萬字總結(jié) | 2023大模型與自動駕駛論文走馬觀花
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
2023年已經(jīng)匆匆過去大半,不知各位自動駕駛小伙伴今年的工作生活情況是否順利呢?高階ADAS方案量產(chǎn)了嗎?新的文章和實驗進展又是否順利呢?今天給大家總結(jié)了2023年前后的一些自動駕駛結(jié)合大模型的開創(chuàng)性研究工作。
2023年是大模型蓬勃發(fā)展的一年,也是高階自動(輔助)駕駛走向現(xiàn)實和落地的一個關(guān)鍵節(jié)點。一些頭部自動駕駛企業(yè)和學(xué)術(shù)團隊也積極的在大模型與自動駕駛這個領(lǐng)域積極探索。其中除了上海人工智能實驗室,清華大學(xué),港大,港科大等自動駕駛研究強校外。也有Nvidia,waymo,wayve,GigaAI,Bosch,華為諾亞這些自動駕駛創(chuàng)新公司以及傳統(tǒng)巨頭分別提出了自己對于自動駕駛以及大模型的視角與展望。
具體而言,LLM直接參與自動駕駛 (LLM + 端到端的自動駕駛,LLM + 語義場景理解,LLM + 駕駛行為生成)成為了一個比較火熱的主旋律。另一些研究方向則關(guān)注在了多模態(tài)大模型進行仿真或世界模型的構(gòu)建,也有部分學(xué)者嘗試對大模型在自動駕駛應(yīng)用中的安全性和可解釋性作出了探討。本篇文章一共總結(jié)了30余篇自動駕駛結(jié)合大模型的論文和開源項目,并進行了非常簡單的總結(jié),希望對大家有用!
Drive Like a Human: Rethinking Autonomous Driving with Large Language Models [paper][github]
論文來自上海AILAB和東南大學(xué),通過LLM的理解環(huán)境能力,作者嘗試構(gòu)建閉環(huán)系統(tǒng)探索LLM在自動駕駛的環(huán)境理解和環(huán)境互動的可行性,并且發(fā)現(xiàn)其在推理和解決長尾問題上也有一定的能力。
DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model [paper][github]
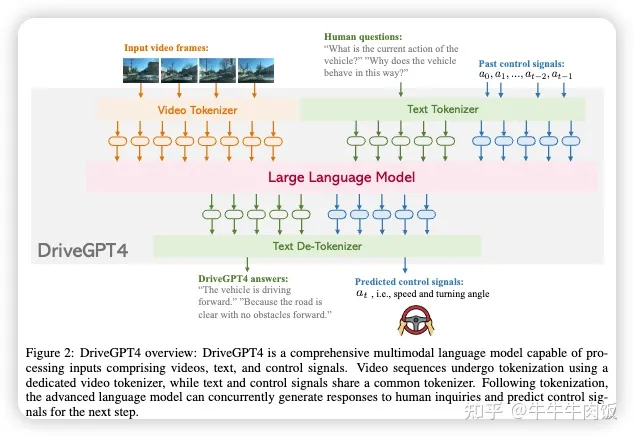
來自港大和諾亞實驗室,DriveGPT4是一個使用LLM的可解釋的端到端自動駕駛系統(tǒng),能夠解釋車輛行為并提供相應(yīng)的推理,還可以回答用戶提出的各種問題,以增強互動性。此外,DriveGPT4以端到端的方式預(yù)測車輛的低級控制信號。
DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models [paper][github]
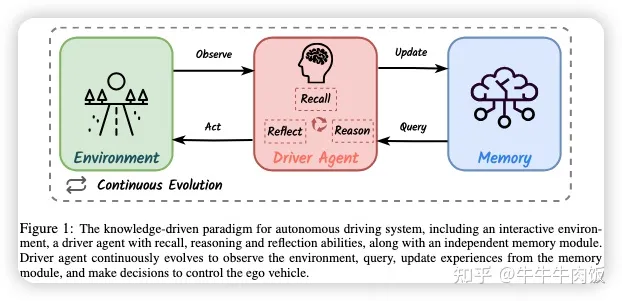
這是一個上海AI Lab提出了DiLu框架,它結(jié)合了推理和反思模塊,使系統(tǒng)能夠基于常識知識做出決策并不斷演化。大量實驗證明DiLu能夠積累經(jīng)驗,并在泛化能力上明顯優(yōu)于基于強化學(xué)習(xí)的方法。此外,DiLu能夠直接從現(xiàn)實世界的數(shù)據(jù)集中獲取經(jīng)驗,突顯了其在實際自動駕駛系統(tǒng)上的潛力。
GPT-Driver: Learning to Drive with GPT [paper][github]

這是一篇南加州大學(xué)的論文,可以將OpenAI GPT-3.5模型轉(zhuǎn)化為可靠的自動駕駛車輛運動規(guī)劃器。GPT-Driver將規(guī)劃器的輸入和輸出表示為語言標(biāo)記,并利用LLM通過坐標(biāo)位置的語言描述生成駕駛軌跡。提出了一種新穎的提示-推理-微調(diào)策略,以激發(fā)LLM的數(shù)值推理潛力。借助這一策略,LLM可以用自然語言描述高度精確的軌跡坐標(biāo),以及其內(nèi)部的決策過程。
Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving [paper][github]

這篇文章來自于Wayve, 論文中引入了一種獨特的物體級多模態(tài)LLM架構(gòu),將向量化數(shù)字模態(tài)與預(yù)訓(xùn)練的LLM相結(jié)合,以提高在駕駛情景中的上下文理解能力。除此之外論文還提供了一個包含來自1萬個駕駛情景的160,000個問答對的新數(shù)據(jù)集,與由RL代理程序收集的高質(zhì)量控制命令和由教師LLM(GPT-3.5)生成的問答對相配對。
LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving [paper][page]
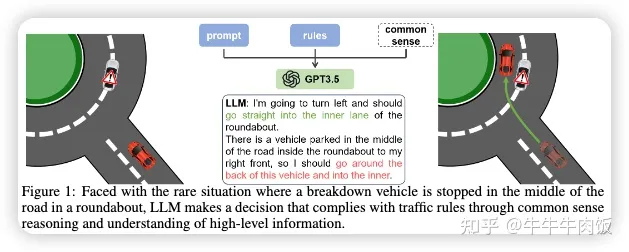
這篇文章來自于清華大學(xué)和UC Berkeley,本研究將大型語言模型(LLMs)作為復(fù)雜AD場景的決策組件,這些場景需要人類的常識理解。作者設(shè)計了認(rèn)知路徑,以使LLMs能夠進行全面的推理,并開發(fā)了將LLM決策轉(zhuǎn)化為可執(zhí)行駕駛命令的算法。通過這種方法,LLM決策可以通過引導(dǎo)參數(shù)矩陣適應(yīng)與低級控制器無縫集成。
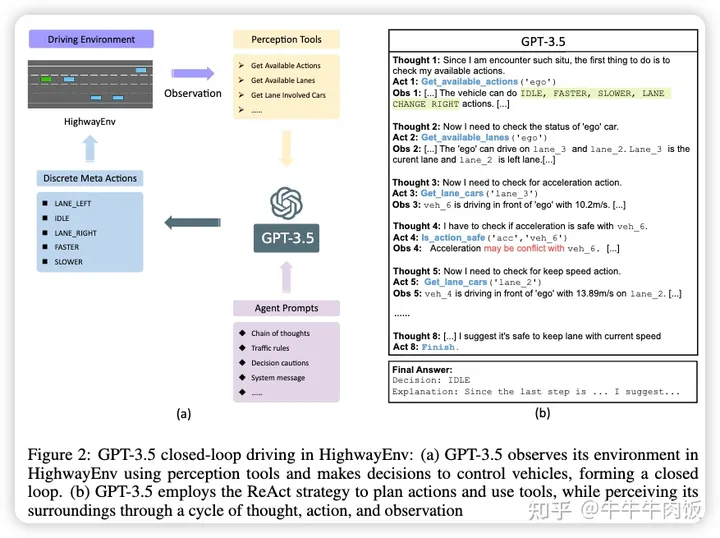
Receive, Reason, and React: Drive as You Say with Large Language Models in Autonomous Vehicles [paper]
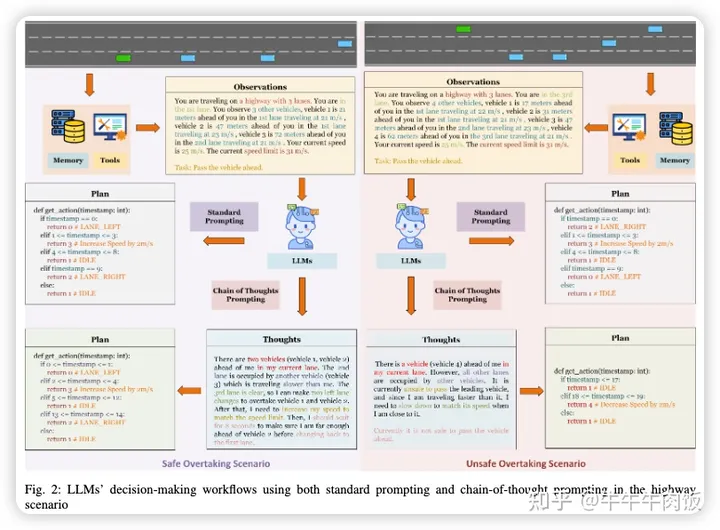
本文來自Purdue University,研究包括在HighwayEnv中進行的實驗,這是一個用于自動駕駛和戰(zhàn)術(shù)決策任務(wù)的環(huán)境集合,旨在探討LLMs在不同場景中的解釋、互動和推理能力。作者還研究了實時個性化,展示了LLMs如何基于口頭命令影響駕駛行為。論文的實證結(jié)果突顯了采用“思維鏈”提示的重大優(yōu)勢,從而改進了駕駛決策,并展示了LLMs通過持續(xù)的口頭反饋提升個性化駕駛體驗的潛力。
Drive as You Speak: Enabling Human-Like Interaction with Large Language Models in Autonomous Vehicles [paper]

本文來自Purdue University,本文主要討論如何利用大型語言模型(LLMs)來增強自動駕駛汽車的決策過程。通過將LLMs的自然語言能力和語境理解、專用工具的使用、推理與自動駕駛汽車上的各種模塊的協(xié)同作用整合在一起。
SurrealDriver: Designing Generative Driver Agent Simulation Framework in Urban Contexts based on Large Language Model [paper]
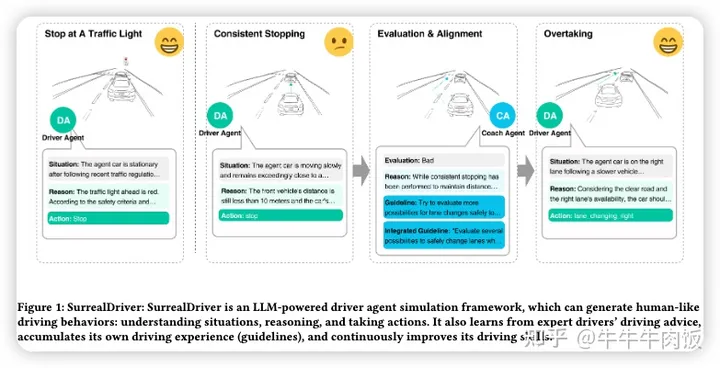
本文來自清華大學(xué),提出了一種基于大型語言模型(LLMs)的生成式駕駛代理模擬框架,能夠感知復(fù)雜的交通場景并提供逼真的駕駛操控。值得注意的是,我們與24名駕駛員進行了訪談,并使用他們對駕駛行為的詳細(xì)描述作為“思維鏈”提示,開發(fā)了一個“教練代理”模塊,該模塊可以評估和協(xié)助駕駛代理積累駕駛經(jīng)驗并培養(yǎng)類似人類的駕駛風(fēng)格。
