













多個(gè)SOTA !OV-Uni3DETR:提高3D檢測(cè)在類別、場(chǎng)景和模態(tài)之間的普遍性(清華&港大)
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
這篇論文聚焦于3D目標(biāo)檢測(cè)的領(lǐng)域,特別是Open-Vocabulary的3D目標(biāo)檢測(cè)。在傳統(tǒng)的3D目標(biāo)檢測(cè)任務(wù)中,系統(tǒng)旨在預(yù)測(cè)真實(shí)場(chǎng)景中物體的定向3D邊界框和語義類別標(biāo)簽,這通常依賴于點(diǎn)云或RGB圖像。盡管2D目標(biāo)檢測(cè)技術(shù)因其普遍性而迅速發(fā)展,但相關(guān)研究表明,3D通用檢測(cè)的發(fā)展相比之下顯著滯后。當(dāng)前,大多數(shù)3D目標(biāo)檢測(cè)方法仍然依賴于完全監(jiān)督學(xué)習(xí),并受到特定輸入模式下完全標(biāo)注數(shù)據(jù)的限制,只能識(shí)別訓(xùn)練過程中出現(xiàn)的類別,無論是在室內(nèi)還是室外場(chǎng)景中。
這篇論文指出,3D通用目標(biāo)檢測(cè)面臨的挑戰(zhàn)主要包括:現(xiàn)有的3D檢測(cè)器僅能在封閉詞匯的情況下工作,因此只能檢測(cè)已見過的類別。緊迫需要Open-Vocabulary的3D目標(biāo)檢測(cè),以識(shí)別和定位訓(xùn)練過程中未獲取的新類別目標(biāo)實(shí)例。然而,現(xiàn)有的3D檢測(cè)數(shù)據(jù)集在大小和類別上與2D數(shù)據(jù)集相比都有限制,這限制了在定位新目標(biāo)方面的泛化能力。此外,3D領(lǐng)域缺乏預(yù)訓(xùn)練的圖像-文本模型,這進(jìn)一步加劇了Open-Vocabulary3D檢測(cè)的挑戰(zhàn)。同時(shí),缺乏一種針對(duì)多模態(tài)3D檢測(cè)的統(tǒng)一架構(gòu),現(xiàn)有的3D檢測(cè)器大多設(shè)計(jì)用于特定的輸入模態(tài)(點(diǎn)云、RGB圖像或兩者)和場(chǎng)景(室內(nèi)或室外),這阻礙了有效利用來自不同模態(tài)和來源的數(shù)據(jù),從而限制了對(duì)新目標(biāo)的泛化能力。
為了解決上述問題,論文提出了一種稱為OV-Uni3DETR的統(tǒng)一多模態(tài)3D檢測(cè)器。該檢測(cè)器在訓(xùn)練期間能夠利用多模態(tài)和多來源數(shù)據(jù),包括點(diǎn)云、帶有精確3D框標(biāo)注并與點(diǎn)云對(duì)齊的3D檢測(cè)圖像,以及僅帶有2D框標(biāo)注的2D檢測(cè)圖像。通過這種多模態(tài)學(xué)習(xí)方式,OV-Uni3DETR能夠在推理時(shí)處理任何模態(tài)的數(shù)據(jù),實(shí)現(xiàn)測(cè)試時(shí)的模態(tài)切換,并在檢測(cè)基礎(chǔ)類別和新類別上表現(xiàn)出色。統(tǒng)一的結(jié)構(gòu)進(jìn)一步使OV-Uni3DETR能夠在室內(nèi)和室外場(chǎng)景中進(jìn)行檢測(cè),具備Open-Vocabulary能力,從而顯著提高3D檢測(cè)器在類別、場(chǎng)景和模態(tài)之間的普遍性。
此外,針對(duì)如何泛化檢測(cè)器以識(shí)別新類別的問題,以及如何從沒有3D框標(biāo)注的大量2D檢測(cè)圖像中學(xué)習(xí)的問題,論文提出了一種稱為周期模態(tài)傳播的方法——在2D和3D模態(tài)之間傳播知識(shí)以解決這兩個(gè)挑戰(zhàn)。通過這種方法,2D檢測(cè)器的豐富語義知識(shí)可以傳播到3D領(lǐng)域,以協(xié)助發(fā)現(xiàn)新的框,而3D檢測(cè)器的幾何知識(shí)則可以用于在2D檢測(cè)圖像中定位目標(biāo),并通過匈牙利匹配分配類別標(biāo)簽。
