













中國如何復刻Sora,華人團隊長文解構!996 OpenAI研究員:Sora是視頻GPT-2時刻
今天,這張圖在AI社區熱轉。
它列舉了一眾文生視頻模型的誕生時間、架構和作者機構。
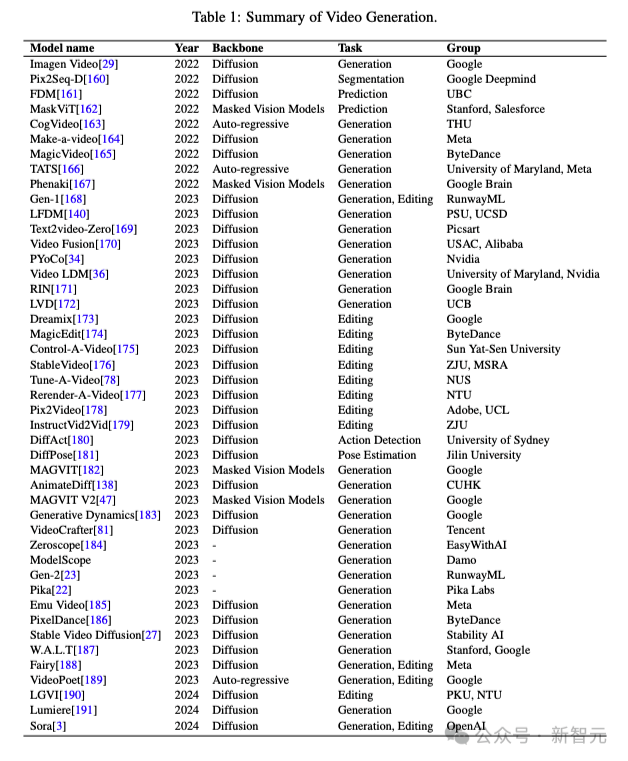
毫不意外,谷歌依然是視頻模型開山之作的作者。不過如今AI視頻的聚光燈,全被Sora搶去了。

同時,自曝996作息時間表的OpenAI研究員Jason Wei表示——
「Sora是一個里程碑,代表著視頻生成的GPT-2時刻。」
對于文字生成領域,GPT-2無疑是一個分水嶺。2018年GPT-2的推出,標志著能夠生成連貫、語法正確的文本段落的新時代。
當然,GPT-2也難以完成一篇完整無誤的文章,會出現邏輯不一致或捏造事實的情況。但是,它為后續的模型發展奠定了基礎。
在不到五年內,GPT-4已經能夠執行串聯思維這種復雜任務,或者寫出一篇長文章,過程中并不會捏造事實。
而今天,Sora已經也意味著這樣的時刻。

它能創作出既有藝術感又逼真的短視頻。雖然還不能創作出長達40分鐘的電視劇,但角色的一致性和故事性已經非常引人入勝!
Jason Wei相信,在Sora以及未來的視頻生成模型中,保持長期一致性、近乎完美的逼真度、創作有深度的故事情節這些能力,都會逐漸成型。

Sora會顛覆好萊塢嗎?它離電影大片還有多遠?
好萊塢知名導演Tyler Perry在看到Sora生成的視頻后,大為震驚,決定撤掉自己亞特蘭大工作室耗資8億美元的擴建計劃。
因為以后拍攝的大片中,可能不需要找取景地,或者搭建實景了。

所以,Sora會顛覆電影產業嗎?Jason Wei表示,它就像現在的GPT-4一樣,可以作為一種輔助工具提升作品質量,所以距離專業的電影制作還有一段距離。
而現在,視頻和文本的最大區別就是,前者的信息密度較低,所以在視頻推理等技能的學習上,就會需要大量的算力和數據。
因此,高質量視頻數據的競爭會非常激烈!就像現在各家都在爭搶高質量的文本數據集。


