LVLM賦能端到端!地平線&華科聯手打造更強自動駕駛系統Senna!
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&筆者的個人理解
近年來,自動駕駛技術發展迅速,在駕駛感知、運動預測、規劃等領域取得了重大進展,為實現更準確、更安全的駕駛決策奠定了堅實的基礎。其中,端到端自動駕駛技術取得了重大突破,端到端方法以大規模數據為基礎,展現出卓越的規劃能力。此外,大型視覺語言模型已經表現出越來越強大的圖像理解和推理能力。通過利用其常識和邏輯,LVLM 可以分析駕駛環境并在復雜場景中做出安全的決策。利用大量駕駛數據來提高 LVLM 在自動駕駛中的性能并連接 LVLM 和端到端模型,對于實現安全、穩健和可推廣的自動駕駛至關重要。
端到端自動駕駛的常見做法是直接預測未來軌跡或控制信號,而無需決策步驟。然而,這種方法可能會使模型學習更加困難,同時缺乏可解釋性。相比之下,當人腦做出詳細決策時,由分層高級決策和低級執行組成的系統起著至關重要的作用。此外,端到端模型通常缺乏常識,在簡單場景中可能會出錯。例如,它們可能會將載有交通錐的卡車誤認為是路障,從而觸發不必要的剎車。這些限制阻礙了端到端模型的規劃性能。因此,本文針對以下涉及到的三個問題進行探索。
- 如何將 LVLM 與端到端模型相結合?目前,LVLM 在自動駕駛規劃中的應用主要分為兩類。一是直接使用 LVLM 作為規劃器來預測軌跡點或控制信號;另一種方法是將 LVLM 與端到端模型相結合。涉及使用 LVLM 預測低頻軌跡點,然后通過端到端模型對其進行細化以產生高頻軌跡。在本文,我們提出了一種結構化的自動駕駛系統Senna,該系統將大型視覺語言模型與端到端模型相結合,具體來說,大型視覺語言模型用自然語言預測高級規劃決策,并將其編碼為高維特征,然后輸入到端到端自動駕駛系統中。根據高級決策,端到端自動駕駛系統生成最終的規劃軌跡。
- 如何設計適合駕駛任務的LVLM?目前流行的LVLM并未專門針對多圖像輸入進行優化。以前用于駕駛任務的 LVLM 要么僅支持前視輸入,這會限制空間感知并增加安全風險,要么可以適應多圖像輸入但仍然缺乏詳細設計或有效性驗證。我們提出的Senna,它支持多圖像輸入來編碼環視數據,這對于了解駕駛場景和確保安全至關重要。
- 如何有效地訓練駕駛 LVLM?在開發用于駕駛任務的 LVLM 之后,最后一步是確保有效的訓練,這需要合適的數據和策略。我們引入了一系列面向規劃的問答,旨在增強 VLM 對駕駛場景中規劃相關線索的理解,最終實現更準確的規劃。
針對上述相關問題的討論,本文提出了一種將 LVLM 與端到端模型相結合的自動駕駛系統,實現了從高級決策到低級軌跡預測的結構化規劃。該算法稱之為Senna。并且在nuScenes數據集和DriveX大規模數據集上的大量實驗也證明了Senna的SOTA規劃性能。

論文鏈接:https://arxiv.org/pdf/2410.22313
網絡結構&技術細節梳理
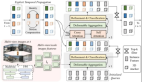
在詳細介紹本文提出的算法模型的網絡架構細節之前,下圖展示了我們提出的Senna算法模型的整體網絡結構圖。

整體而言,輸入的場景信息包括多視角圖像序列、用戶指令和導航命令。用戶指令作為提示輸入到Senna-VLM中,其他指令則同時發送給Senna-VLM和Senna-E2E。Senna-VLM將圖像和文本信息分別編碼為圖像和文本標記,然后由LLM進行處理。LLM生成高級決策,這些決策通過元動作編碼器編碼為高維特征。Senna-E2E根據場景信息和Senna-VLM生成的元動作特征預測最終的規劃軌跡。我們設計了一系列面向規劃的QA來訓練Senna-VLM,這些QA不需要人工注釋,并且可以完全通過自動標記流程大規模生成。
駕駛場景理解
了解駕駛場景中的關鍵因素對于安全準確地進行規劃至關重要。我們設計了一系列面向規劃的 QA,以增強 Senna-VLM 對駕駛場景的理解。每種類型的 QA 的細節如下圖所示。用于生成這些 QA 的原始數據(例如 3D 物體檢測框和物體跟蹤軌跡)可以通過自動注釋系統獲得。此外,描述性 QA 可以由 GPT-4o 等 LVLM 生成。

