













陳丹琦帶著清華特獎(jiǎng)學(xué)弟發(fā)布新成果:打破谷歌BERT提出的訓(xùn)練規(guī)律
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
新晉斯隆獎(jiǎng)得主如何慶祝?
公開最新研究成果算不算?
就在斯隆獎(jiǎng)宣布當(dāng)天,陳丹琦團(tuán)隊(duì)展示了最新的研究成果。
團(tuán)隊(duì)發(fā)現(xiàn),經(jīng)典NLP模型BERT提出的預(yù)訓(xùn)練“15%掩蔽率”法則,是可以被打破的!
“15%掩蔽率”,指在一項(xiàng)預(yù)訓(xùn)練任務(wù)中,隨機(jī)遮住15%的單詞,并通過訓(xùn)練讓AI學(xué)會(huì)預(yù)測(cè)遮住的單詞。
陳丹琦團(tuán)隊(duì)認(rèn)為,如果將掩蔽率提升到40%,性能甚至比15%的時(shí)候還要更好:

不僅如此,這篇文章還提出了一種新的方法,來更好地提升40%掩蔽率下NLP模型訓(xùn)練的效果。
一位抱抱臉(Hugging Face)工程師對(duì)此表示:
關(guān)于BERT有個(gè)很有意思的事情,它雖然是一項(xiàng)開創(chuàng)性的研究,然而它的那些訓(xùn)練方式都是錯(cuò)誤或不必要的。

這篇論文的共同一作高天宇,也是清華特獎(jiǎng)獲得者,本科期間曾發(fā)表過四篇頂會(huì)論文。
那么,論文究竟是怎么得出這一結(jié)論的呢?
“大模型更適合高掩蔽率”
陳丹琦團(tuán)隊(duì)先是從掩蔽率、迭代次數(shù)和模型大小三個(gè)方向,驗(yàn)證了這一結(jié)論。
他們先是用了一系列不同的掩蔽率來訓(xùn)練NLP模型,參數(shù)如下:
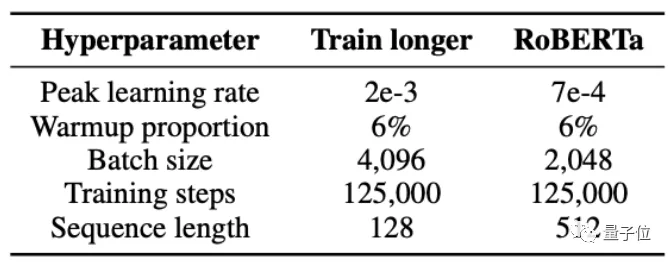
結(jié)果發(fā)現(xiàn),除了小部分?jǐn)?shù)據(jù)集以外,模型在包括MNLI、QNLI、QQP、STS-B、SQuAD等數(shù)據(jù)集上的訓(xùn)練效果,40%掩蔽率都比15%都要更好。
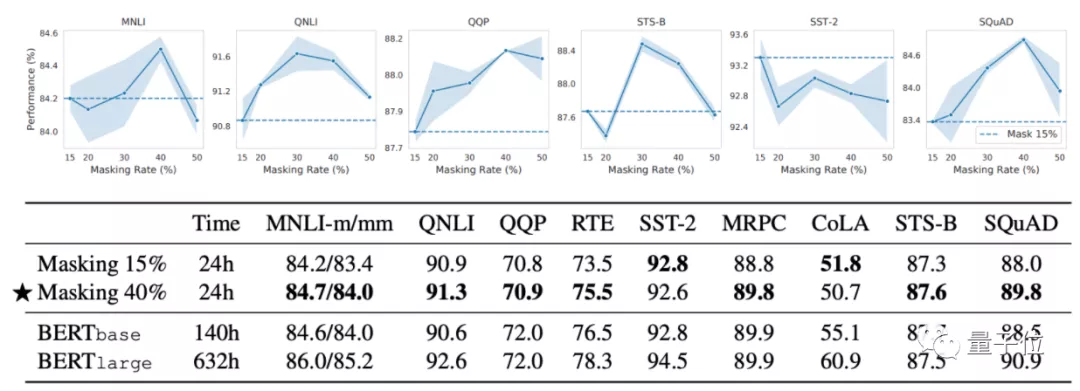
為了進(jìn)一步迭代次數(shù) (training step)受掩蔽率的影響效果,作者們同樣記錄了不同迭代率下模型的效果。
結(jié)果顯示,隨著迭代次數(shù)的增加,40%掩蔽率基本都表現(xiàn)出了比15%更好的性能:

