地平線&港大最新端到端進展!HE-Drive:VLM+擴散模型發大力
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&筆者的個人理解
本文提出了HE-Drive:首個模仿人類駕駛為核心的端到端自動駕駛系統,旨在生成同時具備時間一致性和舒適性的軌跡。近期研究表明,基于模仿學習的規劃器和基于學習的軌跡評分器能夠有效生成并選擇高度模仿專家演示的準確軌跡。然而這類軌跡規劃和評分器面臨生成時間不一致且不舒適的軌跡的困境。為了解決上述問題,HE-Drive首先通過稀疏感知提取關鍵的三維空間表示,這些表示隨后作為條件輸入,傳遞給基于條件去噪擴散概率模型(DDPM)的運動規劃器,生成具備時間一致性的多模態軌跡。隨后,基于視覺語言模型(VLM)引導的軌跡評分器從這些候選軌跡中選擇最舒適的軌跡來控制車輛,確保類人的端到端駕駛體驗。實驗結果表明,HE-Drive在nuScenes和OpenScene數據集上實現了SOTA性能(即比VAD減少了71%的平均碰撞率)和效率(即比SparseDrive快1.9倍),同時在真實世界數據中提供了最舒適的駕駛體驗。
- 代碼鏈接:https://github.com/jmwang0117/HE-Drive
總結來說,本文的主要貢獻如下:
- 基于擴散的運動規劃:本文提出了一種基于擴散的運動規劃器,通過以稀疏感知網絡提取的3D表示為條件,并結合歷史預測軌跡的速度、加速度和偏航角,生成時間一致性和多模態的軌跡。
- 即插即用的軌跡評分:本文引入了一種新穎的基于視覺語言模型(VLMs)引導的軌跡評分器及舒適度指標,彌補了類人駕駛的不足,使其能夠輕松集成到現有的自動駕駛系統中。
- 優秀的開環和閉環測試結果:HE-Drive在nuScenes和OpenScene數據集上實現了最先進的性能(即相比VAD減少了71%的平均碰撞率)和效率(即比SparseDrive快1.9倍),同時在真實世界數據集上將舒適度提升了32%,展示了其在各種場景中的有效性。
文章簡介

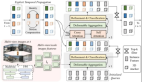
圖1:本文展示了HE-Drive,這是首個類人端到端駕駛系統。HE-Drive將多視角傳感器數據作為輸入,并在復雜場景中輸出最優行駛路徑。
端到端范式將感知、規劃和軌跡評分任務集成到一個統一模型中,以規劃目標進行優化,最近在推動自動駕駛技術發展方面展示了顯著的潛力(圖1a)。最新研究提出了基于模仿學習的運動規劃器,它們通過大規模駕駛演示學習駕駛策略,并使用基于學習的軌跡評分器從多個預測候選軌跡中選擇最安全、最準確的軌跡來控制車輛。然而,盡管現有的規劃器和評分器在預測準確性方面取得了顯著進展,它們仍面臨生成時間不一致軌跡的挑戰,即連續的預測在時間上不穩定且不一致,以及選擇不舒適軌跡的問題,這些軌跡表現為連續制動,導致車輛停頓或過大的轉彎曲率。
本文提出了HE-Drive,這是首個以類人駕駛為核心的端到端自動駕駛系統,旨在解決上述兩個問題,如圖2所示。具體而言,本文發現由基于模仿學習的規劃器生成的軌跡在時間一致性方面存在的問題主要源于兩個因素:時間相關性和泛化能力。首先,這些規劃器依賴當前幀過去幾秒的信息來預測未來軌跡,忽略了連續預測之間的相關性。其次,它們的性能受到離線收集的專家軌跡質量的限制,導致在系統動態變化和分布外狀態下,所學的策略缺乏應對未見場景的泛化能力。受擴散策略在機器人操作中取得成功的啟發,該策略采用視覺條件的擴散模型來精確表示多模態分布以生成動作序列,本文提出了一種基于擴散的規劃器,能夠生成具有強時間一致性的多模態軌跡。
此外,導致預測軌跡不舒適的關鍵原因在于次優軌跡評分器無法實現持續評估,并且缺乏衡量軌跡舒適度的通用指標。近期研究表明,基于學習的評分器在閉環場景中不如基于規則的評分器,而后者由于依賴手工設計的后處理方式,泛化能力有限。其他研究者探索了使用視覺語言模型(VLMs)來感知周圍代理的運動和交通表示,從而決定下一步行動。然而,直接將VLMs作為駕駛決策者面臨解釋性差和嚴重幻覺問題。為了解決這些問題,本文提出了一種新穎的軌跡評分器和通用的舒適度指標,結合了基于規則評分器的可解釋性與VLMs的適應性,能夠根據駕駛風格(例如,激進或保守)進行調整,從而實現持續評估。
綜上所述,HE-Drive是一種新穎的以類人駕駛為核心的端到端自動駕駛系統。該系統利用稀疏感知技術,通過稀疏特征來檢測、跟蹤并映射駕駛場景,生成三維空間表示。這些表示作為條件輸入到基于擴散的運動規劃器中,該規劃器由條件去噪擴散概率模型(DDPM)驅動。最后,基于視覺語言模型(如Llama 3.2V)引導的軌跡評分器從候選軌跡中選擇最舒適的軌跡來控制車輛,確保類人風格的端到端駕駛體驗。
相關工作回顧
端到端自動駕駛
端到端自動駕駛旨在直接從原始傳感器生成規劃軌跡。在該領域,根據其評估方法對進步進行了分類:開環和閉環系統。在開環系統中,UniAD提出了一個統一的框架,該框架將全棧驅動任務與查詢統一接口集成在一起,以改善任務之間的交互。VAD提高了規劃的安全性和效率,其在nuScenes數據集上的性能證明了這一點,而SparseDrive利用稀疏表示來減輕模塊化系統中固有的信息丟失和錯誤傳播,提高了任務性能和計算效率。對于閉環評估,VADv2通過概率規劃推進了矢量化自動駕駛,使用多視圖圖像生成車輛控制的動作分布,在CARLA Town05基準中表現出色。
擴散模型用于軌跡生成
擴散模型最初在圖像合成中備受贊譽,現已被巧妙地用于軌跡生成。基于Potential的擴散運動規劃通過使用學習到的勢函數來構建適用于雜亂環境的自適應運動規劃,進一步增強了該領域,展示了該方法的可擴展性和可轉移性。NoMaD和SkillDiffuser都提出了統一的框架,分別簡化了面向目標的導航和基于技能的任務執行,其中NoMaD實現了更好的導航結果,SkillDiffusion實現了可解釋的高級指令遵循。總之,擴散模型為基于模仿學習的端到端自動駕駛框架的軌跡規劃提供了一種有前景的替代方案。由于固有的因果混淆,模仿學習模型可能會錯誤地將駕駛員的行為歸因于錯誤的因果因素。相比之下,擴散模型可以通過學習場景特征和駕駛員動作在潛在空間中的聯合分布,更好地捕捉潛在的因果關系,使模型能夠正確地將真實原因與適當的動作相關聯。
大模型用于軌跡評測
軌跡評分在自動駕駛決策中起著至關重要的作用。基于規則的方法提供了強有力的安全保證,但缺乏靈活性,而基于學習的方法在開環任務中表現良好,但在閉環場景中表現不佳。最近,DriveLM將VLM集成到端到端的駕駛系統中,通過感知、預測和規劃問答對對對圖結構推理進行建模。然而,大型模型的生成結果可能包含幻覺,需要進一步的策略來安全應用于自動駕駛。VLM的出現提出了一個問題:VLM能否根據軌跡評分器自適應地調整駕駛風格,同時確保舒適性?
HE-Drive方法詳解
稀疏感知
HE Drive首先采用視覺編碼器從輸入的多視圖相機圖像中提取多視圖視覺特征,表示為F。隨后稀疏感知同時執行檢測、跟蹤和在線地圖任務,為周圍環境提供更高效、更緊湊的3D表示(見圖2)。

