













AI訓練數據的版權保護:公地的悲劇還是合作的繁榮?
GPT-4o內置聲音模仿「寡姐」一案鬧的沸沸揚揚,雖然以OpenAI發布聲明暫停使用疑似寡姐聲音的「SKY」的語音、否認曾侵權聲音為階段性結束。但是,一時間「即便是AI,也得保護人類版權」這一話題甚囂塵上,更刺激起了人們本來就對AI是否可控這一現代迷思的焦慮。
近日,普林斯頓大學、哥倫比亞大學、哈佛大學和賓夕法尼亞大學共同推出了一項關于生成式AI版權保護的新方案,題為《An Economic Solution to Copyright Challenges of Generative AI》。

生成式人工智能(AI)技術的快速進展已經深刻影響了文藝產業,帶來了文學、視覺藝術和音樂等領域中由AI生成的內容時代。這些AI模型如大型語言模型和擴散模型能夠創作出能夠與人類藝術家的作品媲美乃至可能取代的高復雜性內容。
這種能力的迅速增長引發了關于大模型訓練數據作者權利的法律和道德界限的重要問題,特別是在版權侵犯方面的爭議。
版權保護一直以來都是各國法律中不可或缺的一部分。保護創作者的權益,可以更有利于調動創作者的積極性,使得文化事業更加繁華。版權保護為創作者不止提供了精神支持,也同時提供了物質支持 (利益分配),這也是為創作者進一步提供了再創作的物質基礎和精神動力。
另一方面,版權保護也更利于優秀作品的傳播,因為版權保護也是在保護傳播者的正當權益和保護公眾對于分享知識文化成果的權利。誠然,一部作品的誕生,不是為了孤芳自賞,更多的是為了以某種形式分享給大眾,為大眾所用。而且, 版權保護也可以讓創作者更加合理地使用他人的結果,避免引發剽竊等諸多麻煩。
因此,目前有幾家AI公司因涉嫌生產侵犯版權的內容而卷入法律訴訟。比如說 《紐約時報》起訴 Chatgpt的開發者 OpenAI [1],控訴后者將數百萬篇 《紐約時報》的文章被用于訓練智能聊天機器人(例如ChatGPT )。這些機器人現在作為新聞消息源與《紐約時報》展開競爭。
《紐約時報》聲稱,OpenAI和微軟大型語言模型 (LLM)能夠模仿《紐約時報》的文字風格從而生成類似內容,有時候甚至能原封不動生成已有的內容,這種現象影響到《紐約時報》通過訂閱和廣告獲得收入,并且有違版權許可。
起訴書中,《紐約時報》提及到一個例子 – 微軟的「以必應瀏覽(Browse With Bing)」中的功能,能夠幾乎一字不差地重現《紐約時報》旗下網站「The Wirecutter」的內容,但完全沒有為提供相關的鏈接進行引用。這個例子充分體現了AI 非法使用版權內容。
目前,針對OpenAI的類似訴訟案件正在不斷增加,例如近來GPT-4o內置聲音模仿「寡姐」一案 [2]。但由于對于AI 非常使用版權內容難以界定,訴訟案件尚在激烈討論中。

