













全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,還煉出最強8B開源模型
為了將大型語言模型(LLM)與人類的價值和意圖對齊,學習人類反饋至關重要,這能確保它們是有用的、誠實的和無害的。在對齊 LLM 方面,一種有效的方法是根據人類反饋的強化學習(RLHF)。盡管經典 RLHF 方法的結果很出色,但其多階段的過程依然帶來了一些優化難題,其中涉及到訓練一個獎勵模型,然后優化一個策略模型來最大化該獎勵。
近段時間已有一些研究者探索了更簡單的離線算法,其中之一便是直接偏好優化(DPO)。DPO 是通過參數化 RLHF 中的獎勵函數來直接根據偏好數據學習策略模型,這樣就無需顯式的獎勵模型了。該方法簡單穩定,已經被廣泛用于實踐。
使用 DPO 時,得到隱式獎勵的方式是使用當前策略模型和監督式微調(SFT)模型之間的響應似然比的對數 的對數比。但是,這種構建獎勵的方式并未與引導生成的指標直接對齊,該指標大約是策略模型所生成響應的平均對數似然。訓練和推理之間的這種差異可能導致性能不佳。
為此,弗吉尼亞大學的助理教授孟瑜與普林斯頓大學的在讀博士夏夢舟和助理教授陳丹琦三人共同提出了 SimPO—— 一種簡單卻有效的離線偏好優化算法。

- 論文標題:SimPO: Simple Preference Optimization with a Reference-Free Reward
- 論文地址:https://arxiv.org/pdf/2405.14734
- 代碼 & 模型:https://github.com/princeton-nlp/SimPO
該算法的核心是將偏好優化目標中的獎勵函數與生成指標對齊。SimPO 包含兩個主要組件:(1)在長度上歸一化的獎勵,其計算方式是使用策略模型的獎勵中所有 token 的平均對數概率;(2)目標獎勵差額,用以確保獲勝和失敗響應之間的獎勵差超過這個差額。
總結起來,SimPO 具有以下特點:
- 簡單:SimPO 不需要參考模型,因此比 DPO 等其它依賴參考模型的方法更輕量更容易實現。
- 性能優勢明顯:盡管 SimPO 很簡單,但其性能卻明顯優于 DPO 及其最新變體(比如近期的無參考式目標 ORPO)。如圖 1 所示。并且在不同的訓練設置和多種指令遵從基準(包括 AlpacaEval 2 和高難度的 Arena-Hard 基準)上,SimPO 都有穩定的優勢。
- 盡量小的長度利用:相比于 SFT 或 DPO 模型,SimPO 不會顯著增加響應長度(見表 1),這說明其長度利用是最小的。