Language-Guided Traffic Simulation via Scene-Level Diffusion [paper]
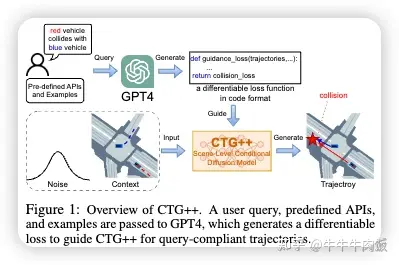
哥倫比亞大學(xué)和Nvidia聯(lián)合提出了CTG++,一種能夠受到語言指導(dǎo)的場景級條件擴散模型。開發(fā)這一模型需要解決兩個挑戰(zhàn):需要一個現(xiàn)實且可控的交通模型骨干,以及一種使用語言與交通模型進行交互的有效方法。為了解決這些挑戰(zhàn),我們首先提出了一個配備有時空變換器骨干的場景級擴散模型,用于生成現(xiàn)實且可控的交通。然后,我們利用大型語言模型(LLM)將用戶的查詢轉(zhuǎn)化為損失函數(shù),引導(dǎo)擴散模型生成符合查詢的結(jié)果。
Language Prompt for Autonomous Driving [paper][github]
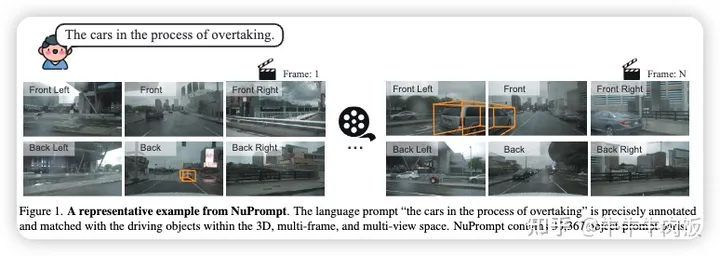
本文由北理和曠世提出,在駕駛場景中使用語言提示的進展受到了數(shù)據(jù)匹配的瓶頸問題的限制,因為匹配語言提示和實例數(shù)據(jù)的配對數(shù)據(jù)相對稀缺。為了解決這一挑戰(zhàn),本文提出了第一個針對三維、多視圖和多幀空間內(nèi)的駕駛場景的以物體為中心的語言提示集,名為NuPrompt。它通過擴展Nuscenes數(shù)據(jù)集,構(gòu)建了共計35,367個語言描述,每個描述涉及平均5.3個物體軌跡。基于新的數(shù)據(jù)集中的物體-文本配對,我們提出了一項新的基于提示的駕駛?cè)蝿?wù),即使用語言提示來預(yù)測跨視圖和幀描述的物體軌跡。
Talk2BEV: Language-Enhanced Bird's Eye View (BEV) Maps [paper][github]
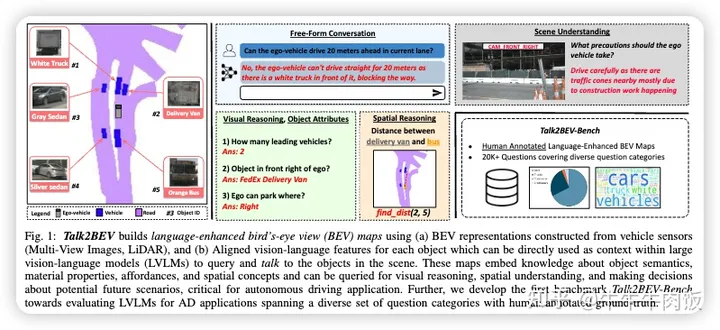
本文來自海得拉巴國際信息技術(shù)學(xué)院,Talk2BEV結(jié)合了通用語言和視覺模型的最新進展以及BEV結(jié)構(gòu)化地圖表示,消除了需要專門的任務(wù)模型。這使得一個單一系統(tǒng)能夠滿足各種自動駕駛?cè)蝿?wù),包括視覺和空間推理、預(yù)測交通參與者的意圖以及基于視覺線索進行決策
BEVGPT: Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning [paper]
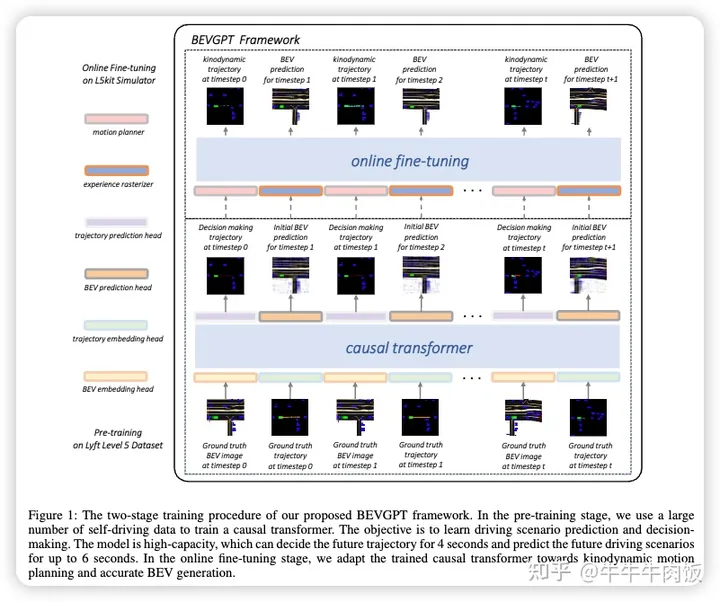
港科大提出了BEVGPT,這是一個集成了駕駛情境預(yù)測、決策和運動規(guī)劃的生成式預(yù)訓(xùn)練大模型。該模型以鳥瞰圖(BEV)圖像作為唯一的輸入源,并基于周圍的交通情景做出駕駛決策。為了確保駕駛軌跡的可行性和平穩(wěn)性,我們開發(fā)了一種基于優(yōu)化的運動規(guī)劃方法。我們在Lyft Level 5數(shù)據(jù)集上實例化了BEVGPT,并使用Woven Planet L5Kit進行了真實駕駛模擬。
DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving [paper]

GigaAI和清華攜手推出DriveDreamer,這是一個全新的世界模型,完全源自真實的駕駛場景。鑒于在復(fù)雜的駕駛場景中對世界進行建模涉及龐大的搜索空間,該文章提出利用強大的擴散模型構(gòu)建復(fù)雜環(huán)境的綜合表示。此外,論文中引入了一個兩階段訓(xùn)練流程。在初始階段,DriveDreamer深入了解結(jié)構(gòu)化的交通約束,而隨后的階段賦予其預(yù)測未來狀態(tài)的能力。DriveDreamer是第一個建立在真實世界駕駛場景中的世界模型。
