













等等我還沒上車!LLM賦能端到端全新范式LeGo-Drive,車速拉滿
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
寫在前面&筆者個(gè)人理解
這篇論文介紹了一種名為LeGo-Drive的基于視覺語言模型的閉環(huán)端到端自動(dòng)駕駛方法。該方法通過預(yù)測(cè)目標(biāo)位置和可微分優(yōu)化器規(guī)劃軌跡,實(shí)現(xiàn)了從導(dǎo)航指令到目標(biāo)位置的端到端閉環(huán)規(guī)劃。通過聯(lián)合優(yōu)化目標(biāo)位置和軌跡,該方法提高了目標(biāo)位置預(yù)測(cè)的準(zhǔn)確性,并生成了平滑、無碰撞的軌跡。在多個(gè)仿真環(huán)境中進(jìn)行的實(shí)驗(yàn)表明,該方法在自動(dòng)駕駛指標(biāo)上取得了顯著改進(jìn),目標(biāo)到達(dá)成功率達(dá)到81%。該方法具有很好的可解釋性,可用于實(shí)際自動(dòng)駕駛車輛和智能交通系統(tǒng)中。
 圖1:LeGo-Drive導(dǎo)航到基于語言的目標(biāo),該目標(biāo)與軌跡參數(shù)共同優(yōu)化。“將車停在左前方公交車站附近”等命令的預(yù)測(cè)目標(biāo)可能會(huì)落在不理想的位置(右上:綠色),這可能會(huì)導(dǎo)致容易發(fā)生碰撞的軌跡。由于軌跡是唯一直接與環(huán)境“交互”的組件,因此我們建議讓感知感知了解軌跡參數(shù),從而將目標(biāo)位置改善為可導(dǎo)航位置(右下角:紅色)
圖1:LeGo-Drive導(dǎo)航到基于語言的目標(biāo),該目標(biāo)與軌跡參數(shù)共同優(yōu)化。“將車停在左前方公交車站附近”等命令的預(yù)測(cè)目標(biāo)可能會(huì)落在不理想的位置(右上:綠色),這可能會(huì)導(dǎo)致容易發(fā)生碰撞的軌跡。由于軌跡是唯一直接與環(huán)境“交互”的組件,因此我們建議讓感知感知了解軌跡參數(shù),從而將目標(biāo)位置改善為可導(dǎo)航位置(右下角:紅色)
開源地址:https://reachpranjal.github.io/lego-drive
相關(guān)工作回顧
視覺基礎(chǔ)
視覺基礎(chǔ)的目標(biāo)是將自然語言查詢與視覺場景中最相關(guān)的視覺元素或目標(biāo)關(guān)聯(lián)起來。早期的研究方法是將視覺基礎(chǔ)任務(wù)視為參考表達(dá)理解(Referring Expression Comprehension, REC),這涉及到生成區(qū)域提案,然后利用語言表達(dá)來選擇最佳匹配的區(qū)域。相對(duì)地,一種稱為Referring Image Segmentation (RIS)的一階段方法,則將語言和視覺特征集成在網(wǎng)絡(luò)中,并直接預(yù)測(cè)目標(biāo)框。參考文獻(xiàn)使用了RIS方法,基于語言命令來識(shí)別可導(dǎo)航區(qū)域的任務(wù)。然而,這項(xiàng)工作僅限于場景理解,并且不包括導(dǎo)航仿真,因?yàn)檐壽E規(guī)劃依賴于精確的目標(biāo)點(diǎn)位置,而這一點(diǎn)并未得到解決。