論文的主要貢獻(xiàn)包括提出了一個(gè)能夠在不同模態(tài)和多樣化場(chǎng)景中檢測(cè)任何類別目標(biāo)的統(tǒng)一Open-Vocabulary3D檢測(cè)器OV-Uni3DETR;提出了一個(gè)針對(duì)室內(nèi)和室外場(chǎng)景的統(tǒng)一多模態(tài)架構(gòu);以及提出了2D和3D模態(tài)之間知識(shí)傳播循環(huán)的概念。通過這些創(chuàng)新,OV-Uni3DETR在多個(gè)3D檢測(cè)任務(wù)上實(shí)現(xiàn)了最先進(jìn)的性能,并在Open-Vocabulary設(shè)置下顯著超過了之前的方法。這些成果表明,OV-Uni3DETR為3D基礎(chǔ)模型的未來發(fā)展邁出了重要一步。

OV-Uni3DETR方法詳解
Multi-Modal Learning

這篇論文提出了一種多模態(tài)學(xué)習(xí)架構(gòu),專門針對(duì)3D目標(biāo)檢測(cè)任務(wù),通過整合點(diǎn)云數(shù)據(jù)和圖像數(shù)據(jù)來增強(qiáng)檢測(cè)性能。這種架構(gòu)能夠處理在推理時(shí)可能缺失的某些傳感器模態(tài),即具備測(cè)試時(shí)模態(tài)切換的能力。通過特定的網(wǎng)絡(luò)結(jié)構(gòu)提取并整合來自兩種不同模態(tài)的特征,即3D點(diǎn)云特征和2D圖像特征,這些特征分別經(jīng)過體素化處理和相機(jī)參數(shù)映射后,被融合用于后續(xù)的目標(biāo)檢測(cè)任務(wù)。
關(guān)鍵的技術(shù)點(diǎn)包括使用3D卷積和批量歸一化來規(guī)范化和整合不同模態(tài)的特征,防止在特征級(jí)別上的不一致性導(dǎo)致某一模態(tài)被忽略。此外,采用隨機(jī)切換模態(tài)的訓(xùn)練策略,確保模型能夠靈活地處理僅來自單一模態(tài)的數(shù)據(jù),從而提高模型的魯棒性和適應(yīng)性。
最終,該架構(gòu)利用復(fù)合損失函數(shù),結(jié)合了類別預(yù)測(cè)、2D和3D邊界框回歸的損失,以及一個(gè)用于加權(quán)回歸損失的不確定性預(yù)測(cè),來優(yōu)化整個(gè)檢測(cè)流程。這種多模態(tài)學(xué)習(xí)方法不僅提高了對(duì)現(xiàn)有類別的檢測(cè)性能,而且通過融合不同類型的數(shù)據(jù),增強(qiáng)了對(duì)新類別的泛化能力。多模態(tài)架構(gòu)最終預(yù)測(cè)類別標(biāo)簽、4維2D框和7維3D框,用于2D和3D目標(biāo)檢測(cè)。對(duì)于3D框回歸,使用L1損失和解耦I(lǐng)oU損失;對(duì)于2D框回歸,使用L1損失和GIoU損失。在Open-Vocabulary設(shè)置中,存在新類別樣本,這增加了訓(xùn)練樣本的難度。因此,引入了不確定性預(yù)測(cè)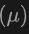 ,并用它來加權(quán)L1回歸損失。目標(biāo)檢測(cè)學(xué)習(xí)的損失為:
,并用它來加權(quán)L1回歸損失。目標(biāo)檢測(cè)學(xué)習(xí)的損失為:
對(duì)于某些3D場(chǎng)景,可能存在多視圖圖像,而不是單一的單眼圖像。對(duì)于它們中的每一個(gè),提取圖像特征并使用各自的投影矩陣投影到體素空間。體素空間中的多個(gè)圖像特征被求和以獲取多模態(tài)特征。這種方法通過結(jié)合來自不同模態(tài)的信息,提高了模型對(duì)新類別的泛化能力,并增強(qiáng)了在多樣化輸入條件下的適應(yīng)性。