基于擴散模型的運動規劃
圖2展示了我們基于擴散的運動規劃器的整體流程。我們采用基于CNN的擴散策略作為基礎,該策略由一個由1D卷積層、上采樣層和FiLM(特征線性調制)層組成的條件U-Net組成。
運動規劃器擴散策略:本文的方法(圖7)采用了條件去噪擴散概率模型(DDPM),這是一個通過參數化馬爾可夫鏈定義的生成模型,使用變分推理訓練來模擬條件分布p(At | Ot)。DDPM由一個正向過程和一個反向過程組成,正向過程逐漸將高斯噪聲添加到輸入數據中,將其轉換為純噪聲,反向過程迭代地對噪聲數據進行去噪以恢復原始數據。

大模型指導下的軌跡評分
為了從DDPM生成的多模態軌跡中選擇最合適的路徑,我們引入了VLMs制導軌跡評分器(VTS),如圖3所示。據我們所知,VTS是第一個結合了可解釋性和零樣本駕駛推理能力的軌跡評分器。通過利用視覺語言模型(VLM),悉尼威立雅運輸公司可以根據各種駕駛因素(如碰撞概率和舒適度)有效地評估軌跡,從而實現透明的決策和對新駕駛場景的適應性,而無需進行廣泛的微調(即終身評估)。

實驗結果

圖4:Llama 3.2V在nuScenes上的定性結果。本文展示了問題(Q)、上下文(C)和答案(A)。通過結合環視圖像和文本數據,基于規則的評分器通過針對性的權重修改,實現了駕駛風格的微調。

圖5:(a) 和 (b) 展示了軌跡生成和評分過程,其中(a) 中的灰色軌跡表示為最優路徑,基于最低成本標準被選中用于車輛控制。

圖6:(a) 顯示了HE-Drive與兩個基線模型在真實世界數據中舒適度指標的比較結果;(b) 顯示了HE-Drive在閉環數據集OpenScene上的效率指標比較結果。
總結
本文介紹了HE-Drive,一種新穎的以類人駕駛為核心的端到端自動駕駛系統,旨在解決現有方法在實現時間一致性和乘客舒適度方面的局限性。HE-Drive集成了稀疏感知模塊、基于擴散的運動規劃器以及Llama 3.2V引導的軌跡評分系統。稀疏感知模塊通過統一檢測、跟蹤和在線映射,實現了完全稀疏的場景表示。基于擴散的運動規劃器在連續空間中生成多模態軌跡,確保時間一致性并模擬人類的決策過程。軌跡評分模塊結合了基于規則的方法和Llama 3.2V,提升了系統的泛化能力、可解釋性、穩定性和舒適度。廣泛的實驗表明,HE-Drive在開放環和閉環數據集上相較于最先進的方法表現出色,生成了具備更好時間一致性和乘客舒適度的類人軌跡。