另外,將視頻與其他信息模式結合起來,作為學習過程的輔助信息將極為關鍵。
并且在未來,擁有視頻處理經驗的AI研究人員會變得非常搶手!不過,他們也需要像傳統的自然語言處理研究者那樣,適應新的技術發展趨勢。
沒有中間物理模型,但已具備革命性
OpenAI的TikTok賬號,還在不斷放出Sora的新作品。
Sora離好萊塢大片距離還有多遠?讓我們來看看這個電影中經常出現的場景——瓢潑大雨中,一輛車在夜色中飛速穿過城市街道。

A super car driving through city streets at night with heavy rain everywhere, shot from behind the car as it drives
再比如,Sora生成的工地上,叉車、挖掘機、腳手架和建筑工人們也都十分逼真。
并且,它還拍出了微型攝影的效果,讓一切都看起來像一個縮影。

當然,仔細看,畫面還會存在一些問題。
比如一個人會突然分裂成好幾個人。

或者,一個人忽然變成了另一個。

AI公司創始人swyx總結說,根本原因還是因為Sora沒有中間物理模型,這完全是LeCun所提世界模型的對立面。

不過,它依然為電影制作流程創造了質的飛躍,大大降低了成本。
雖然Runway可以實現類似功能,但Sora將一切都提升到了一個新的水平。
以下是Sora和Pika、Runway Gen-2、AnimateDiff和LeonardoAI的比較。




人人都能拍自己的電影
在不久的將來,或許我們每個人都可以在幾分鐘內生成自己的電影了。
比如,我們可以用ChatGPT幫忙寫出劇本,然后用Sora進行文字轉視頻。在未來,Sora一定會突破60s的時間限制。

想象一下,在你的腦海里拍出一部從未存在過的電影,是什么感覺
或者,我們可以用Dall-E或者Midjourney生成圖像,然后用Sora生成視頻。

D-ID可以讓角色的嘴部、身體動作和所說的臺詞保持一致。

此前風靡全網的《哈利波特》巴黎世家時尚大片
ElevenLabs,可以為視頻中的角色配音,增強視頻的情感沖擊力,創造視覺和聽覺敘事的無縫融合。
做自己的大片,就是這么簡單!
可惜的是,Sora的訓練成本大概要千萬美元級別。
去年ChatGPT發布后,一下子涌現出千模大戰的盛況。而這次Sora距離誕生已有半個月了,各家公司仍然毫無動靜。
中國公司該如何復刻Sora?
恰恰在最近,華人團隊也發布了非常詳細的Sora分析報告,或許能給這個問題一些啟發。
華人團隊逆向工程分析Sora
最近,來自理海大學的華人團隊和微軟副總裁高劍峰博士,聯合發布了一篇長達37頁的分析論文。
通過分析公開的技術報告和對模型的逆向工程研究,全面審視了Sora的開發背景、所依賴的技術、其在各行業的應用前景、目前面臨的挑戰,以及文本轉視頻技術的未來趨勢。
其中,論文主要針對Sora的開發歷程和構建這一「虛擬世界模擬器」的關鍵技術進行了研究,并深入探討了Sora在電影制作、教育、營銷等領域的應用潛力及其可能帶來的影響。

