當傳統(tǒng)聯邦學習面臨異構性挑戰(zhàn),不妨嘗試這些個性化聯邦學習算法
本文選擇了三篇關于個性化聯邦學習的文章進行深入分析。
經典的機器學習方法基于樣本數據(庫)訓練得到適用于不同任務和場景的機器學習模型。這些樣本數據(庫)一般通過從不同用戶、終端、系統(tǒng)中收集并集中存儲而得到。在實際應用場景中,這種收集樣本數據的方式面臨很多問題。一方面,這種方法損害了數據的隱私性和安全性。在一些應用場景中,例如金融行業(yè)、政府行業(yè)等,受限于數據隱私和安全的要求,根本無法實現對數據的集中存儲;另一方面,這種方法會增加通信開銷。在物聯網等一些大量依賴于移動終端的應用中,這種數據匯聚的通信開銷成本是非常巨大的。
聯邦學習允許多個用戶(稱為客戶機)協作訓練共享的全局模型,而無需分享本地設備中的數據。由中央服務器協調完成多輪聯邦學習以得到最終的全局模型。其中,在每一輪開始時,中央服務器將當前的全局模型發(fā)送給參與聯邦學習的客戶機。每個客戶機根據其本地數據訓練所接收到的全局模型,訓練完畢后將更新后的模型返回中央服務器。中央服務器收集到所有客戶機返回的更新后,對全局模型進行一次更新,進而結束本輪更新。通過上述多輪學習和通信的方法,聯邦學習消除了在單個設備上聚合所有數據的需要,克服了機器學習任務中的隱私和通信挑戰(zhàn),允許機器學習模型學習分散在各個用戶(客戶機)上存儲的數據。
聯邦學習自提出以來獲得了廣泛的關注,并在一些場景中得以應用。聯邦學習解決了數據匯聚的問題,使得一些跨機構、跨部門的機器學習模型、算法的設計和訓練成為了可能。特別地,對于移動設備中的機器學習模型應用,聯邦學習表現出了良好的性能和魯棒性。此外,對于一些沒有足夠的私人數據來開發(fā)精確的本地模型的用戶(客戶機)來說,通過聯邦學習能夠大大改進機器學習模型和算法的性能。但是,由于聯邦學習側重于通過分布式學習所有參與客戶機(設備)的本地數據來獲得高質量的全局模型,因此它無法捕獲每個設備的個人信息,從而導致推理或分類的性能下降。此外,傳統(tǒng)的聯邦學習需要所有參與設備就協作訓練的共同模型達成一致,這在實際復雜的物聯網應用中是不現實的。研究人員將聯邦學習在實際應用中面臨的問題總結如下[2]:(1)各個客戶機(設備)在存儲、計算和通信能力方面存在異構性;(2) 各個客戶機(設備)本地數據的非獨立同分布(Non-Idependently and Identically Distributed,Non-IID)所導致的數據異構性問題;(3)各個客戶機根據其應用場景所需要的模型異構性問題。
為了解決這些異構性挑戰(zhàn),一種有效的方法是在設備、數據和模型級別上進行個性化處理,以減輕異構性并為每個設備獲得高質量的個性化模型,即個性化聯邦學習(Personalized Federated Learning)。針對 Non-IID 的聯邦學習,機器之心之前有專門的分析文章,感興趣的讀者可以閱讀。針對設備異構性的問題,一般可以通過設計新的分布式架構(如 Client-Edge-Cloud[5])或新的聯邦學習算法( Asynchronous Fed[6])來解決。
針對模型異構性的問題,作者在文獻 [1] 中將不同的個性化聯邦學習方法分為以下幾類:增加用戶上下文(Adding User Context )[8]、遷移學習(Transfer Learning)[9]、多任務學習(Multi-task Learning)[10]、元學習(Meta-Learning)[3]、知識蒸餾(Knowledge Distillation )[11]、基本層 + 個性化層( Base + Personalization Layers)[4]、混合全局和局部模型(Mixture of Global and Local Models )[12] 等。
本文選擇了三篇關于個性化聯邦學習的文章進行深入分析。其中,第一篇文章關于設備異構性的問題[6],作者提出了一種新的異步聯邦優(yōu)化算法。對于強凸和非強凸問題以及一類受限的非凸問題,該方法能夠近似線性收斂到全局最優(yōu)解。第二篇文章重點解決模型異構性的問題[7],作者提出了一種引入 Moreau Envelopes 作為客戶機正則化損失函數的個性化聯邦學習算法(pFedMe),該算法有助于將個性化模型優(yōu)化與全局模型學習分離開來。最后,第三篇文章提出了一個協同云邊緣框架 PerFit,用于個性化聯邦學習,從整體上緩解物聯網應用中固有的設備異構性、數據異構性和模型異構性[2]。
一、Asynchronous Federated Optimization