不僅如此,作者們還發(fā)現(xiàn),更大的模型,更適合用40%掩蔽率去訓(xùn)練。
結(jié)果顯示,大模型在40%掩蔽率的情況下,性能比中等NLP模型要更好:
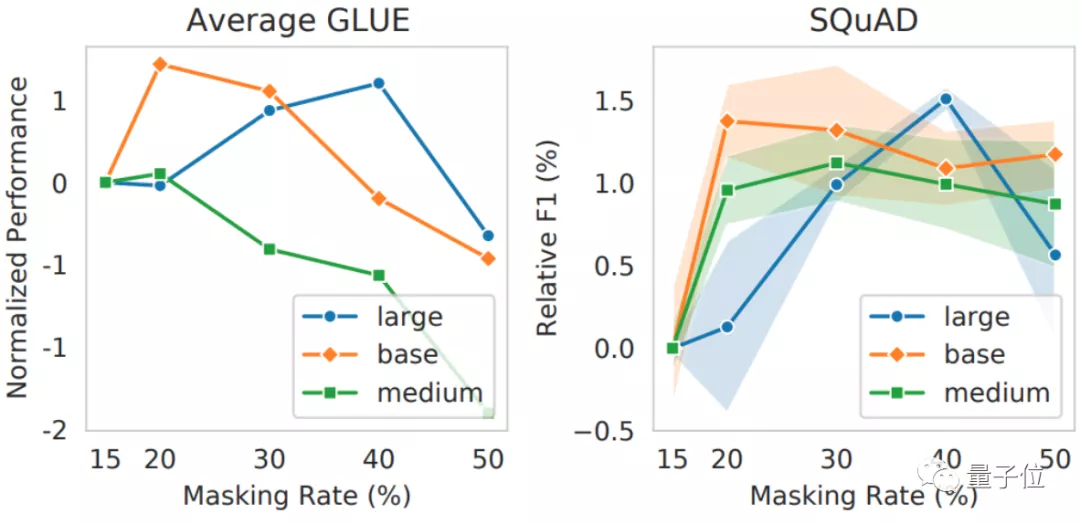
這么看來,只將掩蔽率設(shè)置為15%,確實(shí)沒有40%的訓(xùn)練效果更好,而且,更大的NLP模型還更適合用40%的掩蔽率來訓(xùn)練。
團(tuán)隊(duì)猜測(cè),任務(wù)難一些能促使模型學(xué)到更多特征,而大模型正是有這種余裕。
為了探究其中的原理,作者們又提出了一個(gè)新的評(píng)估方法。
將掩蔽率拆分為2個(gè)指標(biāo)
具體來說,就是將掩蔽率拆分為破壞率 (corruption rate)和預(yù)測(cè)率 (prediction rate)2個(gè)指標(biāo)。
其中,破壞率是句子被破壞的比例,預(yù)測(cè)率是模型預(yù)測(cè)的比例。
例如,“我喜歡打籃球”語料可能被破壞成“我[MASK][MASK][MASK]”提供給模型,但模型卻只需要預(yù)測(cè)第一個(gè)[MASK]是不是“喜歡”。
這樣一來,就可以用破壞率來控制預(yù)訓(xùn)練任務(wù)的難度,用預(yù)測(cè)率來控制模型的優(yōu)化效果。
論文進(jìn)一步針對(duì)破壞率(mcorr)和預(yù)測(cè)率(mpred)進(jìn)行了研究,發(fā)現(xiàn)了一個(gè)新規(guī)律:
預(yù)測(cè)率高,模型效果更好;但破壞率更高,模型效果更差:
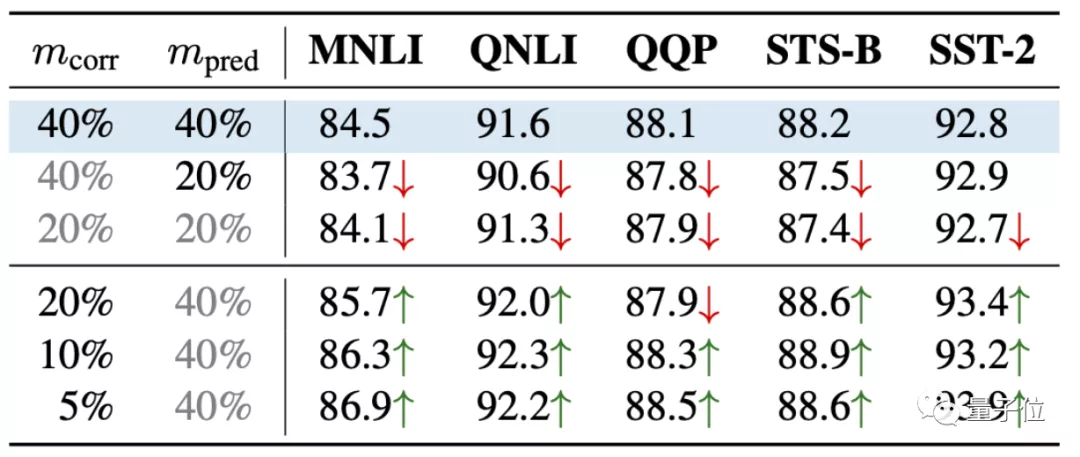
這樣就能用更精準(zhǔn)的方式來評(píng)估各種預(yù)訓(xùn)練任務(wù)了。
最后,作者們?cè)谶@種指標(biāo)下,測(cè)試了多種掩碼,觀察在更高掩蔽率的情況下,哪些掩碼的效果更好。