論文地址:https://arxiv.org/abs/2402.17177
項目地址:https://github.com/lichao-sun/SoraReview
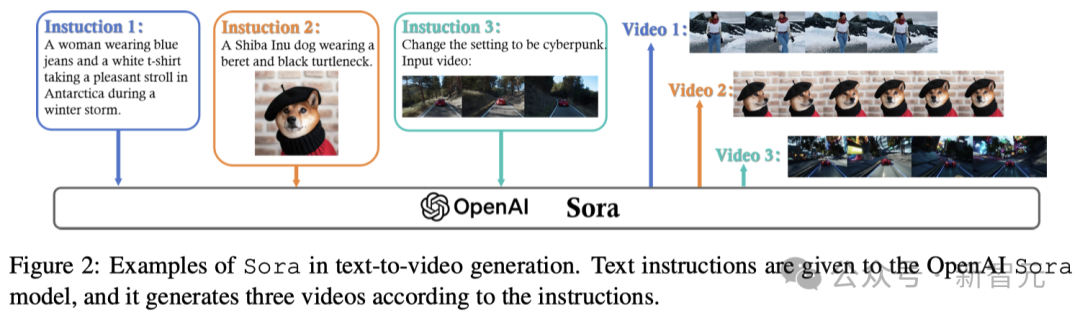
如圖2所示,Sora能夠表現出精準地理解和執行復雜人類指令的能力。
而在制作能夠細致展現運動和互動的長視頻方面,Sora也取得了長足的進展,突破了以往視頻生成技術在視頻長度和視覺表現上的限制。這種能力標志著AI創意工具的重大飛躍,使得用戶能將文字敘述轉化為生動的視覺故事。
研究人員認為,Sora之所以能達到這種高水平,不僅是因為它能處理用戶輸入的文本,還因為它能理解場景中各個元素復雜的相互關系。
如圖3所示,過去十年里,生成式計算機視覺(CV)技術的發展路徑十分多樣,尤其是在Transformer架構成功應用于自然語言處理(NLP)之后,變化顯著。
研究人員通過將Transformer架構與視覺組件相結合,推動了其在視覺任務中的應用,比如開創性的視覺Transformer(ViT)和Swin Transformer。
與此同時,擴散模型在圖像與視頻生成領域也取得了突破,它們通過U-Net技術將噪聲轉化為圖像,展示了數學上的創新方法。
從2021年開始,AI領域的研究重點,便來到了那些能夠理解人類指令的語言和視覺生成模型,即多模態模型。
隨著ChatGPT的發布,我們在2023年看到了諸如Stable Diffusion、Midjourney、DALL-E 3等商業文本到圖像產品的涌現。
然而,由于視頻本身具有的時間復雜性,目前大多數生成工具僅能制作幾秒鐘的短視頻。
在這一背景下,Sora的出現象征著一個重大突破——它是第一個能夠根據人類指令生成長達一分鐘視頻的模型,其意義可與ChatGPT在NLP領域的影響相媲美。
如圖4所示,Sora的核心是一個可以靈活地處理不同維度數據的Diffusion Transformer,其主要由三個部分組成:
1. 首先,時空壓縮器會把原始視頻轉映射到潛空間中。
2. 接著,視覺Transformer(ViT)模型會對已經被分詞的潛表征進行處理,并輸出去除噪聲后的潛表征。
3. 最后,一個與CLIP模型類似的系統根據用戶的指令(已經通過大語言模型進行了增強)和潛視覺提示,引導擴散模型生成具有特定風格或主題的視頻。在經過多次去噪處理之后,會得到生成視頻的潛表征,然后通過相應的解碼器映射回像素空間。

數據預處理
- 可變的持續時間、分辨率和高寬比
如圖5所示,Sora的一大特色是它能夠處理、理解并生成各種大小的視頻和圖片,從寬屏的1920x1080p視頻到豎屏的1080x1920p視頻,應有盡有。

如圖6所示,與那些僅在統一裁剪的正方形視頻上訓練的模型相比,Sora制作的視頻展示了更好的畫面布局,確保視頻場景中的主體被完整捕捉,避免了因正方形裁剪而造成的畫面有時被截斷的問題。