隨著邊緣設備 / 物聯網(如智能手機、可穿戴設備、傳感器以及智能家居 / 建筑)的廣泛使用,這些設備在人們日常生活中所產生的大量數據催生了 “聯邦學習” 的方法。另一方面,對于人工智能算法中所使用的的樣本數據隱私性的考慮,進一步提高了人們對聯邦學習的關注度。然而,聯邦學習是同步優(yōu)化(Synchronous)的,即中央服務器將全局模型同步發(fā)送給多個客戶機,多個客戶機基于本地數據訓練模型后同步將更新后的模型返回中央服務器。聯邦學習的同步特性具有不可擴展、低效和不靈活等問題。這種同步學習的方法在接入大量客戶機的情況下,存在同時接收太多設備反饋會導致中央服務器端網絡擁塞的問題。此外,由于客戶機的計算能力和電池時間有限,任務調度因設備而異,因此很難在每個更新輪次(epoch)結束時精準的同步接入的客戶機。傳統(tǒng)方法會采取設定超時閾值的方法,刪除無法及時同步的客戶機。但是,如果可接入同步的客戶機數量太少,中央服務器可能不得不放棄整個 epoch,包括所有已經接收到的更新。
為了解決同步聯邦學習中出現的這些問題,本文提出了一種新的異步聯邦優(yōu)化算法,其關鍵思想是使用加權平均值來更新全局模型。可以根據陳舊性函數(A Function of the Staleness)自適應設定混合權重值。作者在文中證明,這些更改結合在一起能夠生成有效的異步聯邦優(yōu)化過程。
1.1 方法介紹
給定 n 個客戶機,經典聯邦學習表示為:
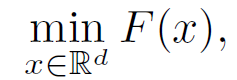
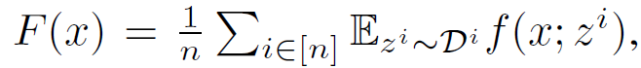
其中,z^i 為第 i 個客戶機設備中的數據采樣。由于不同的客戶機設備之間存在異構性,所存儲的數據庫也不同,從不同設備中提取的樣本具有不同的期望值:
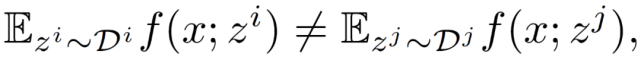
聯邦學習的一次完整的更新過程由 T 個全局 epochs 組成。在第 t 個 epoch 中,中央服務器接收任意一個客戶機發(fā)回的本地訓練的模型 x_new,并通過加權平均來更新全局模型:
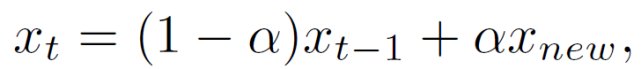
其中,α∈(0,1),α為混合超參數 (mixing hyperparameter)。在任意設備 i 上,在從中央服務器接收到全局模型 x_t(可能已經過時)后,使用 SGD 進行局部優(yōu)化以解決以下正則化優(yōu)化問題:
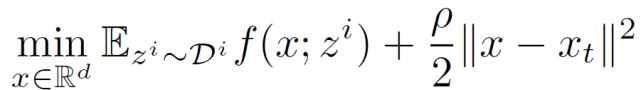
中央服務器和客戶機設備的工作線程執(zhí)行異步更新。當中央服務器接收到本地模型時,會立即更新全局模型。中央服務器和客戶機線程之間的通信是非阻塞的。完整算法具體見算法 1。在中央服務器端,有兩個線程異步并行運行:調度線程和更新線程。調度器定期觸發(fā)一些客戶機設備的訓練任務。更新線程接收到客戶機設備本地訓練得到的模型后更新全局模型。全局模型通過多個具有讀寫鎖的更新線程來提高吞吐量。調度器隨機化訓練任務的時間,以避免更新線程過載,同時控制各個訓練任務的陳舊性(更新線程中的 t-τ)。更新全局模型時,客戶端反饋的陳舊性越大(過時越久),錯誤就越大。

針對模型中的α混合超參,對于具有大滯后性的局部模型(t-τ)可以通過減小α來減小由陳舊性引起的誤差。作者引入一個函數 s(t-τ)來控制α的值。具體的,可選函數格式如下:
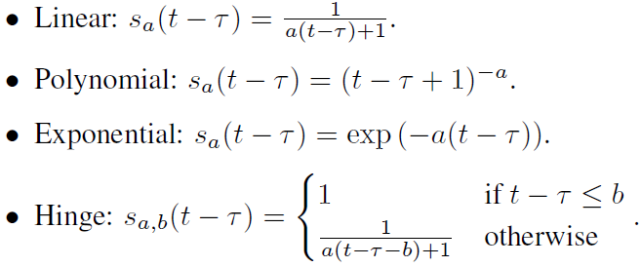
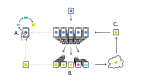
本文提出的異步聯邦優(yōu)化方法的完整結構見圖 1。其中,0:調度進程通過協調器觸發(fā)訓練任務。1、2:客戶機設備接收中央服務器發(fā)來的延遲的全局模型 x_(t-τ)。3:客戶機設備按照算法 1 中的描述進行本地更新。工作進程可以根據客戶機設備的可用性在兩種狀態(tài)之間切換:工作狀態(tài)和空閑狀態(tài)。4、5、6:客戶機設備通過協調器將本地更新的模型推送到中央服務器。調度程序對 5 中接收到的模型進行排隊,并在 6、7、8 中按順序將它們提供給更新進程:中央服務器更新全局模型并使其準備好在協調器中讀取。在該系統(tǒng)中,1 和 5 異步并行運行,中央服務器可以隨時觸發(fā)客戶機設備上的訓練任務,而客戶機設備也可以隨時將本地更新的模型推送到中央服務器。
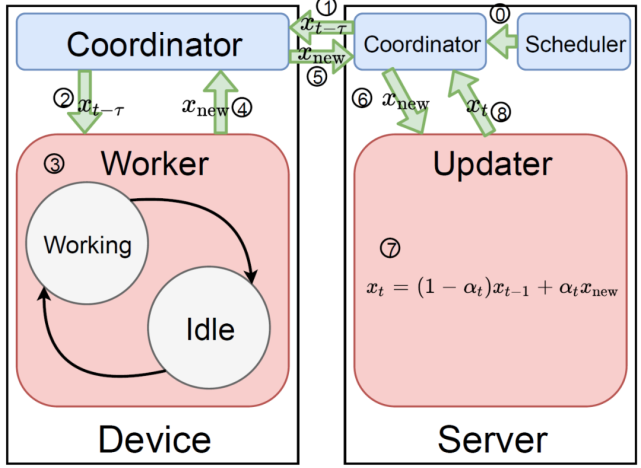
圖 1. 異步聯邦優(yōu)化系統(tǒng)總覽
1.2 實驗分析
本文在基準 CIFAR-10 圖像分類數據集上進行了實驗,該數據集由 50k 個訓練圖像和 10k 個測試圖像組成。調整每個圖像的大小并將其裁剪為(24, 24, 3)的形狀。使用 4 層卷積層 + 1 層全連接層結構的卷積神經網絡(CNN)。實驗中,將訓練集劃分到 n=100 個客戶機設備上。其中,n=100 的每個分區(qū)中有 500 個圖像。對于任何客戶機設備,SGD 處理的小批量大小是 50。使用經典 FedAvg 聯邦學習方法和單線程 SGD 作為基準方法。本文所提出的異步聯邦優(yōu)化方法記作 FedAsync。其中,根據α定義方式的不同,將選擇多項式自適應α的方法定義為 FedAsync+Poly,將采用 Hinge 自適應α的方法記作 FedAsync+Hinge。
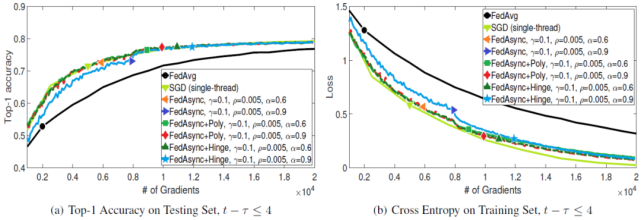