端到端自動(dòng)駕駛
端到端學(xué)習(xí)研究在近年來備受關(guān)注,其目的是采用數(shù)據(jù)驅(qū)動(dòng)的統(tǒng)一學(xué)習(xí)方式,確保安全運(yùn)動(dòng)規(guī)劃,與傳統(tǒng)基于規(guī)則的獨(dú)立優(yōu)化每個(gè)任務(wù)的設(shè)計(jì)相比,后者會(huì)導(dǎo)致累積誤差。在nuScenes數(shù)據(jù)集上,UniAD是當(dāng)前最先進(jìn)的方法,使用柵格化場景表示來識(shí)別P3框架中的關(guān)鍵組件。ST-P3是先前的藝術(shù),它探討了基于視覺的端到端ADS的可解釋性。由于計(jì)算限制,選擇ST-P3作為我們的運(yùn)動(dòng)規(guī)劃基準(zhǔn),而不是UniAD。
面向規(guī)劃的視覺語言導(dǎo)航
在自動(dòng)駕駛系統(tǒng)(ADS)領(lǐng)域,大型語言模型(LLMs)因其多模態(tài)理解和與人類的自然交互而展現(xiàn)出有前景的結(jié)果。現(xiàn)有工作使用LLM來推理駕駛場景并預(yù)測(cè)控制輸入。然而,這些工作僅限于開環(huán)設(shè)置。更近的工作關(guān)注于適應(yīng)閉環(huán)解決方案。它們要么直接估計(jì)控制動(dòng)作,要么將它們映射到一組離散的動(dòng)作空間。這些方法較為粗糙,容易受到感知錯(cuò)誤的影響,因?yàn)樗鼈儑?yán)重依賴于VLMs的知識(shí)檢索能力,這可能導(dǎo)致在需要復(fù)雜控制動(dòng)作組合的復(fù)雜情況下(如泊車、高速公路并線等)產(chǎn)生不流暢的運(yùn)動(dòng)。
數(shù)據(jù)集
詳細(xì)闡述了作者為開發(fā)結(jié)合視覺數(shù)據(jù)和導(dǎo)航指令的智能駕駛agent而創(chuàng)建的數(shù)據(jù)集和標(biāo)注策略。作者利用CARLA仿真器提供的視覺中心數(shù)據(jù),并輔以導(dǎo)航指令。他們假設(shè)agent擁有執(zhí)行成功閉環(huán)導(dǎo)航所需的特權(quán)信息。
數(shù)據(jù)集概覽:先前的工作,如Talk2Car數(shù)據(jù)集,主要關(guān)注通過為目標(biāo)引用標(biāo)注邊界框來進(jìn)行場景理解。進(jìn)一步的工作,如Talk2Car-RegSeg,則通過標(biāo)注可導(dǎo)航區(qū)域的分割mask來包含導(dǎo)航。