- 場景描述:我們利用預先訓練的 LVLM 根據環視圖像生成駕駛場景描述。為了避免生成與規劃無關的冗余信息,我們在提示中指定了所需的信息,包括:交通狀況、環境(例如城市、鄉村等)、道路類型(例如鋪裝道路、高速公路)、天氣狀況、一天中的時間以及道路狀況(例如道路是否平坦或是否有任何障礙物)。通過以這種方式構建提示,我們可以獲得簡潔且信息豐富的場景描述。
- 交通燈信號檢測:交通信號燈有多種類型,但這里我們主要關注最關鍵的一種:交通信號燈。交通信號燈的狀態可分為四種:紅色、綠色、黃色和無,其中無表示在自車前方未檢測到交通信號燈。
- VRU識別:通過識別環境中的VRU,我們增強了 Senna 對這些關鍵物體的感知,并提高了規劃的安全性。具體來說,我們使用真值 3D 檢測結果來獲取 VRU 的類別和位置,然后以文本形式描述這些信息。位置信息以自車為中心,包括每個 VRU 相對于自車的橫向和縱向距離。我們僅使用 Senna-VLM 來預測距離的整數部分,以在構建距離感知的同時降低學習復雜性。
- 運動意圖預測:準確預測其他車輛的未來運動意圖是安全規劃的先決條件。我們還采用了元動作方法,使 Senna 能夠預測周圍車輛的未來行為。這增強了 Senna 對場景動態特征的理解,使其能夠做出更明智的決策。
- 元動作規劃:為了避免使用 LVLM 進行精確的軌跡預測,我們將自身車輛的未來軌跡轉換為元動作以進行高級規劃。具體而言,元動作包括橫向和縱向決策。橫向元動作包括左轉、直行和右轉,而縱向元動作包括加速、保持、減速和停止。橫向元動作是根據預測的未來時間步長 T 內的橫向位移確定的,縱向元動作是根據預測期間的速度變化確定的。最終的元動作包括橫向和縱向元動作。
- 規劃解釋:我們還使用基于車輛真實未來運動的 LVLM 生成規劃解釋。換句話說,我們向 LVLM 告知車輛的實際未來運動(例如加速和左轉),并要求它們分析此類決策背后的原因。在提示中,我們通過考慮以下影響規劃的因素來指導模型分析決策:其他交通參與者的行為、導航信息、道路狀況和交通信號燈狀態。
Senna-VLM
Senna-VLM 由四個組件組成。視覺編碼器以多視角圖像序列作為輸入并提取圖像特征,然后由Driving Vision Adapter進一步編碼和壓縮,產生圖像標記。文本編碼器將用戶指令和導航命令編碼為文本標記。圖像和文本標記均輸入到 LLM 中,后者預測高級決策。在實踐中,我們使用 Vicuna-v1.5-7b作為我們的 LLM。最后,元動作編碼器對決策進行編碼并輸出元動作特征。
我們使用 CLIP 的 ViT-L/14 作為視覺編碼器,由于多幅圖像輸入,導致圖像 token 數量過多,不僅減慢了 VLM 的訓練和推理速度,還會導致模型崩潰和解碼失敗。因此,我們引入了 Driving Vision Adapter 模塊。該模塊不僅將圖像特征映射到LLM特征空間,而且還對圖像特征進行額外的編碼和壓縮,以減少圖像標記的數量。具體來說,我們采用一組圖像查詢來對圖像特征進行編碼并輸出圖像標記:

其中,MHSA代表的是多頭自注意力機制。
為了讓 Senna-VLM 能夠區分不同視圖中的圖像特征并建立空間理解,我們為駕駛場景設計了一個簡單而有效的環視提示。以正面視圖為例,相應的提示是:FRONT VIEW: \n image \n,其中 image 是 LLM 的特殊標記,在生成過程中將被圖像標記替換。下圖說明了我們提出的多視圖提示和圖像編碼方法的設計。

最后,我們提出了元動作編碼器,將LLM輸出的高級決策轉換為元動作特征。元動作編碼器使用一組可學習的嵌入實現從元動作到元動作特征的一對一映射,下面的公式說明了生成元動作特征的過程