Knowledge Propagation: 2D—3D
在介紹的多模態(tài)學(xué)習(xí)基礎(chǔ)上,文中針對(duì)Open-Vocabulary的3D檢測(cè)執(zhí)行了一種稱為“知識(shí)傳播: ”的方法。Open-Vocabulary學(xué)習(xí)的核心問題是識(shí)別訓(xùn)練過程中未經(jīng)人工標(biāo)注的新類別。由于獲取點(diǎn)云數(shù)據(jù)的難度,預(yù)訓(xùn)練的視覺-語言模型尚未在點(diǎn)云領(lǐng)域被開發(fā)。點(diǎn)云數(shù)據(jù)與RGB圖像之間的模態(tài)差異限制了這些模型在3D檢測(cè)中的性能。
”的方法。Open-Vocabulary學(xué)習(xí)的核心問題是識(shí)別訓(xùn)練過程中未經(jīng)人工標(biāo)注的新類別。由于獲取點(diǎn)云數(shù)據(jù)的難度,預(yù)訓(xùn)練的視覺-語言模型尚未在點(diǎn)云領(lǐng)域被開發(fā)。點(diǎn)云數(shù)據(jù)與RGB圖像之間的模態(tài)差異限制了這些模型在3D檢測(cè)中的性能。

為了解決這個(gè)問題,提出利用預(yù)訓(xùn)練的2DOpen-Vocabulary檢測(cè)器的語義知識(shí),并為新類別生成相應(yīng)的3D邊界框。這些生成的3D框?qū)⒀a(bǔ)充訓(xùn)練時(shí)可用類別有限的3D真實(shí)標(biāo)簽。
具體來說,首先使用2DOpen-Vocabulary檢測(cè)器生成2D邊界框或?qū)嵗谡帧?紤]到在2D領(lǐng)域可用的數(shù)據(jù)和標(biāo)注更為豐富,這些生成的2D框能夠?qū)崿F(xiàn)更高的定位精度,并覆蓋更廣泛的類別范圍。然后,通過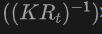 將這些2D框投影到3D空間,以獲得相應(yīng)的3D框。具體操作是使用
將這些2D框投影到3D空間,以獲得相應(yīng)的3D框。具體操作是使用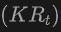
將3D點(diǎn)投影到2D空間,找到2D框內(nèi)的點(diǎn),然后對(duì)2D框內(nèi)的這些點(diǎn)進(jìn)行聚類以消除離群值,從而獲得相應(yīng)的3D框。由于預(yù)訓(xùn)練的2D檢測(cè)器的存在,未標(biāo)注的新目標(biāo)可以在生成的3D框集中被發(fā)現(xiàn)。通過這種方式,從2D領(lǐng)域到生成的3D框傳播的豐富語義知識(shí),極大地促進(jìn)了3DOpen-Vocabulary檢測(cè)。對(duì)于多視圖圖像,分別生成3D框并將它們集成在一起以供最終使用。
在推理過程中,當(dāng)點(diǎn)云和圖像都可用時(shí),可以以類似的方式提取3D框。這些生成的3D框也可以視為3DOpen-Vocabulary檢測(cè)結(jié)果的一種形式。將這些3D框添加到多模態(tài)3D變換器的預(yù)測(cè)中,以補(bǔ)充可能缺失的目標(biāo),并通過3D非極大值抑制(NMS)過濾重疊的邊界框。由預(yù)訓(xùn)練的2D檢測(cè)器分配的置信度得分通過預(yù)定的常數(shù)系統(tǒng)地除以,然后重新解釋為相應(yīng)3D框的置信度得分。
實(shí)驗(yàn)

表格展示了OV-Uni3DETR在SUN RGB-D和ScanNet數(shù)據(jù)集上進(jìn)行Open-Vocabulary3D目標(biāo)檢測(cè)的性能。實(shí)驗(yàn)設(shè)置與CoDA完全相同,使用的數(shù)據(jù)來自CoDA官方發(fā)布的代碼。性能指標(biāo)包括新類別平均精度 、基類平均精度