該團隊進行了大量分析,結果表明 SimPO 能更有效地利用偏好數據,從而在驗證集上對高質量和低質量響應的似然進行更準確的排序,這進一步能造就更好的策略模型。
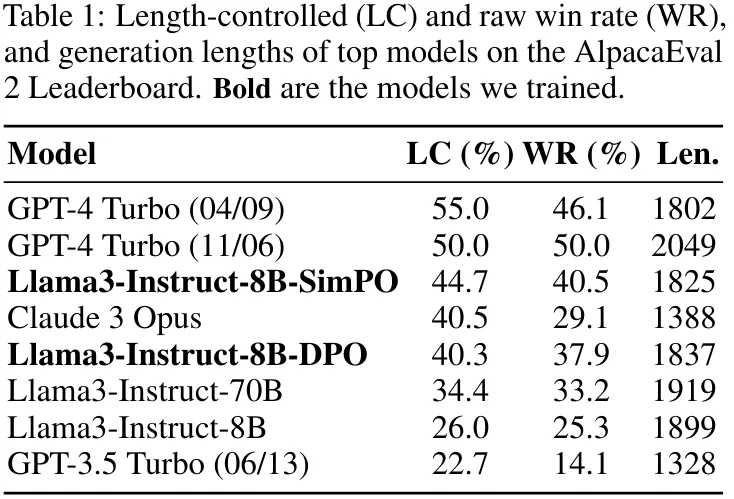
如表 1 所示,該團隊基于 Llama3-8B-instruct 構建了一個具有頂尖性能的模型,其在 AlpacaEval 2 上得到的長度受控式勝率為 44.7,在排行榜上超過了 Claude 3 Opus;另外其在 Arena-Hard 上的勝率為 33.8,使其成為了目前最強大的 8B 開源模型。
SimPO:簡單偏好優化
為便于理解,下面首先介紹 DPO 的背景,然后說明 DPO 的獎勵與生成所用的似然度量之間的差異,并提出一種無參考的替代獎勵公式來緩解這一問題。最后,通過將目標獎勵差額項整合進 Bradley-Terry 模型中,推導出 SimPO 目標。
背景:直接偏好優化(DPO)
DPO 是最常用的離線偏好優化方法之一。DPO 并不會學習一個顯式的獎勵模型,而是使用一個帶最優策略的閉式表達式來對獎勵函數 r 進行重新參數化:
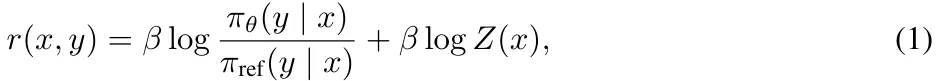
其中 π_θ 是策略模型,π_ref 是參考策略(通常是 SFT 模型),Z (x) 是配分函數。通過將這種獎勵構建方式整合進 Bradley-Terry (BT) 排名目標, ,DPO 可使用策略模型而非獎勵模型來表示偏好數據的概率,從而得到以下目標:
,DPO 可使用策略模型而非獎勵模型來表示偏好數據的概率,從而得到以下目標:

其中 (x, y_w, y_l) 是由來自偏好數據集 D 的 prompt、獲勝響應和失敗響應構成的偏好對。
一種與生成結果對齊的簡單無參考獎勵
DPO 的獎勵與生成之間的差異。使用 (1) 式作為隱式的獎勵表達式有以下缺點:(1) 訓練階段需要參考模型 π_ref,這會帶來額外的內存和計算成本;(2) 訓練階段優化的獎勵與推理所用的生成指標之間存在差異。具體來說,在生成階段,會使用策略模型 π_θ 生成一個能近似最大化平均對數似然的序列,定義如下:

在解碼過程中直接最大化該指標是非常困難的,為此可以使用多種解碼策略,如貪婪解碼、波束搜索、核采樣和 top-k 采樣。此外,該指標通常用于在語言模型執行多選任務時對選項進行排名。在 DPO 中,對于任意三元組 (x, y_w, y_l),滿足獎勵排名 r (x, y_w) > r (x, y_l) 并不一定意味著滿足似然排名 。事實上,在使用 DPO 訓練時,留存集中大約只有 50% 的三元組滿足這個條件(見圖 4b)。
。事實上,在使用 DPO 訓練時,留存集中大約只有 50% 的三元組滿足這個條件(見圖 4b)。
構建在長度上歸一化的獎勵。很自然地,我們會考慮使用 (3) 式中的 p_θ 來替換 DPO 中的獎勵構建,使其與引導生成的似然指標對齊。這會得到一個在長度上歸一化的獎勵:

其中 β 是控制獎勵差異大小的常量。該團隊發現,根據響應長度對獎勵進行歸一化非常關鍵;從獎勵公式中移除長度歸一化項會導致模型傾向于生成更長但質量更低的序列。這樣一來,構建的獎勵中就無需參考模型了,從而實現比依賴參考模型的算法更高的內存和計算效率。
SimPO 目標
目標獎勵差額。另外,該團隊還為 Bradley-Terry 目標引入了一個目標獎勵差額項 γ > 0,以確保獲勝響應的獎勵 r (x, y_w) 超過失敗響應的獎勵 r (x, y_l) 至少 γ:

