挑戰。
例如,在考慮交通狀況、道路封閉和送貨窗口的同時,為送貨卡車確定最大限度地縮短行程時間的最佳路線需要復雜的算法和實時數據集成。同樣,考慮到各種影響因素,通過時間和地理信息來追蹤疾病的傳播,需要復雜的建模和分析,這甚至會讓經驗豐富的數據科學家都感到困惑。
這些例子強調了時空問題雖然在概念上是可訪問的,但往往隱藏著使其編碼成為一項艱巨任務的復雜性。即使是經驗最豐富的SQL專家,也可能會對理解最佳數學運算以及相應的SQL函數語法提出挑戰。
值得慶幸的是,最新一代的大型語言模型(LLM)能夠熟練地生成正確高效的代碼,包括SQL。經過時空分析細微差別訓練的這些模型的微調版本,例如Kinetica的SQL-GPT原生LLM,現在可以為一類全新的用戶來解釋這些分析領域。
例如,假設我想分析典型的紐約市出租車數據集,并提出與空間和時間有關的問題。首先,我將為LLM提供一些關于我要分析的表的基本上下文。在Kinetica Cloud中,我可以使用UI或基本的SQL命令來定義我的分析上下文,包括對特定表的引用。這些表的列名和定義與LLM共享,但不共享這些表中的任何數據。或者,我可以在上下文中包含其他注釋、規則或示例查詢結果,以進一步提高SQL的準確性。
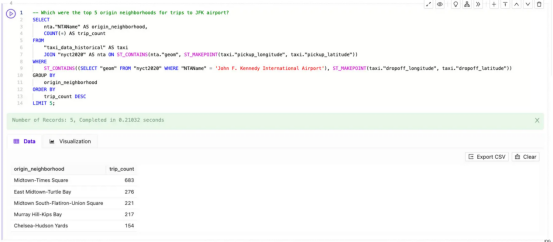
一旦我設置了初始上下文,我就可以在Kinetica Cloud中使用SQL-GPT來詢問“Which were the top 5 origin neighborhoods for trips to JFK airport?(前往JFK機場的前5個始發社區是哪些?)”。經過微調的LLM會立即生成以下SQL:
--前往JFK機場的前5個始發社區是哪些?
SELECT
nta."NTAName" AS origin_neighborhood,
COUNT(*) AS trip_count
FROM
"taxi_data_historical" AS taxi
JOIN "nyct2020" AS nta
ON ST_CONTAINS(nta."geom", ST_MAKEPOINT(taxi."pickup_longitude", taxi."pickup_latitude"))
WHERE ST_CONTAINS((
SELECT "geom"
FROM "nyct2020"
WHERE "NTAName" = 'John F. Kennedy International Airport'
),
ST_MAKEPOINT(taxi."dropoff_longitude", taxi."dropoff_latitude"))
GROUP BY
origin_neighborhood
ORDER BY
trip_count DESC
LIMIT 5;幾秒鐘內,經過微調的LLM就幫助我實現了:
- 設置SELECT語句,引用正確的目標表和列,設置JOIN并使用COUNT(*)、GROUP BY、ORDER BY和LIMIT。對于那些不太精通SQL的人來說,即使是基本的查詢構造也算是一個巨大的加速器。
- 使用正確的空間函數,如使用ST_MAKEPOINT()從緯度和經度創建點,使用ST_CONTAINS()查找包含指定點的地理區域。通過幫助我選擇正確的函數和語法,LLM可以幫助那些新進入該領域的人開始進行空間分析。
- 將真實世界中的參考信息集成到位置和時間。我問過“JFK airport(肯尼迪機場)”,但LLM能夠將這個參考翻譯成名為“John F. Kennedy International Airport(約翰·F·肯尼迪國際機場)”的規劃單元。這又一次節省了時間——太謝謝你了,LLM!
