













通過實時調試,讓AI編寫有效的UI自動化
作者簡介
Thales Fu,攜程高級研發經理,致力于尋找更好的方法,結合AI和工程來解決現實中的問題。
引言
在快速迭代的軟件開發周期中,用戶界面(UI)的自動化測試已成為提高效率和確保產品質量的關鍵。然而,隨著應用程序變得日益復雜,傳統的UI自動化方法逐漸顯露出局限性。AI驅動的UI自動化出現了,但仍面臨著準確性和可靠性的挑戰。在這個背景下,本文提出一個創新的視角:通過實時調試技術,顯著提升AI編寫的UI自動化腳本的有效性。
這個問題不僅僅是技術上的挑戰,它關系到如何在保證軟件質量的同時加速軟件的交付。本文將探討實時調試如何幫助AI更準確地理解和執行UI測試腳本,以及這種方法如何能夠為軟件開發帶來革命性的改變。
一、UI自動化的現狀
從最初的記錄與回放工具到復雜的腳本編寫框架,UI自動化經歷了顯著的發展。然而,盡管技術進步,傳統的UI自動化方法在應對快速變化的應用界面時仍然面臨諸多挑戰。
手動編寫測試腳本不僅效率低下,而且在應用更新時需要大量的重新工作。據行業調查顯示,UI自動化測試腳本的維護可能占到整個測試工作的60%至70%。在一個典型的敏捷開發環境中,每次應用更新可能需要超過100小時來重新編寫和測試現有的自動化腳本。這種高昂的維護成本凸顯了傳統UI自動化方法的低效性和資源消耗。
二、行為驅動開發BDD的引入
行為驅動開發(BDD)是一種敏捷軟件開發的實踐,它鼓勵軟件項目的開發者、測試人員和非技術利益相關者之間進行更有效的溝通。Cucumber是實現BDD方法論的一個流行工具,它允許團隊成員使用自然語言編寫明確的、可執行的測試用例。
Cucumber使用一種稱為Gherkin的域特定語言(DSL),這種語言是高度可讀的,使得非技術背景的人員也能理解測試的內容和目的。測試場景被寫成一系列的Given-When-Then語句,描述了在特定條件下系統應該如何響應。
例如,一個在線購物網站的購物車功能可能有如下的Gherkin場景:

這種方法通過使用自然語言描述功能,幫助技術和非技術團隊成員之間建立更好的理解和溝通。自然語言的測試場景也充當了項目文檔,幫助新團隊成員快速理解項目功能。讓非技術人員可以直接參與測試用例的編寫和驗證過程,確保開發工作與業務需求緊密對齊。
但是它也存在著局限性,盡管測試場景用自然語言編寫,每個步驟背后的實現(步驟定義)仍然需要技術人員使用編程語言來編寫。這意味著實現測試邏輯可能涉及復雜的代碼編寫工作。隨著應用程序的發展和變化,維護和更新與之相對應的測試步驟可能會變得繁瑣。特別是在UI頻繁更改的情況下,相關的步驟定義也需要相應地進行更新。還有靈活性和適應性限制:Cucumber測試腳本依賴于預定義的步驟和結構,這可能限制測試的靈活性。對于一些復雜的測試場景,實現特定的測試邏輯可能需要創造性地規避框架的限制。

三、當前AI在UI自動化中的應用
近年來,AI技術被集成到UI自動化中,特別是以GPT為代表的大模型出現后,因為它本身就有代碼生成能力。業界也開始試著通過大模型來直接把Gherkin的測試用例描述語言生成成測試代碼。

不過,當前大模型生成的測試代碼并不能完全達到預期,主要有幾個問題:首先,生成出來的腳本,因為語法錯誤可能無法運行;其次,也可能沒有準確的覆蓋到測試用例需要它去測試的校驗點。在我們的實踐下,真正能第一次就成功的比例不超過5%。
它生成失敗后,接著就需要人介入再進行一些補救的工作。包括:調試,修改用例重新生成,或者直接修改生成的腳本。