作者在此基礎(chǔ)上擴(kuò)展了數(shù)據(jù)集,涵蓋各種駕駛操作,包括車道變更、速度調(diào)整、轉(zhuǎn)彎、繞過其他物體或車輛、通過交叉口以及在行人橫道或交通信號(hào)燈處停車,并在其中演示了閉環(huán)導(dǎo)航。創(chuàng)建的LeGo-Drive數(shù)據(jù)集包含4500個(gè)訓(xùn)練點(diǎn)和1000個(gè)驗(yàn)證點(diǎn)。作者使用復(fù)雜和簡單的命令標(biāo)注進(jìn)行了結(jié)果、基準(zhǔn)比較和消除實(shí)驗(yàn)。
仿真器設(shè)置:LeGo-Drive數(shù)據(jù)集收集過程包括兩個(gè)階段:
- 同步記錄駕駛agent狀態(tài)與相機(jī)傳感器數(shù)據(jù),隨后記錄交通agent,
- 解析和標(biāo)注收集的數(shù)據(jù),以導(dǎo)航指令為標(biāo)注。
作者以10 FPS的速率錄制數(shù)據(jù),為避免連續(xù)幀之間的冗余,數(shù)據(jù)點(diǎn)在10米的距離間隔內(nèi)進(jìn)行過濾。對(duì)于每個(gè)幀,他們收集了自車的狀態(tài)(位置和速度)、自車車道(前后各50米范圍)、前RGB相機(jī)圖像,以及使用基于規(guī)則的專家agent收集的交通agent狀態(tài)(位置和速度),所有這些都以自車幀為單位。數(shù)據(jù)集涵蓋了6個(gè)不同的城鎮(zhèn),具有各種獨(dú)特的環(huán)境,代表不同的駕駛場景,包括不同的車道配置、交通密度、光照和天氣條件。此外,數(shù)據(jù)集還包括了戶外場景中常見的各種物體,如公交車站、食品攤位和交通信號(hào)燈。
語言命令標(biāo)注:每個(gè)幀都手動(dòng)標(biāo)注了適當(dāng)?shù)膶?dǎo)航命令,以目標(biāo)區(qū)域分割mask的形式,以涵蓋各種駕駛場景。作者考慮了3種不同的命令類別:
- 以目標(biāo)為中心的命令,直接指向當(dāng)前相機(jī)幀中可見的目標(biāo),
- 車道操作命令,與車道變更或車道內(nèi)調(diào)整相關(guān)的指令,
- 復(fù)合命令,連接多個(gè)指令以模擬實(shí)際駕駛場景。
作者利用ChatGPT API生成具有相似語義含義的不同變體。表I展示了他們數(shù)據(jù)集中的一些示例指令。值得注意的是,作者并未涵蓋誤導(dǎo)性指令的處理。這種能力對(duì)于場景推理模型至關(guān)重要,可能被視為未來的擴(kuò)展范圍;然而,它超出了當(dāng)前研究的范圍。
表I:LeGo-Drive數(shù)據(jù)集的導(dǎo)航指令示例
LeGo-Drive架構(gòu)
本文提出了LeGo-Drive框架,旨在解決從VLA進(jìn)行控制動(dòng)作的粗略估計(jì)的問題,將這一問題視為一個(gè)短期目標(biāo)實(shí)現(xiàn)問題。這是通過學(xué)習(xí)軌跡優(yōu)化器的參數(shù)和行為輸入,生成并改進(jìn)與導(dǎo)航指令一致的可實(shí)現(xiàn)目標(biāo)來實(shí)現(xiàn)的。