、基類平均精度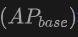 和所有類平均精度
和所有類平均精度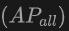 。輸入類型包括點(diǎn)云(P)、圖像(I)以及它們的組合(P+I)。
。輸入類型包括點(diǎn)云(P)、圖像(I)以及它們的組合(P+I)。
分析這些結(jié)果,我們可以觀察到以下幾點(diǎn):
- 多模態(tài)輸入的優(yōu)勢(shì):當(dāng)使用點(diǎn)云和圖像的組合作為輸入時(shí),OV-Uni3DETR在兩個(gè)數(shù)據(jù)集的所有評(píng)價(jià)指標(biāo)上都取得了最高分,尤其是在新類別平均精度
 上的提升最為顯著。這表明結(jié)合點(diǎn)云和圖像可以顯著提高模型對(duì)未見類別的檢測(cè)能力,以及整體檢測(cè)性能。
上的提升最為顯著。這表明結(jié)合點(diǎn)云和圖像可以顯著提高模型對(duì)未見類別的檢測(cè)能力,以及整體檢測(cè)性能。 - 對(duì)比其他方法:與其他基于點(diǎn)云的方法相比(如Det-PointCLIP、Det-PointCLIPv2、Det-CLIP、3D-CLIP和CoDA),OV-Uni3DETR在所有評(píng)價(jià)指標(biāo)上都展現(xiàn)出優(yōu)異的性能。這證明了OV-Uni3DETR在處理Open-Vocabulary3D目標(biāo)檢測(cè)任務(wù)上的有效性,尤其是在利用多模態(tài)學(xué)習(xí)和知識(shí)傳播策略方面。
- 圖像與點(diǎn)云輸入的比較:僅使用圖像(I)作為輸入的OV-Uni3DETR雖然在性能上低于使用點(diǎn)云(P)作為輸入的情況,但依然表現(xiàn)出不錯(cuò)的檢測(cè)能力。這證明了OV-Uni3DETR架構(gòu)的靈活性和對(duì)單一模態(tài)數(shù)據(jù)的適應(yīng)能力,同時(shí)也強(qiáng)調(diào)了融合多種模態(tài)數(shù)據(jù)對(duì)提升檢測(cè)性能的重要性。
- 在新類別上的表現(xiàn):OV-Uni3DETR在新類別平均精度
 上的表現(xiàn)尤其值得關(guān)注,這對(duì)于Open-Vocabulary檢測(cè)尤為關(guān)鍵。在SUN RGB-D數(shù)據(jù)集上,使用點(diǎn)云和圖像輸入時(shí)的
上的表現(xiàn)尤其值得關(guān)注,這對(duì)于Open-Vocabulary檢測(cè)尤為關(guān)鍵。在SUN RGB-D數(shù)據(jù)集上,使用點(diǎn)云和圖像輸入時(shí)的 達(dá)到了12.96%,在ScanNet數(shù)據(jù)集上達(dá)到了15.21%,這顯著高于其他方法,顯示了其在識(shí)別訓(xùn)練過程中未見過的類別上的強(qiáng)大能力。
達(dá)到了12.96%,在ScanNet數(shù)據(jù)集上達(dá)到了15.21%,這顯著高于其他方法,顯示了其在識(shí)別訓(xùn)練過程中未見過的類別上的強(qiáng)大能力。
總的來說,OV-Uni3DETR通過其統(tǒng)一的多模態(tài)學(xué)習(xí)架構(gòu),在Open-Vocabulary3D目標(biāo)檢測(cè)任務(wù)上表現(xiàn)出卓越的性能,尤其是在結(jié)合點(diǎn)云和圖像數(shù)據(jù)時(shí),能夠有效提升對(duì)新類別的檢測(cè)能力,證明了多模態(tài)輸入和知識(shí)傳播策略的有效性和重要性。