圖 2. 指標與梯度,陳舊性為 4
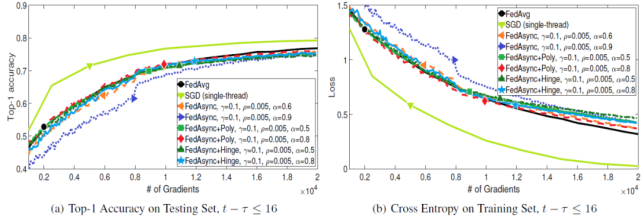
圖 3. 指標與梯度,陳舊性為 16
圖 2 和圖 3 給出了梯度值增加時 FedAsync 如何收斂。可以看到,當整體陳舊性較小時,FedAsync 收斂速度與 SGD 一樣快,比 FedAvg 快。當陳舊性較大時,FedAsync 收斂速度較慢。在最壞的情況下,FedAsync 的收斂速度與 FedAvg 相似。當 α值非常大時,收斂可能不穩(wěn)定。使用自適應 α,收斂性對較大的 α 是魯棒的。當最大陳舊性狀態(tài)為 4 時,FedAsync 和 FedAsync+Hinge (b=4)是相同的。
1.3 論文小結
與經典聯邦學習相比,本文提出的異步聯邦優(yōu)化方法具有下述優(yōu)點:
效率:中央服務器可以隨時接收客戶機設備的更新。與 FedAvg 不同,陳舊性(延時反饋)的更新不會被刪除。當陳舊性很小時,FedAsync 比 FedAvg 收斂的快得多。在最壞的情況下,當陳舊性很大時(延時嚴重),FedAsync 仍然具有與 FedAvg 相似的性能。
靈活性:如果某些設備不再能夠執(zhí)行訓練任務(設備不再空閑、充電中或連接到不可用的網絡),可以將其暫時掛起,等待繼續(xù)訓練或稍后將訓練模型推送到中央服務器。這也為中央服務器上的進程調度提供了很大的靈活性。與 FedAvg 不同,FedAsync 可以自行安排訓練任務,即使設備當前不合格 / 不能夠工作,因為中央服務器無需一直等待設備響應,也可以做到令當前不合格 / 不能工作的客戶機設備稍后開始訓練任務。
可伸縮性:與 FedAvg 相比,FedAsync 可以處理更多并行運行的客戶機設備,因為中央服務器和這些設備上的所有更新都是非阻塞的。服務器只需隨機化各個客戶機設備的響應時間即可避免網絡擁塞。
作者在文章中通過理論分析和實驗驗證的方式證明了 FedAsync 的收斂性。對于強凸問題和非強凸問題,以及一類受限制的非凸問題,FedAsync 具有近似線性收斂到全局最優(yōu)解的能力。在未來的工作中,作者計劃進一步研究如何設計策略來更好的調整混合超參數。
二、Personalized Federated Learning with Moreau Envelopes

隨著手持設備、移動終端的快速發(fā)展和推廣應用,這些手持設備 / 移動終端產生的大量數據推動了聯邦學習的發(fā)展。聯邦學習以一種保護隱私和高效通信的方式通過分散在客戶端(客戶機設備)中的數據構建一個精確的全局模型。在實際應用中,經典聯邦學習面臨了這樣一個問題:* 如何利用聯邦學習中的全局模型來找到一個針對每個客戶端數據進行個性化適配處理的“個性化模型”*?
參考個性化模型在醫(yī)療保健、金融和人工智能服務等領域中應用的模式,本文提出了一種個性化聯邦學習方案,該方案引入了基于客戶端損失函數的 Moreau envelopes 優(yōu)化。通過該方案,客戶端不僅可以像經典聯邦學習一樣構建全局模型,而且可以利用全局模型來優(yōu)化其個性化模型。從幾何的角度分析,該方案中的全局模型可以看作是所有客戶端一致同意的“中心點”,而個性化模型是客戶端根據其異構數據分布來構建的遵循不同方向的點。
2.1 方法介紹
首先,作者回顧了經典聯邦學習:
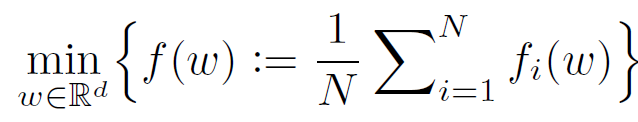
(1)
其中,ω 表示全局模型,函數 f_i 表示客戶端 i 中數據分布的預期損失。
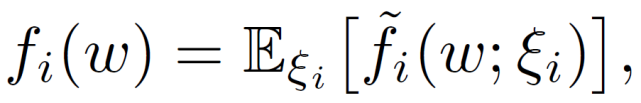
其中,ξ_i 為根據客戶端 i 的分布隨機抽取數據樣本,f_i(ω;ξ _i)表示對應于該樣本和ω的損失函數。在聯邦學習中,由于客戶端的數據可能來自不同的環(huán)境、上下文和應用程序,因此客戶端具有 Non-IID 數據分布,不同客戶端的ξ_i 不同。
不同于經典聯邦學習,本文對每個客戶端使用 L_2 范數的正則化損失函數,如下所示:
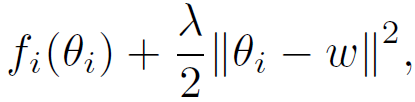
(2)
其中,θ_i 表示客戶端 i 的個性化模型,λ表示控制個性化模型的ω強度的正則化參數。雖然較大的λ可以從豐富的數據聚合中受益于不可靠的數據,但是較小的λ可以幫助擁有足夠多有用數據的客戶端優(yōu)先進行個性化設置。總之,本文方法的目的是 * 允許客戶端沿不同的方向更新本地模型,同時不會偏離每個客戶端都貢獻所得到的“參考點”ω*。個性化聯邦學習可以表述為一個雙層問題:
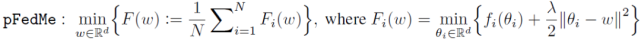
通過在外部層(outer level)利用來自多個客戶端的數據聚合來確定ω,在內部層(inner level)針對客戶端 i 的數據分布優(yōu)化θ_i,并使其與ω保持一定距離。F_i(ω)定義為 Moreau envelope。最優(yōu)個性化模型是解決 pFedMe 內部層問題的唯一解決方案,在文獻中也被稱為鄰近算子(proximal operator),其定義如下:
