













給NeRF開透視眼!稀疏視角下用X光進行三維重建,9類算法工具包全開源 | CVPR 2024
眾所周知,X 光由于有著十分強大的穿透力而被廣泛地應用于醫療、安檢、考古、生物、工業檢測等場景的透射成像。
然而,X 光的輻射作用對人體是有害的,受試者與測試者都會或多或少地收到影響。為了減少 X 光對人體的傷害,人們開始研究稀疏視角下的 X 光重建從而降低在 X 光中的暴露時間。
這主要包含了兩個子任務:
1. 新視角合成,即從一個被掃描物體的一些已拍攝的視角來合成出新的沒有被拍攝過的視角下該物體的投影。
2. CT 重建,即從多視角的 X 光投影中恢復出密集的三維 CT 體輻射密度 (volume radiodensity)。
輻射密度刻畫的是當 X 光穿透物體時,X 光被吸收或者阻擋的程度大小。如圖 2 所示,自然光成像主要靠的是光線在物體表面的反射。
而 X 光成像主要依靠的是 X 光穿透物體后被吸收或阻擋。換句話說,自然光成像關注并捕獲的是物體表面的信息如紋理顏色等,而 X 光成像關注的更多的是物體內部的結構和材質。
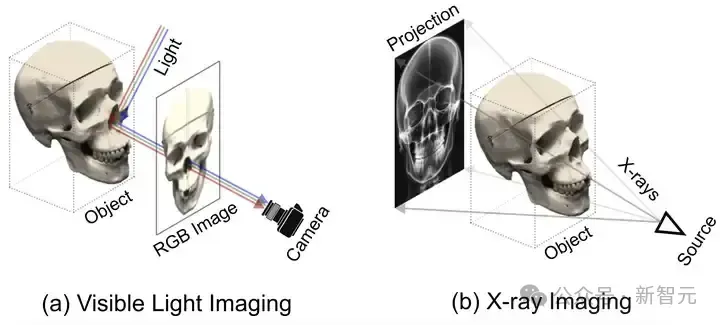
圖1 自然光成像原理對比 X 光成像原理
也正是因為自然光成像和 X 光成像之間的顯著差異,自然光下的 NeRF 方法以及對應的公式并不適用于 X 光。
針對 X 光的三維重建問題,本文提出了一種用于稀疏視角下 X 光三維重建的 NeRF 方法。具體而言,主要做兩個任務。一是 X 光的新視角合成 (Novel View Synthesis, NVS),二是 CT 重建,可以簡單理解為體密度的重建。

論文鏈接: https://arxiv.org/abs/2311.10959
代碼鏈接: https://github.com/caiyuanhao1998/SAX-NeRF
演示視頻:https://www.youtube.com/watch?v=oVVUaBY61eo
leaderboard: https://paperswithcode.com/dataset/x3d

X 光三維重建動態 demo
先給大家看一個在新視角合成任務上的性能對比圖:

圖2 我們的方法與 SOTA 方法在醫學、生物、安檢、工業場景上的新視角合成性能對比
目前所有的訓練測試代碼、預訓練權重、訓練日志、數據、測試結果均已開源。此外,我們已經在 paper with code 設置好了 leaderboard, 歡迎大家來提交結果。
我們將開源的 github repo 拓展成了一個支持 9 類算法的工具包方便大家的科研工作。除此之外,我還把數據可視化的代碼,和造數據的代碼也一起公開了,以方便有條件的可以接觸到CT數據的朋友可以在自己搜集的數據上開展研究。
文中主要做出了以下四點貢獻:
1. 提出了一套全新的能夠同時做 X 光新視角合成與 CT 成像的 NeRF 框架,名為 SAX-NeRF。該框架的訓練不需要用的 CT 作為監督信號,只使用 X 光片即可。
2. 設計了一種新的分段式 Transformer,名為 Lineformer,可以捕獲成像物體在三維空間中的復雜的內部結構。據我們所知,我們的 Lineformer 是首個將 Transformer 應用于 X 光渲染的 Transformer。
3. 提出了一種新型的射線采樣策略,名為 MLG sampling,可以從 X 光片上提取出局部和全局的信息。
4. 搜集了首個大規模的 X 光三維重建數據集,涵蓋醫療、生物、安檢、工業領域。同時,我們設計的算法在這個數據集上取得了當前最好效果,在 X 光新視角合成和 CT 重建兩大任務上比之前的最好方法要高出 12.56 和 2.49 dB。
空間坐標系的轉換
我們在圓形掃描軌跡錐形 X 光束掃描(circular cone-beam X-ray scanning)場景下研究三維重建問題。空間坐標系的變換關系如圖 3 所示。
被掃描物體的中心 O 為世界坐標系的原點。掃描儀的中心 S 為相機坐標系的中心。探測器 D 的左上角為圖像坐標系的原點。整個空間坐標系的變換遵循 OpenCV 三維視覺的標準。
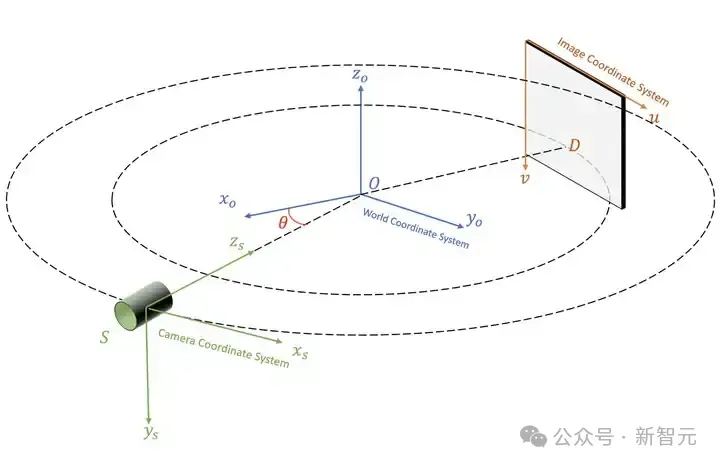
圖3 空間坐標系轉換關系示意圖
本文方法
NeRF 從自然光成像到 X 光成像
在自然光成像中,NeRF采用一個 MLP Θ 來擬合的是空間中點的位置 (??,??,??) 和視角 (??,??) 到該點的顏色 (??,??,??) 和體密度 (??) 的隱式映射:

而在 X 光成像中,并不關注顏色信息,只需要重建出輻射密度 ??。
同時我們注意到輻射密度屬性與觀測的視角無關。因此,我們指出,X 光下的 NeRF 公式應當為:

其中的 Θ?? 表示我們 Lineformer 的可學習參數。根據 Beer-Lambert 規則,一條 X 光射線的強度會沿著它所穿過的物體的輻射密度的積分而呈指數型衰減。如下公式所示:

將公式 (3)中的積分離散化,同時將其中的 ??(??(??)) 用我們 Lineformer 預測的 ???? 替代便可得到預測的 X 光強度,如公式(4)所示:

我們的訓練監督目標是預測的 X 光強度與真實的 X 光強度之間的均方誤差:

Lineformer — 分段式 Transformer
我們注意到 X 光的成像過程是沿著穿透物體被吸收或者阻擋,成像物體不同部分的結構和材質存在差異,因此 X 光被吸收的程度也不一致。
然而之前的 NeRF 類方法大都使用很常規的 MLP 網絡平等地對待沿著射線上的采樣點。如果直接采用 MLP 來擬合公式(3)的話,那 X 光成像的重要性質便被忽略了,難以取得很好的效果。
基于此,我們提出了一種新型的分段式 Transformer (Line Segment-based Transformer,簡稱 Lineformer)來擬合 X 光在穿透不同結構時的衰減。
我們的算法框架如圖 4 所示。我們首先采用 MLP sampling 策略采樣出一個 batch 的 X 光射線 ?? 。
對每一條射線,我們采出一組三維點的位置 ?? 。將 ?? 通過一個哈希編碼器 ?? 得到點特征 ??。然后 ?? 經過 4 個分段式注意力塊(Line Segment-based Attention Block,簡稱為 LSAB)與兩層全連接層便可得到這些點的輻射密度 ?? 。

圖4 SAX-NeRF 的算法框架圖
LSAB 中最核心的模塊是分段式的多頭自注意力機制(Line Segment-based Multi-head Self-Attention,LS-MSA),其結構如圖 4 (c)所示。將輸入的點特征記為 ??∈????×?? ,將其分為 M 段:

其中的 ????∈??????×?? 。然后 ???? 會被線性地投影到 ???? 、???? 、???? :

然后將 ???? 、 ???? 、 ???? 沿著通道維度均勻地分成 k 個頭:
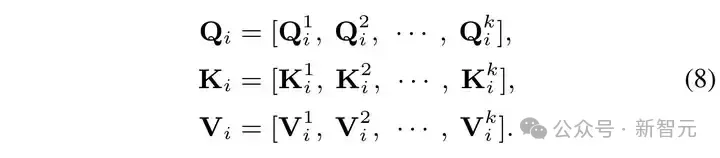
然后在每一個頭內計算自相似注意力 ?????? 如下:
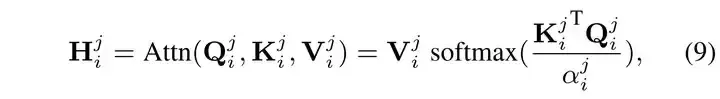
然后將計算結果拼接起來,通過一個全連接層后與一個位置編碼 ???? 相加后得到一段的輸出:

將 M 段輸出拼接起來便得到總的輸出:

分析我們的 LS-MSA 計算復雜度如下:
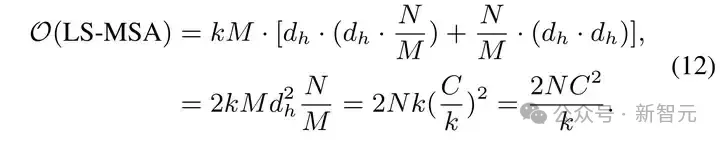
與采樣的點數 ?? 呈線性相關。對比全局多頭自注意力機制的計算復雜度:
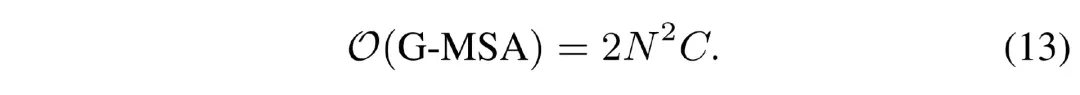
與采樣的點數 ?? 呈二次相關。因此我們的方法計算量比常規的 Transformer 要小得多。
X 射線采樣策略
由于 RGB 成像中信息普遍比較密集,即一張 RGB 圖像中幾乎每一個像素都傳遞信息。因此,RGB NeRF 在采射線時通常會使用隨機的方式在圖像上采集一批像素點,如圖5 (a) 中的藍色像素所示,每一個像素點對應一條射線。
然而這種射線采樣的策略并不適用于 X 光圖片,因為 X 光片有著較大的空間稀疏性。如果隨機采樣的話,可能有一些采樣點不落在成像區域,如圖 5 (a) 中的像素點 ?????? 。為了解決這個問題,我們設計了一種高效的射線

圖5 簡單隨機采樣 (a) 與我們的采樣策略 (b) 的對比
采樣策略,名為 MLG sampling,如圖 (b) 所示。首先,我們用一個二值化的掩膜將成像區域分割出來。然后我們將整個圖像分成互不重疊的小方塊。
然后我們隨機抽選 M 個完全落在成像區域的小方塊,取出小方塊內所有的像素對應的射線。在成像區域的其他位置(除開被選取的小方塊外),我們還再繼續抽取 N 個像素點對應的射線。
將兩次抽取的射線組成一個 ray batch 用作訓練。如此采樣得到的射線首先全都穿透被掃描物體,捕獲到被掃描物體的輻射密度信息。同時成塊的區域還有著豐富的語義上下文信息以幫助三維重建。
實驗結果
新視角合成
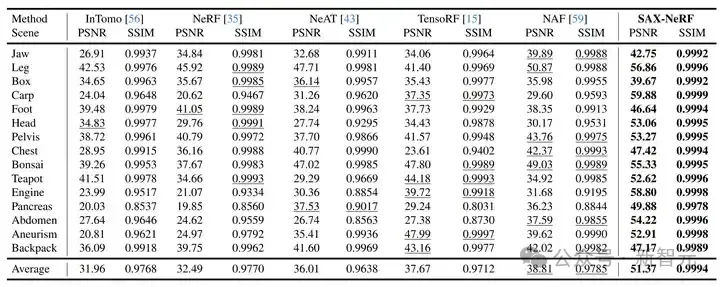
表1 新視角合成的定量實驗結果對比
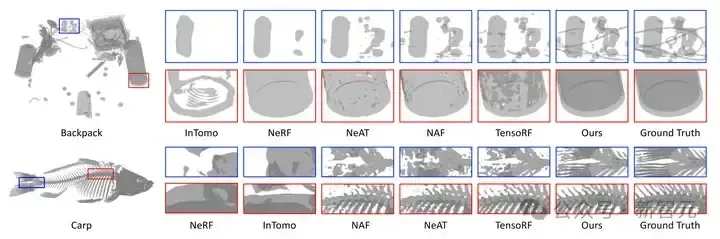
圖6 新視角合成的視覺結果對比
新視角合成任務上的定量指標和視覺對比分別如表 1 和圖 6 所示。我們的方法比之前最好方法還要高出 12.56 dB。
CT 圖像重建

表2 CT 圖像重建定量指標對比

圖7 CT 圖像重建的視覺對比
CT 圖像重建的定量指標和視覺對比分別如表 2 與圖 7 所示。我們的方法比之前最好的方法要高出 2.5 dB。
總結與后記
本文針對 X 光三維重建問題,設計了一套基于 NeRF 的可同時進行 X 光新視角合成與 CT 重建的算法框架 SAX-NeRF。搜集了一個大規模的 X 光三維重建數據集 X3D。
目前我已經將開源的 github repo 做成了一套相對完善的 codebase,支持 9 類算法,包含了數據生成、可視化的輔助功能函數代碼。


