結(jié)果顯示,隨著掩蔽率的提升,隨機(jī)均勻掩碼的效果(Uniform)的表現(xiàn)還會(huì)比Span Masking、相關(guān)區(qū)間原則性掩碼(PMI-Masking)更好。
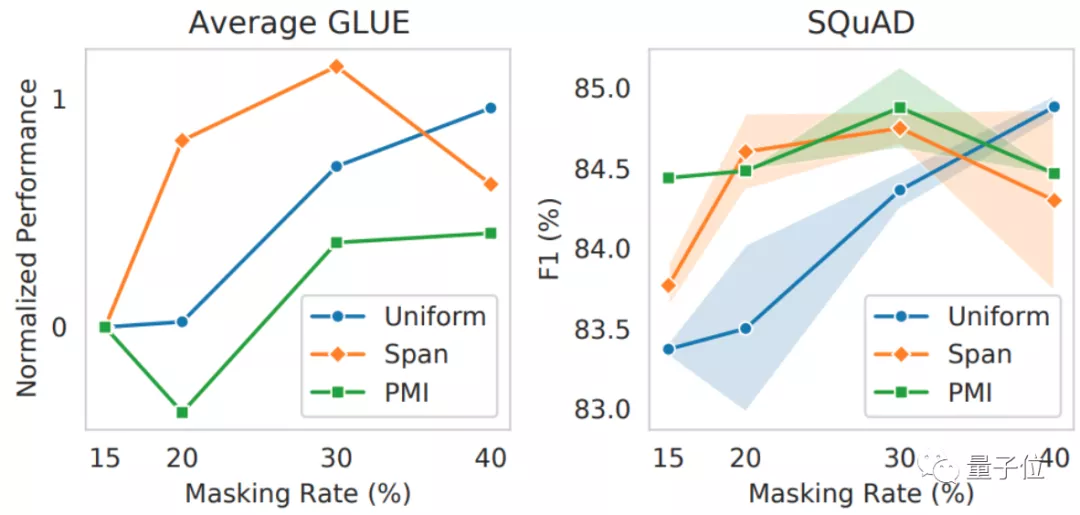
然而,在之前的很多NLP模型中,基本都直接采用了PMI-Masking或是Span Masking等更復(fù)雜的掩碼來訓(xùn)練。
這也說明,NLP大模型的預(yù)訓(xùn)練效果不能一概而論,光是訓(xùn)練方法就值得進(jìn)一步研究。
作者介紹
論文的幾名作者均來自陳丹琦團(tuán)隊(duì)。

一作高天宇,目前是普林斯頓大學(xué)的二年級(jí)博士生,本科畢業(yè)于清華大學(xué),曾經(jīng)獲得清華本科特等獎(jiǎng)學(xué)金。
本科時(shí),高天宇就在劉知遠(yuǎn)教授團(tuán)隊(duì)中搞科研了,期間一共發(fā)表了4篇頂會(huì)論文(兩篇AAAI,兩篇EMNLP)。

共同一作Alexander Wettig,普林斯頓大學(xué)一年級(jí)博士生,本碩畢業(yè)于劍橋大學(xué),對(duì)NLP的泛化能力方向感興趣。

鐘澤軒(Zexuan Zhong),普林斯頓大學(xué)博士生,碩士畢業(yè)于伊利諾伊大學(xué)香檳分校,導(dǎo)師是謝濤;本科畢業(yè)于北京大學(xué)計(jì)算機(jī)系,曾在微軟亞研院實(shí)習(xí),導(dǎo)師是聶再清。
通過這一發(fā)現(xiàn),不少NLP大模型說不定又能通過改進(jìn)訓(xùn)練方法,取得更好的效果了。
論文地址:
https://gaotianyu.xyz/content/files/2022/02/should_you_mask_15-1.pdf

























