













ICLR 2024 | 聯邦學習后門攻擊的模型關鍵層
聯邦學習使多個參與方可以在數據隱私得到保護的情況下訓練機器學習模型。但是由于服務器無法監控參與者在本地進行的訓練過程,參與者可以篡改本地訓練模型,從而對聯邦學習的全局模型構成安全序隱患,如后門攻擊。
本文重點關注如何在有防御保護的訓練框架下,對聯邦學習發起后門攻擊。本文發現后門攻擊的植入與部分神經網絡層的相關性更高,并將這些層稱為后門攻擊關鍵層。
基于后門關鍵層的發現,本文提出通過攻擊后門關鍵層繞過防御算法檢測,從而可以控制少量的參與者進行高效的后門攻擊。

論文題目:Backdoor Federated Learning By Poisoning Backdoor-Critical Layers
論文鏈接:https://openreview.net/pdf?id=AJBGSVSTT2
代碼鏈接:https://github.com/zhmzm/Poisoning_Backdoor-critical_Layers_Attack
方法

本文提出層替換方法識別后門關鍵層。具體方法如下:
- 第一步,先將模型在干凈數據集上訓練至收斂,并保存模型參數記為良性模型
 。再將良性模型的復制在含有后門的數據集上訓練,收斂后保存模型參數并記為惡意模型
。再將良性模型的復制在含有后門的數據集上訓練,收斂后保存模型參數并記為惡意模型 。
。 - 第二步,取良性模型中一層參數替換到包含后門的惡意模型中,并計算所得到的模型的后門攻擊成功率
 。將得到的后門攻擊成功率與惡意模型的后門攻擊成功率 BSR 做差得到 △BSR,可得到該層對后門攻擊的影響程度。對神經網絡中每一層使用相同的方法,可得到一個記錄所有層對后門攻擊影響程度的列表。
。將得到的后門攻擊成功率與惡意模型的后門攻擊成功率 BSR 做差得到 △BSR,可得到該層對后門攻擊的影響程度。對神經網絡中每一層使用相同的方法,可得到一個記錄所有層對后門攻擊影響程度的列表。 - 第三步,對所有層按照對后門攻擊的影響程度進行排序。將列表中影響程度最大的一層取出并加入后門攻擊關鍵層集合
 ,并將惡意模型中的后門攻擊關鍵層(在集合
,并將惡意模型中的后門攻擊關鍵層(在集合  中的層)參數植入良性模型。計算所得到模型的后門攻擊成功率
中的層)參數植入良性模型。計算所得到模型的后門攻擊成功率 。如果后門攻擊成功率大于所設閾值 τ 乘以惡意模型后門攻擊成功率
。如果后門攻擊成功率大于所設閾值 τ 乘以惡意模型后門攻擊成功率 ,則停止算法。若不滿足,則繼續將列表所剩層中最大的一層加入后門攻擊關鍵層
,則停止算法。若不滿足,則繼續將列表所剩層中最大的一層加入后門攻擊關鍵層 直到滿足條件。
直到滿足條件。
在得到后門攻擊關鍵層的集合之后,本文提出通過攻擊后門關鍵層的方法來繞過防御方法的檢測。除此之外,本文引入模擬聚合和良性模型中心進一步減小與其他良性模型的距離。
實驗結果
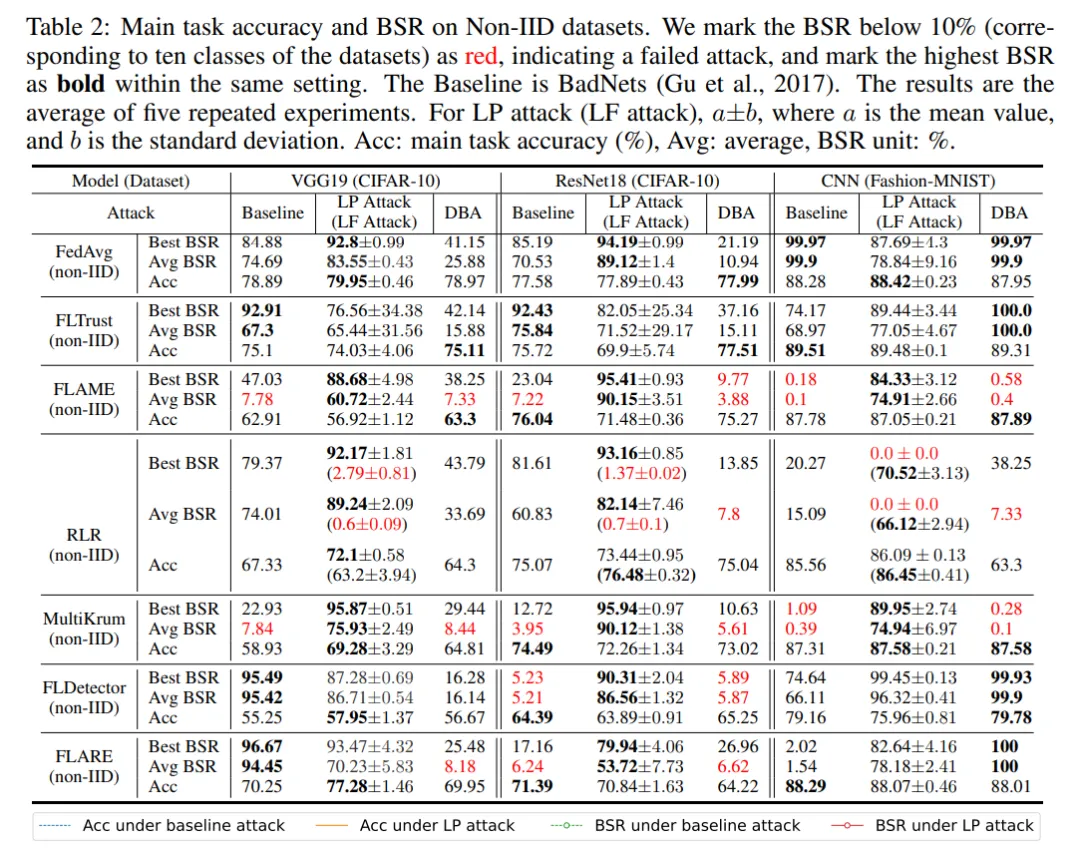
本文對多個防御方法在 CIFAR-10 和 MNIST 數據集上驗證了基于后門關鍵層攻擊的有效性。實驗將分別使用后門攻擊成功率 BSR 和惡意模型接收率 MAR(良性模型接收率 BAR)作為衡量攻擊有效性的指標。
首先,基于層的攻擊 LP Attack 可以讓惡意客戶端獲得很高的選取率。如下表所示,LP Attack 在 CIFAR-10 數據集上得到了 90% 的接收率,遠高于良性用戶的 34%。