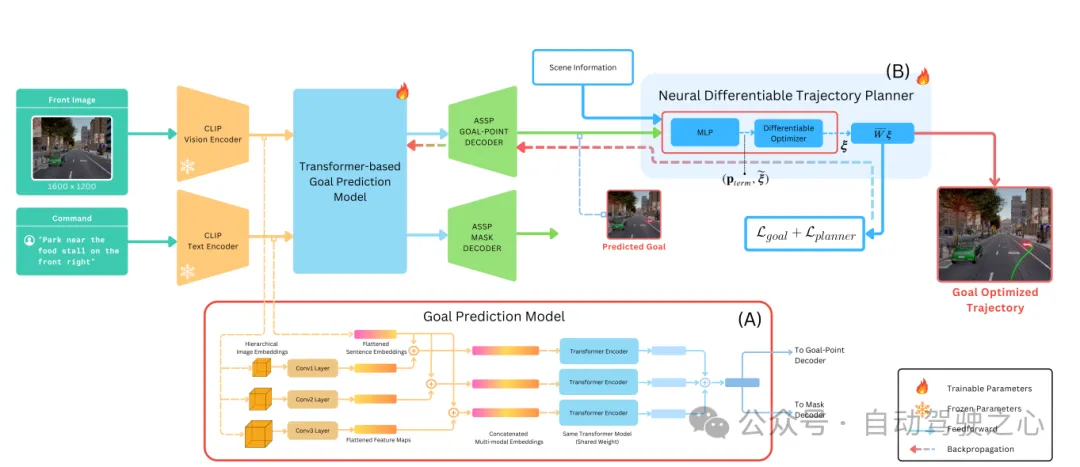
圖3:LeGo-Drive架構(gòu)
如圖3所示,架構(gòu)由兩個(gè)主要部分組成:
- 目標(biāo)預(yù)測(cè)模塊,接受前視圖圖像和相應(yīng)的語言命令,生成或預(yù)測(cè)一個(gè)分割mask ,然后是一個(gè)目標(biāo)位置。
- 可微優(yōu)化器,生成一個(gè)軌跡,共同優(yōu)化估計(jì)的目標(biāo)和軌跡優(yōu)化器的參數(shù),當(dāng)進(jìn)行端到端訓(xùn)練時(shí),導(dǎo)致所需位置坐標(biāo)到可導(dǎo)航位置的改進(jìn)。
目標(biāo)預(yù)測(cè)模塊
為編碼給定的導(dǎo)航命令,作者使用CLIP 標(biāo)記器對(duì)語言命令進(jìn)行標(biāo)記,并經(jīng)過CLIP文本編碼器獲得文本嵌入。為了從給定的前攝像頭圖像中獲得圖像特征,使用帶有ResNet-101骨干網(wǎng)絡(luò)的CLIP圖像編碼器。提取不同視覺特征,通過卷積塊ConvBlocki進(jìn)行處理,以標(biāo)準(zhǔn)大小和相等的通道尺寸、高度和寬度進(jìn)行重塑。
為捕捉圖像和文本特征的跨模態(tài)上下文,作者進(jìn)一步使用來自DETR架構(gòu)的transformer編碼器。文本特征與不同的個(gè)體拼接,得到多模態(tài)特征,然后單獨(dú)通過transformer編碼器,其中多頭自注意力層幫助跨模態(tài)交互不同類型的特征,以獲得形狀相同的編碼器輸出。
有兩個(gè)解碼頭,一個(gè)用于分割mask預(yù)測(cè),另一個(gè)用于目標(biāo)點(diǎn)預(yù)測(cè)。分割mask預(yù)測(cè)頭將進(jìn)行重塑和重組,得到,并使用ASPP解碼器。目標(biāo)點(diǎn)預(yù)測(cè)解碼器由卷積層和全連接層組成,輸出形狀為表示圖像上的像素位置。
首先,分割mask預(yù)測(cè)頭與真實(shí)分割mask之間的BCE損失進(jìn)行端到端訓(xùn)練。在幾個(gè)epoch之后,目標(biāo)點(diǎn)預(yù)測(cè)頭以平滑L1損失與真實(shí)目標(biāo)點(diǎn)之間的差異進(jìn)行類似端到端的訓(xùn)練。
復(fù)雜命令和場景理解:為處理最終目標(biāo)位置在當(dāng)前幀中不可見的復(fù)合指令,通過將復(fù)雜命令分解為需要順序執(zhí)行的原子命令列表來適應(yīng)他們的方法。例如,“切換到左車道然后跟著黑色汽車”可以分解為“切換到左車道”和“跟著黑色汽車”。為分解這種復(fù)雜命令,作者構(gòu)建了一個(gè)原子命令列表L,涵蓋廣泛的簡單操作,如車道變更、轉(zhuǎn)彎、速度調(diào)整和目標(biāo)引用。在收到復(fù)雜命令后,作者利用小樣本學(xué)習(xí)技術(shù)提示LLM將給定復(fù)雜命令分解為原子命令列表li,來自L。這些原子命令隨后迭代執(zhí)行,預(yù)測(cè)的目標(biāo)點(diǎn)位置作為中間路點(diǎn)幫助我們達(dá)到最終目標(biāo)點(diǎn)。