MagicDrive: Street View Generation with Diverse 3D Geometry Control [paper]

MagicDrive,這是一個新穎的街景生成框架,提供多樣的3D幾何控制,包括相機位置、道路地圖和3D邊界框,還包括文本描述,通過定制的編碼策略實現(xiàn)。此外,論文的設(shè)計還包括一個跨視圖注意力模塊,確保多個相機視圖之間的一致性。使用MagicDrive實現(xiàn)了高保真的街景合成,捕捉了精細(xì)的3D幾何形狀和各種場景描述,增強了鳥瞰圖分割和3D物體檢測等任務(wù)的性能。
GAIA-1: A Generative World Model for Autonomous Driving [paper]

近期大名鼎鼎的GAIA-1('Generative AI for Autonomy')這是一個生成式世界模型,由Wayve推出,利用視頻、文本和行為輸入來生成逼真的駕駛場景,同時對自車行為和場景特征進行精細(xì)控制。我們的方法將世界建模視為一個無監(jiān)督的序列建模問題,通過將輸入映射到離散標(biāo)記,并預(yù)測序列中的下一個標(biāo)記。我們模型中的新特性包括學(xué)習(xí)高級結(jié)構(gòu)和場景動態(tài)、上下文意識、泛化能力以及對幾何形狀的理解。GAIA-1學(xué)得的表示能夠捕獲未來事件的期望,再加上其生成逼真樣本的能力,為自動駕駛技術(shù)領(lǐng)域的創(chuàng)新提供了新的可能性,實現(xiàn)了自動駕駛技術(shù)的增強和加速訓(xùn)練。
HiLM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving [paper]
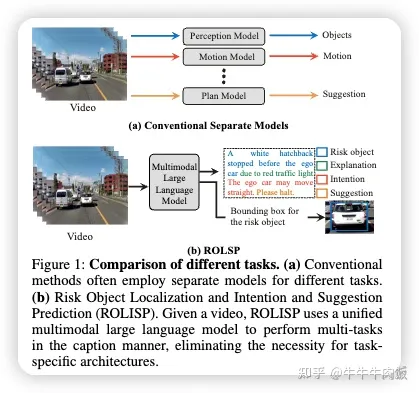
本文由港科大和諾亞實驗室提出,首次利用單一的多模態(tài)大型語言模型(MLLMs)來整合多個自動駕駛?cè)蝿?wù),即風(fēng)險目標(biāo)定位和意圖與建議預(yù)測(ROLISP)任務(wù)。ROLISP使用自然語言來同時識別和解釋風(fēng)險目標(biāo),理解自動駕駛汽車的意圖,并提供運動建議,消除了需要特定任務(wù)架構(gòu)的必要性。
Can you text what is happening? Integrating pre-trained language encoders into trajectory prediction models for autonomous driving [paper]
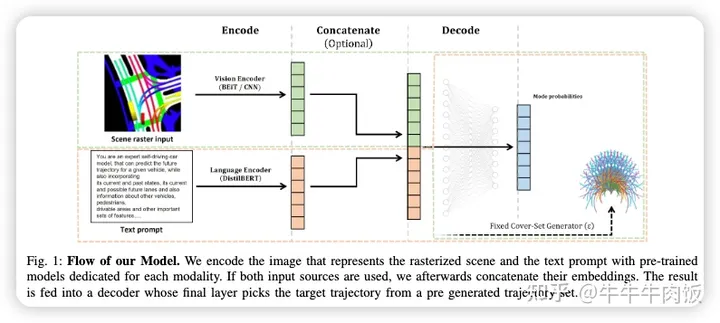
這篇文章來自自動駕駛Tier 1, Bosch,文章提出了一種新穎的基于文本的交通場景表示,并使用預(yù)訓(xùn)練的語言編碼器處理它。首先,我們展示了文本表示與傳統(tǒng)的柵格化圖像表示相結(jié)合,可以產(chǎn)生描述性的場景嵌入。
OpenAnnotate3D: Open-Vocabulary Auto-Labeling System for Multi-modal 3D Data [paper][github]

復(fù)旦大學(xué)提出了OpenAnnotate3D,這是一個開源的開放詞匯自動標(biāo)注系統(tǒng),可以自動生成用于視覺和點云數(shù)據(jù)的2D掩模、3D掩模和3D邊界框注釋。我們的系統(tǒng)整合了大型語言模型(LLMs)的思維鏈能力和視覺語言模型(VLMs)的跨模態(tài)能力。
