開源的Gemma 模型:Google 的語言奇跡,讓你用指令調優、低秩適應和 Switch Transformer 玩轉小模型
語言是人類最重要的交流工具,也是人工智能領域最具挑戰性的研究對象。如何讓機器理解和生成自然語言,是人工智能的一個核心問題,也是人類智能的一個重要標志。近年來隨著深度學習的發展,語言模型(Language Model,LM)作為一種基于神經網絡的自然語言處理技術,取得了令人矚目的成果。
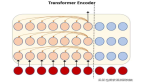
語言模型的發展經歷了從統計模型到神經網絡模型的轉變,其中最具代表性的是基于 Transformer 的大規模預訓練語言模型(Large-scale Pre-trained Language Model,LLM)。Transformer 是一種基于自注意力機制(Self-Attention Mechanism)的神經網絡架構,它可以有效地處理長距離的依賴關系,提高模型的并行性和效率。基于 Transformer 的 LLM 通過在大量的無標注文本上進行預訓練,學習到了豐富的語言知識和語義表示,然后通過在特定的下游任務上進行微調,實現了對不同領域和場景的適應。基于 Transformer 的 LLM 的典型代表有 BERT、GPT、XLNet、T5 等,它們在各種自然語言處理任務上都取得了顯著的性能提升,引領了自然語言處理的新浪潮。
基于 Transformer 的 LLM 也存在一些挑戰和局限性,主要有以下幾個方面:
1)模型規模的增長帶來了計算資源和存儲空間的巨大需求。為了提高模型的表達能力和泛化能力,基于 Transformer 的 LLM 不斷增加模型的參數數量和層數,從幾百萬到幾十億,甚至到幾萬億。這導致了模型的訓練和推理需要大量的計算資源和存儲空間,增加了模型的部署和使用的成本和難度。
2)模型的預訓練和微調過程缺乏有效的指導和反饋。基于 Transformer 的 LLM 通常使用無監督的目標函數,如掩碼語言模型(Masked Language Model,MLM)或自回歸語言模型(Autoregressive Language Model,ARLM),來進行預訓練,這些目標函數只利用了文本的局部信息,忽略了文本的整體結構和語義。而在微調過程中,模型只能根據下游任務的標簽進行調整,缺乏對模型輸出的有效指導和反饋,導致模型的輸出可能不符合用戶的期望和需求。
3)模型的泛化能力和適應能力有待提高。基于 Transformer 的 LLM 雖然在預訓練階段學習到了大量的語言知識,但是在面對不同的下游任務和領域時,仍然需要進行大量的微調,才能達到較好的性能。這意味著模型的泛化能力和適應能力有限,不能很好地處理新的或復雜的語言現象和場景。
 圖片
圖片
為了解決這些問題,Google 最近發布了一系列新的開源模型:Gemma,它們是基于用于創建 Google Gemini 模型的研究和技術構建的輕量級模型。Gemma 模型包括 2B 和 7B 兩種規模,分別有 20 億和 70 億個參數,可以用于各種自然語言處理任務,如文本生成、問答、對話和情感分析。Gemma 模型使用了一種稱為低秩適應(LoRA)的技術,可以在保持模型輸出質量的同時,大大減少微調所需的參數數量和訓練時間。Gemma 模型還使用了一種稱為指令調優(Instruction Tuning,IT)的技術,可以通過用戶提供的指令來控制模型的行為和輸出,實現更靈活和可定制的文本生成。Gemma 模型由 Kaggle 托管,用戶需要在 Kaggle 上請求訪問權限,并接受相關條款和條件。用戶還可以使用不同的后端和框架,如 JAX、Keras、PyTorch 和 Transformers 來訪問和使用 Gemma 模型。
Gartner 分析師 Chirag Dekate 表示,谷歌的新模型表明 2024 年是小語言模型(SLM) 和大語言模型的一年。