神經(jīng)可微優(yōu)化器
計(jì)劃采用優(yōu)化問題的形式,其中嵌入有可學(xué)習(xí)參數(shù),以改進(jìn)由VLA生成的下游任務(wù)的跟蹤目標(biāo),并加速其收斂。作者首先介紹了他們軌跡優(yōu)化器的基本結(jié)構(gòu),然后介紹了其與網(wǎng)絡(luò)的集成。
基本問題公式:作者假設(shè)可以獲得車道中心線,并使用它來構(gòu)建Frenet框架。在Frenet框架中,軌跡規(guī)劃具有優(yōu)勢(shì),即汽車在縱向和橫向運(yùn)動(dòng)與Frenet框架的X和Y軸對(duì)齊。在給定這種表示的情況下,他們的軌跡優(yōu)化問題具有以下形式:
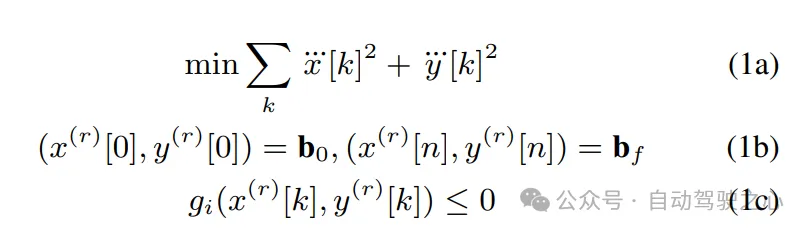
等式約束(1b)確保計(jì)劃的軌跡滿足初始和最終邊界條件,在r階導(dǎo)數(shù)上。在公式中使用r={0,1,2}。不等式約束(1c)也依賴于r階導(dǎo)數(shù)的上界,包括速度、加速度、車道偏移以及避碰和曲率約束。的代數(shù)結(jié)構(gòu)取自先前的工作。
為確保他們?cè)谄交壽E的空間中優(yōu)化,作者以以下形式參數(shù)化沿X-Y方向的運(yùn)動(dòng):
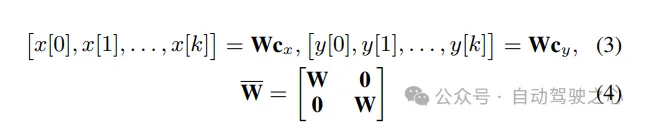
使用(4),優(yōu)化(1a)-(1c)可以寫成以下緊湊形式
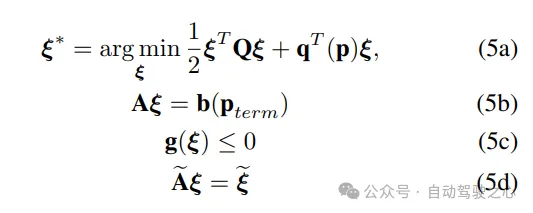
端到端訓(xùn)練
LeGo-Drive E2E:表示目標(biāo)預(yù)測(cè)模塊和規(guī)劃器模塊的聯(lián)合訓(xùn)練。模型在組合損失上訓(xùn)練,其中目標(biāo)損失是預(yù)測(cè)目標(biāo)與預(yù)測(cè)軌跡端點(diǎn)之間的均方誤差損失,規(guī)劃器損失Lplanner是違反非凸約束g的組合,涉及車道偏移、避碰和運(yùn)動(dòng)學(xué)約束。梯度從規(guī)劃器流向目標(biāo)預(yù)測(cè)部分。
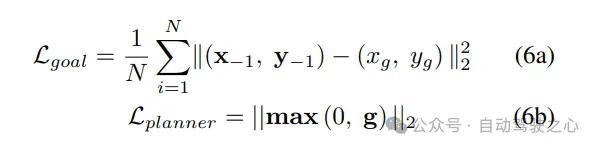
LeGo-Drive Decoupled:表示目標(biāo)預(yù)測(cè)模塊和規(guī)劃器模塊分別訓(xùn)練的過程。首先,目標(biāo)預(yù)測(cè)模塊在預(yù)測(cè)目標(biāo)與真實(shí)目標(biāo)之間的均方誤差損失上進(jìn)行訓(xùn)練。然后,規(guī)劃器在上訓(xùn)練,同時(shí)凍結(jié)目標(biāo)預(yù)測(cè)模塊的參數(shù)。