而這些工作本身也需要消耗不少的人力,和我們系統通過AI來自動生成測試腳本的初衷相違背。
四、AI全自動的來編寫有效的測試腳本
為了解決這個問題,我們重新思考了AI生成測試腳本的整個過程。

我們把人的工作也放在里面一起考慮。人在系統中做了調試和修改的工作,那這部分工作是不是可以讓AI來做呢,讓系統自己運行生成的代碼,讓AI來調試和修改自己生成的錯誤代碼。
因此,我們調整了系統設計,讓AI代替人自主地來做這些工作。最終,對于攜程酒店訂單詳情頁的全部用例,在無人參與的情況下,生成可以執行成功的占全部的83.3%,在生成腳本過程中,有8%的case就已經發現了Bug。我們連續生成這些用例三次,成功率分別在84.3%,81.4%和83.3%,系統是穩定有效的。

具體的測試用例和代碼如下:

首先,需要滑動到訂單詳情頁下放的用戶權益模塊,然后點擊訂房優化區域,來彈出價格浮層。

然后再看,費用明細里面是否包含黑鉆貴賓。

最終生成的測試代碼如下:

五、系統實現
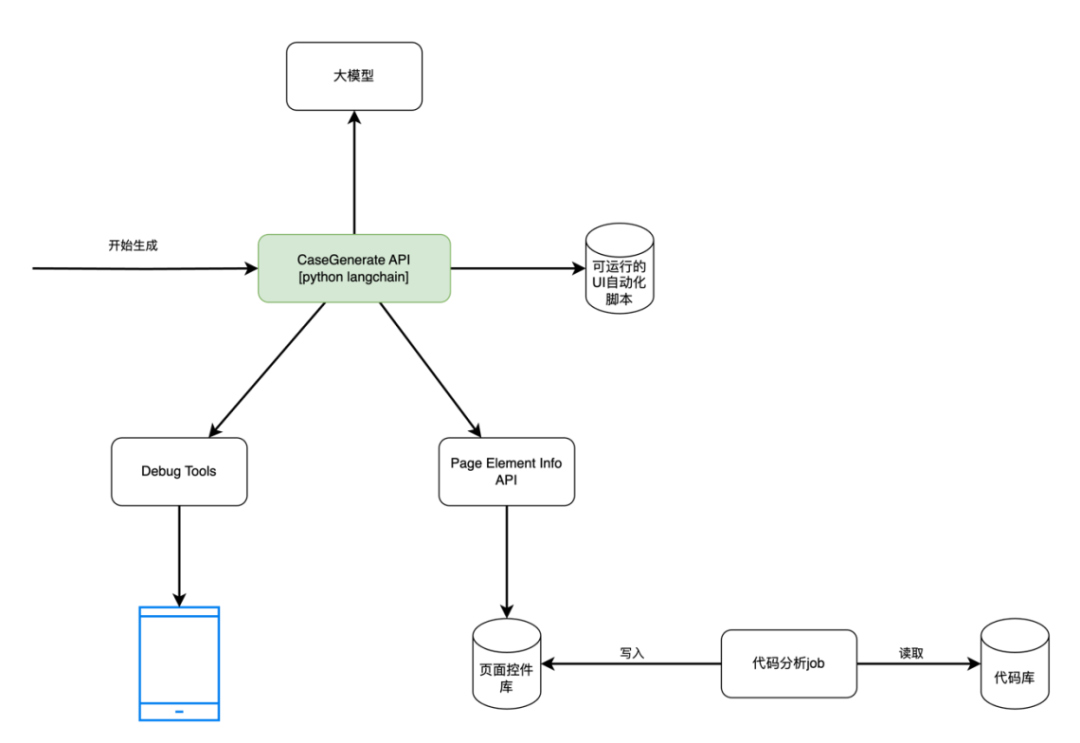
整個系統的核心架構示意圖如下。系統的核心部分是一個langchain框架的程序。它會去訪問大模型,我們給它配備了多個工具,主要分成兩類,一類是頁面信息的獲取工具,一類是調試工具。
Langchain會自動根據需要,使用頁面信息獲取工具,去拿頁面的數據,來判斷當前的操作需要具體哪個控件,來生成代碼。然后再使用調試工具在手機中真實的執行代碼,基于調試的反饋來判斷自己生成的代碼是否正確。
5.1 提示詞
有了基本的架構后,我們需要提示詞,來把這些工具粘合起來,讓AI理解它該如何工作。我們的提示詞從結構上來說包含了幾部分內容:首先告訴AI它該如何思考和工作,其次告訴它一定要通過Debug調試它每一句生成的語句,再次告訴它輸出格式是什么,最后是告訴AI要處理的完整用例文本。
對于告訴AI它該如何思考和工作,展開包含以下部分:首先看頁面有哪些模塊,我要操作的這個步驟應該是哪個模塊,這個模塊里有哪些控件和組件,我當前要操作的是哪個控件或組件,我要操作的動作是什么,以及我可以用的特殊的語法是什么,然后生成語句。