LangProp: A Code Optimization Framework Using Language Models Applied to Driving [openreview][github]
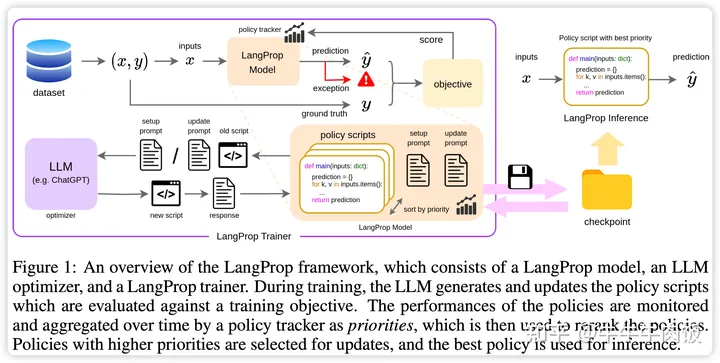
LangProp自動評估了輸入-輸出對數(shù)據(jù)集上的代碼性能,以及捕獲任何異常,并將結(jié)果反饋給LLM在訓(xùn)練循環(huán)中,使LLM可以迭代地改進其生成的代碼。通過采用度量和數(shù)據(jù)驅(qū)動的代碼優(yōu)化過程的訓(xùn)練范式,可以輕松地借鑒傳統(tǒng)機器學(xué)習(xí)技術(shù),如模仿學(xué)習(xí)、DAgger和強化學(xué)習(xí)等的發(fā)現(xiàn)。在CARLA中展示了自動代碼優(yōu)化的第一個概念驗證,證明了LangProp可以生成可解釋且透明的駕駛策略,可以以度量和數(shù)據(jù)驅(qū)動的方式進行驗證和改進。
Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion [openreview]
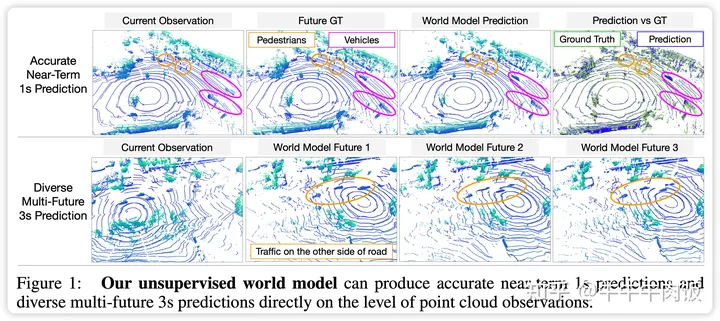
作者確定了兩個主要瓶頸原因:處理復(fù)雜和無結(jié)構(gòu)的觀測空間以及具備可擴展性的生成模型。因此,我們提出了一種新穎的世界建模方法,首先使用VQVAE對傳感器觀測進行標(biāo)記,然后通過離散擴散來預(yù)測未來。為了高效地并行解碼和去噪標(biāo)記,我們將遮蔽的生成式圖像變換器重新構(gòu)建成離散擴散框架,只需進行一些簡單的更改,結(jié)果有顯著的改進。
Planning with an Ensemble of World Models [openreview]
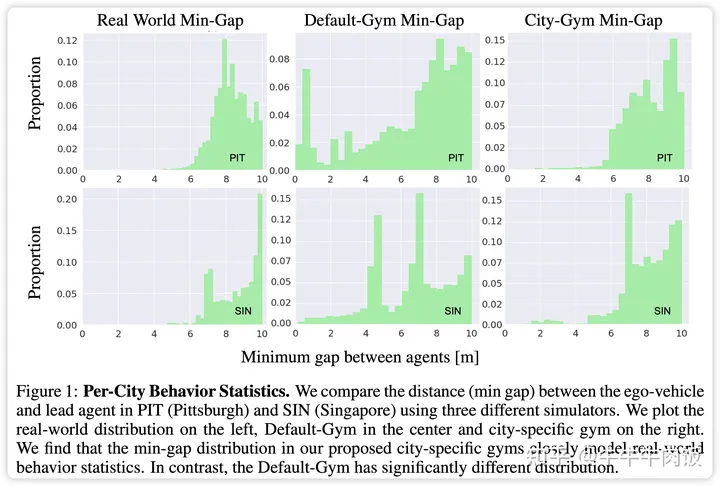
特定于城市的gym(例如波士頓-Gym和匹茲堡-Gym)來評估規(guī)劃性能。使用我們提出的gym集合來評估最先進的規(guī)劃器導(dǎo)致性能下降,這表明一個優(yōu)秀的規(guī)劃器必須適應(yīng)不同的環(huán)境。借助這一見解,我們提出了City-Driver,一種基于模型預(yù)測控制(MPC)的規(guī)劃器,它展開了適應(yīng)不同駕駛條件的城市特定世界模型。
Large Language Models Can Design Game-Theoretic Objectives for Multi-Agent Planning [openreview]
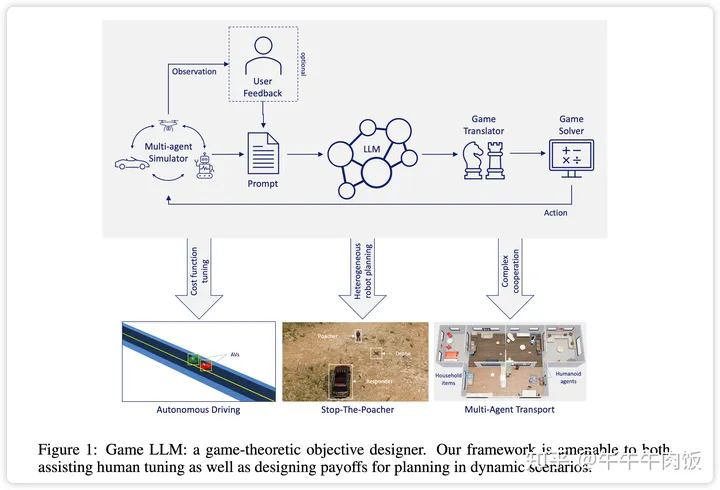
論文首先展示了更強大的LLM(如GPT-4)在調(diào)整連續(xù)目標(biāo)函數(shù)參數(shù)方面的zero-shot能力,以符合自動駕駛示例的指定高級目標(biāo)。然后,作者開發(fā)了一種規(guī)劃器,它將LLM作為矩陣游戲的設(shè)計者,用于具有離散有限動作空間的場景。在給定場景歷史、每個智能體可用的動作和高級目標(biāo)(用自然語言表達(dá))時,LLM評估與每種動作組合相關(guān)的回報。從獲得的博弈結(jié)構(gòu)中,智能體執(zhí)行Nash最優(yōu)動作,重新評估場景,并重復(fù)該過程。
TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction [paper]
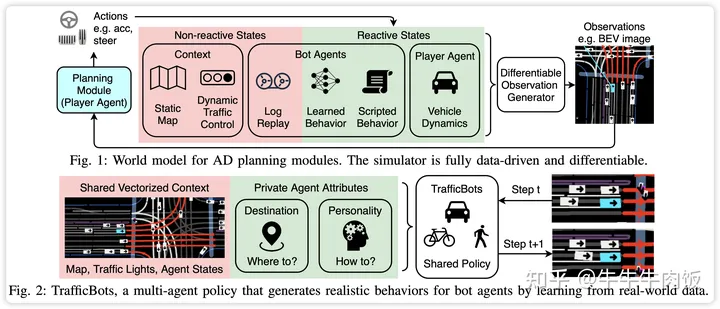
作者展示了數(shù)據(jù)驅(qū)動的交通仿真可以被構(gòu)建為一個世界模型。文章提出了TrafficBots,這是一個基于運動預(yù)測和端到端駕駛的多智能體策略,基于TrafficBots獲得了一個專門為自動駕駛車輛的規(guī)劃模塊定制的世界模型。現(xiàn)有的數(shù)據(jù)驅(qū)動交通仿真器缺乏可配置性和可擴展性。為了生成可配置的行為,對于每個智能體引入了目的地作為導(dǎo)航信息,以及一個不隨時間變化的潛在個性,指定了行為風(fēng)格。為了提高可擴展性提出了一種用于角度的位置編碼的新方案,允許所有智能體共享相同的矢量化上下文,以及基于點積注意力的架構(gòu)。
BEV-CLIP: Multi-Modal BEV Retrieval Methodology for Complex Scene in Autonomous Driving [openreview]
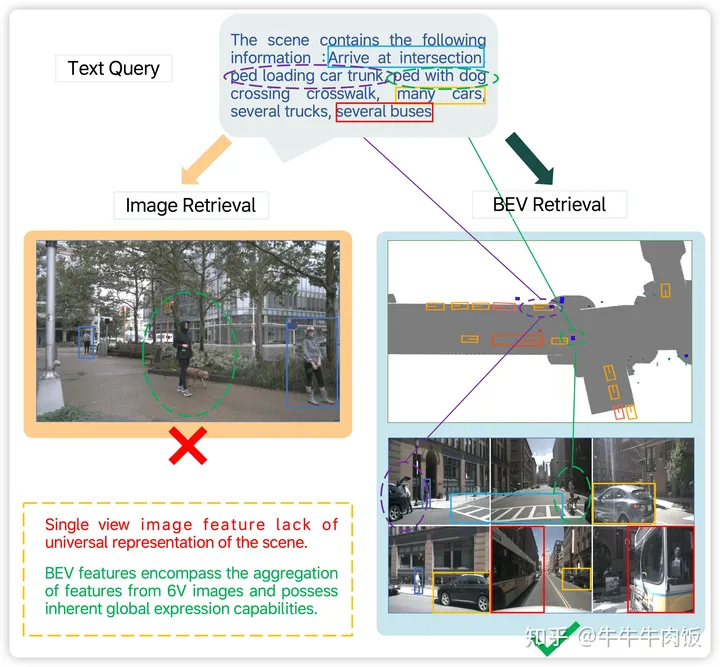
在現(xiàn)有的二維圖像檢索方法下,可能會出現(xiàn)一些場景檢索的問題,比如缺乏全局特征表示和次優(yōu)的文本檢索能力。為了解決這些問題,本文作者提出了BEV-CLIP,這是第一個利用描述性文本作為輸入以檢索相應(yīng)場景的多模態(tài)BEV檢索方法。這種方法應(yīng)用了大型語言模型(LLM)的語義特征提取能力,以便進行廣泛的文本描述的零次檢索,并結(jié)合了知識圖的半結(jié)構(gòu)信息,以提高語言嵌入的語義豐富性和多樣性。
Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research [paper][github]
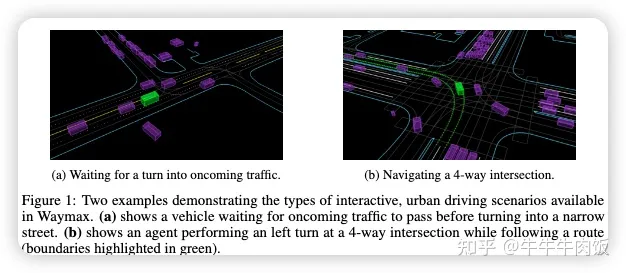
Waymo引入了Waymax,這是一種用于自動駕駛多智體場景的新型數(shù)據(jù)驅(qū)動模擬器,專為大規(guī)模模擬和測試而設(shè)計。Waymax使用已公開發(fā)布的實際駕駛數(shù)據(jù)(例如Waymo開放運動數(shù)據(jù)集)來初始化或回放各種多智體模擬場景。它完全在硬件加速器上運行,如TPU/GPU,并支持用于訓(xùn)練的圖內(nèi)模擬,使其適用于現(xiàn)代的大規(guī)模分布式機器學(xué)習(xí)工作流。
Semantic Anomaly Detection with Large Language Models [paper]
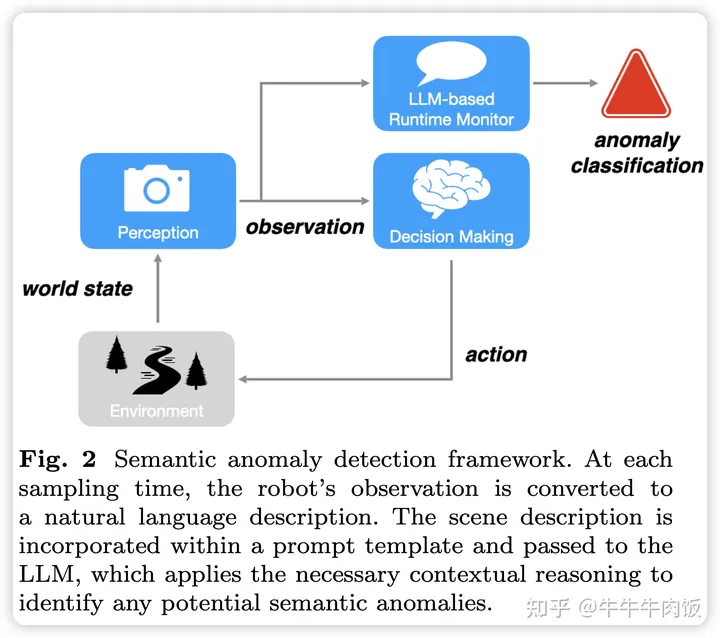
這篇論文隨著機器人獲得越來越復(fù)雜的技能并觀察到越來越復(fù)雜和多樣化的環(huán)境,邊緣案例或異常故障的威脅隨時存在。這些系統(tǒng)級故障不是由于自動駕駛系統(tǒng)堆棧的任何單個組件的故障,而是由于語義推理方面的系統(tǒng)級缺陷。這種稱之為語義異常的邊緣情況對于人類來說很容易解開,但需要具有深刻推理能力。為此,作者研究了賦予大型語言模型(LLMs)廣泛的上下文理解和推理能力,以識別這類邊緣情況,并引入了一種基于視覺策略的語義異常檢測的監(jiān)控框架。我們將這一框架應(yīng)用于自動駕駛的有限狀態(tài)機策略和物體操作的學(xué)習(xí)策略。
Driving through the Concept Gridlock: Unraveling Explainability Bottlenecks in Automated Driving [paper]
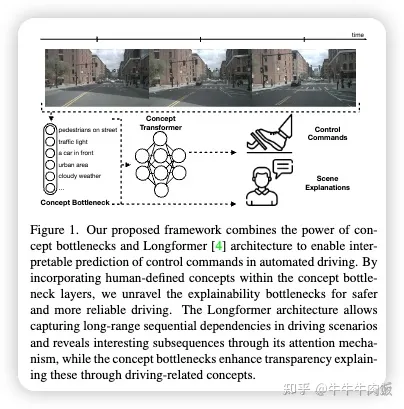
在人工輔助或自動駕駛的背景下,可解釋性模型可以幫助用戶接受和理解自動駕駛車輛所做的決策,這可以用來解釋和說明駕駛員或車輛的行為。論文中提出了一種新方法,使用概念瓶頸作為控制命令預(yù)測和用戶以及車輛行為解釋的視覺特征。作者學(xué)習(xí)了一個人可以理解的概念層,用來解釋順序駕駛場景,同時學(xué)習(xí)車輛控制命令。這種方法可以用來確定人類(或自動駕駛車輛)對于首選車距或轉(zhuǎn)向命令的改變是否受到外部刺激或偏好的改變的影響。