Sora對視頻和圖片特征的精細理解和保留,在生成模型領域是一個重大的進步。
它不僅展現了生成更真實和吸引人的視頻的可能性,還突出了訓練數據的多樣性對生成式AI取得高質量結果的重要性。
- 統一的視覺表征
為了有效處理各種各樣的視覺輸入,比如不同長度、清晰度和畫面比例的圖片和視頻,一個重要的方法是把這些視覺數據轉換為統一的表征。這樣做還有利于對生成模型進行大規模的訓練。
具體來說,Sora首先將視頻壓縮到「低維潛空間」,然后再將表征分解成「時空patches」。
- 視頻壓縮網絡
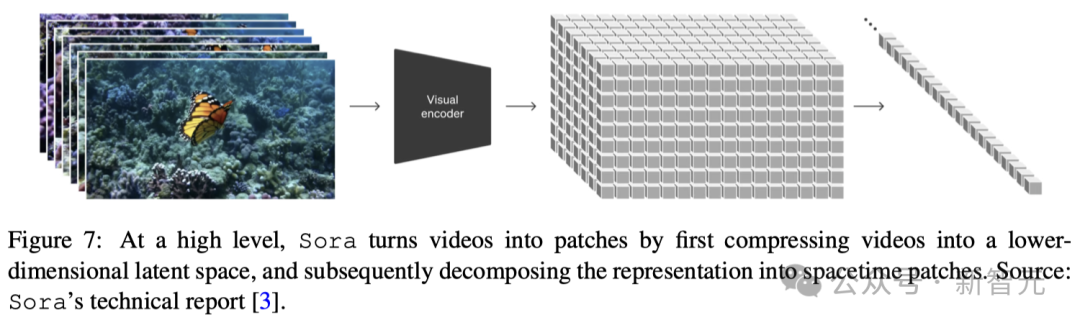
如圖7所示,Sora的視頻壓縮網絡(或視覺編碼器)的目標是降低輸入數據的維度,并輸出經過時空壓縮的潛表征。
技術報告中的參考文獻顯示,這種壓縮技術是VAE或矢量量化-VAE(VQ-VAE)基礎上的。然而,根據報告,如果不進行圖像的大小調整和裁剪,VAE很難將不同尺寸的視覺數據映射到一個統一且大小固定的潛空間中。
針對這個問題,研究人員探討了兩種可能的技術實現方案:
1. 空間patches壓縮
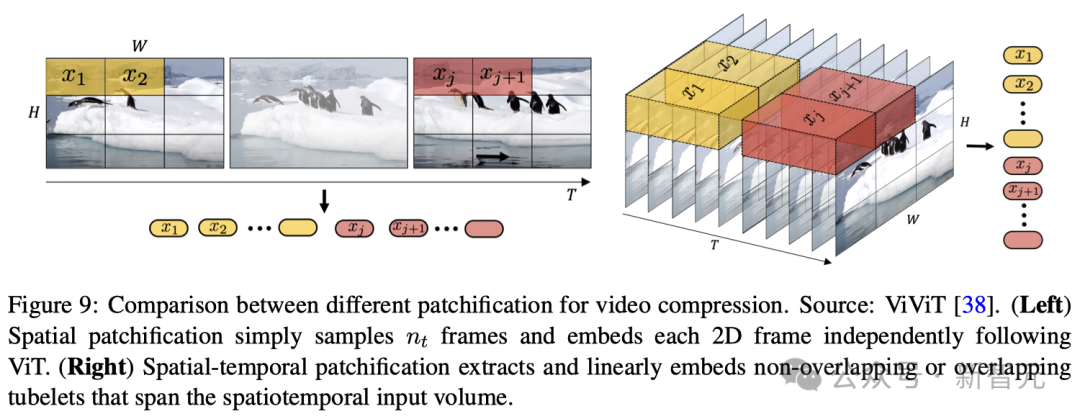
這一過程需要將視頻幀轉換成固定大小的patches,與ViT和MAE模型采用的方法相似(如圖8所示),然后再將其編碼到潛空間中。
通過這種方式,模型可以高效地處理具有不同分辨率和寬高比的視頻,因為它能通過分析這些patches來理解整個視頻幀的內容。接下來,這些空間Token會按時間順序排列,形成空間-時間潛表征。