5.2 調試工具
調試工具的本質是通過adb工具遠程連接到手機上。連接后,我們就可以把AI生成的指令發送給手機去運行,并且讀取到運行后的結果給到AI,讓AI去判斷自己生成的指令是否正確。
5.3 頁面信息獲取工具
頁面信息獲取工具的最終目的是幫助AI判斷出,BDD的用例上面寫得要操作的內容,它具體要操作的控件的ID是什么,有了ID才能基于ID生成后續的程序指令。而為了拿到ID,我們需要有個控件和組件庫,這個庫里面的核心是每個控件和組件的ID以及它們的描述。有了這兩項內容后,才能幫助AI看了BDD用例后,基于控件的描述去猜需要的是哪個控件。
為了達到這個目的,我們建立了一個頁面控件庫。這個庫除了包含頁面上每個控件的ID和描述外,還包含了頁面和組件的關系,以及組件和控件的關系。能方便AI一步步的進行查詢。

而這個控件庫本身是基于我們通過job對代碼進行靜態分析來生成的。不過實際應用中,因為頁面當前真正展示的控件會根據場景狀態的不同而不同,在某些場景下頁面上的控件會隱藏。因此頁面信息獲取工具會把頁面當前真實存在的控件和控件庫中查詢出來的控件做交集,從而獲取到當前頁面真實展示出的控件和它的描述信息。
5.4 進一步拆分AI

當做了這些工作后,AI基本上已經可以把上面這張圖黃色的部分,也就是人的工作自動去做了。生成成功率也從5%提升到了55%,但是55%的成功率還是不夠的。
我們進一步分析了失敗的case。發現主要問題是AI的幻覺,雖然提示詞已經比較詳細了,但是AI有時會沒有按照要求處理,有的時候會自己胡說八道。
我們的結論是,給AI的責任太多了,它要考慮的東西太多。倒不是說它的Token不夠,而是讓它做的事情太多,會遺忘,無法精準完成要求。因此我們考慮進行拆分,還是利用了langchain的function的功能,既然AI能通過工具去完成功能,那這個工具為什么本身不能也是個AI呢。

甚至還可以把它再進行拆分。

通過這些拆分,我們讓每一個AI需要考慮的工作變得更少更簡單,也讓它處理得更加精準,最終生成成功率提升到了80%以上。
六、后續的發展
當前,通過我們的工作,能讓AI在無人參與下以80%左右的成功率去生成自動化測試的代碼,很讓人振奮,但還有很多問題需要繼續去解決。
1)大模型的調用成本還是不低,是否有更好的辦法,更低的成本去完成工作。
2)當前還有些比較難處理的操作或者校驗,成功率80%還有不小的提升空間,以及目前最后還是需要人來復核生成結果。
3)除此之外,其他方面也都有提高的空間,值得我們繼續去完善。




