圖1:NY Times指控ChatGPT生成內容和NY Times文章高度一致。
為了緩解訓練數據版權所有者與AI開發者之間的緊張關系,人們已經開始嘗試修改生成模型的訓練或推理過程,以減少生成侵權內容的可能性。然而這些改動可能會因為排除了高質量的受版權保護的訓練數據或限制內容生成而損害模型性能。版權法的復雜性和模糊性增加了額外的難度,使得區分侵權和非侵權成果變得模糊不清。
這種不確定性可能導致雙方在法庭爭議中浪費大量資源。
本文提出一種在AI開發者和版權所有者之間建立互利的收益分享協議的方案,此提議呼應了經濟學中最近提倡的觀點。然而,模型訓練和內容生成的「黑箱」特性使得傳統的按比例直接分成方法不再適用。
因此,需要一種新的框架來公平合理地處理這些新出現的版權問題,確保在鼓勵創新的同時,也保護數據提供者的合法權益。
圖2:該工作被Ethan Mollick宣傳。
Shapley版權分享框架
該文章的框架分為兩步:
- 第一步是評估模型在整個數據集的每一個可能子集上訓練的效用。直觀上,如果在某數據子集上訓練的模型能夠有很大的可能性生成與部署模型相似的AI生成內容(例如藝術作品),那么該數據子集的效用就會很大。
- 第二步是根據第一步的效用使用合作博弈論工具(即Shapley值)來確定任何訓練數據版權所有者的應得份額。簡而言之,如果將其數據包括在模型訓練中能夠增加效用,那么版權所有者的份額就會大。
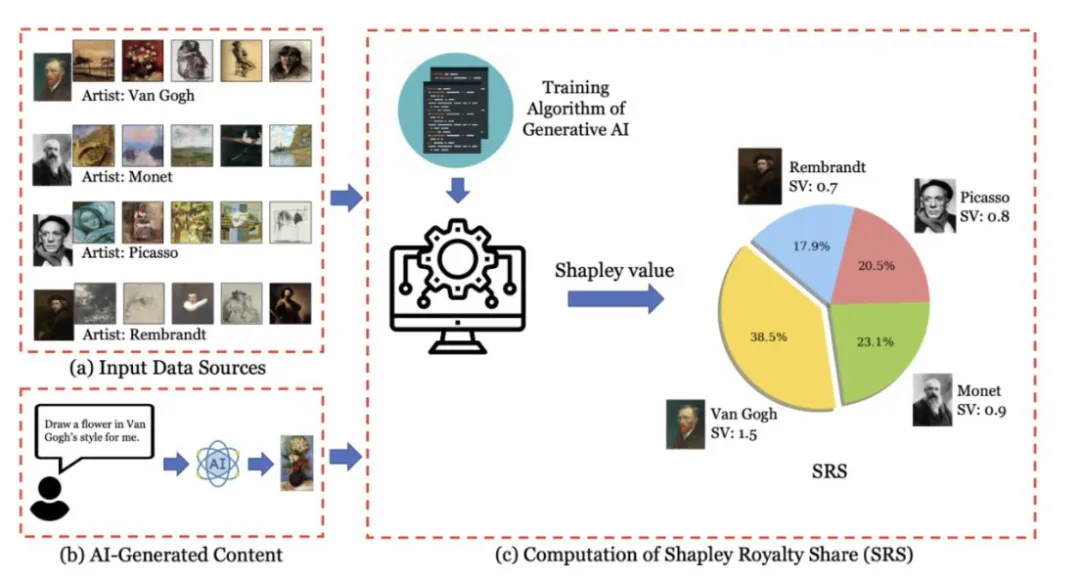
圖3:基于Shapley值的版權分配框架。
不同數據源組合的效用
設有 n 個版權所有者,第 i個擁有訓練數據集 的版權,其中i∈N?{1,2,…n}。部署的模型訓練在整個數據集
的版權,其中i∈N?{1,2,…n}。部署的模型訓練在整個數據集 上,并生成內容
上,并生成內容 。考慮一個在數據子集
。考慮一個在數據子集 上訓練的反事實模型,其中S?N表示數據所有者的一個子集。
上訓練的反事實模型,其中S?N表示數據所有者的一個子集。
該反事實模型生成同一內容 的概率密度函數由
的概率密度函數由 表示。對于生成模型生成的內容,一個子集的效用最容易反映在該反事實模型生成目標內容的概率。當比較不同模型時,可以通過生成目標內容的概率比例衡量它們之間的效用差距。
表示。對于生成模型生成的內容,一個子集的效用最容易反映在該反事實模型生成目標內容的概率。當比較不同模型時,可以通過生成目標內容的概率比例衡量它們之間的效用差距。
因此,該文章定義此模型對內容的 效用為
效用為 ,這樣可以直接根據
,這樣可以直接根據 來比較兩個數據集之間的效用。
來比較兩個數據集之間的效用。
這種效用提供了一種衡量數據源S在生成內容方面的責任程度的方式。如果反事實模型不太可能生成與部署模型相同的內容,其效用就小,反之亦然。
版權所有者間的版稅分配
效用v(S)可以解釋為所有S成員為訓練生成式AI模型提供數據所應得的總補償。下一步是基于所有可能的數據源組合的效用來確定每個個別版權所有者的收益。該文章提議使用Shapley值。
Shapley值是博弈論中的一個解決方案概念,它提供了一種根據每個玩家組合作為聯盟的效用分配收益的原則性方法。它是由諾貝爾獎獲得者Lloyd Shapley (此后簡稱為Shapley) 提出的。
Shapley (1923-2016)是美國籍數學家和經濟學家,并且由于對穩定分配理論和市場設計的實踐做出突出貢獻,而獲得了2012年的經濟學諾貝爾獎 [3]。Shapley是博弈論領域的傳奇,并且在其博士工作和博士論文中引入了Shapley值。
美國經濟學會稱Shapley是「博弈論和經濟學理論的巨人」。

Shapley值的具體計算如下:
參與者i的Shapley值計算為其在所有可能聯盟中邊際貢獻的加權平均:

Shapley值是唯一滿足幾個重要經濟屬性的支付規則,并在機器學習模型的數據估值中獲得了普及。利用Shapley值,該文章提出使用SRS(Shapley Royalty Share)來計算版權分配。
SRS定義如下:
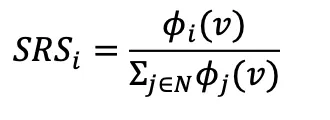
這里, 是版權所有者i的Shapley值。
是版權所有者i的Shapley值。
SRS提供了一種經濟學方法解決生成式AI環境中的版權和收益分配問題,支持公正的數據使用和創新激勵。
該文章用一個簡單的例子來解釋Shapley值的計算過程。在這個例子中,有三個數據所有者(A, B, C),他們共同訓練一個模型,使用模型對某生成內容的log-likelihood作為效用函數。假設使用不同的數據組合訓練后的模型的log-likelihood如下:

可以根據以下量來計算A的Shapley值:
- 數據所有者A單獨貢獻:v({A})=5
- 數據所有者A和B的貢獻:v({A,B})-v({B})=15-7=8
- 數據所有者A和C的貢獻:v({A,C})-v({C})=10-3=7
- 數據所有者A、B和C的貢獻:v({A,B,C})-v({B,C})=20-12=8
根據Shapley值公式,可以得到

計算考慮
在應用SRS框架時,主要挑戰在于其相當大的計算成本。對不同數據源組合的效用函數評估需要多次重新訓練模型。在版權所有者數量較少的某些應用中,計算挑戰可能并不像看起來那么嚴重。
實際上,可以預見這種基于合約的框架在整個版權數據被少數幾個版權所有者分割時效果最佳,這樣每個數據源都有足夠的數據影響訓練結果。如果數據源的規模非常小,版權所有者的版稅份額可能微不足道,且由于訓練AI模型的隨機性,結果可能更加噪聲化。
為了減輕這種計算負擔,可以采用兩種方法:
- 第一種是使用蒙特卡洛方法來近似計算Shapley值,這種技術特別適用于版權所有者眾多的情況。
- 第二種方法是通過從另一個在較小數據子集上訓練的模型微調來訓練模型。因此,可以通過對整個訓練數據只訓練一次,來近似在不同數據子集上訓練的模型。具體來說,對于隨機抽樣的版權所有者排列,可以首先在第一個版權所有者上訓練,然后是第二個,一直到最后一個版權所有者。這種技術可以與著名的Shapley值排列抽樣估計器一起使用。
在實踐中,商業AI模型可能每天進行數百萬次交易。僅估計每個版權所有者應得的聚合收益,而不是按照公式為每個AI生成的內容計算收益,可以節省計算成本。理論上,可以僅評估所有交易中一小部分的SRS,然后按比例計算從所有交易中獲得的收入分布。
實驗結果
該文章通過實驗評估了所提出框架在分配AI生成內容版稅方面的有效性,重點關注創意藝術和圖像領域的標志設計。
評估使用了公開可獲取的數據集:WikiArt和FlickrLogo-27。
評估SRS的有效性
對于WikiArt數據集,該文章選取了四位著名藝術家的四個不相交的畫作子集。一個最初在更廣泛的訓練圖像集(不包括這四位藝術家的作品)上訓練的模型,作為基礎模型。通過在選定藝術家的四組畫作的各種組合上進一步微調基礎模型,計算SRS。
類似地,對于FlickrLogo-27數據集,該文章選取了四個品牌的四個不相交的標志設計子集,并使用在其他品牌標志圖像上訓練的基礎模型計算SRS。該文章的目標是評估SRS是否能反映每個版權所有者對圖像生成的貢獻。
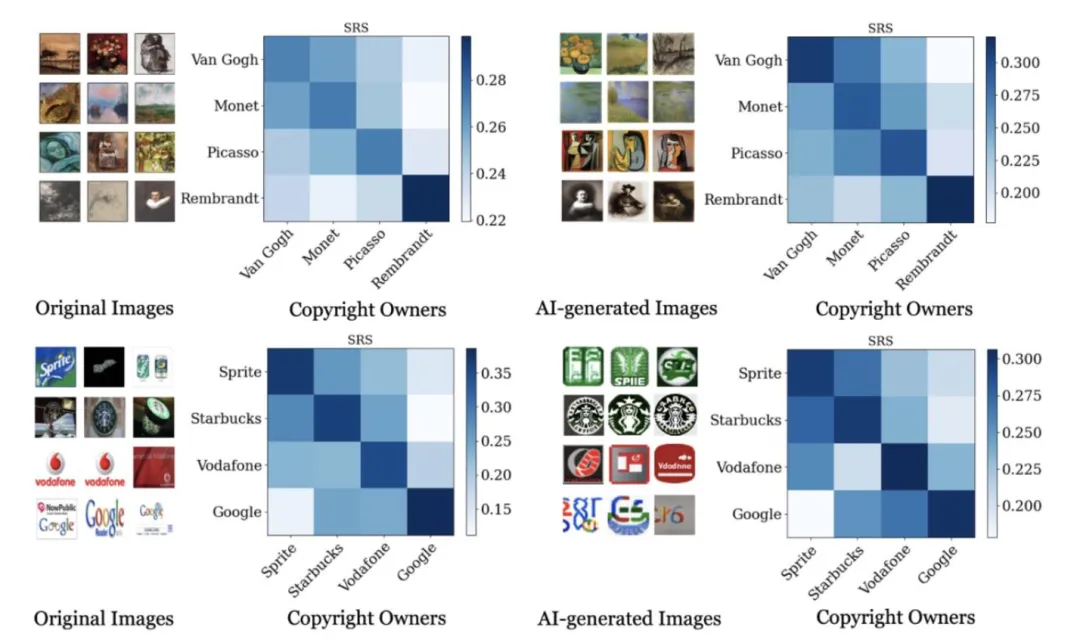
圖4:使用SRS評估每個版權所有者對圖像生成的貢獻。
結果表明,當 的風格與訓練數據源的風格非常接近時,SRS值最高。這一關系凸顯了SRS框架準確歸因于AI生成圖像創作貢獻的能力。
的風格與訓練數據源的風格非常接近時,SRS值最高。這一關系凸顯了SRS框架準確歸因于AI生成圖像創作貢獻的能力。
評估SRS對于混合風格的生成圖像的歸因能力
在WikiArt數據集上,該文章探討了針對要求從多個數據源生成內容的提示的SRS分布。顯著地,提示要求生成模型融合多位藝術家的風格。SRS有效地識別并獎勵了融入生成藝術作品的數據源的貢獻,展示了該框架在辨識和評價多樣化數據源輸入以生成內容的能力。

圖5:使用SRS評估每個版權所有者對混有不同藝術家風格的圖像生成的貢獻。
討論與深入研究
生成式AI的快速發展對傳統版權法構成了深刻挑戰,這不僅是因為其強大的內容生成能力,還因為對AI生成內容版權的解釋復雜以及大型AI系統的“黑箱”本質。該文章從經濟學角度出發,開發了一個允許在版權數據訓練中交換收入分配的版權分享模型,促進了AI開發者和版權所有者之間的互利合作。通過數值實驗,該文章證明了這一框架的有效性和可行性。