“在 GenAI 時代,企業不僅需要能夠從 LLM 創造價值,還需要能夠以較低的價格從 SLM 中創造價值,這些價值對他們來說很重要,而且可以在其數據環境中進行情境化,這變得非常重要,”德卡特說道。
Constellation Research 創始人 R.“Ray”Wang 表示,較小的語言模型使企業能夠獲得更高的精度。
01 Gemma 模型的背景
Gemma 模型的背景可以追溯到 Google Gemini 模型的研究和開發。Gemini 是 Google 在 2020 年底發布的一種新型的大規模預訓練語言模型,它具有 1012 億個參數,是當時世界上最大的語言模型。Gemini 模型的目標是實現一種通用的語言理解和生成的能力,可以用于各種自然語言處理的任務和場景,如對話、摘要、翻譯、問答等。Gemini 模型的特點是使用了一種稱為 Switch Transformer 的新型神經網絡架構,它可以動態地調整模型的大小和復雜度,以適應不同的輸入和輸出,從而提高模型的效率和靈活性。Gemini 模型還使用了一種稱為 Mixture of Experts(MoE)的技術,它可以將模型的參數分布在多個專家模塊中,從而提高模型的容量和表達能力。
Gemini 模型的研究和開發為 Google 帶來了許多新的技術和經驗,也為 Google 的其他產品和服務提供了支持和幫助。例如,Google Assistant 使用了 Gemini 模型的一部分來提升其對話和問答的能力,Google Translate 使用了 Gemini 模型的一部分來提升其翻譯的質量和速度,Google Search 使用了 Gemini 模型的一部分來提升其搜索的相關性和準確性等。然而,Gemini 模型的規模和復雜度也給 Google 帶來了一些挑戰和困難,主要有以下幾個方面:
Gemini 模型的訓練和推理需要大量的計算資源和存儲空間,超出了大多數用戶和開發者的可用范圍。Gemini 模型的訓練需要使用數千個 TPU 芯片,耗時數周,而推理需要使用數百個 TPU 芯片,耗時數秒。這意味著 Gemini 模型的使用和部署需要高昂的成本和復雜的技術,不適合普通的個人和企業。
Gemini 模型的預訓練和微調過程缺乏有效的指導和反饋,導致模型的輸出可能不符合用戶的期望和需求。Gemini 模型在預訓練階段使用了無監督的目標函數,如 MLM 或 ARLM,這些目標函數只利用了文本的局部信息,忽略了文本的整體結構和語義。而在微調過程中,模型只能根據下游任務的標簽進行調整,缺乏對模型輸出的有效指導和反饋。這導致模型的輸出可能不符合用戶的期望和需求,例如,模型可能生成不相關或不合理的文本,或者模型可能無法處理一些特定的指令或場景。
Gemini 模型的泛化能力和適應能力有待提高,不能很好地處理新的或復雜的語言現象和場景。Gemini 模型雖然在預訓練階段學習到了大量的語言知識,但是在面對不同的下游任務和領域時,仍然需要進行大量的微調,才能達到較好的性能。這意味著模型的泛化能力和適應能力有限,不能很好地處理新的或復雜的語言現象和場景,例如,模型可能無法理解一些特殊的術語或縮寫,或者模型可能無法生成一些特定的文本類型或風格。
為了解決這些問題,Google 基于 Gemini 模型的研究和技術開發了一系列新的開放模型:Gemma,它們是一種輕量級而靈活的語言模型,可以用于各種自然語言處理任務,如文本生成、問答、對話和情感分析。
Gemma 模型的創新點主要有以下幾個方面:
Gemma 模型使用一種稱為低秩適應(LoRA)的技術,可以在保持模型輸出質量的同時,大大減少微調所需的參數數量和訓練時間。LoRA 是一種基于低秩矩陣分解的技術,它可以將模型的權重矩陣分解為兩個較小的矩陣的乘積,從而降低模型的復雜度和冗余度。LoRA 可以動態地調整模型的大小和復雜度,以適應不同的任務和場景,從而提高模型的效率和靈活性。Gemma 模型使用了 LoRA 的兩種變體:LoRA-IT 和 LoRA-PT,分別用于指令調優和預訓練。LoRA-IT 可以將模型的參數數量減少 99.9%,而 LoRA-PT 可以將模型的參數數量減少 99.5%。