2. 空間-時間patches壓縮
這種技術包含了視頻數據的空間和時間維度,不僅考慮了視頻畫面的靜態細節,還關注了畫面之間的運動和變化,從而全面捕捉視頻的動態特性。利用三維卷積是實現這種整合的直接而有效的方法
- 潛空間patches
在壓縮網絡部分還有一個關鍵問題:在將patches送入Diffusion Transformer的輸入層之前,如何處理潛空間維度的變化(即不同視頻類型的潛特征塊或patches的數量)。
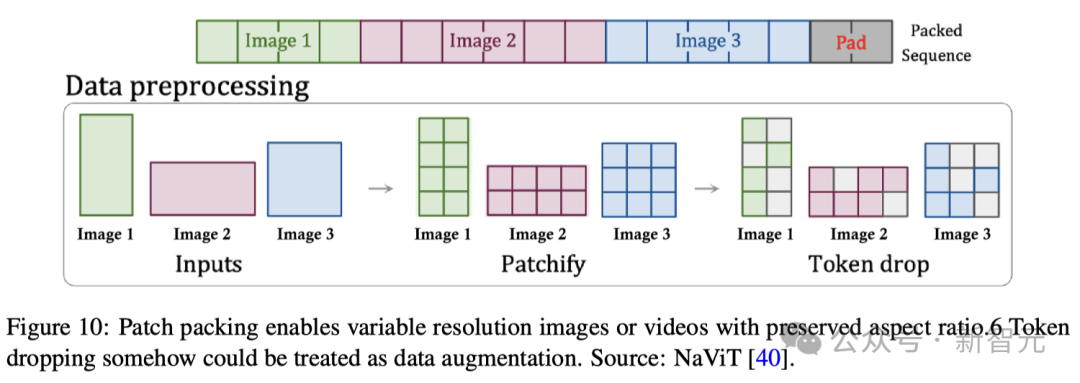
根據Sora的技術報告和相應的參考文獻,patch n' pack(PNP)很可能是一種解決方案。
如圖10所示,PNP將來自不同圖像的多個patches打包在一個序列中。
在這里,patch化和token嵌入步驟需要在壓縮網絡中完成,但Sora可能會像Diffusion Transformer那樣,進一步將潛在的patch化為Transformer token。
- Diffusion Transformer
建模
- 圖像Diffusion Transformer
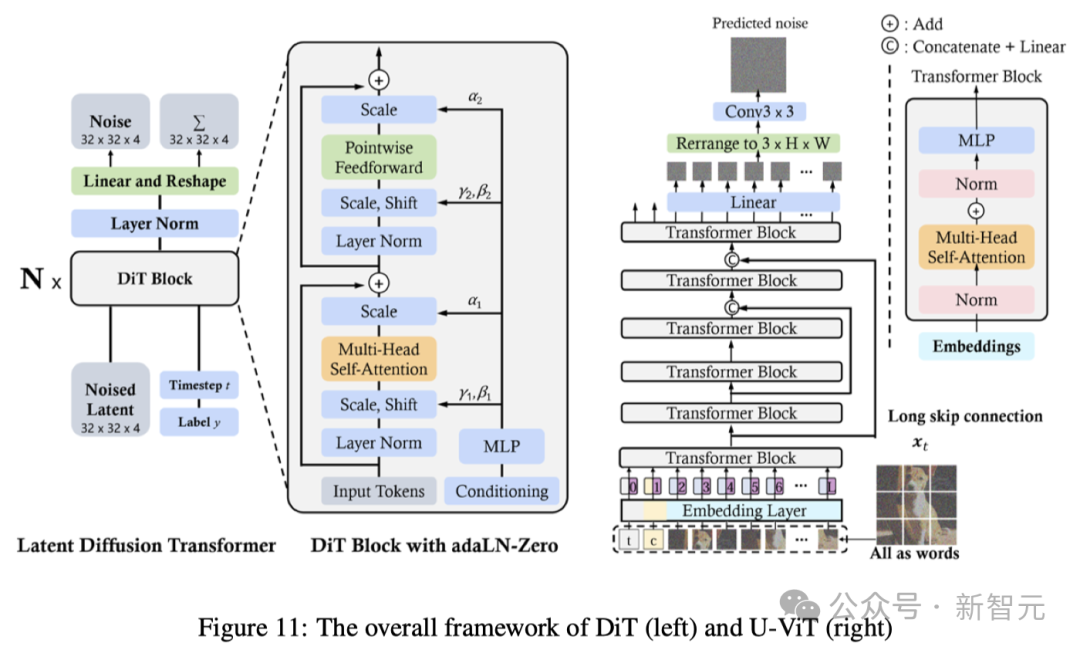
DiT和U-ViT是最早將視覺Transformers用于潛在擴散模型的工作之一。與ViT一樣,DiT也采用多頭自注意力層和點卷積前饋網絡,交錯一些層歸一化和縮放層。
此外,DiT還通過自適應層歸一化(AdaLN)并增加了一個額外的MLP層進行零初始化,這樣初始化每個殘差塊為恒等函數,從而極大地穩定了訓練過程。
U-ViT將所有輸入,包括時間、條件和噪聲圖像patches,都視為token,并提出了淺層和深層Transformer層之間的長跳躍連接。結果表明,U-ViT在圖像和文本到圖像生成中取得了破紀錄的FID分數。