這個(gè)表格展示了OV-Uni3DETR在KITTI和nuScenes數(shù)據(jù)集上進(jìn)行Open-Vocabulary3D目標(biāo)檢測(cè)的性能,涵蓋了在訓(xùn)練過程中已見(base)和未見(novel)的類別。對(duì)于KITTI數(shù)據(jù)集,"car"和"cyclist"類別在訓(xùn)練過程中已見,而"pedestrian"類別是新穎的。性能使用在中等難度下的
指標(biāo)來衡量,且采用了11個(gè)召回位置。對(duì)于nuScenes數(shù)據(jù)集,"car, trailer, construction vehicle, motorcycle, bicycle"是已見類別,剩余五個(gè)為未見類別。除了AP指標(biāo)外,還報(bào)告了NDS(NuScenes Detection Score)來綜合評(píng)估檢測(cè)性能。
分析這些結(jié)果可以得出以下結(jié)論:
- 多模態(tài)輸入的顯著優(yōu)勢(shì):與僅使用點(diǎn)云(P)或圖像(I)作為輸入的情況相比,當(dāng)同時(shí)使用點(diǎn)云和圖像(P+I)作為輸入時(shí),OV-Uni3DETR在所有評(píng)價(jià)指標(biāo)上都獲得了最高分。這一結(jié)果強(qiáng)調(diào)了多模態(tài)學(xué)習(xí)在提高對(duì)未見類別檢測(cè)能力和整體檢測(cè)性能方面的顯著優(yōu)勢(shì)。
- Open-Vocabulary檢測(cè)的有效性:OV-Uni3DETR在處理未見類別時(shí)展現(xiàn)出了出色的性能,尤其是在KITTI數(shù)據(jù)集的"pedestrian"類別和nuScenes數(shù)據(jù)集的"novel"類別上。這表明了模型對(duì)新穎類別具有很強(qiáng)的泛化能力,是一個(gè)有效的Open-Vocabulary檢測(cè)解決方案。
- 與其他方法的對(duì)比:與其他基于點(diǎn)云的方法相比(如Det-PointCLIP、Det-PointCLIPv2和3D-CLIP),OV-Uni3DETR展現(xiàn)出了顯著的性能提升,無論是在已見還是未見類別的檢測(cè)上。這證明了其在處理Open-Vocabulary3D目標(biāo)檢測(cè)任務(wù)上的先進(jìn)性。
- 圖像輸入與點(diǎn)云輸入的對(duì)比:盡管使用圖像輸入的性能略低于使用點(diǎn)云輸入,但圖像輸入仍然能夠提供相對(duì)較高的檢測(cè)精度,這表明了OV-Uni3DETR架構(gòu)的適應(yīng)性和靈活性。
- 綜合評(píng)價(jià)指標(biāo):通過NDS評(píng)價(jià)指標(biāo)的結(jié)果可以看出,OV-Uni3DETR不僅在識(shí)別準(zhǔn)確性上表現(xiàn)出色,而且在整體檢測(cè)質(zhì)量上也取得了很高的分?jǐn)?shù),尤其是在結(jié)合點(diǎn)云和圖像數(shù)據(jù)時(shí)。
OV-Uni3DETR在Open-Vocabulary3D目標(biāo)檢測(cè)上展示了卓越的性能,特別是在處理未見類別和多模態(tài)數(shù)據(jù)方面。這些結(jié)果驗(yàn)證了多模態(tài)輸入和知識(shí)傳播策略的有效性,以及OV-Uni3DETR在提升3D目標(biāo)檢測(cè)任務(wù)泛化能力方面的潛力。
討論