兩個類之間的差額已知會影響分類器的泛化能力。在使用隨機模型初始化的標準訓練設置中,增加目標差額通常能提升泛化性能。在偏好優化中,這兩個類別是單個輸入的獲勝或失敗響應。
在實踐中,該團隊觀察到隨著目標差額增大,生成質量一開始會提升,但當這個差額變得過大時,生成質量就會下降。DPO 的一種變體 IPO 也構建了與 SimPO 類似的目標獎勵差額,但其整體目標的效果不及 SimPO。
目標。最后,通過將 (4) 式代入到 (5) 式中,可以得到 SimPO 目標:

總結起來,SimPO 采用了與生成指標直接對齊的隱式獎勵形式,從而消除了對參考模型的需求。此外,其還引入了一個目標獎勵差額 γ 來分離獲勝和失敗響應。
實驗設置
模型和訓練設置。該團隊的實驗使用了 Base 和 Instruct 兩種設置下的兩類模型 Llama3-8B 和 Mistral-7B。
評估基準。該團隊使用了三個最常用的開放式指令遵從基準:MT-Bench、AlpacaEval 2 和 Arena-Hard v0.1。這些基準可評估模型在各種查詢上的多樣化對話能力,并已被社區廣泛采用。表 2 給出了一些細節。

基線方法。表 3 列出了與 SimPO 做對比的其它離線偏好優化方法。