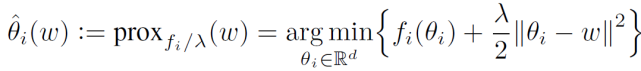
(3)
為了進行比較,作者討論了 Per-FedAvg[13],它可以說是最接近 pFedMe 的公式:
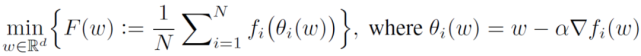
(4)
Per-FedAvg 是一個元學習方法,基于經典元學習的與模型無關的元學習(MAML)框架,Per-FedAvg 的目標是找到一個全局模型ω,可以用它作為初始化全局模型,進一步對損失函數執(zhí)行梯度更新(步長為 α)來得到它的個性化模型θ_i(ω)。
與 Per-FedAvg 相比,本文的問題具有類似于 “元模型” 的考慮,但是沒有使用ω作為初始化,而是通過解決一個雙層問題來并行地求得個性化和全局模型,這種方式有幾個好處:首先,雖然 Per-FedAvg 針對其個性化模型進行了一步梯度更新的優(yōu)化,但 pFedMe 對內部優(yōu)化器是不可知的,這意味著公式(3)可以使用任何具有多步更新的迭代方法來求解。其次,可以將 Per-FedAvg 的個性化模型更新重寫為:
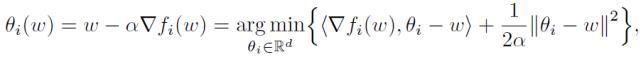
(5)
使用 < x,y > 作為兩個向量 x 和 y 的內積,可以看到除了相似的正則化項外,Per-FedAvg 只優(yōu)化了 f_i 的一階近似,而 pFedMe 直接最小化了公式(3)中的 f_i。第三,Per-FedAvg(或通常基于 MAML 的方法)需要計算或估計 Hessian 矩陣,而 pFedMe 只需要使用一階方法計算梯度。
此外,作者還給出了 Moreau envelope 的一些數學特性證明,這些數學特性能夠保證引入 Moreau envelope 的聯邦學習方法的收斂性。
假設 1(強凸性和光滑性):f_i 分別是(a)μ- 強凸或(b)非凸和 L - 光滑的(即 L-Lipschitz 梯度),如下所示:
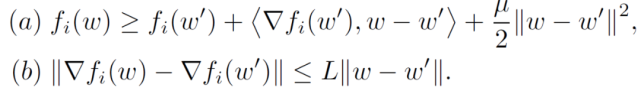
假設 2(有界方差):每個客戶端的隨機梯度方差是有界的:
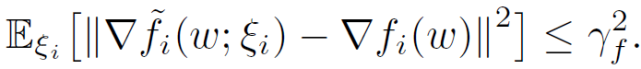
假設 3(有界多樣性):局部梯度對全局梯度的方差是有界的
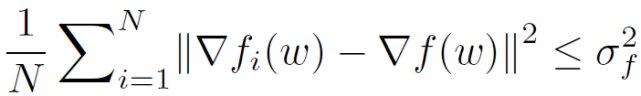
最后,作者回顧了 Moreau envelope 的一些有用的性質,例如平滑和保持凸性。
命題 1:如果 f_i 與 L-Lipschitz-▽f_i 是凸的或非凸的,那么▽f_i 是 L_F - 光滑的,L_F=λ(對于非凸 L - 光滑 f_i,條件是λ>2L),并且有:
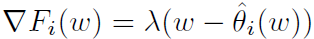
此外,如果 f_i 是μ強凸的,那么 f_i 是 F_i - 強凸的μ_F=λ_μ/(λ+μ)。
最后,作者介紹本文提出的 pFedMe 完整流程如下:

首先,在內部層,每個客戶端 i 求解公式(3)以獲得其個性化模型,其中 w^t_(i,r)表示客戶端 i 在全局輪次 t 和局部輪次 r 的局部模型。與 FedAvg 類似,本地模型的目的是幫助構建全局模型,減少客戶端和服務器之間的通信輪數。其次,在外部層面,使用隨機梯度下降的客戶端 i 的局部更新是關于 F_i(而不是 f_i)的,如下所示
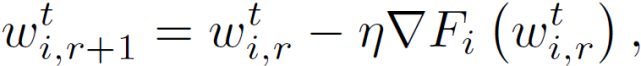
其中,η表示學習速率,使用當前個性化模型和公式 (6) 計算▽F_i。
此外,作者還提出在實際場景中應用時,一般采用滿足下面約束的δ近似的個性化模型:
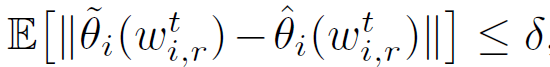
對應的,使用下式完成逼近▽F_i 的計算:
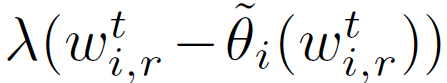
這樣處理的原因有兩個:第一,使用公式(3)計算個性化模型需要計算▽F_i(θ_i),這種計算依賴于ξ_i 的分布。實際上,可以通過對 D_i 的小樣本采樣來計算▽F_i(θ_i)的無偏估計:
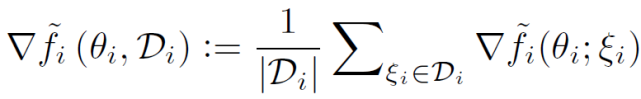
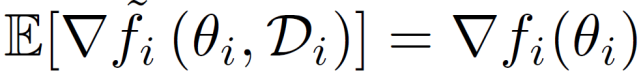
第二,獲取封閉形式的個性化模型是很困難的,相反,通常使用迭代一階方法來獲得高精度的近似值:
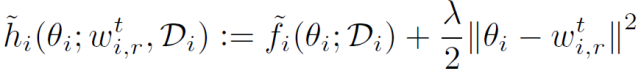
選擇λ,令 h_i 是條件數為 k 的強凸,然后可以應用梯度下降(例如,奈斯特羅夫加速梯度下降(Nesterov’s accelerated
gradient descent)))以獲得個性化模型:
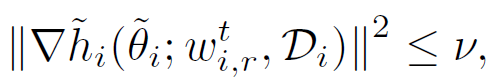
pFedMe 中每個客戶端的計算復雜度是 FedAvg 的 K 倍。
2.2 實驗分析