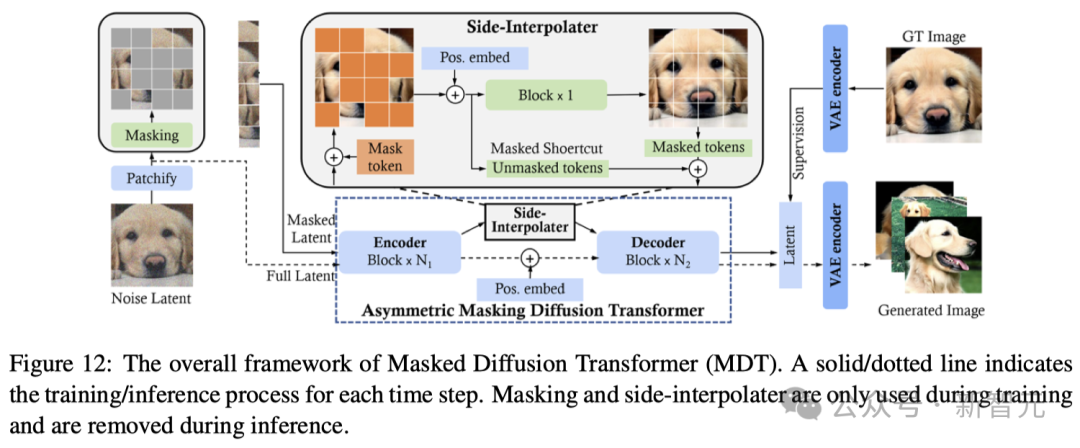
類似于掩碼自編碼器(MAE)的方法,掩碼擴散Transformer(MDT)也在擴散過程中加入了掩碼潛模型,有效提高了對圖像中不同對象部分之間上下文關系的學習能力。
如圖12所示,MDT會在訓練階段使用側插值進行額外的掩碼token重建任務,以提高訓練效率,并學習強大的上下文感知位置嵌入進行推理。與DiT相比,MDT實現了更好的性能和更快的學習速度。
在另一項創新工作中,Diffusion Vision Transformers(DiffiT)采用了時間依賴的自注意力(TMSA)模塊來對采樣時間步驟上的動態去噪行為進行建模。
此外,DiffiT還采用了兩種混合分層架構,分別在像素空間和潛空間中進行高效去噪,并在各種生成任務中實現了新的SOTA。
- 視頻Diffusion Transformer
由于視頻的時空特性,在這一領域應用DiT所面臨的主要挑戰是:
(1)如何從空間和時間上將視頻壓縮到潛空間,以實現高效去噪;
(2)如何將壓縮潛空間轉換為patches,并將其輸入到Transformer中;
(3)如何處理長距離的時空依賴性,并確保內容的一致性。
Imagen Video是谷歌研究院開發的文本到視頻生成系統,它利用級聯擴散模型(由7個子模型組成,分別執行文本條件視頻生成、空間超分辨率和時間超分辨率)將文本提示轉化為高清視頻。
如圖13所示,首先,凍結的T5文本編碼器會根據輸入的文本提示生成上下文嵌入。隨后,嵌入信息被注入基礎模型,用于生成低分辨率視頻,然后通過級聯擴散模型對其進行細化,以提高分辨率。