實驗結果
主要結果與消融研究
SimPO 的表現總是顯著優于之前已有的偏好優化方法。如表 4 所示,盡管所有的偏好優化算法的表現都優于 SFT 模型,但簡單的 SimPO 卻在所有基準和設置上都取得了最佳表現。這樣全面的大幅領先彰顯了 SimPO 的穩健性和有效性。
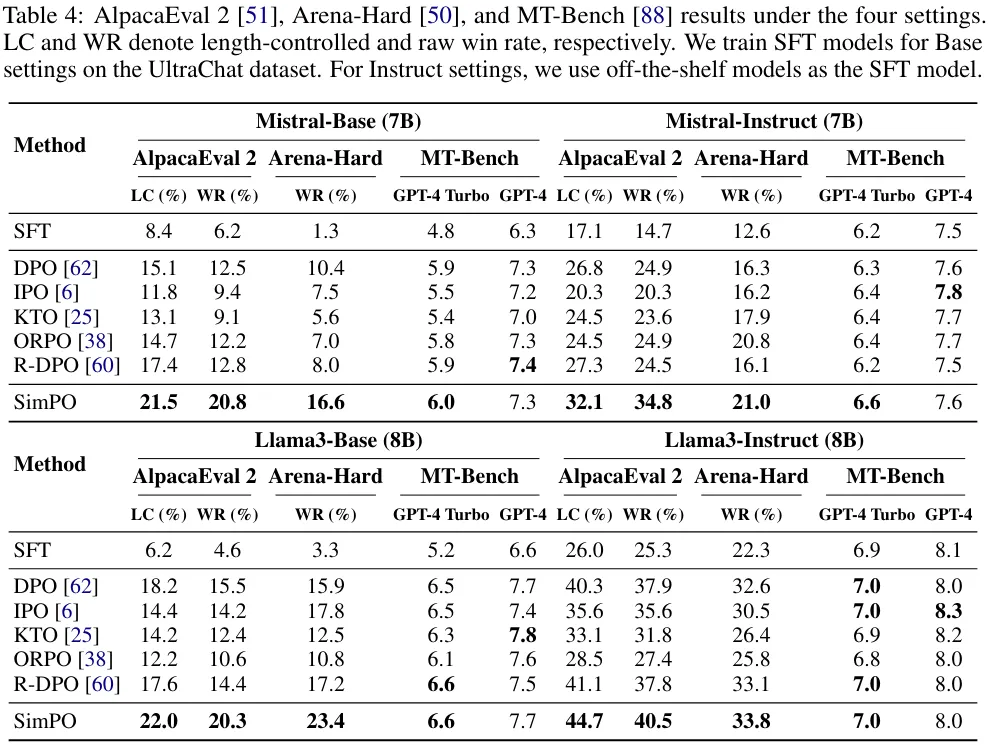
基準質量各不相同。可以觀察到,在 Arena-Hard 上的勝率明顯低于在 AlpacaEval 2 上勝率,這說明 Arena-Hard 是更困難的基準。
Instruct 設置會帶來顯著的性能增益。可以看到,Instruct 設置在所有基準上都全面優于 Base 設置。這可能是因為這些模型使用了更高質量的 SFT 模型來進行初始化以及這些模型生成的偏好數據的質量更高。
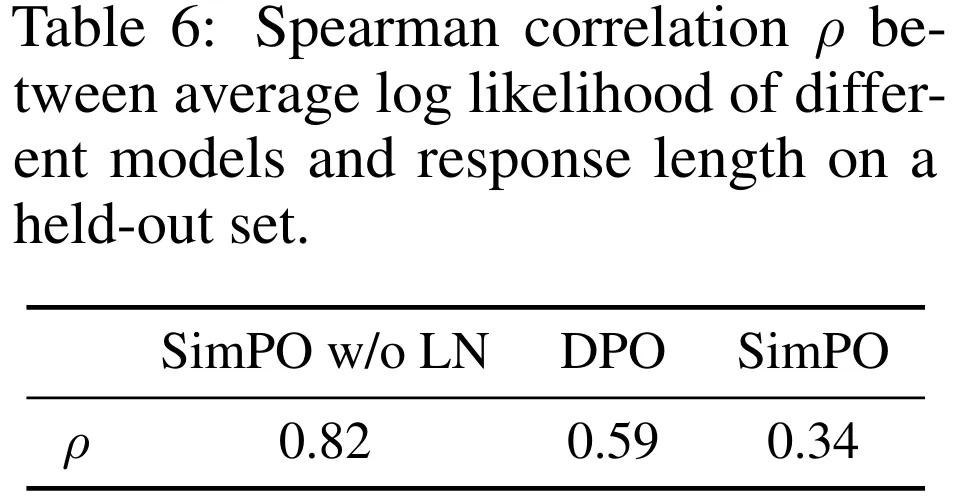
SimPO 的兩種關鍵設計都很重要。表 5 展示了對 SimPO 的每種關鍵設計進行消融實驗的結果。(1) 移除 (4) 式中的長度歸一化(即 w/o LN);(2) 將 (6) 式中的目標獎勵差額設置為 0(即 γ = 0)。

移除長度歸一化對結果的影響最大。該團隊研究發現,這會導致模型生成長且重復的模式,由此嚴重拉低輸出的整體質量。將 γ 設為 0 也會導致 SimPO 的性能下降,這說明 0 并非最優的目標獎勵差額。

有關這兩項設計選擇的更深度分析請參閱原論文。
深度對比 DPO 與 SimPO
最后,該團隊還從四個角度全面比較了 DPO 與 SimPO:(1) 似然 - 長度相關性、(2) 獎勵構建、(3) 獎勵準確度、(4) 算法效率。結果表明 SimPO 在準確度和效率方面優于 DPO。
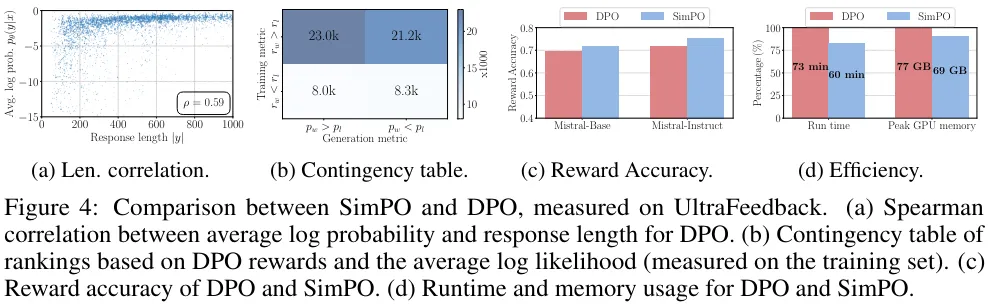
DPO 獎勵會隱式地促進長度歸一化。
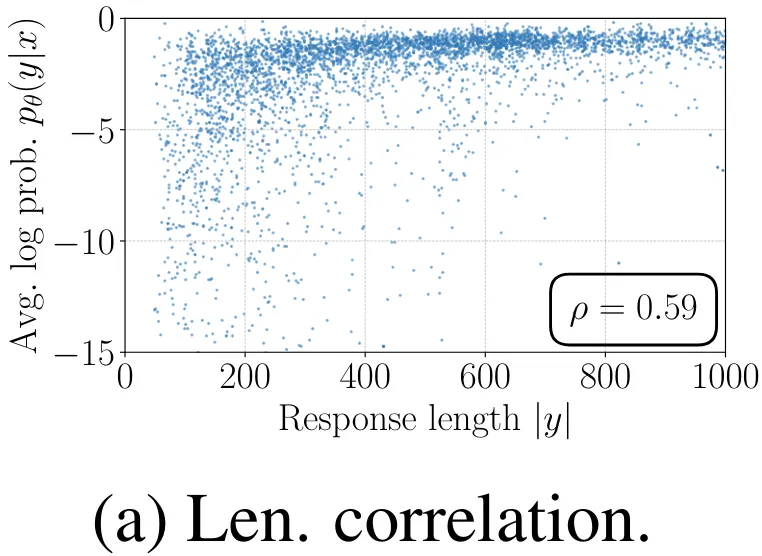
盡管 DPO 獎勵表達式  (不包含配分函數)缺乏一個用于長度歸一化的顯式項,但策略模型和參考模型之間的對數比可以隱式地抵消長度偏見。如表 6 與圖 4a 所示,相比于沒有任何長度歸一化的方法(記為 SimPO w/o LN),使用 DPO 會降低平均對數似然和響應長度之間的斯皮爾曼相關系數。但是,當與 SimPO 比較時,其仍然表現出更強的正相關性。
(不包含配分函數)缺乏一個用于長度歸一化的顯式項,但策略模型和參考模型之間的對數比可以隱式地抵消長度偏見。如表 6 與圖 4a 所示,相比于沒有任何長度歸一化的方法(記為 SimPO w/o LN),使用 DPO 會降低平均對數似然和響應長度之間的斯皮爾曼相關系數。但是,當與 SimPO 比較時,其仍然表現出更強的正相關性。
DPO 獎勵與生成似然不匹配。

DPO 的獎勵與平均對數似然指標之間存在差異,這會直接影響生成。如圖 4b 所示,在 UltraFeedback 訓練集上的實例中,其中  ,幾乎一半的數據對都有
,幾乎一半的數據對都有 。相較之下,SimPO 是直接將平均對數似然(由 β 縮放)用作獎勵表達式,由此完全消除了其中的差異。
。相較之下,SimPO 是直接將平均對數似然(由 β 縮放)用作獎勵表達式,由此完全消除了其中的差異。
DPO 在獎勵準確度方面不及 SimPO。

圖 4c 比較了 SimPO 和 DPO 的獎勵準確度,這評估的是它們最終學習到的獎勵與留存集上的偏好標簽的對齊程度。可以觀察到,SimPO 的獎勵準確度高于 DPO,這說明 SimPO 的獎勵設計有助于實現更有效的泛化和更高質量的生成。
SimPO 的內存效率和計算效率都比 DPO 高。

SimPO 的另一大優勢是效率,畢竟它不使用參考模型。圖 4d 給出了在 8×H100 GPU 上使用 Llama3-Base 設置時,SimPO 和 DPO 的整體運行時間和每臺 GPU 的峰值內存使用量。相比于原版 DPO 實現,得益于消除了使用參考模型的前向通過,SimPO 可將運行時間降低約 20%,將 GPU 內存使用量降低約 10%。
更多詳細內容,請閱讀原文。






