隨后,元動作特征將被輸入到 SennaE2E 中以預測規劃軌跡。
Senna-E2E
Senna-E2E 擴展了 VADv2。具體來說,Senna-E2E 的輸入包括多視角圖像序列、導航命令和元動作特征。它由三個模塊組成:感知模塊,用于檢測動態物體并生成局部地圖;運動預測模塊,用于預測動態物體的未來軌跡;規劃模塊,使用一組通過注意力機制與場景特征交互的規劃標記來預測規劃軌跡。我們將元動作特征集成為 Senna-E2E 的附加交互標記。由于元動作特征采用嵌入向量的形式,因此 Senna-VLM 可以輕松與其他端到端模型結合。Senna-E2E的軌跡規劃過程可以表述如下

訓練策略
我們為 Senna-VLM 提出了一種三階段訓練策略。第一階段是混合預訓練,我們使用單圖像數據訓練Driving Vision Adapter,同時保持 Senna-VLM 中其他模塊的參數不變。這樣可以將圖像特征映射到 LLM 特征空間。混合是指使用來自多個來源的數據,包括 LLaVA中使用的指令跟蹤數據和我們提出的駕駛場景描述數據。第二階段是駕駛微調,我們根據之前提出的面向規劃的 QA 對 Senna-VLM 進行微調,不包括元動作規劃 QA。在此階段,使用環視多圖像輸入而不是單圖像輸入。第三階段是規劃微調,我們僅使用元動作規劃 QA 進一步微調 Senna-VLM。
實驗結果&評價指標
下圖的實驗結果展示了 Senna 在高級規劃和場景描述方面的表現,并與最先進的開源 LVLM(包括 QwenVL、LLaVA 和 VILA)進行了比較。前三行的結果是通過直接評估原始模型獲得的。可以看出,使用預訓練權重的模型在駕駛任務上表現不佳,因為它們的訓練目標是面向一般理解和對話,而不是專門針對駕駛相關任務而量身定制的。

為了進一步驗證 Senna 的優勢,我們還使用相同的訓練流程在 DriveX 數據集上對這些模型進行了微調。Senna 在高級規劃和場景描述方面均優于其他方法。與其他方法的最佳結果相比,Senna 將規劃準確率提高了 10.44%。此外,在減速等最關鍵的駕駛安全決策中,F1 得分從 52.68 提升至 61.99,提升幅度達 17.67%,凸顯了Senna在駕駛場景分析和空間理解方面的卓越能力。
此外,我們在下表中展示了 Senna 在 nuScenes 數據集上的軌跡規劃性能。為了進行公平比較,我們用 VAD 替換 VADv2 作為端到端模型。與之前將 LVLM 與端到端模型相結合的 SOTA 方法相比,Senna 有效地將平均規劃位移誤差降低了 29.03%,碰撞率降低了 20.00%。為了避免與使用自車狀態特征相關的潛在問題,我們還報告了未使用自車狀態特征的結果。通過使用來自 DriveX 數據集的預訓練權重初始化模型并在 nuScenes 數據集上進行微調,Senna 實現了最先進的規劃性能。與 VAD 相比,平均規劃位移誤差顯著降低了 40.28%,平均碰撞率降低了 45.45%。通過在 DriveX 數據集上進行預訓練,然后在 nuScenes 數據集上進行微調,Senna 的性能得到顯著增強,展示了其強大的泛化和可轉移性。

下表展示了DriveX 數據集上的軌跡規劃結果。除了端到端模型 VADv2 之外,我們還引入了兩個額外的比較模型。第一個模型將真值規劃元動作作為額外的輸入特征,旨在驗證我們提出的結構化規劃策略的性能上限。第二個模型是我們復現的 DriveVLM,它預測低頻軌跡而不是元動作,充當 LVLM 和端到端模型之間的連接器。

通過實驗結果可以看出,利用真值規劃元動作的 VADv2 實現了最低的規劃誤差,驗證了我們提出的結構化規劃策略的有效性。預測低頻軌跡作為連接器的 DriveVLM僅比 VADv2 顯示出微小的改進。相比之下,我們提出的 Senna 在所有方法中提供了最佳的規劃性能,將平均規劃位移誤差大大降低了 14.27%。
結論
在本文中,我們提出了LVLM 與端到端模型相結合,用于結構化規劃,從高級決策到低級軌跡規劃的自動駕駛系統Senna,大量的實驗結果證明了我們提出的Senna算法模型的卓越性能,凸顯了通過基于語言的規劃將 LVLM 與端到端模型相結合的潛力。