本文實驗考慮了一個使用真實(MNIST)和合成數據集的分類問題。MNIST 是一個手寫數字數據集,包含 10 個標簽和 70000 個實例。由于 MNIST 數據量的限制,作者將完整的 MNIST 數據集分發(fā)給 N=20 個客戶端。為了根據本地數據大小和類別對異構設置進行建模,每個客戶端都被分配了一個不同的本地數據大小,范圍為 [1165;3834],并且只有 10 個標簽中的 2 個。對于合成數據,作者采用數據生成和分布過程,使用兩個參數 α=0.5 和β=0.5 來控制每個客戶端的本地模型和數據集的差異。具體來說,數據集使用 60 維實值數據為 10 類分類器提供服務。每個客戶端的數據大小在[250;25810] 范圍內。最后,將數據分發(fā)給 N=100 個客戶端。
作者對 pFedMe、FedAvg 和 Per-FedAvg 進行了比較。MNIST 數據集中的實驗結果見圖 4。pFedMe 的個性化模型在強凸設置下的準確率分別比其全局模型 Per-FedAvg 和 FedAvg 高 1.1%、1.3% 和 1.5%。非凸設置下的相應數據為 0.9%、0.9% 和 1.3%。
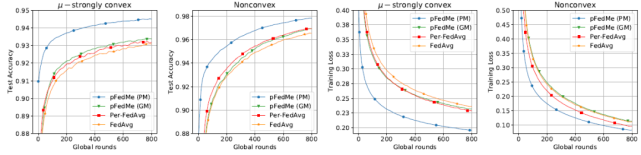
圖 4. 使用 MNIST 的 pFedMe、FedAvg 和 Per-FedAvg 在μ- 強凸和非凸設置下的性能比較
對于合成數據集,利用相同參數和微調參數的比較結果見圖 5。在圖 5 中,盡管 pFedMe 的全局模型在測試準確率和訓練損失方面表現不如其他模型,但 pFedMe 的個性化模型仍然顯示出它的優(yōu)勢,因為它獲得了最高的測試準確率和最小的訓練損失。圖 5 顯示,pFedMe 的個性化模型比其全局模型 Per-FedAvg 和 FedAvg 的準確率分別高出 6.1%、3.8% 和 5.2%。
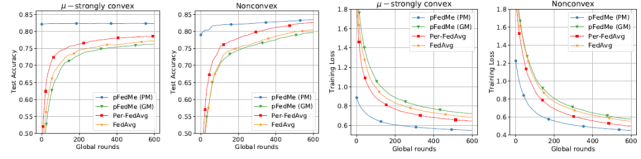
圖 5. 使用合成數據集的 pFedMe、FedAvg 和 Per-FedAvg 在μ- 強凸和非凸設置下的性能比較
從實驗結果來看,當客戶端之間的數據是非獨立同分布(Non-IID)時,pFedMe 和 Per-FedAvg 都獲得了比 FedAvg 更高的測試準確度,因為這兩種方法允許全局模型針對特定客戶端進行個性化處理。通過多次梯度更新近似優(yōu)化個性化模型從而避免計算 Hessian 矩陣,pFedMe 的個性化模型在收斂速度和計算復雜度方面比 Per-FedAvg 更具優(yōu)勢。
2.3 論文小結
本文提出了一種個性化聯邦學習方法 pFedMe。pFedMe 利用了 Moreau envelope 函數,該函數有助于將個性化模型優(yōu)化從全局模型學習中分解出來,從而使得 pFedMe 可以類似于 FedAvg 更新全局模型,但又能根據 t 每個客戶端的本地數據分布并行優(yōu)化個性化模型。理論結果表明,pFedMe 可以達到最快的收斂加速率。實驗結果表明,在凸和非凸環(huán)境下,使用真實和合成數據集,pFedMe 的性能都優(yōu)于經典 FedAvg 和基于元學習的個性化聯邦學習算法 Per-FedAvg。
三、Personalized Federated Learning for Intelligent IoT Applications: A Cloud-Edge based Framework

復雜物聯網環(huán)境中固有的設備、統(tǒng)計和模型的異構性給傳統(tǒng)的聯邦學習帶來了巨大挑戰(zhàn),使其無法直接部署應用。為了解決物聯網環(huán)境中的異構性問題,本文重點研究個性化聯邦學習方法,這種方法能夠減輕異質性帶來的負面影響。此外,借助邊緣計算的能力,個性化聯邦學習能夠滿足智能物聯網應用對快速處理能力和低延遲的要求。
邊緣計算的提出主要是為了解決設備異構性中的高通信和計算成本問題,從而為物聯網設備提供了按需計算的能力。因此,每個物聯網設備可以選擇將其計算密集型學習任務卸載到邊緣,以滿足快速處理能力和低延遲的要求。此外,邊緣計算可以通過在本地就近存儲數據的方式(例如,在智能家庭應用的智能邊緣網關中)解決隱私問題,而無需將數據上傳到遠程云。還可以采用差分隱私和同態(tài)加密等隱私和安全保護技術來提高隱私保護水平。
本文提出了一個用于個性化聯邦學習的協同云邊緣框架 PerFit,該框架能夠從整體上緩解物聯網應用中固有的設備異構性、統(tǒng)計異構性和模型異構性問題。對于統(tǒng)計和模型的異構性,該框架還允許終端設備和邊緣服務器在云邊緣范例中的中心云服務器的協調下共同訓練一個全局模型。在對全局模型進行學習訓練后,在客戶端設備中可以采用不同的個性化聯邦學習方法,根據不同設備的應用需求對其進行個性化模型部署。
3.1 方法介紹
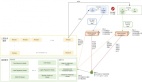
本文提出了一個針對智能物聯網應用的個性化聯邦學習框架,以整體的方式應對設備異構性、數據異構性和模型異構性挑戰(zhàn)。如圖 6 所示,本文提出的 PerFit 框架采用云邊緣架構,為物聯網設備提供必要的按需邊緣計算能力。每個物聯網設備可以選擇通過無線連接將其密集的計算任務轉移到邊緣設備中(即家中的邊緣網關、辦公室的邊緣服務器或室外的 5G MEC 服務器),從而滿足物聯網應用的高處理效率和低延遲的要求。