然后,LP Attack 可以取得很高的后門攻擊成功率,即使在只有 10% 惡意客戶端的設定下。如下表所示,LP Attack 在不同的數據集和不同的防御方法保護下,均能取得很高的后門攻擊成功率 BSR。
在消融實驗中,本文分別對后門關鍵層和非后門關鍵層進行投毒并測量兩種實驗的后門攻擊成功率。如下圖所示,攻擊相同層數的情況下,對非后門關鍵層進行投毒的成功率遠低于對后門關鍵層進行投毒,這表明本文的算法可以選擇出有效的后門攻擊關鍵層。

除此之外,我們對模型聚合模塊 Model Averaging 和自適應控制模塊 Adaptive Control 進行消融實驗。如下表所示,這兩個模塊均對提升選取率和后門攻擊成功率,證明了這兩個模塊的有效性。

總結
本文發現后門攻擊與部分層緊密相關,并提出了一種算法搜尋后門攻擊關鍵層。本文利用后門攻擊關鍵層提出了針對聯邦學習中保護算法的基于層的 layer-wise 攻擊。所提出的攻擊揭示了目前三類防御方法的漏洞,表明未來將需要更加精細的防御算法對聯邦學習安全進行保護。
作者介紹
Zhuang Haomin,本科畢業于華南理工大學,曾于路易斯安那州立大學 IntelliSys 實驗室擔任研究助理,現于圣母大學就讀博士。主要研究方向為后門攻擊和對抗樣本攻擊。
