該文章的研究也為未來的研究開辟了道路。例如,版權所有者可能會通過合并或分割他們的數據來最大化版權分成,SRS可能會被惡意版權所有者操縱。盡管已經探索了抗復制的解決方案,但這些主要關注于Shapley值的影響而非復制下的比率。開發一種抗操縱的機制是未來工作的一個重要方向。
另一個開放問題是處理無法或不愿意協商協議的版權所有者的版權數據,特別是當每個擁有者的數據集很小的情況。在這種情況下,該文章的方法可以與生成合法內容的方法結合使用, 增強他們的模型以確定版權所有者和AI開發者之間適當的收入分配,認識到計算資源、算法設計和工程專長在開發高性能AI模型中的關鍵作用,是另一個研究方向。
該文章已經通過采用合作博弈理論中的權限結構概念來初步適應這種情況。
從方法論角度看,未來研究的一個關鍵方面是使用Shapley值比率進行收入分配。直接使用Shapley值的主要挑戰在于任何版權所有者數據聯盟的總收入未知。但當考慮比率時,Shapley值的效率屬性(確保所有Shapley值之和等于大聯盟的效用)失去了意義。
在這種情況下,半值(一種放棄效率公理的Shapley值推廣)可能提供了一個可行的替代方案。未來的工作可以旨在建立公理化的理由,以識別此背景下用于版稅分配的最合適的解決方案概念。
從實用性的角度講,Shapley值最大的不足之處在于計算開銷。盡管Monte Carlo方法可以加速計算過程,但仍需要大量的模型重復訓練。這種計算需求在處理大型數據集和復雜模型時變得尤其突出,可能導致計算資源的極大消耗和時間的延長。
未來的工作可以著重于解決這一問題,通過開發更高效的算法或啟用新的方法來減少計算開銷,從而使Shapley值在實際應用中更加可行和高效。
作者介紹:
1. Jiachen Wang (王嘉宸):現為普林斯頓大學電子工程系博士生,主攻人工智能數據估值(data valuation)等方向。
2. Zhun Deng (鄧準):現為哥倫比亞大學計算機系博后,博后導師為 Richard Zemel。此前為哈佛大學計算機系博士生,師從Cynthia Dwork,主攻機器學習可靠性和社會責任性等方向。
3. Hiroaki Chiba-Okabe:現為賓夕法尼亞大學應用數學和計算科學博士生,主攻方向是人工智能引發的道德問題和社會問題。
4. Boaz Barak: 哈佛大學正教授,主攻方向理論計算機和機器學習方向。同時在OpenAI 任職。
5. Wijie Su (蘇煒杰):現為賓夕法尼亞大學沃頓商學院、計算機系和數學系副教授,研究方向包括人工智能的理論基礎等方向。



















