GitHub突破1000星!上交、清華開源個性化聯邦學習算法庫PFLlib
我們在 GitHub 上開源了一個個性化聯邦學習算法倉庫(PFLlib),目前已經獲得 1K+ 個 Star 和 200+ 個 Fork,在業內收到了廣泛的好評。PFLlib 囊括了 34 個聯邦學習算法(其中包含 27 個個性化聯邦學習算法)、3 大類數據異質場景、20 個數據集。
開源該倉庫的主要目的是:1)降低初學者研究個性化聯邦學習算法的門檻;2)提供一個統一的實驗環境,在多種場景和多個方面對不同個性化聯邦學習算法進行評估,為個性化聯邦學習算法在具體場景中應用時的選擇提供參考;3)為個性化聯邦學習算法的研究者們提供一個可以交流的平臺,在交流的過程中互相學習,碰撞出新的火花。

▲ GitHub Star 的增長曲線

論文標題:
PFLlib: Personalized Federated Learning Algorithm Library
論文鏈接:
https://arxiv.org/abs/2312.04992
代碼鏈接:
https://github.com/TsingZ0/PFLlib
01 個性化聯邦學習(PFL)
聯邦學習(FL)作為一種新型的分布式機器學習范式,它主要用于訓練人工智能(AI)模型。除了傳統分布式機器學習的跨設備協同訓練 AI 模型的特點之外,聯邦學習的特殊性主要體現在保護每個設備上數據隱私的能力。
聯邦學習實現隱私保護的主要方式是:禁止具有隱私性的數據離開產生該數據的設備。這種限制使得這些設備上的本地數據無法通過傳統分布式機器學習中的數據采集、數據清洗、數據分片等操作,來實現每個設備上數據的一致性。
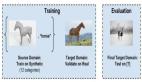
由于不同設備所處環境的不同,使得它們各自產生數據、采集數據、處理數據的方式不盡相同。于是,便產生了各個設備之間的數據異質問題,如圖 1。在異質的數據上學習得到的本地模型,通過服務器進行了模型參數聚合后生成的全局模型會有表現不佳等問題。

▲ 圖1:聯邦學習及數據異質問題。
為了應對聯邦學習中的數據異質問題,研究者們開始探索在設備參與到聯邦學習系統里進行協同訓練、聚合得到全局模型的同時,為自己學習適配本地任務的個性化模型的新型聯邦學習算法。這類算法被人們稱為“個性化聯邦學習算法”。
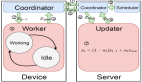
在個性化聯邦學習的范疇中,生成全局模型不再是最終的目的,而以全局模型為知識共享的載體、用全局模型中蘊含的全局信息來提升本地模型效果才是最終的目標,如圖 2 所示。
在個性化聯邦學習框架之下,每個參與者通過聯邦學習過程實現協作,用聚合得到的全局信息彌補了本地數據不足的問題;且每個參與者為自己本地任務訓練得到的個性化模型利好參與者自身,無形中激勵了各個設備參與聯邦學習的熱情。

▲ 圖2:個性化聯邦學習。
02 PFLlib 簡介
2021 年伊始,本人在探索個性化聯邦學習算法的過程中發現,由于不同論文的實驗設置(如數據集、模型結構、數據異質種類、客戶機數量、超參數設定等)不同,導致論文中的大部分實驗數據不能復用。同時,有相當一部分的論文,其代碼并不開源,使得我們無法通過在新場景下運行代碼來獲得實驗數據。
此外,在 PFL 領域逐漸火熱起來后,對比實驗往往需要比較十幾個相關方法,即使每個方法有自己的開源代碼,為這些具有不同風格、結構、規范的代碼進行新實驗設置的適配需要花費大量的精力和時間,使得剛入門 PFL 的研究者無法關注在 PFL 本身的研究上。
當時,我在探索后來發表在 AAAI 2023 的 FedALA [1](PFLlib 包含該算法)過程中,感覺自己寫的用來進行對比實驗的代碼框架相對簡單易懂。出于開源精神,我便對其進行了開源。之后,隨著我在 PFL 領域逐步深入,越來越多的PFL方法出現,我后續也持續地加入了不少算法,才有了如今的規模。