端到端訓(xùn)練需要通過優(yōu)化層建模軌跡規(guī)劃過程進(jìn)行反向傳播,可以通過隱式微分和算法展開兩種方式進(jìn)行。作者建立了一個(gè)自定義的反向傳播程序,遵循算法展開,這種方法可以處理約束,并且反向傳播可以避免矩陣分解。兩種方法的性能在表II中展示,并在后面章節(jié)中進(jìn)行分析。該方法的核心創(chuàng)新在于其模塊化的端到端規(guī)劃框架,其中框架優(yōu)化目標(biāo)預(yù)測(cè)模塊,同時(shí)優(yōu)先考慮軌跡優(yōu)化,確保獲取的行為輸入有效地促進(jìn)優(yōu)化器的收斂。不同模塊的迭代改進(jìn)形成系統(tǒng)設(shè)計(jì)的基礎(chǔ),確保系統(tǒng)內(nèi)部的協(xié)同和迭代改進(jìn)循環(huán)。
表II:模型比較:
實(shí)驗(yàn)
實(shí)現(xiàn)細(xì)節(jié)
感知模塊輸入:模型輸入包括1600x1200像素的RGB圖像和最大長度為20個(gè)詞的語言指令。使用CLIP提取視覺和文本特征,并使用Transformer進(jìn)行多模態(tài)交互,輸出分割mask和目標(biāo)點(diǎn)預(yù)測(cè)。
規(guī)劃模塊:基于優(yōu)化器的可微規(guī)劃器在道路對(duì)齊的Frenet坐標(biāo)系中操作,考慮50米范圍內(nèi)的5個(gè)最近障礙物。規(guī)劃器以車輛控制和動(dòng)力學(xué)約束為條件,并輸出滿足約束的平滑軌跡
訓(xùn)練:使用Adam優(yōu)化器,權(quán)重衰減為,batch size為16,學(xué)習(xí)率初始化為,進(jìn)行100個(gè)epoch的訓(xùn)練。訓(xùn)練過程中需要通過算法展開進(jìn)行反向傳播
評(píng)估指標(biāo)
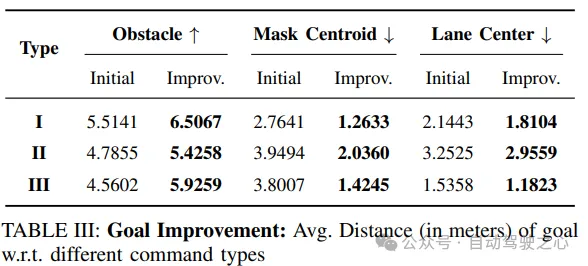
目標(biāo)評(píng)估:評(píng)估預(yù)測(cè)目標(biāo)與mask質(zhì)心和車道中心的接近程度,以及與最近障礙物的距離。這些指標(biāo)用于衡量模型在理解語言指令并準(zhǔn)確預(yù)測(cè)目標(biāo)位置方面的性能。
軌跡評(píng)估:使用最小最終位移誤差(minFDE)和成功率(SR)評(píng)估軌跡性能。minFDE表示預(yù)測(cè)軌跡終點(diǎn)與目標(biāo)位置的歐氏距離,SR表示車輛在3米范圍內(nèi)成功到達(dá)目標(biāo)的比例。這些指標(biāo)用于評(píng)估模型在生成可行、平滑的軌跡方面的性能。
平滑性:評(píng)估軌跡接近目標(biāo)的平穩(wěn)程度,采用平滑指數(shù)度量。較低的平滑指數(shù)表示軌跡更平滑地接近目標(biāo),該指標(biāo)用于衡量模型生成軌跡的平滑性。
實(shí)驗(yàn)結(jié)果
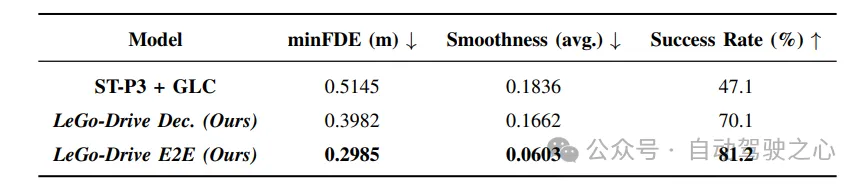