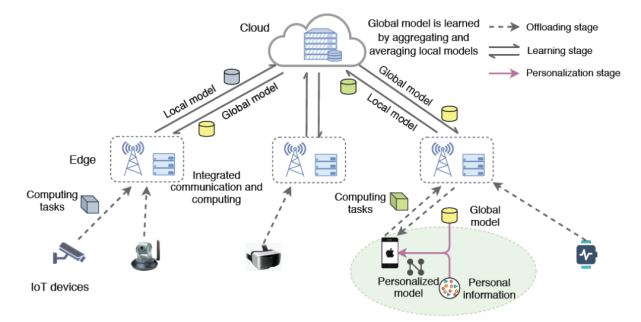
圖 6. 智能物聯網應用的個性化聯邦學習框架,支持靈活選擇個性化的聯邦學習方法
具體來說,PerFit 中的協作學習過程主要包括以下三個階段,如圖 6 中所述:
卸載階段(Offloading stage)。當邊緣設備是可信的(例如,家中的邊緣網關),物聯網設備用戶可以將其整個學習模型和數據樣本卸載到邊緣設備中以進行快速計算。否則,設備用戶將通過將輸入層及其數據樣本本地保存在其設備上并將剩余的模型層卸載到邊緣設備中以進行設備邊緣協作計算來執(zhí)行模型劃分。
學習階段(Learning stage)。邊緣設備根據個人數據樣本協同計算本地模型,然后將本地模型信息傳輸到云服務器。云服務器將各個邊緣設備所提交的本地模型信息聚合起來,并將它們平均化為一個全局模型,然后發(fā)送回各個邊緣設備中。這樣的模型信息交換過程不斷重復,直到經過一定次數的迭代后收斂為止。因此,可以實現一個高質量的全局模型,然后傳輸到邊緣設備以進行進一步的個性化設置。
個性化階段(Personalization stage)。為了捕捉特定的個人特征和需求,每個邊緣設備都基于全局模型信息和自身的個人信息(即本地數據)訓練一個個性化模型。這一階段的具體學習操作取決于采用的個性化聯邦學習機制。例如,遷移學習、多任務學習、元學習、知識蒸餾、混合模型等。
進一步,在邊緣設備上進行本地模型聚合,也有助于避免大量設備通過昂貴的主干網帶寬與云服務器直接通信,從而降低通信開銷。通過執(zhí)行個性化處理,可以在一些資源有限的設備上部署輕量級的個性化模型(例如,通過模型修剪或傳輸學習)。這將有助于減輕設備在通信和計算資源方面的異構性。此外,也可以很好的支持統(tǒng)計異構性和模型異構性,因為該框架可以根據不同邊緣設備的本地數據特性、應用程序需求和部署環(huán)境利用個性化的模型和機制。
PerFit 通過在邊緣設備和云服務器之間交換不同類型的模型信息,能夠靈活地集成多種個性化的聯邦學習方法,包括我們在這篇文章中分析的兩種個性化聯邦學習方法。通過解決復雜物聯網環(huán)境中固有的異構性問題并在默認情況下確保用戶隱私,PerFit 可以成為大規(guī)模實際部署的理想選擇。
3.2 個性化聯邦學習機制
作者在文章中回顧并簡述了幾個個性化聯合學習機制,這些機制可以與 PerFit 框架集成用于智能物聯網應用程序。文中重點分析了以下幾種類型:聯邦遷移學習,聯邦元學習,聯邦多任務學習、聯邦蒸餾和數據增強。
3.2.1 聯邦遷移學習
聯邦遷移學習的基本思想是將全局共享模型遷移到分布式物聯網設備上(客戶端設備),通過針對各個物聯網設備實現個性化處理,以減輕聯邦學習中固有的數據異構性問題(Non-IID 數據分布)。考慮到深度神經網絡的結構和通信過載問題,通過聯邦轉移學習實現個性化的方法主要有兩種。具體可見圖 7。
圖 7(a)中為 Chen 在文獻 [14] 中提出的聯邦遷移學習方法。首先通過經典的聯邦學習訓練一個全局模型,然后將全局模型發(fā)送至每個客戶端設備。每個設備都能夠通過使用其本地數據來改進、細化全局模型從而構建個性化模型。為了減少訓練開銷,只對指定層的模型參數進行微調,而不是對整個模型進行再訓練。由圖 7(a)可見,由于深度網絡的底層側重于學習全局(公共的)和底層特征,因此,在全局模型中的這些底層參數可以傳輸到局部模型中后直接復用。而傳入的更高層的全局模型參數則應該根據本地數據進行微調,以便學習到針對當前設備定制的更具體的個性化特性。
Arivazhagan 等在文獻 [15] 中提出了另一類聯邦遷移學習方法 FedPer。FedPer 主張將深度學習模型視為基礎 + 個性化層,如圖 7(b)所示。其中,將基本層作為共享層,使用現有的聯邦學習方法(即 FedAvg 方法)以協作方式進行訓練。而個人化層在本地進行訓練,從而能夠捕獲物聯網設備的個人信息。在聯邦學習一個階段的訓練過程之后,可以將全局共享的基礎層轉移到參與的物聯網設備上,以其獨特的個性化層構建自己的個性化深度學習模型。因此,FedPer 能夠捕捉到特定設備上的細粒度信息,以進行更好的個性化推理或分類,并在一定程度上解決數據異構性問題。此外,由于只需要上傳和聚合部分模型,FedPer 需要較少的計算和通信開銷,這在物聯網環(huán)境中是至關重要的。
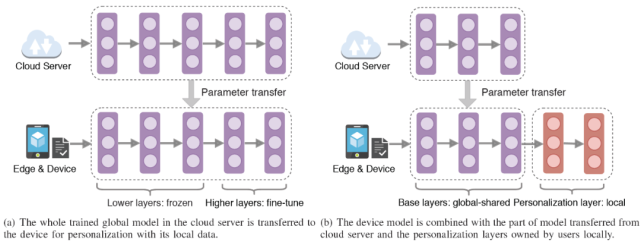
圖 7. 兩種聯邦遷移學習架構
3.2.2 聯邦元學習