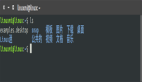
▲ 圖3:PFLlib 中實現 FedAvg 的例子。
總的來說,PFLlib 擁有以下幾個特性:
- 代碼結構簡單,易于入手和閱讀,易于添加新算法。工具函數存放在
utils文件夾中。基礎的設備和服務器操作分別存放在clientbase.py和serverbase.py中。如圖 3,以在 MNIST 數據集上實現最基礎的 FedAvg [2] 算法為例,我們只需要編寫generate_MNIST.py來生成實驗場景,然后編寫clientavg.py和serveravg.py來實現 FedAvg 訓練流程,再將 FedAvg 在main.py配置一下,即可通過命令行運行 FedAvg 算法。 - 提供了較為全面的聯邦學習算法倉庫和實驗環境。PFLlib 總共擁有 34 個聯邦學習算法(其中包含 27 個個性化聯邦學習算法)、3 大類數據異質場景、20 個數據集。
- GPU 資源需求較少。使用實驗中最常用的 4 層 CNN 網絡,可以在 NVIDIA GeForce RTX 3090 GPU 上,僅用 5.08GB 顯存模擬 500 個設備同步訓練的場景。
- 提供了一種基于 DLG [3] 的隱私攻擊和隱私泄露度量指標,用于度量多數論文中沒提及的 PFL 算法的隱私保護能力。
03 34個聯邦學習算法
根據聯邦學習算法中用到的技術,我們對 34 個 PFL 算法進行了分類,具體分類結果見表 1。

▲ 表1:PFLlib 中聯邦學習算法的分類。
04 3個場景和20個數據集
聯邦學習的數據異質場景主要分為四大類:不平衡性(unbalance)、標簽傾斜(label skew)、特征漂移(feature shift)、真實世界(real-world)。
其中不平衡性指的是不同設備上數據量不同;標簽傾斜主要指的是不同設備上的數據特征相似但類別(標簽)不同;特征漂移則與標簽傾斜恰好相反,指的是不同設備上的數據標簽相同但特征不同;真實世界指的是不同設備上的數據是真實采集到的,可能同時包含以上三種情況。
由于不平衡性與標簽傾斜和特征漂移都不沖突,PFLlib 將不平衡性融入了標簽傾斜和特征漂移之中。
PFLlib 為標簽傾斜(含不平衡性)、特征漂移(含不平衡性)、真實世界三個場景分別提供了適用于各自場景的數據集。
標簽傾斜:該場景是在聯邦學習領域探索的最多的場景,也是現實情況下最容易遇到的場景。該場景進一步還分為病態的非獨立同分布(pathological non-IID)和真實的非獨立同分布(practical non-IID)兩個子場景。
總共有 14 個數據集用于標簽傾斜場景:MNIST、EMNIST、Fashion-MNIST、Cifar10、Cifar100、AG News、Sogou News、Tiny-ImageNet、Country211、Flowers102、GTSRB、Shakespeare、Stanford Cars。它們都支持以上兩個子場景。
特征漂移:在這個場景中,PFLlib 主要采用了 3 個數據集,分別是:Amazon Review、Digit5、DomainNet。
真實世界:PFLlib 采用的是 IoT(Internet of Things)數據集,它們分別是:Omniglot(20 個設備, 50 個標簽)、HAR(Human Activity Recognition)(30 個設備, 6 個標簽)、PAMAP2(9 個設備,12 個標簽)。
每個數據集中含有多個子數據集,每個子數據集是從某個具體的設備(例如傳感器、陀螺儀等)上采集得到的真實數據。這類數據集有利于 PFL 算法在實際場景落地問題的研究。正如 GPFL [4](PFLlib 包含該算法)中的實驗表明,在模擬場景(標簽傾斜和特征漂移等)表現較好的算法,在真實世界場景中不一定具有良好表現。
05 部分實驗結果
出于驗證 PFLlib 中附帶實驗平臺的可用性,根據 GPFL 中的默認實驗設置,我們對部分算法在部分常見場景中的表現進行了展示,如下表所示(實驗結果僅供參考)。

▲ 表2:PFLlib 中部分聯邦學習算法在部分場景中測試集上的分類準確率。
最后,感謝大家對 PFLlib 項目的支持,也歡迎剛了解到 PFLlib 的朋友們一起參與到 PFLlib 項目的建設中來!