這篇論文通過提出OV-Uni3DETR,一個(gè)統(tǒng)一的多模態(tài)3D檢測(cè)器,為Open-Vocabulary的3D目標(biāo)檢測(cè)領(lǐng)域帶來了顯著的進(jìn)步。該方法利用了多模態(tài)數(shù)據(jù)(點(diǎn)云和圖像)來提升檢測(cè)性能,并通過2D到3D的知識(shí)傳播策略,有效地?cái)U(kuò)展了模型對(duì)未見類別的識(shí)別能力。在多個(gè)公開數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果證明了OV-Uni3DETR在新類別和基類上的出色性能,尤其是在結(jié)合點(diǎn)云和圖像輸入時(shí),能夠顯著提高對(duì)新類別的檢測(cè)能力,同時(shí)在整體檢測(cè)性能上也達(dá)到了新的高度。
優(yōu)點(diǎn)方面,OV-Uni3DETR首先展示了多模態(tài)學(xué)習(xí)在提升3D目標(biāo)檢測(cè)性能中的潛力。通過整合點(diǎn)云和圖像數(shù)據(jù),模型能夠從每種模態(tài)中學(xué)習(xí)到互補(bǔ)的特征,從而在豐富的場(chǎng)景和多樣的目標(biāo)類別上實(shí)現(xiàn)更精確的檢測(cè)。其次,通過引入2D到3D的知識(shí)傳播機(jī)制,OV-Uni3DETR能夠利用豐富的2D圖像數(shù)據(jù)和預(yù)訓(xùn)練的2D檢測(cè)模型來識(shí)別和定位訓(xùn)練過程中未見過的新類別,這大大提高了模型的泛化能力。此外,該方法在處理Open-Vocabulary檢測(cè)時(shí)顯示出的強(qiáng)大能力,為3D檢測(cè)領(lǐng)域帶來了新的研究方向和潛在應(yīng)用。
缺點(diǎn)方面,雖然OV-Uni3DETR在多個(gè)方面展現(xiàn)了其優(yōu)勢(shì),但也存在一些潛在的局限性。首先,多模態(tài)學(xué)習(xí)雖然能提高性能,但也增加了數(shù)據(jù)采集和處理的復(fù)雜性,尤其是在實(shí)際應(yīng)用中,不同模態(tài)數(shù)據(jù)的同步和配準(zhǔn)可能會(huì)帶來挑戰(zhàn)。其次,盡管知識(shí)傳播策略能有效利用2D數(shù)據(jù)來輔助3D檢測(cè),但這種方法可能依賴于高質(zhì)量的2D檢測(cè)模型和準(zhǔn)確的3D-2D對(duì)齊技術(shù),這在一些復(fù)雜環(huán)境中可能難以保證。此外,對(duì)于一些極其罕見的類別,即使是Open-Vocabulary檢測(cè)也可能面臨識(shí)別準(zhǔn)確性的挑戰(zhàn),這需要進(jìn)一步的研究來解決。
OV-Uni3DETR通過其創(chuàng)新的多模態(tài)學(xué)習(xí)和知識(shí)傳播策略,在Open-Vocabulary3D目標(biāo)檢測(cè)上取得了顯著的進(jìn)展。雖然存在一些潛在的局限性,但其優(yōu)點(diǎn)表明了這一方法在推動(dòng)3D檢測(cè)技術(shù)發(fā)展和應(yīng)用拓展方面的巨大潛力。未來的研究可以進(jìn)一步探索如何克服這些局限性,以及如何將這些策略應(yīng)用于更廣泛的3D感知任務(wù)中。
結(jié)論
在本文中,我們主要提出了OV-Uni3DETR,一種統(tǒng)一的多模態(tài)開放詞匯三維檢測(cè)器。借助于多模態(tài)學(xué)習(xí)和循環(huán)模態(tài)知識(shí)傳播,我們的OV-Uni3DETR很好地識(shí)別和定位了新類,實(shí)現(xiàn)了模態(tài)統(tǒng)一和場(chǎng)景統(tǒng)一。實(shí)驗(yàn)證明,它在開放詞匯和封閉詞匯環(huán)境中,無論是室內(nèi)還是室外場(chǎng)景,以及任何模態(tài)數(shù)據(jù)輸入中都有很強(qiáng)的能力。針對(duì)多模態(tài)環(huán)境下統(tǒng)一的開放詞匯三維檢測(cè),我們相信我們的研究將推動(dòng)后續(xù)研究沿著有希望但具有挑戰(zhàn)性的通用三維計(jì)算機(jī)視覺方向發(fā)展。




