目標(biāo)改進(jìn):通過比較解耦訓(xùn)練和端到端訓(xùn)練的目標(biāo)預(yù)測(cè)指標(biāo),結(jié)果顯示端到端訓(xùn)練方法在所有指標(biāo)上表現(xiàn)更好。特別是在復(fù)合指令下,目標(biāo)改進(jìn)幅度更大,證明了該方法的有效性。
軌跡改進(jìn):與基準(zhǔn)方法ST-P3相比,LeGo-Drive模型在目標(biāo)可達(dá)性、軌跡平滑性等方面明顯優(yōu)于基準(zhǔn)方法。特別是復(fù)合指令下的最小最終位移誤差降低了60%,進(jìn)一步證明了端到端訓(xùn)練的優(yōu)勢(shì)。
模型比較:通過比較端到端方法、解耦訓(xùn)練和基準(zhǔn)方法,結(jié)果顯示端到端方法在目標(biāo)可達(dá)性和軌跡平滑性方面明顯優(yōu)于其他方法。
定性結(jié)果:定性結(jié)果直觀展示了端到端方法生成的軌跡比基準(zhǔn)方法更平滑,進(jìn)一步驗(yàn)證了實(shí)驗(yàn)結(jié)果。
表Ⅲ: Goal Improvement
表IV: Trajectory Evaluation
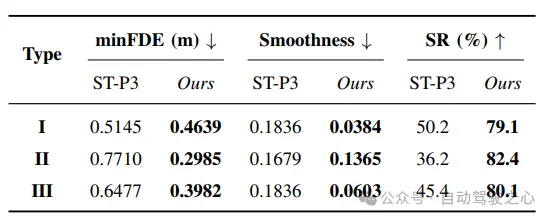

圖4:不同以目標(biāo)為中心的停車命令的目標(biāo)改進(jìn)。(左)查詢命令的前視圖圖像。(右)場景的俯視圖。目標(biāo)位置從綠色中不理想的位置((a)中的汽車頂部和(b)中的路邊邊緣)改進(jìn)為紅色中的可到達(dá)位置
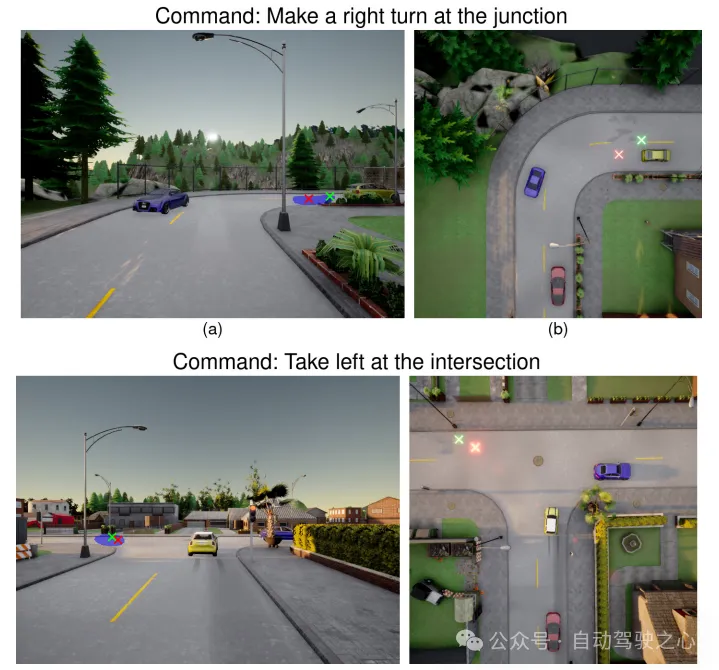
圖5:車削指令情況下的結(jié)果。在這兩幅圖中(上、下),綠色的初始目標(biāo)與車道中心的偏移量較大。該模型近似于改進(jìn)版本的紅色顯示到車道中心

圖6:不同導(dǎo)航指令下軌跡改進(jìn)的定性結(jié)果。與我們的(綠色)相比,紅色顯示的基線ST-P3軌跡始終規(guī)劃著一個(gè)不光滑的軌跡。所有行中的第三張圖顯示了我們?cè)贔renet框架中的規(guī)劃,其中紅色矩形表示自我車輛,藍(lán)色表示周圍車輛,紅色十字表示目標(biāo)位置以及用黑色實(shí)線表示的車道邊界
實(shí)驗(yàn)結(jié)果證明了端到端訓(xùn)練方法的有效性,能夠提高目標(biāo)預(yù)測(cè)的準(zhǔn)確性和軌跡的平滑性。
結(jié)論
本文通過將所提出的端到端方法作為目標(biāo)點(diǎn)導(dǎo)航問題來解決,揭示了其與傳統(tǒng)解耦方法相比的明顯優(yōu)勢(shì)。目標(biāo)預(yù)測(cè)模塊與基于可微分優(yōu)化器的軌跡規(guī)劃器的聯(lián)合訓(xùn)練突出了方法的有效性,從而提高了準(zhǔn)確性和上下文感知目標(biāo)預(yù)測(cè),最終產(chǎn)生更平滑、無碰撞的可導(dǎo)航軌跡。此外,還證明了所提出的模型適用于當(dāng)前的視覺語言模型,以豐富的場景理解和生成帶有適當(dāng)推理的詳細(xì)導(dǎo)航指令。