在元學習中,模型是由一個能夠學習大量相似任務的元學習者(a Meta-Learner)來訓練的,訓練模型的目標是從少量的新數據中快速適應新的相似任務。聯邦元學習是指將元學習中的相似任務作為設備的個性化模型,將聯邦學習與元學習相結合,通過協作學習實現個性化處理。Jiang 等在文獻 [16] 中提出了一種改進的個性化 FedAvg。該方法通過引入一個精細化調整階段,該精細化調整階段使用模型不可知的元學習算法(model agnostic meta learning,MAML)。通過聯邦學習訓練得到的全局模型可以個性化地捕捉單個設備中的細粒度信息,從而提高每個物聯網設備的性能。MAML 可以靈活地與任何模型表示相結合,以適應基于梯度的訓練。此外,它只需少量的數據樣本就可以快速學習和個性化適應處理。
由于聯邦元學習方法通常使用復雜的訓練算法,因此,與聯邦遷移學習方法相比,聯邦元學習方法實現的復雜度較高。不過,聯邦元學習方法的學習模型更健壯,這一特性對于數據樣本很少的設備是非常有用的。
3.2.3 聯邦多任務學習
由前兩節(jié)的分析可知,聯邦遷移學習和聯邦元學習的目的是通過個性化微調處理,在物聯網設備上學習相同或相似任務的共享模型。與這種思路不同的是,聯邦多任務學習的目標是同時學習不同設備的不同任務,并試圖在沒有隱私風險的情況下捕捉它們之間的模型關系(Model Relationships)。利用這種模型關系,每個設備的模型可以獲取其他設備的信息。此外,為每個設備學習的模型總是個性化的。
由圖 8 所示,在聯邦多任務學習訓練過程中,云服務器根據物聯網設備上傳的模型參數,學習多個學習任務之間的模型關系。然后,每個設備可以用其本地數據和當前模型關系更新自己的模型參數。聯邦多任務學習通過交替優(yōu)化云服務器中的模型關系和每個任務的模型參數,使參與其中的物聯網設備能夠協同訓練其本地模型,從而減輕數據異構性,獲得高質量的個性化模型。
文獻 [17] 中提出了一種分布式優(yōu)化方法 MOCHA。為了應對高通信成本的問題,MOCHA 具有一定的計算靈活性,從而通過執(zhí)行額外的本地計算的方式造成在聯邦環(huán)境下的通信輪次更少。為了減少最終結果的離散程度,作者建議在計算資源有限的情況下近似計算設備的本地更新。此外,異步更新方案也是避免離散問題的一種替代方法。此外,通過允許參與設備周期性地退出,MOCHA 具有健壯的容錯性。由于復雜物聯網環(huán)境中固有的設備異構性對聯邦學習的性能至關重要,聯邦多任務學習對于智能物聯網應用具有重要意義。
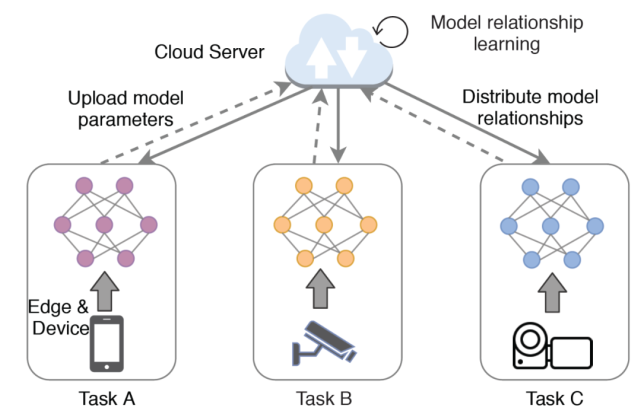
圖 8. 聯邦多任務學習
3.2.4 聯邦蒸餾方法
在經典聯邦學習框架中,所有的客戶機(例如參與的邊緣設備)都必須同意在全局服務器和本地客戶機上訓練得到的模型的特定體系結構。然而,在一些現實的商業(yè)環(huán)境中,如醫(yī)療保健領域和金融領域等,每個參與者都有能力和意愿設計自己獨特的模型,并且可能出于隱私和知識產權的考慮而不愿意分享模型細節(jié)。這種模型異構性對傳統(tǒng)的聯邦學習提出了新的挑戰(zhàn)。
Li 等在文獻 [18] 中提出了一個新的聯邦學習框架 FedMD,使參與者能夠利用知識蒸餾的方法獨立地設計自己的模型。在 FedMD 中,每個客戶機獨立的將所學知識轉化為標準格式,在不共享數據和模型體系結構的情況下確保其他人可以理解該格式。中央服務器收集這些知識來計算全局模型,并將其進一步分發(fā)給參與的客戶機。知識轉換步驟可以通過知識蒸餾來實現,例如,使用客戶模型產生的類概率作為標準格式,如圖 9 所示。通過這種方式,云服務器聚合并平均每個數據樣本的類概率,然后分發(fā)到客戶機以指導其更新。
Jeong 等在文獻 [19] 中提出一種聯邦蒸餾方法,其中每個客戶機將自己視為學生,并將所有其他客戶機的平均模型輸出視為其教師的輸出。教師與學生的產出差異為學生提供了學習的方向。這里值得注意的是,為了在聯邦學習中進行知識提煉,需要一個公共數據集,因為教師和學生的輸出應該使用相同的訓練數據樣本進行評估。
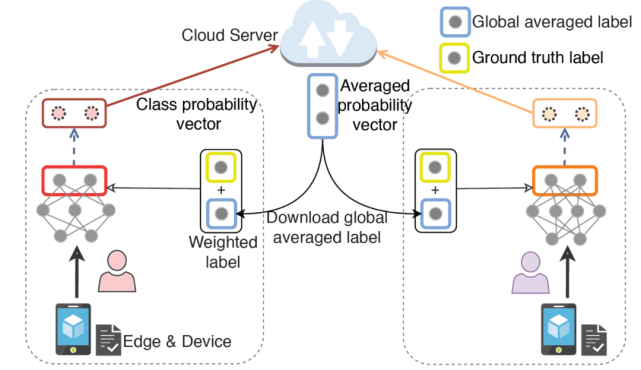
圖 9. 聯邦蒸餾
3.2.5 數據增強
Zhao 等提出了一種數據共享策略,將一些均勻分布的全局數據從云端(中央服務器)分發(fā)到邊緣客戶端[20],從而在一定程度上緩解客戶數據高度不平衡的分布狀況,從而提高個性化模型的性能。然而,直接將全局數據分發(fā)到邊緣客戶端會帶來很大的隱私泄露風險,這種方法需要在數據隱私保護和性能改進之間進行權衡。此外,全局共享數據與用戶本地數據的分布差異也會導致性能下降。
為了在不損害用戶隱私的前提下糾正不平衡的 Non-IID 局部數據集問題,研究人員采用了一些具有生成能力的過采樣技術和深度學習方法。Jeong 等提出了一種聯邦擴充方法(Federated Augmentation,FAug)[21],其中每個客戶機共同訓練一個生成模型,從而擴充其本地數據以生成 IID 數據集。具體地說,每個邊緣客戶機識別其數據樣本中缺少的標簽(稱為目標標簽),然后將這些目標標簽的少數種子數據樣本上載到服務器。服務器對上傳的種子數據樣本進行過采樣,然后訓練一個生成性對抗網絡(Generative Atterial Network,GAN)。最后,每個設備可以下載經過訓練的 GAN 發(fā)生器來補充其目標標簽,直到得到一個平衡的數據集。通過數據擴充,每個客戶機可以根據生成的數據集訓練出一個更加個性化和精確的用于分類或推理任務的模型。值得注意的是,FAug 的服務器應該是可信的,這樣用戶才愿意上傳他們的個人數據。