Gemma 模型使用一種稱為指令調優(IT)的技術,可以通過用戶提供的指令來控制模型的行為和輸出,實現更靈活和可定制的文本生成。指令是一種用于描述用戶期望和需求的自然語言表達,它可以指定模型的目標、約束、風格等。指令調優是一種基于指令的微調方法,它可以在訓練和推理時使用指令來引導模型的學習和生成,從而提高模型的質量和多樣性。Gemma 模型使用了一種特殊的標記系統,稱為 Gemma 格式,來表示對話中的角色、輪次和指令,從而實現對模型的有效控制。
Gemma 模型使用一種稱為 Switch Transformer 的新型神經網絡架構,它可以動態地調整模型的大小和復雜度,以適應不同的輸入和輸出,從而提高模型的效率和靈活性。Switch Transformer 是一種基于 Transformer 的架構,它使用了一種稱為 Mixture of Experts(MoE)的技術,它可以將模型的參數分布在多個專家模塊中,從而提高模型的容量和表達能力。Switch Transformer 還使用了一種稱為路由器(Router)的技術,它可以根據輸入的特征,動態地選擇合適的專家模塊,從而減少模型的計算開銷和存儲需求。
 圖片
圖片
圖1:與 Llama 2 和 Mistral 7B 等熱門模型相比,Gemma 在尺寸方面的優越性能設定了新標準
02 Gemma 模型的原理
Gemma 模型的原理主要涉及到三個方面:低秩適應、指令調優和 Switch Transformer。下面我們分別介紹這三個方面的原理和細節。
低秩適應
低秩適應(LoRA)是一種基于低秩矩陣分解的技術,它可以將模型的權重矩陣分解為兩個較小的矩陣的乘積,從而降低模型的復雜度和冗余度。低秩適應的基本思想是,模型的權重矩陣可以近似地表示為一個低秩的矩陣,即一個秩(Rank)遠小于矩陣維度的矩陣。低秩矩陣可以通過兩個較小的矩陣的乘積來表示,例如,一個 m x n 的矩陣 W 可以表示為一個 m x r 的矩陣 U 和一個 r x n 的矩陣 V 的乘積,即 W = UV,其中 r 是一個小于 m 和 n 的正整數,稱為矩陣的秩。這樣,我們就可以用 2mr 個參數來代替 mn 個參數,從而減少模型的參數數量和存儲空間。同時,低秩矩陣也可以減少模型的冗余度和噪聲,從而提高模型的泛化能力和穩定性。
低秩適應的一個關鍵問題是如何確定矩陣的秩,即 r 的值。如果 r 太小,那么低秩矩陣可能無法很好地近似原始矩陣,導致模型的性能下降;如果 r 太大,那么低秩矩陣可能無法很好地壓縮原始矩陣,導致模型的效率降低。因此,我們需要根據不同的任務和場景,動態地調整 r 的值,以達到最佳的平衡。Gemma 模型使用了一種稱為自適應秩(Adaptive Rank)的技術,它可以根據輸入的特征和輸出的目標,自動地選擇合適的 r 的值,從而實現模型的動態調整。具體來說,Gemma 模型使用了一種稱為自適應秩(Adaptive Rank)的技術,它可以根據輸入的特征和輸出的目標,自動地選擇合適的 r 的值,從而實現模型的動態調整。具體來說,Gemma 模型使用了一個額外的神經網絡,稱為秩預測器(Rank Predictor),它可以根據輸入的特征,如詞頻、詞性、詞義等,預測每個權重矩陣的最佳 r 的值,然后將這些值作為低秩矩陣分解的參數,從而得到低秩的權重矩陣。這樣,Gemma 模型可以根據不同的任務和場景,動態地調整模型的大小和復雜度,以達到最佳的平衡。