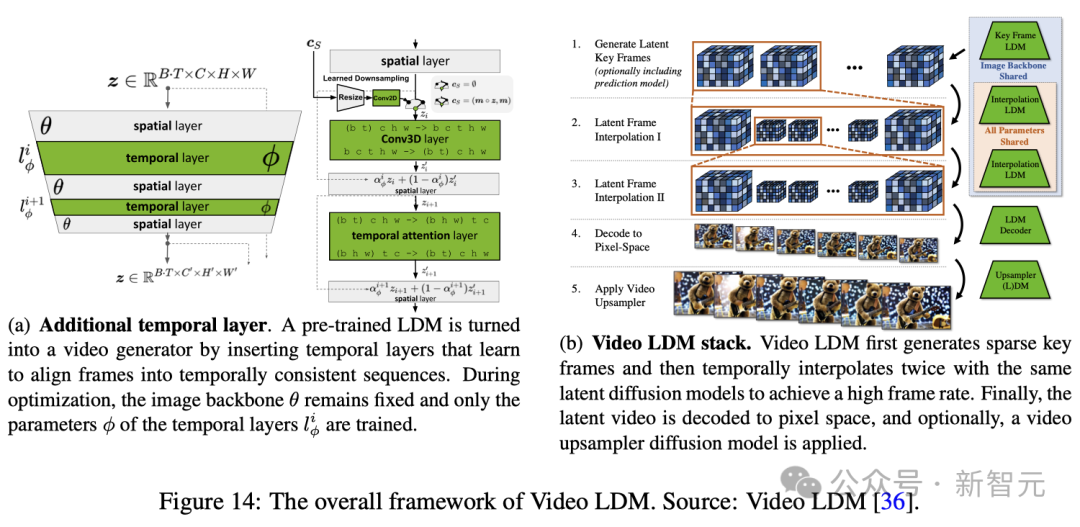
Blattmann等人提出了一種創新方法,可以將2D潛擴散模型(Latent Diffusion Model, LDM)轉換為視頻潛擴散模型(Video Latent Diffusion Model, Video LDM)。
語言指令跟隨
模型指令調優旨在增強AI模型準確跟隨提示的能力。
為了提高文本到視頻模型跟隨文本指令的能力,Sora采用了與DALL-E 3類似的方法。
該方法涉及訓練一個描述性字幕生成模型,并利用該模型生成的數據進一步微調。
通過這種指令調優,Sora能夠滿足用戶的各種要求,確保對指令中的細節給予精確的關注,進而生成的視頻能夠滿足用戶的需求。
提示工程
- 文本提示
文本提示對于指導Sora等文本到視頻模型,制作既具有視覺沖擊力,又能精確滿足用戶創建視頻需求至關重要。
這就需要制作詳細的說明來指導模型,以效彌補人類創造力與AI執行能力之間的差距。
Sora的提示涵蓋了廣泛的場景。
最近研究工作,如VoP、Make-A-Video和Tune-A-Video等,都展示了提示工程如何利用模型的NLP能力來解碼復雜指令,并將其呈現為連貫、生動和高質量的視頻敘事。
如圖15所示經典Sora演示,「一個時髦的女人走在霓虹燈閃爍的東京街頭...... 」
提示中,包含了人物的動作、設定、角色出場,甚至是所期望的情緒,以及場景氛圍。
就是這樣一個精心制作的文本提示,它確保Sora生成的視頻與預期的視覺效果非常吻合。
提示工程的質量取決于對詞語的精心選擇、所提供細節的具體性,以及對其對模型輸出影響的理解。

- 圖像提示
圖像提示就是要給生成的視頻內容和其他元素(如人物、場景和情緒),提供一個視覺錨點。
此外,文字提示還可以指示模型將這些元素動畫化,例如,添加動作、互動和敘事進展等層次,使靜態圖像栩栩如生。
通過使用圖像提示,Sora可以利用視覺和文本信息將靜態圖像轉換成動態、由敘事驅動的視頻。
在圖16中,展示了AI生成的視頻「一只頭戴貝雷帽、身穿高領毛衣的柴犬」、「一個獨特的怪物家族」、「一朵云組成了SORA一詞」,以及 「沖浪者在一座歷史悠久的大廳內乘著巨浪」。
這些例子展示了通過DALL-E生成的圖像提示Sora可以實現的功能。

- 視頻提示
視頻提示也可用于視頻生成。
最近的研究,如Fast-Vid2Vid表明,好的視頻提示需要具體,且靈活。

這樣既能確保模型在特定目標(如特定物體和視覺主題的描述)上獲得明確的指導,又能在最終輸出中富有想象力的變化。
例如,在視頻擴展任務中,提示可以指定擴展的方向(時間向前或向后)和背景或主題。
在圖17(a)中,視頻提示指示Sora向后延伸一段視頻,以探索原始起點的事件。
(b)所示,在通過視頻提示執行視頻到視頻的編輯時,模型需要清楚地了解所需的轉換,例如改變視頻的風格、場景或氛圍,或改變燈光或情緒等微妙的方面。
(c)中,提示指示Sora連接視頻,同時確保視頻中不同場景中的物體之間平滑過渡。

Sora對各行業的影響
最后,研究團隊還針對Sora可能在電影、教育、游戲、醫療保健和機器人領域產生的影響做了預測。
隨著以Sora為代表的視頻擴散模型成為前沿技術,其在不同研究領域和行業的應用正在迅速加速。
這項技術的影響遠遠超出了單純的視頻創作,為從自動內容生成到復雜決策過程等任務提供了變革潛力。
電影
視頻生成技術的出現預示著電影制作進入了一個新時代,用簡單的文本中自主制作電影的夢想正在變為現實。
研究人員已經涉足電影生成領域,將視頻生成模型擴展到電影創作中。
比如使用MovieFactory,利用擴散模型從ChatGPT制作的腳本中生成電影風格的視頻,整個工作流已經跑通了。
MobileVidFactory只需用戶提供簡單的文本,就能自動生成垂直移動視頻。

而Sora能夠毫不費力地讓用戶生成效果非常炸裂的電影片段,標志著人人都能制作電影的時刻來臨了。
這會大大降低了電影行業的準入門檻,并為電影制作引入了一個新的維度,將傳統的故事講述方式與人工智能驅動的創造力融為一體。
這些AI的影響不僅僅是讓電影制作變得簡單,還有可能重塑電影制作的格局,使其在面對不斷變化的觀眾喜好和發行渠道時,變得更加容易獲得,用途更加廣泛。
機器人
人們都說,2024年是機器人元年。
正是因為大模型的爆發,再加上視頻模型的迭代升級,讓機器人進入了一個新時代——
生成和解釋復雜的視頻序列,感知和決策能力增強。
尤其,視頻擴散模型釋放了機器人新能力,使其能夠與環境互動,并以前所未有的復雜度和精確度執行任務。
將web-scale擴散模型引入機器人技術,展示了利用大規模LLM增強機器人視覺和理解能力的潛力。
比如,在DALL-E加持下的機器人,能夠準確擺好餐盤。

另一種視頻預測新技術——潛在擴散模型(Latent diffusion model。
它可以通過語言指導,讓機器人能夠通過預測視頻中的動作結果,來理解和執行任務。
此外,機器人研究對環境模擬的依賴,可以通過視頻擴散模型——能創建高度逼真的視頻序列來解決。
這樣一來,就能為機器人生成多樣化的訓練場景,打破真實世界數據匱乏所帶來的限制。
研究人員相信,將Sora等技術整合到機器人領域有望取得突破性發展。
利用Sora的強大功能,未來的機器人技術將取得前所未有的進步,機器人可以無縫導航并與周圍環境進行互動。
另外,對于游戲、教育、醫療保健等行業,AI視頻模型也將為此帶來深刻的變革。
最后,好消息是,Sora現在雖然還沒有開放功能,但我們可以申請紅隊測試。

從申請表中可以看出,OpenAI正在尋找以下認知科學、化學、生物、物理、計算機、經濟學等領域的專家。

符合條件的同學,可以上手申請了!






