3.3 實驗分析
本文實驗基于一個名為 MobiAct 的可公開訪問的數據集完成,該數據集重點研究人類活動識別任務。每個參與構建 MobiAct 數據集的志愿者都戴著三星 Galaxy S3 智能手機,帶有加速計和陀螺儀傳感器。志愿者在進行預定活動時,三軸線性加速度計和角速度信號由嵌入式傳感器記錄。使用 1 秒的滑動窗口進行特征提取,因為一秒鐘就足夠執(zhí)行一個活動。MobiAct 中記錄了 10 種活動,如步行、上下樓梯、摔倒、跳躍、慢跑、踏車等。為了實際模擬聯邦學習的環(huán)境,本文實驗隨機選擇了 30 名志愿者,并將他們視為不同的客戶端。對于每個客戶端,為每個活動隨機抽取若干個樣本,最后,每個客戶端有 480 個樣本用于模型訓練。這樣,不同客戶端的個人數據可能呈現出 Non-IID 分布(統(tǒng)計異質性)。每個客戶端的測試數據由分布均衡的 160 個樣本組成。
使用兩種模型進行客戶端中的個性化學習。1) 多層感知器網絡由三個完全連接的層組成,有 400 個、100 個和 10 個神經單元(總參數 521510 個),記作 3NN。2) 卷積神經網絡(CNN),有三個 3×3 的卷積層(第一層有 32 個通道,第二個有 16 個通道,最后一個有 8 個通道,前兩層每個都有一個 2×2 最大池化層),一個有 128 個單元和 ReLu 激活的全連接層,以及一個最終的 Softmax 輸出層(總參數為 33698)。采用交叉熵損失和隨機梯度下降(SGD)優(yōu)化算法訓練 3NN 和 CNN,學習率為 0.01。
作者選擇集中式學習、經典聯邦學習方法作為基準方法。對于集中式方法,采用了支持向量機(SVM)、k - 最近鄰(kNN)和隨機森林(RF)等常用的機器學習方法。此外,還采用了集中式 3NN(c3NN)和集中式 CNN(cCNN)進行比較。對于個性化聯邦學習,作者選擇了兩種被廣泛采用的方法:聯邦遷移學習(Federated Transfer Learning ,FTL)和聯邦蒸餾(Federated Distillation,FD)。對于 FTL,每個客戶端設備將使用其個人數據對從云服務器下載的模型進行微調。而在 FD 中,每個客戶端可以根據自己的需求定制自己的模型。
圖 10 給出了 30 個客戶端在不同學習方法下的測試準確度。對于集中式方法,基于深度學習的方法(c3NN、cCNN)可以比傳統(tǒng)的基于機器學習的方法(SVM、kNN 和 RF)獲得更高的準確度。經典聯邦學習(FL-CNN)中的邊緣客戶端在中央云服務器的協調下,能夠在不損害數據隱私的前提下改進識別性能,并達到與 cCNN 類似的 85.22% 的識別率。FL-3NN 和 FL-CNN 與集中式模式相比性能略有下降,這是由于聯邦學習環(huán)境中固有的統(tǒng)計異質性造成的。通過個性化的聯邦學習,FTL 和 FD 都可以捕捉到用戶細粒度的個人信息,并為每個參與者獲得個性化的模型,從而獲得更高的測試準確度。例如,FTL-3NN 識別率可達 95.37%,比 FL3NN 高 11.12%。
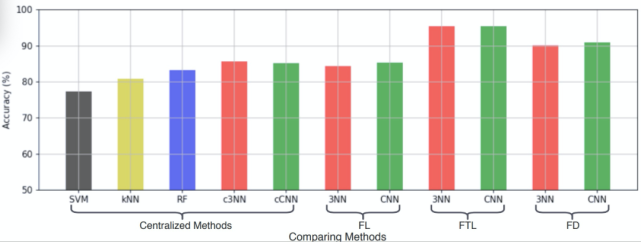
圖 10. 不同學習方法在人體活動識別中的準確性研究
3.4 論文小結
本文提出了一個云邊緣架構中的個性化聯邦學習框架 PerFit,用于具有數據隱私保護的智能物聯網應用。PerFit 能夠通過聚合來自分布式物聯網設備的本地更新并利用邊緣計算的優(yōu)點來學習全局共享模型。為了解決物聯網環(huán)境中的設備、統(tǒng)計和模型的異構性,PerFit 可以自然地集成各種個性化聯邦學習方法,從而實現物聯網應用中設備的個性化處理并增強性能。通過一個人類活動識別任務的案例研究,作者證明了 PerFit 的有效性。
4、總結
在這篇文章中,我們聚焦了個性化聯邦學習的問題。聯邦學習是一個有效的處理分布式數據訓練的解決方案,它能夠通過聚集和平均本地計算的更新來協作訓練高質量的共享全局模型。此外,聯邦學習能夠在不損害用戶數據隱私的情況下學習得到令人滿意的全局模型。然而,由于分布式處理方式的固有弊端,聯邦學習面臨設備異構性、數據異構性和模型異構性等問題,在實際推廣應用中存在無法直接部署的風險。
個性化聯邦學習的目的是根據不同設備的應用需求對其進行個性化模型部署,以解決各類異構性問題。本文選擇了專門針對于設備異構性和模型異構性問題的兩篇文章進行詳細分析,最后還選擇了一篇文章介紹在物聯網應用的云邊緣架構中使用的個性化聯邦學習框架。由我們選擇的幾篇論文中作者進行的理論分析和實驗給出的結果可以看出,個性化聯邦學習確實可以改進經典聯邦學習方法的效果,能夠有效應對客戶端設備中的各種異構性情況,甚至能夠處理一些設備宕機 / 存儲空間已滿等臨時性失效的問題。聯邦學習在各類實際場景中都有著巨大的應用需求,我們會繼續(xù)關注個性化聯邦學習的技術發(fā)展和部署應用方法。