Gemma 模型使用了兩種不同的低秩適應的變體,分別用于指令調優和預訓練,分別稱為 LoRA-IT 和 LoRA-PT。LoRA-IT 是一種用于指令調優的低秩適應方法,它可以將模型的參數數量減少 99.9%,從 20 億或 70 億減少到 130 萬或 450 萬。LoRA-IT 的主要思想是,將模型的權重矩陣分解為兩個部分:一個固定的原始權重矩陣,和一個可訓練的低秩矩陣,然后將這兩個部分相加,得到最終的權重矩陣。這樣,模型可以保留原始權重矩陣的信息,同時通過低秩矩陣進行微調,以適應不同的指令。LoRA-PT 是一種用于預訓練的低秩適應方法,它可以將模型的參數數量減少 99.5%,從 20 億或 70 億減少到 1 億或 3.5 億。LoRA-PT 的主要思想是,將模型的權重矩陣分解為兩個部分:一個固定的低秩矩陣,和一個可訓練的殘差矩陣,然后將這兩個部分相加,得到最終的權重矩陣。這樣,模型可以利用低秩矩陣進行預訓練,同時通過殘差矩陣進行微調,以適應不同的任務。
指令調優
指令調優(IT)是一種基于指令的微調方法,它可以通過用戶提供的指令來控制模型的行為和輸出,實現更靈活和可定制的文本生成。指令是一種用于描述用戶期望和需求的自然語言表達,它可以指定模型的目標、約束、風格等。例如,用戶可以提供以下幾種類型的指令:
- 任務指令,用于指定模型要完成的任務,如“寫一首詩”、“回答這個問題”、“寫一篇文章”等。
- 內容指令,用于指定模型要生成的內容,如“關于春天的”、“包含這些關鍵詞的”、“基于這個故事的”等。
- 風格指令,用于指定模型要生成的風格,如“幽默的”、“正式的”、“押韻的”等。
- 約束指令,用于指定模型要遵守的約束,如“不超過 100 個詞”、“不包含敏感詞”、“不抄襲”等。
指令調優的主要思想是,將用戶提供的指令作為模型的輸入的一部分,從而引導模型的學習和生成,使模型的輸出符合用戶的期望和需求。指令調優的過程分為兩個階段:訓練階段和推理階段。在訓練階段,模型使用一些帶有指令和標簽的樣本進行微調,學習如何根據不同的指令生成不同的文本。在推理階段,模型根據用戶提供的指令和輸入,生成相應的文本。為了實現指令調優,Gemma 模型使用了一種特殊的標記系統,稱為 Gemma 格式,來表示對話中的角色、輪次和指令。Gemma 格式使用四種特殊的控制令牌:<start_of_turn>、<end_of_turn>、user 和 model,以及一些可選的輔助令牌,如 <start_of_response> 和 <end_of_response>。Gemma 格式的示例是:
<start_of_turn>user Write a poem about spring<end_of_turn> <start_of_turn>model Spring is here, the flowers bloom The birds sing, the bees zoom The sun shines, the sky is blue Spring is here, and so are you<end_of_turn>
Switch Transformer
Switch Transformer 是一種基于 Transformer 的新型神經網絡架構,它可以動態地調整模型的大小和復雜度,以適應不同的輸入和輸出,從而提高模型的效率和靈活性。Switch Transformer 的主要特點是使用了一種稱為 Mixture of Experts(MoE)的技術,它可以將模型的參數分布在多個專家模塊中,從而提高模型的容量和表達能力。MoE 是一種基于集成學習的技術,它可以將多個不同的模型組合在一起,形成一個更強大的模型。MoE 的基本思想是,不同的模型可以專注于不同的子任務或子領域,從而提高模型的專業性和多樣性。MoE 的一個關鍵問題是如何將輸入分配給不同的模型,即如何選擇合適的專家。Switch Transformer 使用了一種稱為路由器(Router)的技術,它可以根據輸入的特征,動態地選擇合適的專家模塊,從而減少模型的計算開銷和存儲需求。路由器是一個額外的神經網絡,它可以根據輸入的特征,如詞頻、詞性、詞義等,預測每個專家模塊的權重,然后根據這些權重,將輸入分配給一個或多個專家模塊,從而得到最終的輸出。