Drama: Joint risk localization and captioning in driving [paper]

考慮到在安全關(guān)鍵的自動化系統(tǒng)中的情境感知功能,對駕駛場景中風(fēng)險的感知以及其可解釋性對于自動駕駛和合作駕駛尤為重要。為實現(xiàn)這一目標(biāo),本文提出了一個新的研究方向,即駕駛場景中的風(fēng)險聯(lián)合定位及其以自然語言描述的風(fēng)險解釋。由于缺乏標(biāo)準(zhǔn)基準(zhǔn),作者的研究團隊收集了一個大規(guī)模數(shù)據(jù)集,名為DRAMA(帶有字幕模塊的駕駛風(fēng)險評估機制),其中包括了在日本東京收集的17,785個交互式駕駛場景。我們的DRAMA數(shù)據(jù)集包含了有關(guān)駕駛風(fēng)險的視頻和對象級問題,以及與重要對象相關(guān)的問題,以實現(xiàn)自由形式的語言描述,包括多級問題的封閉和開放式回答,可用于評估駕駛場景中的各種圖像字幕能力。
3D Dense Captioning Beyond Nouns: A Middleware for Autonomous Driving[openreview]
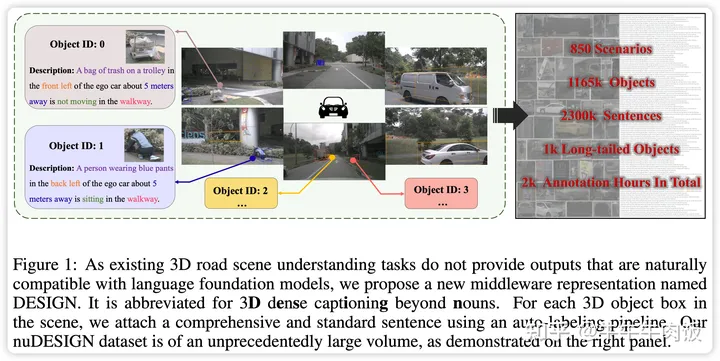
作者認(rèn)為一個主要的大語言模型很難獲得安全駕駛的障礙是缺乏將感知和規(guī)劃連接起來的綜合和標(biāo)準(zhǔn)的中間件表示。作者重新思考了現(xiàn)有中間件的局限性(例如,3D框或占用情況)并提出了超越名詞的3D密集字幕(簡稱為DESIGN)。對于每個輸入場景,DESIGN指的是一組帶有語言描述的3D邊界框。特別是,綜合的描述不僅包括這個框是什么(名詞),還包括它的屬性(形容詞),位置(介詞)和運動狀態(tài)(副詞)。我們設(shè)計了一種可擴展的基于規(guī)則的自動標(biāo)注方法來生成DESIGN的地面真實數(shù)據(jù),以確保中間件是標(biāo)準(zhǔn)的。
SwapTransformer: Highway Overtaking Tactical Planner Model via Imitation Learning on OSHA Dataset [openreview]
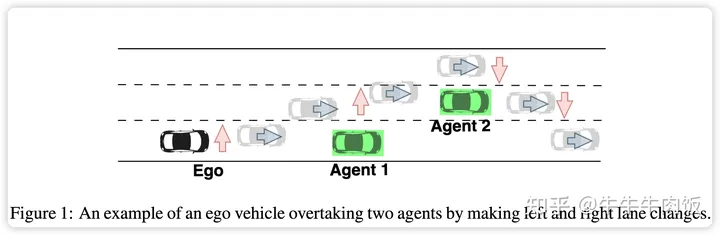
這篇論文研究了關(guān)于在高速公路情境中進行變道和超越其他較慢車輛的高級決策問題。具體來說,本文旨在改進旅行輔助功能,以實現(xiàn)對高速公路上的自動超車和變道。在模擬中收集了大約900萬個樣本,包括車道圖像和其他動態(tài)對象。這些數(shù)據(jù)構(gòu)成了"模擬高速公路上的超車"(OSHA)數(shù)據(jù)集,用于解決這一挑戰(zhàn)。為了解決這個問題,設(shè)計并實施了一種名為SwapTransformer的架構(gòu),作為OSHA數(shù)據(jù)集上的模仿學(xué)習(xí)方法。此外,提出了輔助任務(wù),如未來點和汽車距離網(wǎng)絡(luò)預(yù)測,以幫助模型更好地理解周圍環(huán)境。提出的解決方案的性能與多層感知器(MLP)和多頭自注意力網(wǎng)絡(luò)作為基線在模擬環(huán)境中進行了比較。
NuScenes-QA: A Multi-modal Visual Question Answering Benchmark for Autonomous Driving Scenario [paper][github]
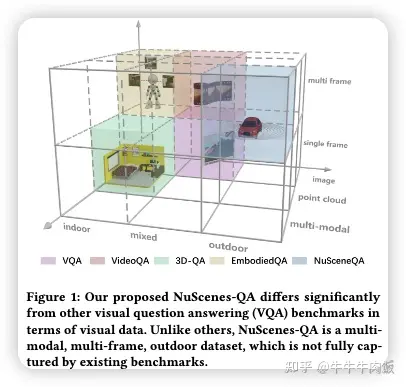
本文來自于復(fù)旦大學(xué),作者引入了一個新穎的視覺問答(VQA)任務(wù),即自動駕駛背景下的VQA任務(wù),旨在基于街景線索回答自然語言問題。與傳統(tǒng)的VQA任務(wù)相比,自動駕駛場景中的VQA任務(wù)具有更多挑戰(zhàn)。首先,原始的視覺數(shù)據(jù)是多模態(tài)的,包括由攝像機和激光雷達(dá)(LiDAR)捕獲的圖像和點云數(shù)據(jù)。其次,由于連續(xù)實時采集,數(shù)據(jù)是多幀的。第三,室外場景同時包括移動的前景和靜態(tài)的背景。現(xiàn)有的VQA基準(zhǔn)未能充分解決這些復(fù)雜性。為了填補這一差距,作者提出了NuScenes-QA,這是自動駕駛場景中的第一個VQA基準(zhǔn),包括34,000個視覺場景和460,000個問題-答案對。具體而言利用現(xiàn)有的3D檢測注釋生成場景圖,并手動設(shè)計問題模板。隨后,問題-答案對是基于這些模板自動生成的。全面的統(tǒng)計數(shù)據(jù)證明了我們的NuScenes-QA是一個平衡的大規(guī)模基準(zhǔn),具有多樣的問題格式。
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models [paper]
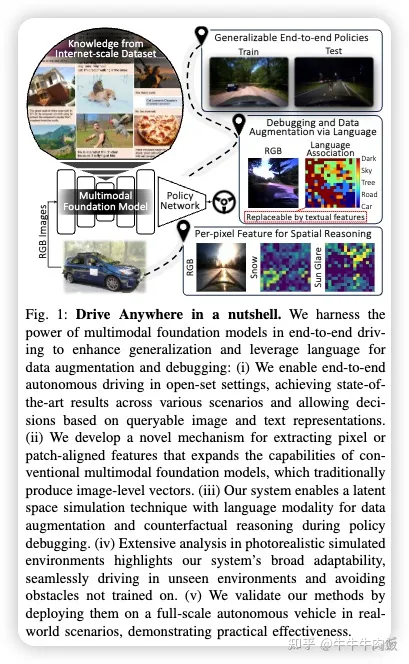
隨著自動駕駛技術(shù)的成熟,端到端方法已經(jīng)成為一種主要策略,承諾通過深度學(xué)習(xí)實現(xiàn)從感知到控制的無縫集成。然而,現(xiàn)有系統(tǒng)面臨著意想不到的開放環(huán)境和黑盒模型復(fù)雜性等挑戰(zhàn)。與此同時,深度學(xué)習(xí)的發(fā)展引入了更大的多模態(tài)基礎(chǔ)模型,提供了多模態(tài)的視覺和文本理解。在本文中,作者利用這些多模態(tài)基礎(chǔ)模型來增強自動駕駛系統(tǒng)的健壯性和適應(yīng)性,實現(xiàn)了端到端的多模態(tài)和更具解釋性的自主性,使其能夠在分布之外、端到端、多模態(tài)和更具解釋性的環(huán)境下進行操作。具體而言,作者提出了一種應(yīng)用端到端開放集(任何環(huán)境/場景)自動駕駛的方法,能夠從可通過圖像和文本查詢的表示中提供駕駛決策。為此,文中引入了一種從Transformer中提取微妙的空間(像素/補丁對齊)特征的方法,以實現(xiàn)空間和語義特征的封裝。我們的方法在多種測試中表現(xiàn)出色,同時在分布之外的情況下具有更大的健壯性,并允許通過文本進行潛在空間模擬,從而改進訓(xùn)練(通過文本進行數(shù)據(jù)增強)和策略調(diào)試。
Vision Language Models in Autonomous Driving and Intelligent Transportation Systems [paper]
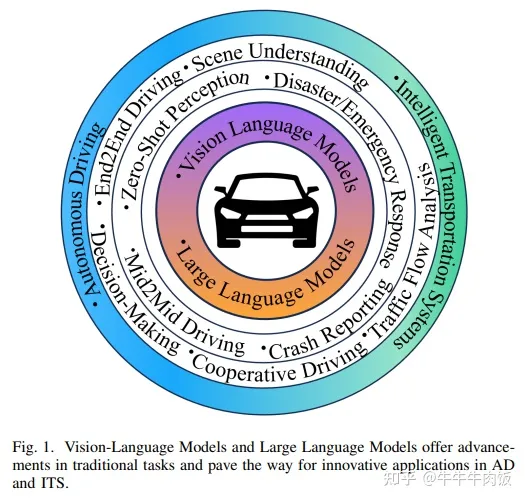
最后這篇是一篇綜述,這篇文章來自于慕尼黑工業(yè)大學(xué)的IEEE Fellow, Alois C. Knoll. 2023年是視覺-語言大模型的爆發(fā)年,其的出現(xiàn)改變了計算機領(lǐng)域的方方面面。同樣的,視覺語言大模型在自動駕駛(AD)和智能交通系統(tǒng)(ITS)領(lǐng)域的應(yīng)用引起廣泛關(guān)注。通過整合視覺語言數(shù)據(jù),車輛和交通系統(tǒng)能夠深入理解現(xiàn)實場景環(huán)境,提高駕駛安全性和效率。這篇綜述全面調(diào)研了該領(lǐng)域視覺語言大模型的各類研究進展,包括現(xiàn)有的模型和數(shù)據(jù)集。此外,該論文探討了視覺語言大模型在自動駕駛領(lǐng)域潛在的應(yīng)用和新興的研究方向,詳細(xì)討論了挑戰(zhàn)和研究空白。