現在,我運行查詢來回答我的初始問題:
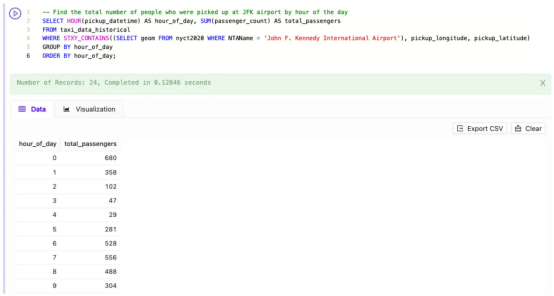
同樣,如果我請求Kinetica SQL-GPT幫助我“Find the total number of people who were picked up at JFK airport by hour of the day(查找一天中在肯尼迪機場接載的總人數)”,它會生成以下SQL:
-- Find the total number of people who were picked up at JFK airport by hour of the day
SELECT HOUR(pickup_datetime) AS hour_of_day, SUM(passenger_count) AS total_passengers
FROM taxi_data_historical
WHERE STXY_CONTAINS((SELECT geom FROM nyct2020 WHERE NTAName = 'John F. Kennedy International Airport'), pickup_longitude, pickup_latitude)
GROUP BY hour_of_day
ORDER BY hour_of_day;這個查詢包含了額外的復雜性,即對每輛出租車的乘客人數進行求和,并按一天中的小時對數據進行統計。但是,LLM處理了這種復雜性,并立即生成了正確的SQL。
對于更復雜的用戶,LLM還可以進行更高級的時空處理。例如,在下一個例子中,我想分析華盛頓特區的一隊卡車,我想了解哪些卡車目前靠近一組地理圍欄(在這種情況下,是華盛頓特區著名地標周圍的緩沖區)。
我可以從一個關于特定地理圍欄附近的基本問題開始,比如“How many unique trucks are currently within 1000 meters of the white house landmark?(白宮地標1000米范圍內目前有多少輛獨特的卡車?)”并使用Kinetica SQL-GPT生成以下SQL:
-- How many unique trucks are currently within 1000 meters of the white house landmark?
SELECT COUNT(DISTINCT r.TRACKID)
FROM recent_locations r
JOIN dc_landmarks d ON STXY_DWITHIN(r.x, r.y, d.wkt, 1000, 1)
WHERE d.fence_label = 'white house'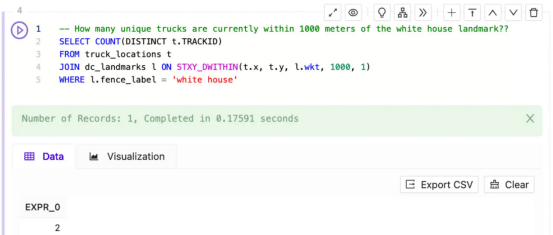
但是,如果我想不斷刷新哪些卡車在我的地理圍欄附近的視圖,我可以讓LLM幫助我創建一個物化視圖。
Kinetica SQL-GPT和LLM能夠生成SQL來創建和刷新物化視圖,并從“在過去5分鐘內,哪些卡車到達華盛頓特區地標200米以內?保留所有列并創建一個名為landmark_trucks的物化視圖(每10秒刷新一次以存儲結果)”這一提示開始:
-- Which trucks came within 200 meters of a landmark in Washington DC in the last 5 mins? Keep all the columns and create a materialized view called landmark_trucks that refreshes every 10 seconds to store the results.
CREATE OR REPLACE MATERIALIZED VIEW landmark_trucks REFRESH EVERY 10 SECONDS AS
SELECT *
FROM truck_locations t
JOIN dc_landmarks d ON STXY_DWITHIN(t.x, t.y, d.wkt, 200, 1)
WHERE t."TIMESTAMP" >= NOW() - INTERVAL '5' MINUTE;為了利用不斷增長的時空數據量,企業需要對其數據平臺進行現代化改造,以處理分析的規模,并提供其業務所依賴的見解和優化。幸運的是,GPU和生成人工智能的最新進展已準備好改變時空分析的世界。
總結
GPU加速的數據庫極大地簡化了時空數據的大規模處理和探索。隨著針對自然語言到SQL進行微調的大型語言模型的最新進展,時空分析技術可以在廣大組織中進一步推廣應用,這將有助于超越GIS分析師和SQL專家的傳統領域。GPU和生成人工智能的快速創新必將使這類應用成為一個令人興奮的領域。
本文作者Philip Darringer是Kinetica公司(http://www.kinetica.com/)的產品管理副總裁,負責指導公司時間序列和時空工作負載實時分析數據庫的開發。他在企業產品管理方面擁有超過15年的經驗,專注于數據分析、機器學習和位置情報領域。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Transforming spatiotemporal data analysis with GPUs and generative AI,作者:Philip Darringer





