Switch Transformer 的一個優點是,它可以動態地調整模型的大小和復雜度,以適應不同的輸入和輸出,從而提高模型的效率和靈活性。例如,對于一些簡單的輸入,如常見的詞或短語,Switch Transformer 可以只使用少數的專家模塊,從而節省計算資源和時間;而對于一些復雜的輸入,如罕見的詞或長句,Switch Transformer 可以使用更多的專家模塊,從而提高模型的表達能力和質量。Switch Transformer 的另一個優點是,它可以提高模型的容量和表達能力,從而提高模型的泛化能力和適應能力。例如,對于一些新的或復雜的語言現象和場景,Switch Transformer 可以利用不同的專家模塊,從而提高模型的專業性和多樣性。

圖2:與類似大小的開放模型相比,Gemma 7B在不同功能下的語言理解和生成性能。我們將標準的學術基準評估按能力分組,并對各自的得分進行平均;(詳見技術文檔表6)
03 Gemma 模型的應用和展望
Gemma 模型是一種強大而靈活的語言模型,可以用于各種自然語言處理任務,如文本生成、問答、對話和情感分析。
文本生成
文本生成是指根據一定的輸入,自動地生成連貫的文本的任務,它可以用于各種場景,如創作、教育、娛樂、商業等。Gemma 模型可以根據用戶提供的指令和輸入,生成不同的文本類型和風格,如詩歌、故事、代碼、文章、歌詞等。Gemma 模型的優勢是,它可以通過指令調優,實現對文本生成的靈活和可定制的控制,從而滿足用戶的不同期望和需求。例如,用戶可以指定文本的主題、內容、長度、風格、約束等,從而得到更符合自己的意愿的文本。Gemma 模型的另一個優勢是,它可以通過低秩適應,實現對文本生成的高效和快速的微調,從而適應不同的任務和場景。例如,用戶可以在不同的平臺和框架上,使用不同的后端和設備,快速地訪問和使用 Gemma 模型,從而提高文本生成的效率和便利性。
問答
問答是指根據用戶提出的問題,自動地給出相關的答案的任務,它可以用于各種領域,如科學、歷史、文化、生活等。Gemma 模型可以根據用戶提出的問題,生成簡潔而準確的答案,或者提供相關的信息和資源,以幫助用戶解決問題。Gemma 模型的優勢是,它可以利用預訓練階段學習到的大量的語言知識和語義表示,從而提高問答的質量和準確性。例如,Gemma 模型可以理解不同的問題類型和難度,從而給出不同的答案格式和詳細程度。Gemma 模型的另一個優勢是,它可以利用指令調優,實現對問答的靈活和可定制的控制,從而滿足用戶的不同期望和需求。例如,用戶可以指定問題的領域、范圍、來源、語言等,從而得到更符合自己的意愿的答案。
對話
對話是指根據用戶和模型之間的交互,自動地生成連貫的對話的任務,它可以用于各種目的,如咨詢、娛樂、教育、社交等。Gemma 模型可以根據用戶和模型之間的交互,生成自然而有趣的對話,或者提供相關的服務和建議,以增強用戶的體驗和滿意度。Gemma 模型的優勢是,它可以利用預訓練階段學習到的大量的語言知識和語義表示,從而提高對話的質量和流暢性。例如,Gemma 模型可以理解不同的對話類型和場景,從而給出不同的對話策略和風格。Gemma 模型的另一個優勢是,它可以利用指令調優,實現對對話的靈活和可定制的控制,從而滿足用戶的不同期望和需求。例如,用戶可以指定對話的目的、主題、角色、情感等,從而得到更符合自己的意愿的對話。
情感分析
情感分析是指根據用戶提供的文本,自動地判斷文本的情感傾向和強度的任務,它可以用于各種應用,如評論、反饋、輿情、推薦等。Gemma 模型可以根據用戶提供的文本,生成簡潔而準確的情感分析結果,或者提供相關的建議和反饋,以幫助用戶了解和改善自己的情感狀態。Gemma 模型的優勢是,它可以利用預訓練階段學習到的大量的語言知識和語義表示,從而提高情感分析的質量和準確性。例如,Gemma 模型可以理解不同的文本類型和風格,從而給出不同的情感標簽和分數。Gemma 模型的另一個優勢是,它可以利用指令調優,實現對情感分析的靈活和可定制的控制,從而滿足用戶的不同期望和需求。例如,用戶可以指定文本的領域、范圍、來源、語言等,從而得到更符合自己的意愿的情感分析結果。
Gemma 模型是一種強大而靈活的語言模型,它可以用于各種自然語言處理任務,如文本生成、問答、對話和情感分析。Gemma 模型的創新點主要有以下幾個方面:低秩適應、指令調優和 Switch Transformer。低秩適應是一種基于低秩矩陣分解的技術,它可以在保持模型輸出質量的同時,大大減少微調所需的參數數量和訓練時間。指令調優是一種基于指令的微調方法,它可以通過用戶提供的指令來控制模型的行為和輸出,實現更靈活和可定制的文本生成。Switch Transformer 是一種基于 Transformer 的新型神經網絡架構,它可以動態地調整模型的大小和復雜度,以適應不同的輸入和輸出,從而提高模型的效率和靈活性。Gemma 模型的原理主要涉及到三個方面:低秩適應、指令調優和 Switch Transformer。低秩適應的基本思想是,將模型的權重矩陣分解為兩個較小的矩陣的乘積,從而降低模型的復雜度和冗余度。指令調優的主要思想是,將用戶提供的指令作為模型的輸入的一部分,從而引導模型的學習和生成,使模型的輸出符合用戶的期望和需求。Switch Transformer 的主要特點是使用了一種稱為 Mixture of Experts(MoE)的技術,它可以將模型的參數分布在多個專家模塊中,從而提高模型的容量和表達能力。Gemma 模型的應用和展望主要有以下幾個方面:文本生成、問答、對話和情感分析。文本生成是指根據一定的輸入,自動地生成連貫的文本的任務,它可以用于各種場景,如創作、教育、娛樂、商業等。問答是指根據用戶提出的問題,自動地給出相關的答案的任務,它可以用于各種領域,如科學、歷史、文化、生活等。對話是指根據用戶和模型之間的交互,自動地生成連貫的對話的任務,它可以用于各種目的,如咨詢、娛樂、教育、社交等。Gemma 模型可以根據用戶和模型之間的交互,生成自然而有趣的對話,或者提供相關的服務和建議,以增強用戶的體驗和滿意度。情感分析是指根據用戶提供的文本,自動地判斷文本的情感傾向和強度的任務,它可以用于各種應用,如評論、反饋、輿情、推薦等。Gemma 模型可以根據用戶提供的文本,生成簡潔而準確的情感分析結果,或者提供相關的建議和反饋,以幫助用戶了解和改善自己的情感狀態。
Gemma 模型是一種強大而靈活的語言模型,它可以用于各種自然語言處理任務,如文本生成、問答、對話和情感分析。Gemma 模型的創新點、原理、應用和展望,都體現了 Google 在人工智能領域的最新進展和創新,也為用戶和開發者提供了更多的選擇和機會。Gemma 模型的優勢在于,它可以通過低秩適應、指令調優和 Switch Transformer,實現對模型的動態調整、靈活控制和高效運行,從而提高模型的性能和質量,滿足用戶的不同期望和需求。Gemma 模型的挑戰在于,它需要在保證模型的通用性和泛化能力的同時,適應不同的任務和場景,處理不同的語言現象和場景,從而提高模型的專業性和多樣性。Gemma 模型的前景在于,它可以通過不斷的研究和開發,優化模型的架構和技術,擴展模型的應用和領域,從而提高模型的影響力和價值。
總之,Gemma 模型是一種強大而靈活的語言模型,它可以用于各種自然語言處理任務,如文本生成、問答、對話和情感分析。Gemma 模型的創新點、原理、應用和展望,都值得我們深入了解和使用。Gemma 模型不僅是 Google 在人工智能領域的一項重要貢獻,也是我們在語言理解和生成方面的一次重要探索。(END)
參考資料:
1.https://ai.google.dev/gemma/docs
2.https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf